본 논문 optimal transport for domain adaptation 에서는, optimal transport를 이용한 도메인 적응 문제의 formulation, 그리고 계산을 위한 알고리즘을 소개하고 있다.
Domain adaptation?
도메인 적응 문제는 다음과 같은 상황에서 일어난다.
어떤 Learning 상황에서든, Training data와 Test data(적용하고자 하는 데이터)의 분포가 같기는 힘들다. Training Data에서 학습된 모델이 잘 작동하게 하기 위해서 (Generalization error의 최소화) 두 분포 차이를 어떻게 다뤄야 할까?
이 문제를 푸는 데에는 다양한 방법론들이 있으며, 본 논문에서는 optimal transport를 통해 이를 다루는 방법론을 설명한다. 이는 현재 가장 각광받는 접근방식 중 하나이기도 하다.
<Optimal transport를 활용한 도메인 적응문제 그림으로 설명>
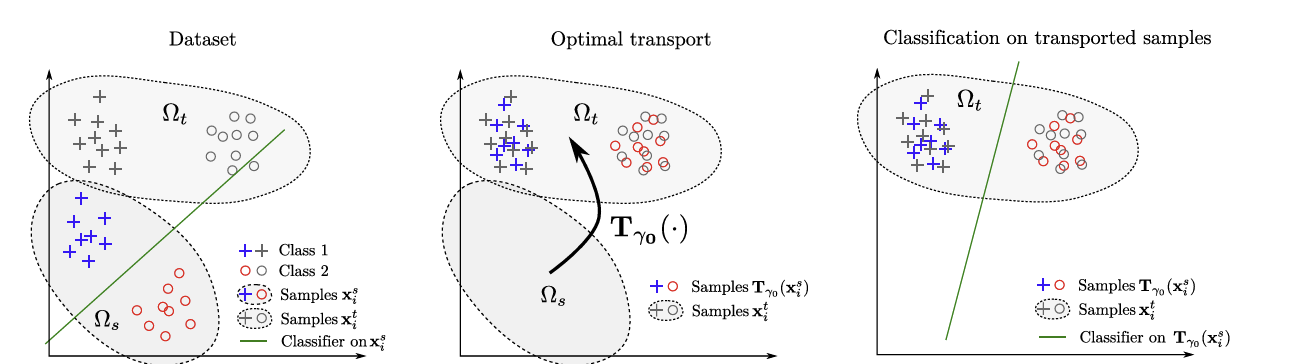
Optimal transport?
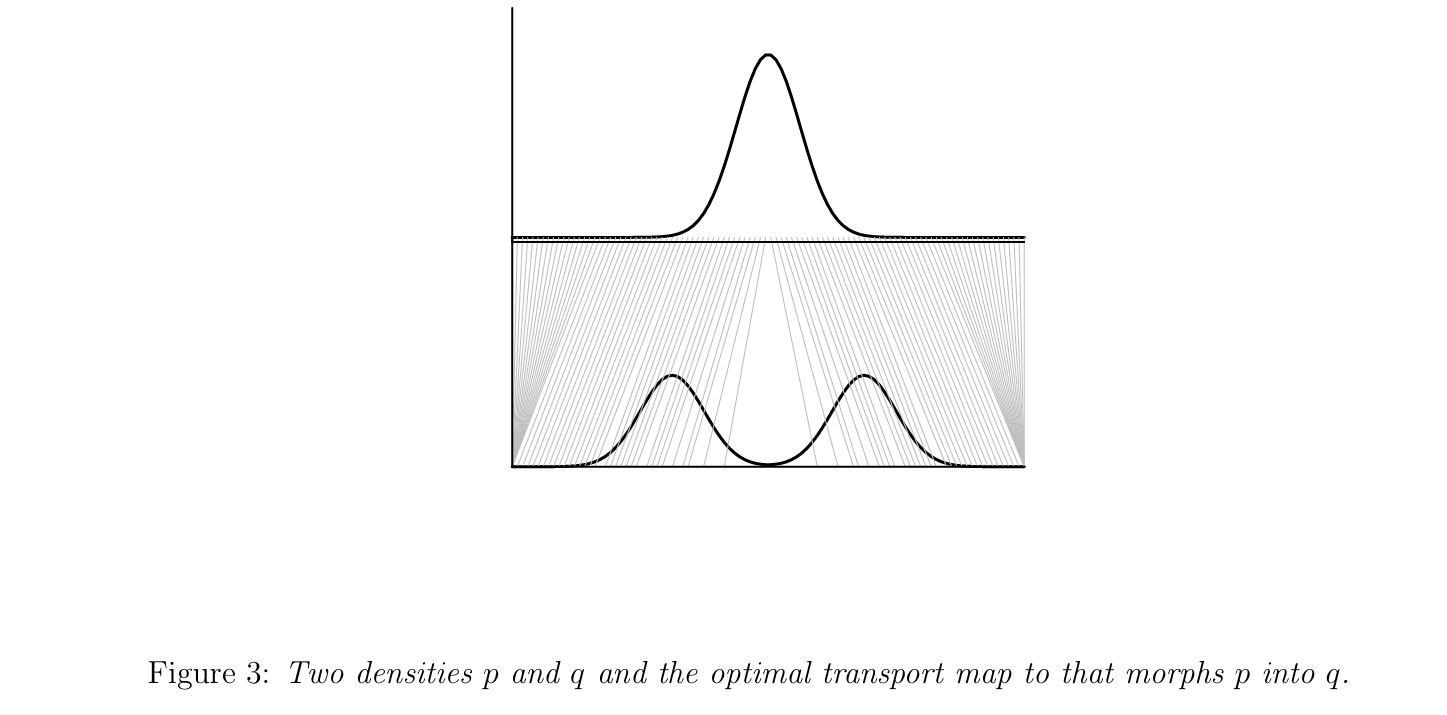
optimal transport(이하 OT)는 한국어로 하면 "최적수송" 방법으로, 서로 다른 분포가 있을 때, 확률밀도/질량 함수 관점에서 접근하면 어떻게 가장 적은 cost(다양한 metric이 사용됨)로 각 support를 mapping 시킬지에 관한 내용이다.
