BLUR 된 이미지가 STAGE1에 들어가면, STAGE1, STAGE2를 거쳐 BLUR가 없어진 이미지가 나오게끔 하는 것이 이 네트워크의 구조이다.
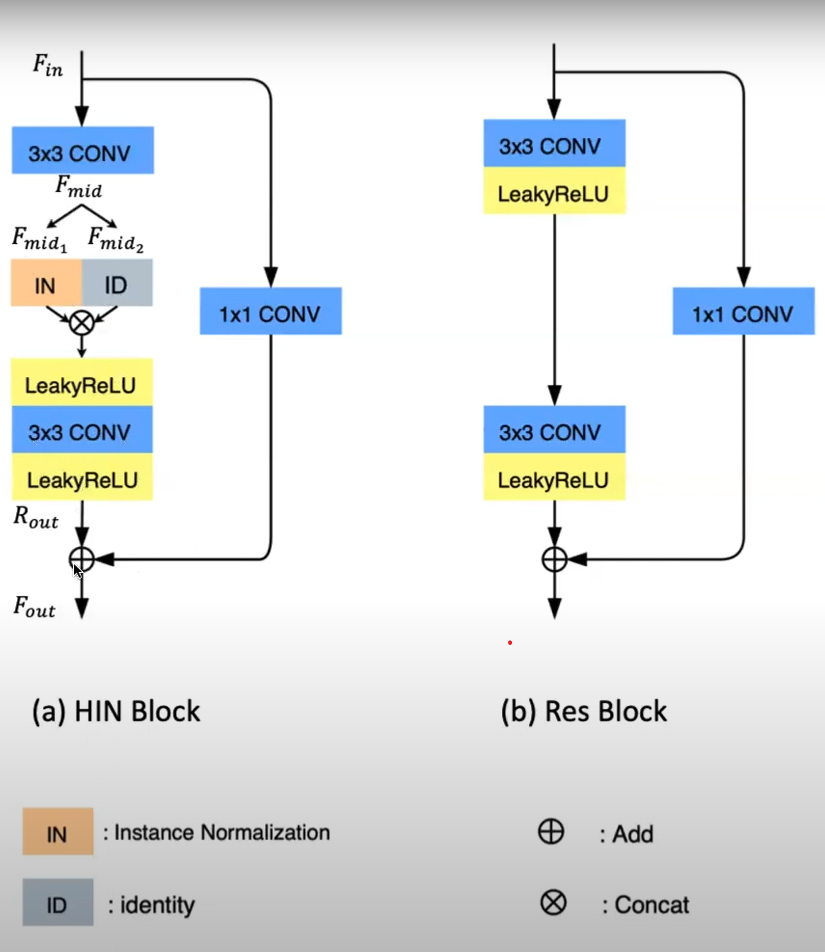
STAGE1, STAGE2 가 있다. UNET과 비슷한 구조이고 DOWN-SAMPLING 2번, UP-SAMPLING 2번으로 이루어져 있다. 그리고 이 때, DOWN-SAMPLING과 UP-SAMPLING 에서 각각 두 개의 HIN BLOCK과 RES BLOCK이 쓰인 것을 알 수 있다.
HINET의 HIN BLOCK에서는 INSTANCE NORMALIZATION과 IDENTITY의 CONCATENATE를 사용한 것을 알 수 있고, DOWN-SAMPLING과 UPSAMPLING에서 오는 정보 손실을 피하기 위해 SAM과 CSFF를 이용하는 것을 알 수 있다.
- SAM(Selective Attention Module)
: 주어진 특징 맵에서 중요한 정보를 강조하고 덜 중요한 정보를 억제하는 기능을 한다. 이 모듈은 주로 네트워크 학습 중에 어떤 특징이 task에 가장 관련이 있는 지를 학습하여 해당 특징의 가중치를 증가시킨다. 이를 통해 네트워크는 중요한 신호에 더 집중할 수 있고, 노이즈나 관련없는 정보는 무시할 수 있다.
예를 들어 이미지에서 얼굴을 인식하는 작업에서 SAM은 얼굴의 특징적인 부분(눈, 코, 입 등)에 더 많은 주목을 할 수 있도록 한다. 이를 통해 배경이 복잡하거나 조명이 좋지 않은 환경에서도 얼굴을 효과적으로 인식할 수 있다.
- CSFF(Cross-Scale Feature Fusion)
: CSFF는 다른 스케일에서 얻은 특징 맵을 효과적으로 통합하는 기능을 수행한다. 이 모듈은 서로 다른 해상도에서 추출된 특징을 결합하여 이미지 복원이나 분류 과정에서 세밀한 특징과 전반적인 구조 모두를 고려할 수 있도록 합니다
예를 들어, 이미지를 확대하는 과정에서 CSFF는 저해상도 입력에서 얻은 정보와 고해상도 입력에서 얻은 정보를 결합하여 이미지의 품질을 개선한다. 저해상도에서는 이미지의 전반적인 구조를 파악하는 데 유리하고, 고해상도에서는 세부적인 텍스처와 경계를 더 잘 파악할 수 있다.
- 배치 정규화 VS 인스턴스 정규화
: 배치 정규화가 배치 차원에 걸쳐 각 채널의 평균과 분산을 계산하는 데 반해, 인스턴스 정규화는 단일 이미지 내에서 각 채널의 평균과 분산을 독립적으로 계산한다.


끊임없이 뭔가를 남기는 사람