1. 프로젝트 개요
-
레드 와인과 화이트 데이터를 이용하여, 각 와인을 구분할 수 있는 모델을 만들어보고
그 모델을 결정짓는 주요 feature를 확인해보자 -
또한, 와인 맛에 대한 분류도 진행해보자
2. 데이터 확인
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')red_wine.head()
white_wine.head()
두 데이터를 하나의 데이터로 합쳐보자 !
red_wine['color'] = 1
white_wine['color'] = 0wine = pd.concat([red_wine,white_wine])
wine.info()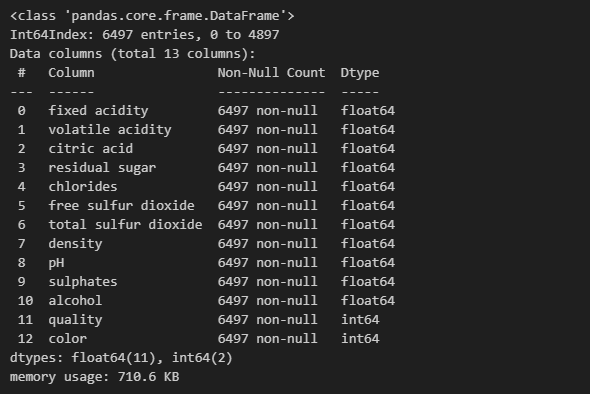
wine.head()
3. 데이터 시각화
3-1. 레드 / 화이트 와인별 histogram
fig = px.histogram(wine, x='quality', color='color')
fig.show()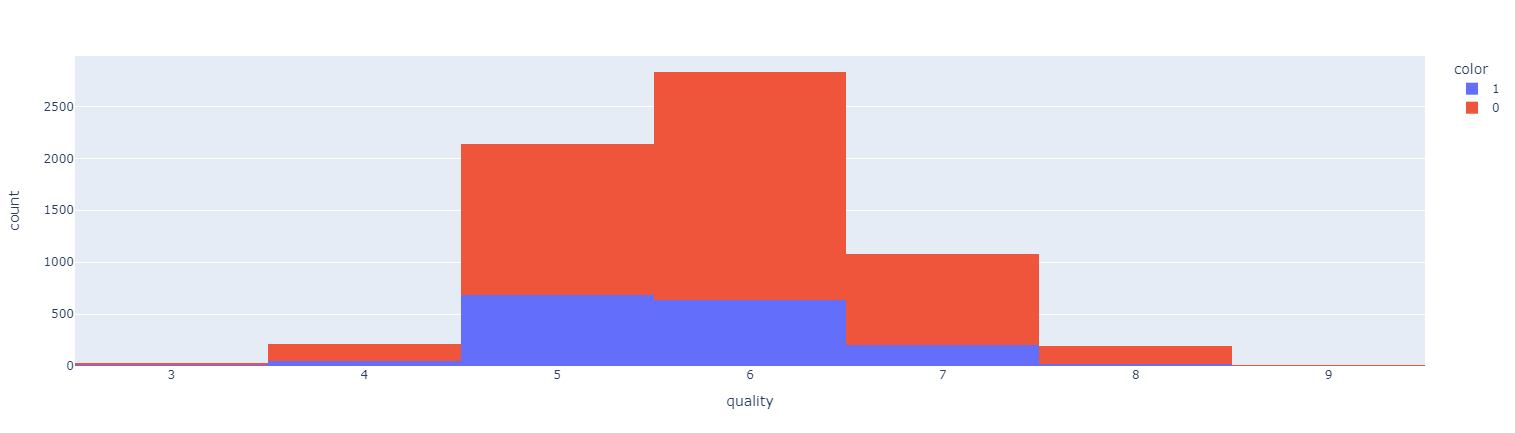
3-2. Quality (맛) histogram
wine['quality'].unique()
import plotly.express as px
fig = px.histogram(wine, x= 'quality')
fig.show()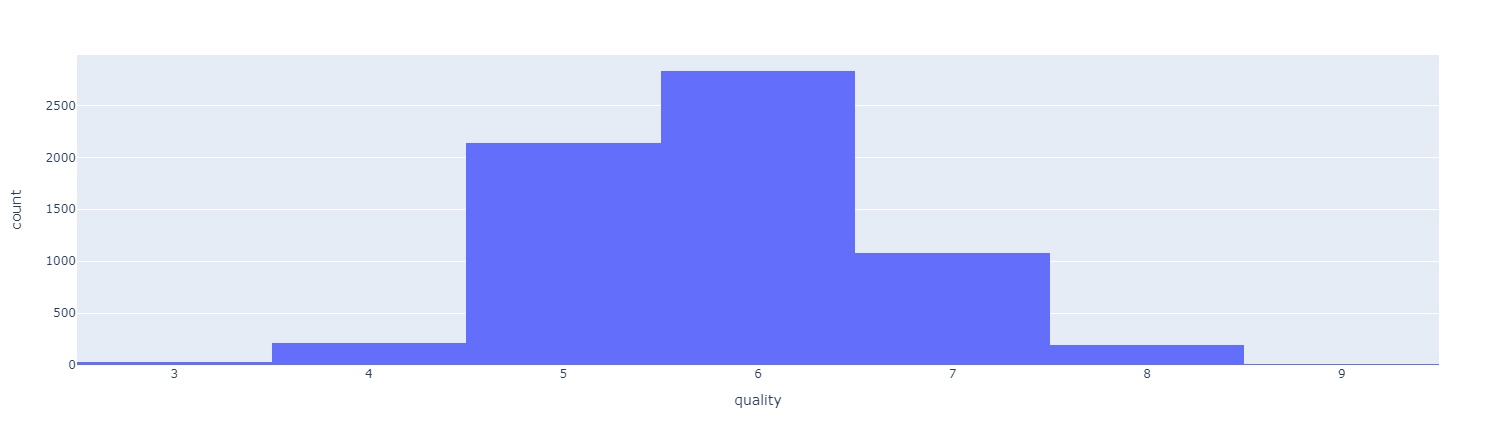
wine['quality'].value_counts()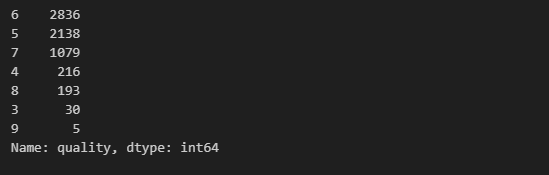
분류를 위해 quality 컬럼을 이진화하자 !
wine['taste'] = [1. if grade>5 else 0.for grade in wine['quality']]
wine.info()
4. 데이터 모델링
4-1. 레드/화이트 와인 분류
