파이토치에서 임베딩 벡터를 사용하는 방법은 2가지다.
-
임베딩 층을 만들어 훈련 데이터로부터, 처음부터 임베딩 벡터를 학습하는 방법과 미리 사전에 훈련된 임베딩 벡터들을 가져와 사용하는 방법
-
미리 사전에 훈련된 임베딩 벡터들을 가져와 사용하는 방법
임베딩 층은 룩업 테이블
임베딩 층의 입력으로 사용하기 위해서는 입력 시퀀스의 각 단어들이 모두 정수로 인코딩이 되어있어야 한다.
어떤 단어 -> 단어에 부여된 고유한 정수값 -> 임베딩 층 통과 -> 밀집 벡터
임베딩 층은 입력 정수에 대해 밀집 벡터로 맵핑하고 이 밀집 벡터는 인공 신경망의 학습 과정에서 가중치가 학습되는 것과 같은 방식으로 훈련된다. 훈련 과정에서 단어는 모델이 풀고자 하는 작업에 맞는 값으로 업데이트 된다. 이 밀집 벡터를 임베딩 벡터라고 한다.
정수를 밀집 벡터 또는 임베딩 벡터로 맵핑하는 것은,
nn.Embedding
각각 num_embeddings와 embedding_dim을 인자로 받는데, 여기서 num_embeddings는 임베딩을 할 단어들의 개수, 다시 말해 단어 집합의 크기이고, embedding_dim은 임베딩할 벡터의 차원이다.
nn.LSTM
input_dim = 4
hidden_dim = 2
n_layers = 1
nn.LSTM(input_dim, hidden_dim, n_layers, batch_first=True)LSTM Layer가 어떻게 input을 받는지 보기 위해 임의의 데이터를 생성해본다.
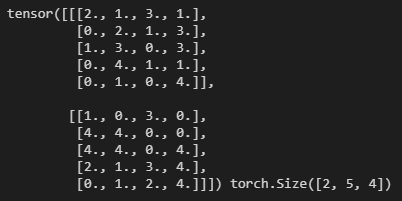
위 데이터는 size= (batch_size, seq_len, input_dim)인 텐서다.
hidden_state와 cell_state 또한 같은 형식으로 size= (1, 2, 2) 로 만들 수 있는데 이를
hidden = (hidden_state, cell_state)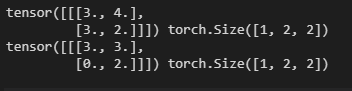
다음과 같이 나타나는 것을 확인할 수 있다.
out, hidden = lstm_layer(inp, hidden)
이를 lstm_layer에 넣으면 out과 hidden이 나타나는데,
size= (batch_size, seq_len, input_dim) 인 out과
입력값으로 2,5,4 shape의 텐서를 lstm_layer에 주면 그 결과 값으로 2,5,2의 텐서가 생성되고 이는 각 lstm cell마다 2,1,2 shape을 가진 텐서를 추력한다는 것을 의미한다.
