적용 순서
-
setup이 로드되어야 한다.
-
setup의 파라미터는 classification, regression, anormaly 에 따라 달라질 수 있다.
모델 생성 및 비교
-
model()
-
compare_models()
Setup된 데이터를 각각 머신러닝 모델에 적용 후 비교한다.
-
create_model()
model()에 적힌 머신러닝 모델을 선택해서 생성한다.
모델 최적화
compare_models나 create_model을 사용해서 각각의 모델들을 생성하거나 비교했다. 결과를 바탕으로 성능이 좋은 모델들을 조합하여 실험해볼 수 있는 모듈을 제공한다.
-
tune_model()
모델의 하이퍼파라미터를 최적화하는 모듈이다. 하이퍼파라미터 반복 횟수나 최적화할 메트릭을 선택할 수 있다.
-
ensemble_model()
ensemble 기법을 구현한 모듈이다. bagging과 boosting을 파라미터에서 선택할 수 있다.
-
blend_models()
voting 알고리즘을 구현한 모듈이다. compare_models()에서 성능이 잘 나 온 모델들을 선택하는 파라미터를 적용(n_select)시켜서 사용할 수 있다.
학습된 모델 분석
-
plot_model()
학습한 모델에 대한 각종 지표들을 시각화한 플롯을 그려주는 모듈이다. auc, threshold, confusion matrix 등 약 15가지 이상의 다양한 플롯들을 지원한다.
-
interpret_model()
모델이 예측한 결과에 대해서 각 파라미터들이 얼마나 영향을 줬는지 시각화해서 보여준다.
-
assign_model()
비지도 류의 머신러닝 기법에 대한 머신러닝 결과값을 데이터셋에 부쳐준다.
- evaluate_model()
모델 분석 후 각 플롯을 볼 수 있도록 사용자 인터페이스를 제공해준다. 한방에 플롯을 전부 띄우고 싶다면 plot_model()보다는 evaluate_model()을 사용한다.
Hard voting vs Soft voting
Hard voting
각각의 모델들이 결과를 예측하면 단순하게 가장 많은 표를 얻은 결과를 선택하는 것

Soft voting
각 class별로 모델들이 예측한 확률을 합산해서 가장 높은 결과를 선택하는 것
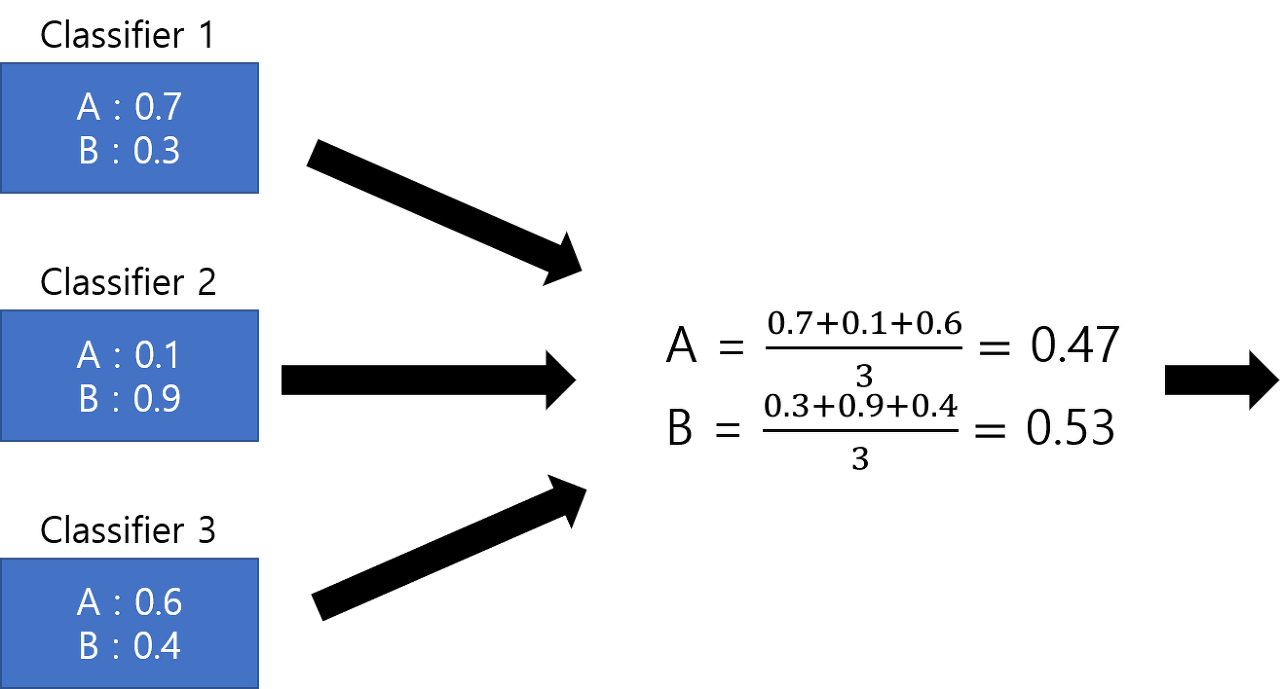
출처: https://velog.io/@devseunggwan/Machine-Learning-pycaret%EC%9D%84-%EC%82%AC%EC%9A%A9%ED%95%9C-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D, https://devkor.tistory.com/entry/Soft-Voting-%EA%B3%BC-Hard-Voting
Bagging(Bootstrap Aggregating)
기존 학습 데이터로부터 랜덤하게 '복원추출'하여 동일한 사이즈의 데이터셋을 여러 개 만들어 앙상블을 구성하는 여러 모델을 학습시키는 방법이다. 이러한 복원추출로 만들어진 새로운 데이터셋을 Bootstrap이라고 한다. 여기서 학습 모델은 정해진 것이 아니며, 어떠한 지도 학습 알고리즘이든 다 활용될 수 있다.
