1. Pandas
- Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
2. Series
- index와 value로 이루어져 있음
- 한 가지 데이터 타입만 가질 수 있음
- pandas는 통상 pd
- numpy는 통상 np
import pandas as pd
import numpy as np > pd.Series([1, 2, 3, 4])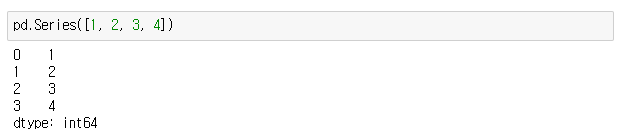
> pd.Series([1, 2, 3, 4], dtype=np.float64)
> pd.Series([1, 2, 3, 4], dtype=str)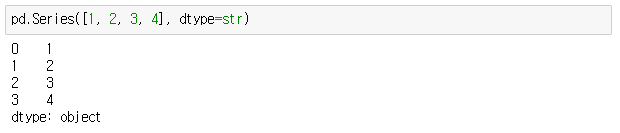
> pd.Series(np.array([1, 2, 3]))
> pd.Series({"Key": "Value"})
3. DataFrame
- pd.Series() : index, value
- pd.DataFrame() : index, value, column
# 표준정규분포에서 샘플링한 난수 생성
> data = np.random.randn(6,4)
> data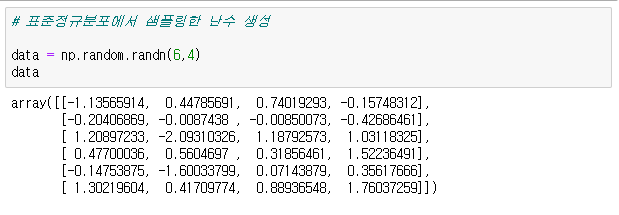
# pd.DataFrame(data, index, columns)
> df = pd.DataFrame(data, index = dates, columns= ["A", "B", "C", "D"])
> df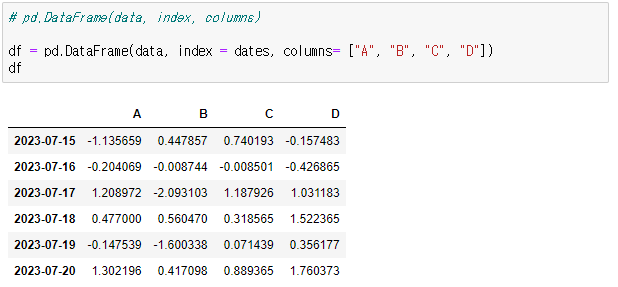
> df.index
> df.values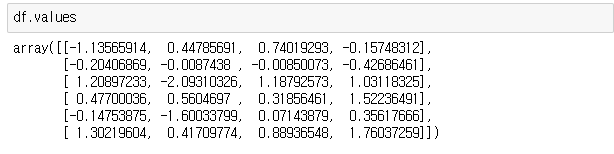
> df.columns
4. 정보 탐색
> df.head()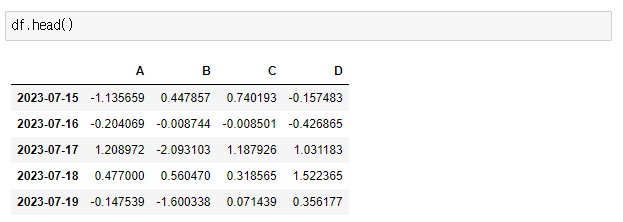
> df.tail()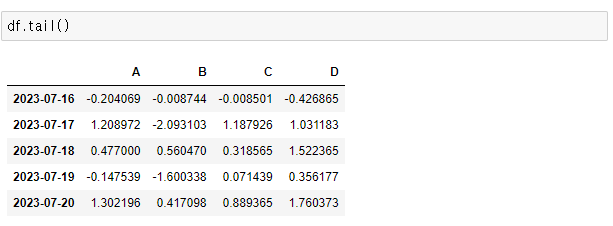
> df.info()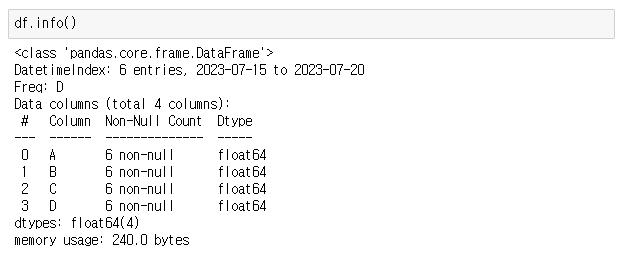