기본적인 OT mapping T는 다음과 같이 정의된다.

위와 같이 구하는 mapping T를 optimal transport map이라고 하며, T는 어느 한 분포의 support에서 다른 어떠한 분포의 support로 가는 mapping이다.
이러한 문제를 Monge problem 이라고 한다.
문제는, Monge problem의 해를 정의할 수 없는 상황이 많이 발생한다는 것이다. 예를 들어, 서로 다른 두 이산형 분포 P, Q가 있는데, P의 support에 해당하는 원소가 Q의 support의 그것보다 개수가 적은 경우, 위와 같은 map T를 찾아낼 수 없는 경우가 존재한다. 이런 경우까지 포괄하고자, Kantorovich formulation이 제안되었다.
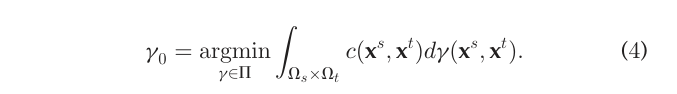
Kantorovich formulation에서는 Monge problem과 다르게 OT map T를 명시적으로 구하지는 않는다.(애초에 map T가 존재하지 않는 상황을 위한 개념임을 생각하자) 대신, joint distribution 가 비슷한 역할을 한다.
에서 쉽게 를 구할 수 있고, 직관적으로 이것이 가지는 의미는, x의 질량을 y에 어떠한 확률(비율)로 분배하는지를 나타낸다고 볼 수 있다. 우리는 이 joint distribution을 optimal coupling이라고 부른다.
추가적으로, optimal transport와 아주 밀접한(사실상 동일한) 개념임 Wasserstein distance는 두 분포의 차이를 나타내는 metric으로서 다음과 같이 정의할 수 있다.
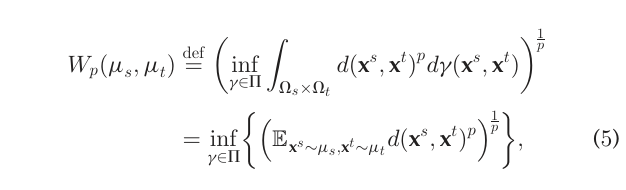
Framework
위의 OT개념을 사용하여 Domain adaptation 문제를 다음과 같은 방식으로 풀어 낼 수 있을 것이다.
-
Sample data , target data 로 부터 sample, target 분포 를 estimate 한다
-
에서 로 가는 optimal transport를 도출한다.
-
sample data를 transport를 통해 target support로 이동시키고, 거기서 분류기를 학습한다. (classifier이기 때문에 sample data의 label은 그대로 유지한다)
여기서, kantorovich formulation 하에서 OT-coupling을 통해 데이터를 이동시키는 것이 애매하다고 느껴질 수 있다.
이러한 상황에서는 barycentric mapping이라는 개념을 이용하여,
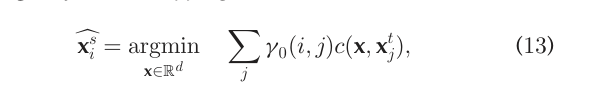
다음의 조건을 만족시키는 점을 optimal coupling에 의해 생성되는 map으로 정의한다.
Regularized Discrete Optimal Transport
위의 Framework 하에서, 결국 우리에게 주어진 것은 OT-coupling 를 어떻게 구할 것이냐에 대한 문제이다.

앞에서 구한 OT-coupling의 정의에 의하면, 위의 식을 품으로써 OT-coupling을 구하게 된다.
본 논문에서는 위의 단순한 Loss에 추가적으로 Regularization Term 들을 도입함으로써, 더 나은 일반화 성능을 가지는 OT-coupling 구하는 방법론을 소개한다.
