쓰는 이유
시계열 클러스터링에 대한 가장 일반적인 접근 방식은 시계열을 각 시간 인덱스에 대한 열이 있는 테이블로 평면화하고 k-means와 같은 표준 클러스터링 알고리즘을 직접 적용하는 것이다.
Unsupervised learning으로 하지만 시계열로 되어 있는 데이터를 클러스터링해버리면 시간에 따른 정보가 사라지기 때문에 다른 방법이 필요하다.
timeserieskmeans 는 시간에 따른 군집화가 가능하기 때문에 위의 문제를 해결할 수 있다.
방법
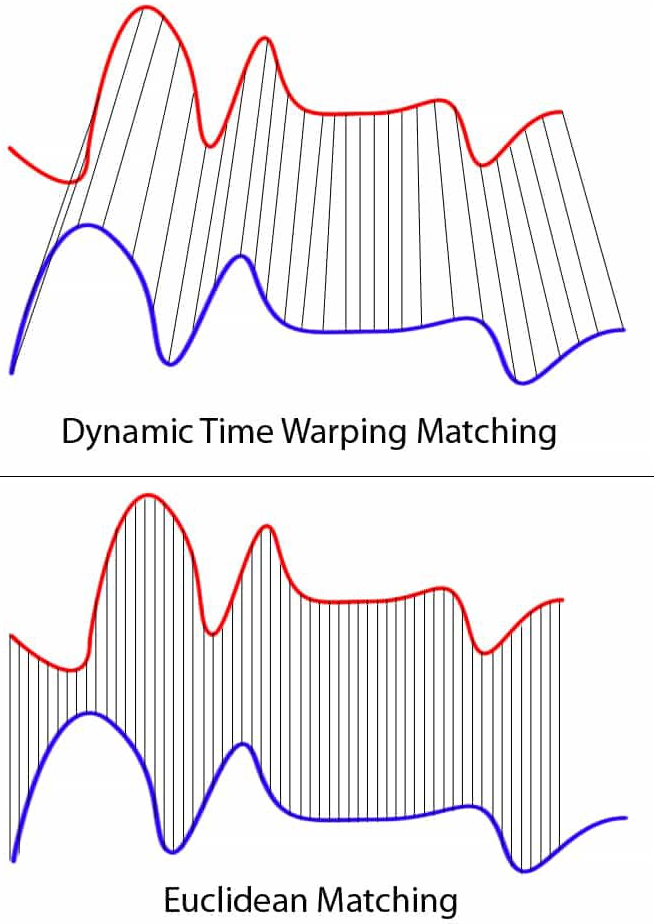
기본 거리 측정을 동적 시간왜곡과 같은 시계열 비교를 위한 메트릭으로 바꾸어야 한다. 그러나 먼저 일반적인 유클리드 거리 측정법이 시계열에 적합하지 않은 이유는 무엇일까?
데이터의 시간 차원을 무시하고 시간 이동에 불변한다. 두 시계열이 높은 상관관계가 있지만 하나가 한 시간 단계만큼 이동하는 경우 유클리드 거리는 더 멀리 떨어져 있는 것으로 잘못 측정하게 된다.
이러한 문제를 해결하기 위해 동일한 시간선상의 데이터 이외에 주변 시점의 데이터를 활용하여 비교한 뒤 더 비슷한 요소와 매칭하자는 아이디로 출발한 DTW를 사용하여 두 개의 시계열 간의 유사도를 측정할 수 있다.

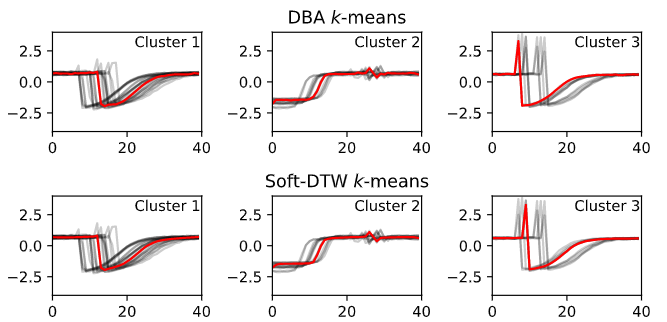
동적시간 왜곡을 사용한 k-means clustering
-
dtw(dynamic time warping)는 유사한 모양의 시계열을 수집하는 데 사용된다.
-
군집 중심 또는 barycenters는 dtw를 기준으로 계산된다. 무게중심은 dtw 공간에서 시계열 그룹의 평균시퀀스다. dtw dba 알고리즘은 군집에서 중심과 계열간의 제곱 dtw 거리의 합을 최소화한다. soft-dtw 알고리즘은 군집의 중심과 계열 사이의 soft-dtw 거리의 가중치 합을 최소화한다. 가중치는 조정할 수 있지만 합계는 1이어야 한다.