> df.descirbe()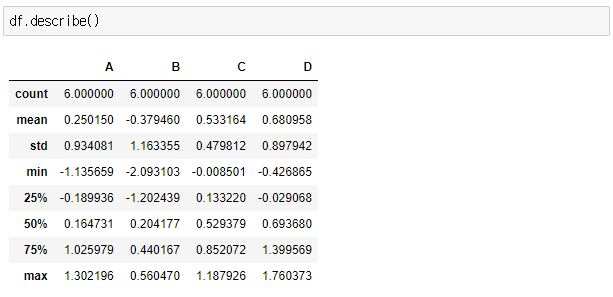
5. 데이터 핸들링
# 두 개 이상 컬럼 선택
> df[["A", "B"]]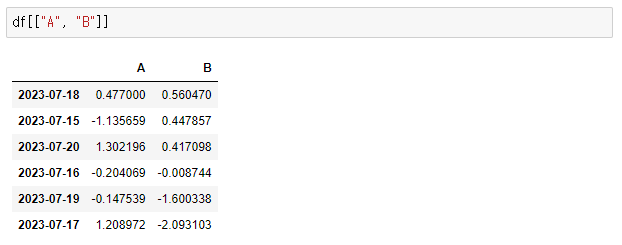
- offset index
- [n:m] : n부터 m-1 까지
- 인덱스나 컬럼의 이름으로 slice 하는 경우는 끝을 포함
> df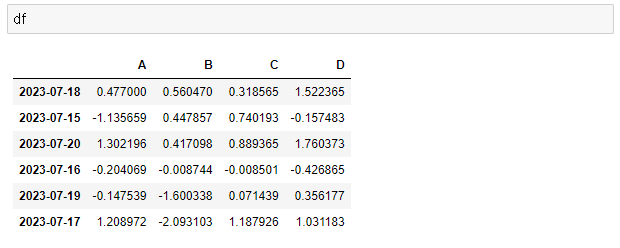
> df[0:3]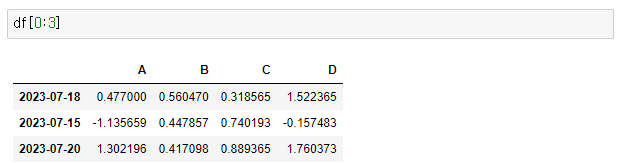
> df["20230715" : "20230718"]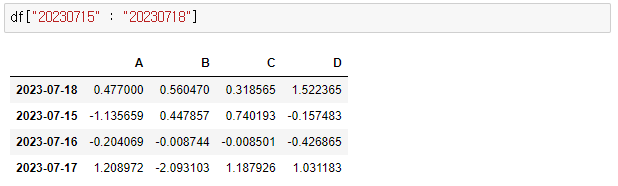
- loc
- index 이름으로 특정 행,열 선택
> df.loc[:, ["A","B"]]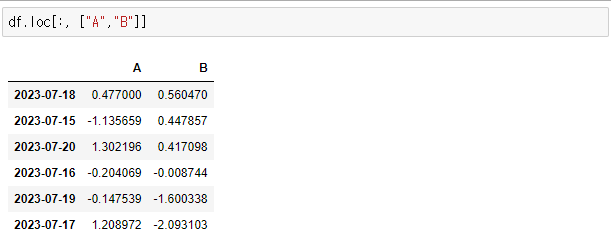
> df.loc["20230715" : "20230718", "A":"D"]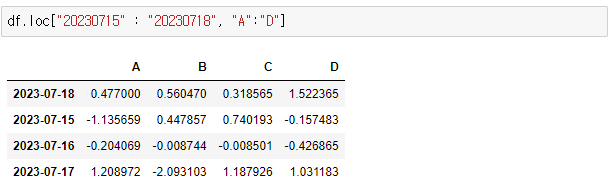
- iloc
- 컴퓨터가 인식하는 인덱스 값으로 선택
> df.iloc[3]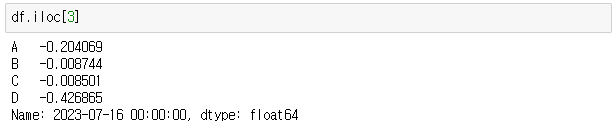
> df.iloc[3,:]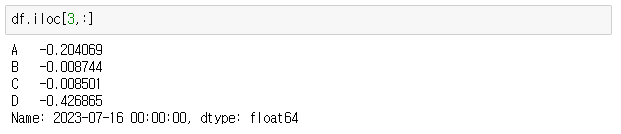
> df.iloc[3:5,0:2]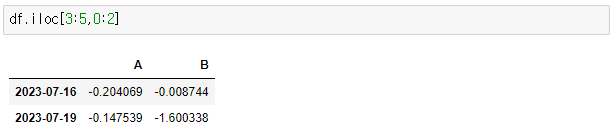
> df.iloc[[1,2,4],[0,2]]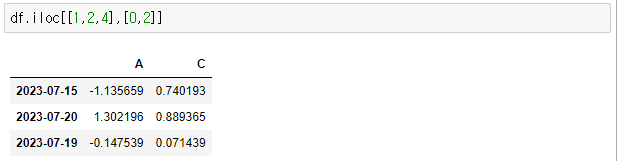
- condition
- 특정 조건에 해당하는 data만 선택 가능
> df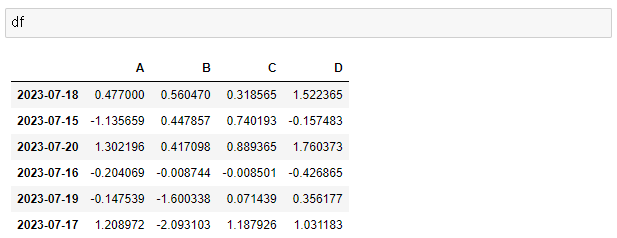
# A 컬럼에서 0보다 큰 숫자(양수)만 선택
> df["A"] > 0
> df[df["A"] > 0]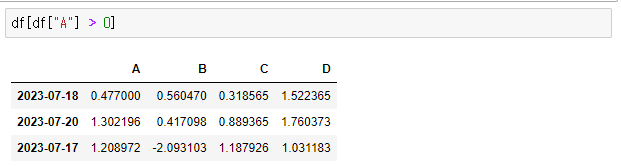
> df[df>0]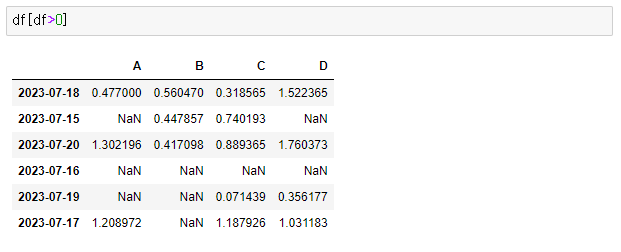

데이터 관련 학습 일지