For smoothness
위의 정의로만 구한 OT-coupling 는 x (각각 sample, target 데이터 개수) 차원을 가지는 matrix로 구해지며, 많은 원소가 0으로 나타내게 된다. Overfitting을 피하기 위해서는 을 보다 smooth 하게 보정해줄 필요가 있다. 따라서 Cuturi(2013)은 다음과 같은 Regularization term을 도입한 Loss function을 제안하였다.
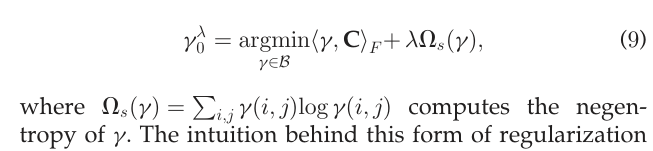
위의 식에서 는 negative entropy를 의미하며, 가 uniform 분포를 가질 때 최소화 된다. 즉 위의 제약 항은 특정 원소가 0이 되지 않도록 (sparsity 방지) 하는 항이라고 보면 되며, 이는 uniform 분포와 사이의 KL-divergence로 이해 할 수도 있다.
위와 같은 최적화문제는 Sinkhorn-Knopp's scaling matrix approach를 통하여 효율적으로 구할 수 있다고 한다.(추후 설명)
Class-Regularization for Domain Adaptation
Sample data를 Target domain으로 이동시킬 때는, Sample data들의 구조를 보존하는 것도 매우 중요한 점이다.
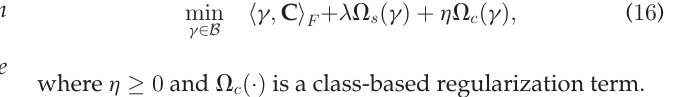
따라서 이에 대한 제약 항 를 도입하면 Loss는 위와 같이 정의될 수 있다. Class-regularization을 위한 제약 항으로 논문에서는 두 가지의 옵션을 제시한다.
Regularization with Group-Sparsity
첫 번째 옵션은 sample data의 label 정보를 이용하는 것이다. 직관적인 motivation은 Target domain의 point는 같은 label을 가지는 sample data의 원소로부터만 mass를 받아야 한다는 것이다. 이는 transformation 후의 class 구조를 보존하기 위한 것이다.
만약, source에서 class가 잘 분리 되어 있었는데, OT에 의해 이동된 source 데이터에 class가 막 섞여있다면, 바람직한 결과가 나오기 어렵기 때문이다.
이에 따라서 다음과 같은 regularization term을 추가로 도입한다.

위의 제약항을 해석해보면, 각 target data 에 대하여, label 을 가지는 source data들 , 에 대한 확률 합을 최소화 시킨다는 것이고, 이는 특정 고정된 j에 대해 특정 cl만을 label로 가지는 source가 연결될 확률이 양수가 되도록 강제한다.
이러한 제약 항을 도입하는데에 있어서, 우리가 기대하는 것은 Y의 분포가 source와 target domain에서 비슷하다는 것이다. (Source의 Y 정보가 Target의 Y 정보로 전송? 되고 있으므로) 하지만 약간의 차이는 용인 가능하다고 한다.
Laplacian Regularization
에 대한 첫 번째 선택에서는 class의 구조를 보존하는 것을 목표로 한 것이다.
두 번째 방법인 Laplacian Regularization 에서는 그래프를 통해서 추정된 데이터 구조를 OT 동안 유지하고자 하는데 목적이 있다.
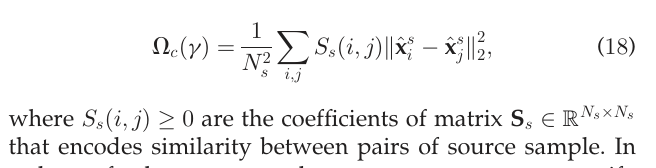
위에서 는 sample data 사이의 유사도를 나타낸 행렬을 의미하며, 이 제약항은 결국 유사도가 큰 데이터들이 target 으로 mapping 되었을 때, 두 barycenter mapping 간의 distance가 가까이 유지되게끔 강제한다.
Generalized Conditional Gradient(GCG) for solving regularized OT problems
이제 를 최적화시키는 방법을 알아보자. 이에 앞서, 논문에서는 restricted 의 집합에서 최적의 가 존재하는 조건에 대하여 탐구한다.
- 위의 Loss는 에 대하여 연속임
- 는 compact set.
- 최대최소정리에 의해 Loss는 minima를 가짐
- Loss function이 convex인가?
- Frobenius norm : convex (w.r.t )- negative entropy : convex
- (18)의 laplacian regularization term은 convex
- negative entropy : convex
minima를 구하는 알고리즘으로, 이 논문에서는 기존의 conditional gradient algorithm(CG)를 확장한 Generalized conditional gradient(GCG)를 제안한다.
이 부분에 대해서는 convex optimization을 공부해보고 업데이트 예정이다.