X = wine.drop(['color'], axis=1)
y = wine['color']from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)accuracy_score(y_train,y_pred_tr)
accuracy_score(y_test,y_pred_test)
Accuracy 측면에서 두 개의 성능은 유사한 것을 확인
dict(zip(X_train.columns, wine_tree.feature_importances_))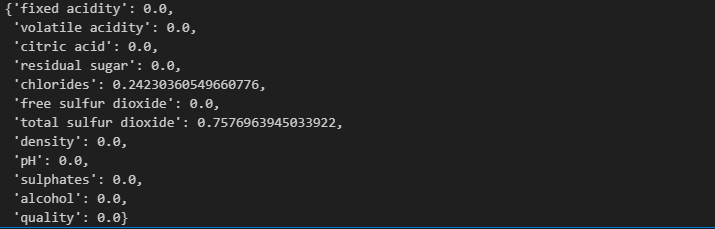
레드 와인과 화이트 와인을 구분짓는 주요 feature는 chlorides 와 total sulfur dioxide 인 것을 확인.
4-2. 와인 맛 분류
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train,y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))
import sklearn.tree as tree
plt.figure(figsize=(12,5))
tree.plot_tree(wine_tree, feature_names=X.columns,
filled=True, rounded=True);
dict(zip(X_train.columns, wine_tree.feature_importances_))
decision tree가 와인 맛을 구분하는 주요 feature는 alcohol 과 volatile acidity 인 것을 확인
5. 그 외 tip
decision tree는 scaler를 이용한 전처리가 크게 의미가 없다.
하지만 만약 scaler를 진행해야하는 경우, Pipeline을 이용하여 좀 더 간단히 진행할 수도 있다.
