번역기

번역기의 내부를 상상해보자. 번역기의 모습은 어떻게 생겼을까? 번역기는 크게 인코더와 디코더라는 두 개의 모듈로 구성된다. 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 만드는데, 이를 컨벡스트 벡터라고 한다. 입력 문장의 정보가 하나의 컨텍스트 벡터로 압축되면 인코더는 컨텍스트 벡터를 디코더로 전송한다. 디코더는 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력한다.
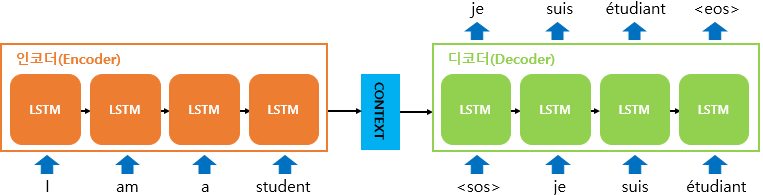
디코더는 초기 입력으로 문장의 시작을 의미하는 심볼 sos 가 들어간다. 디코더는 sos가 입력되면, 다음에 등장할 확률이 높은 단어를 예측한다. 첫번째 시점의 디코더 셀은 다음에 등장할 단어를 예측한다. 첫번째 시점의 디코더 셀은 예측된 단어는 다음 시점의 셀의 입력으로 입력한다. 그리고 두번 째 시점의 셀은 입력된 단어로부터 다시 다음에 올 단어를 예측하고 또 다시 이것을 다음 시점의 셀의 입력으로 보낸다. 디코더는 이런 식으로 기본적으로 다음에 올 단어를 예측하고, 그 예측한 단어를 다음 시점의 셀의 입력으로 넣는 행위를 반복한다. 이 행위는 문장의 끝을 의미하는 eos가 다음 단어로 예측될 때까지 반복한다.
출력 단어로 나올 수 있는 단어들은 다양한 단어들이 있다. seq2seq 모델은 선택될 수 있는 모든 단어들로부터 하나의 단어를 골라서 예측해야 한다. 이를 예측하기 위해서 쓸 수 있는 함수가 바로 소프트맥스 함수다. 디코더에서 각 시점의 셀에서 출력벡터가 나오면, 해당 벡터는 소프트맥스 함수를 통해 출력 시퀀스의 각 단어별 확률값을 반환하고, 디코더는 출력 단어를 결정한다.
