슬라이싱
슬라이싱은 리스트나 문자열 등의 연속적인 객체들의 범위를 지정해서 객체들을 가져오는 방법을 의미한다. 슬라이싱을 하면 일부분을 잘라낸 새로운 객체를 생성한다.
객체[start:end:step]getitem
클래스의 인덱스에 접근할 때 자동으로 호출되는 메소드이다.
class study:
def __init__(self):
print("생성자")
self._numbers = ["a", "b", "c", "d", "e"]
def __getitem__(self, index):
print("호출")
return self._numbers[index]
a = study()
a[0]생성자
호출
'a'
가 출력되는 것을 확인할 수 있다.
len
class A:
def __init__(self, a):
print("생성자")
self.a = a
def __len__(self):
print("호출")
return len(self.a)
print(A('string').__len__()) # 6
a = A('string')생성자
호출
6
생성자
가 출력되는 것을 확인할 수 있다.
torch.utils.data.DataLoader
Dataset을 샘플에 쉽게 접근할 수 있도록 순회 가능한 객체로 감싼다.
모델을 학습할 때, 일반적으로 샘플들을 미니배치로 전달하고 매 에폭마다 데이터를 다시 섞어서 과적합을 막고, python의 멀티프로세싱을 사용하여 데이터 검색속도를 높이려고 한다.
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)torch.utils.data.Dataset
샘플과 정답을 저장한다.
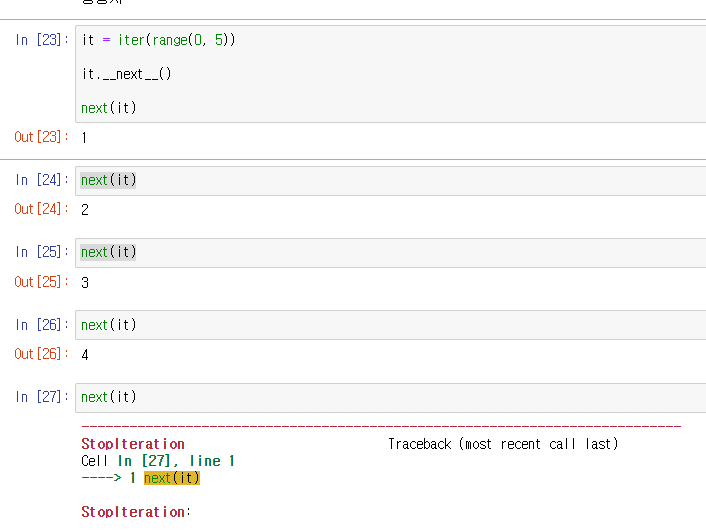
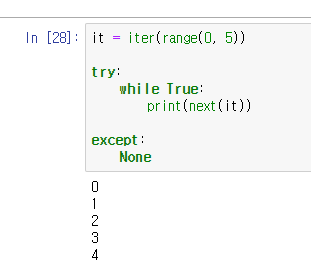
iter와 next
iter는 반복을 끝낼 값을 지정하면 특정 값이 나올 때 반복을 끝낸다. 이 경우 반복 가능한 객체 대신 호출 가능한 객체를 넣어준다.

끊임없이 뭔가를 남기는 사람