5-1. Pipeline 생성
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1
white_wine['color'] = 0
wine = pd.concat([red_wine,white_wine])
X = wine.drop(['color'], axis=1)
y = wine['color']from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())
]
pipe = Pipeline(estimators)pipe
pipe.steps
set_params을 이용하여 세부 옵션을 지정할 수도 있다
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13)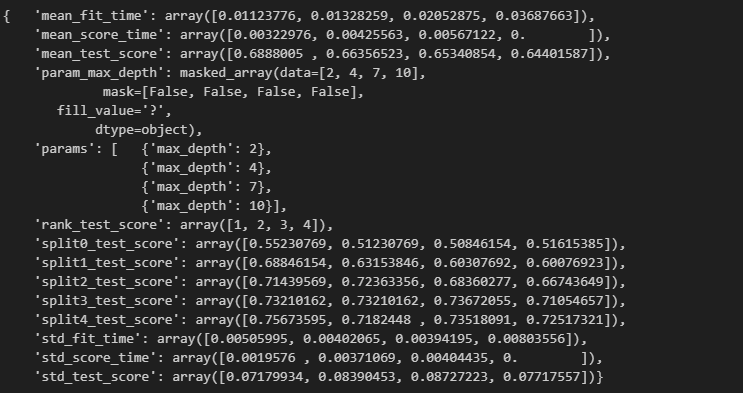
5-2. Pipeline 실행
- 원래라면 다음의 순서이겠지만
[scaler]
- StandardScaler( )
- fit
- transform
[ DecisionTree ]
- train_test_split( )
- DecisionTreeClassifier( )
- fit
- predict
- pipeline을 이용하면 바로 6,7만 진행하면 된다.
# 만약 train, test data 분리 시 분포를 맞추고 싶다면 stratify 옵션을 이용하면 된다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=13, stratify=y)
pipe.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train acc : ', accuracy_score(y_train, y_pred_tr))
print('Test acc : ', accuracy_score(y_test, y_pred_test))
6. CrossValidation
4-2 와인 맛 분류에서 진행했던 코드이다.
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train,y_train)
만약 여기서 이 결과가 정말 괜찮은 것인지에 대한 질문을 받을 때, 어떤 근거를 들면 좋을까 ?
교차검증 : 데이터를 여러 번 반복해서 나누고 학습된 알고리즘의 성능을 평가하는 방법
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X , y, scoring=None, cv=skfold)
만약 test score가 아닌 train score도 함께 보고 싶을 경우
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)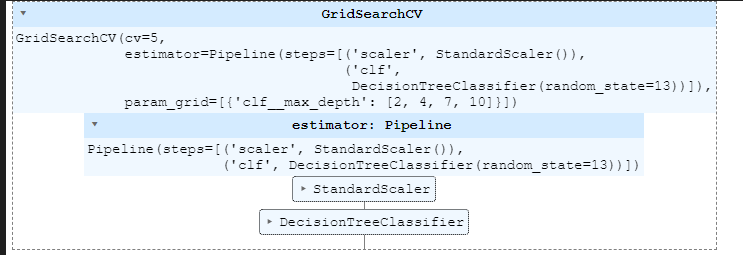
7. 하이퍼파라미터
하이퍼파라미터 : 모델의 성능을 확보하기 위해 조절하는 설정 값
위에서 튜닝해볼만한 것은 max_depth
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X,y)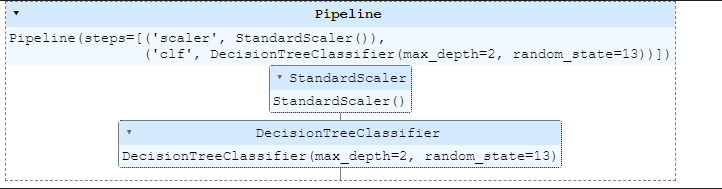
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)
최적의 성능을 가진 모델은 ?
gridsearch.best_estimator_
gridsearch.best_score_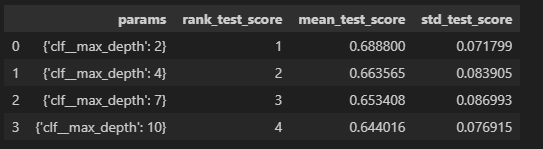
gridsearch.best_params_만약 pipeline을 적용한 모델에 GridSearch를 적용하고 싶다면 ?
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier(random_state=13))
]
pipe = Pipeline(estimators)param_grid = [ {'clf__max_depth' : [2,4,7,10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X,y)GridSearch.best_estimator_GridSearch.best_score_데이터프레임으로 정리
score_df = pd.DataFrame(GridSearch.cv_results_)
score_dfscore_df[['params','rank_test_score','mean_test_score','std_test_score']]