위키백과 문서 가져오기
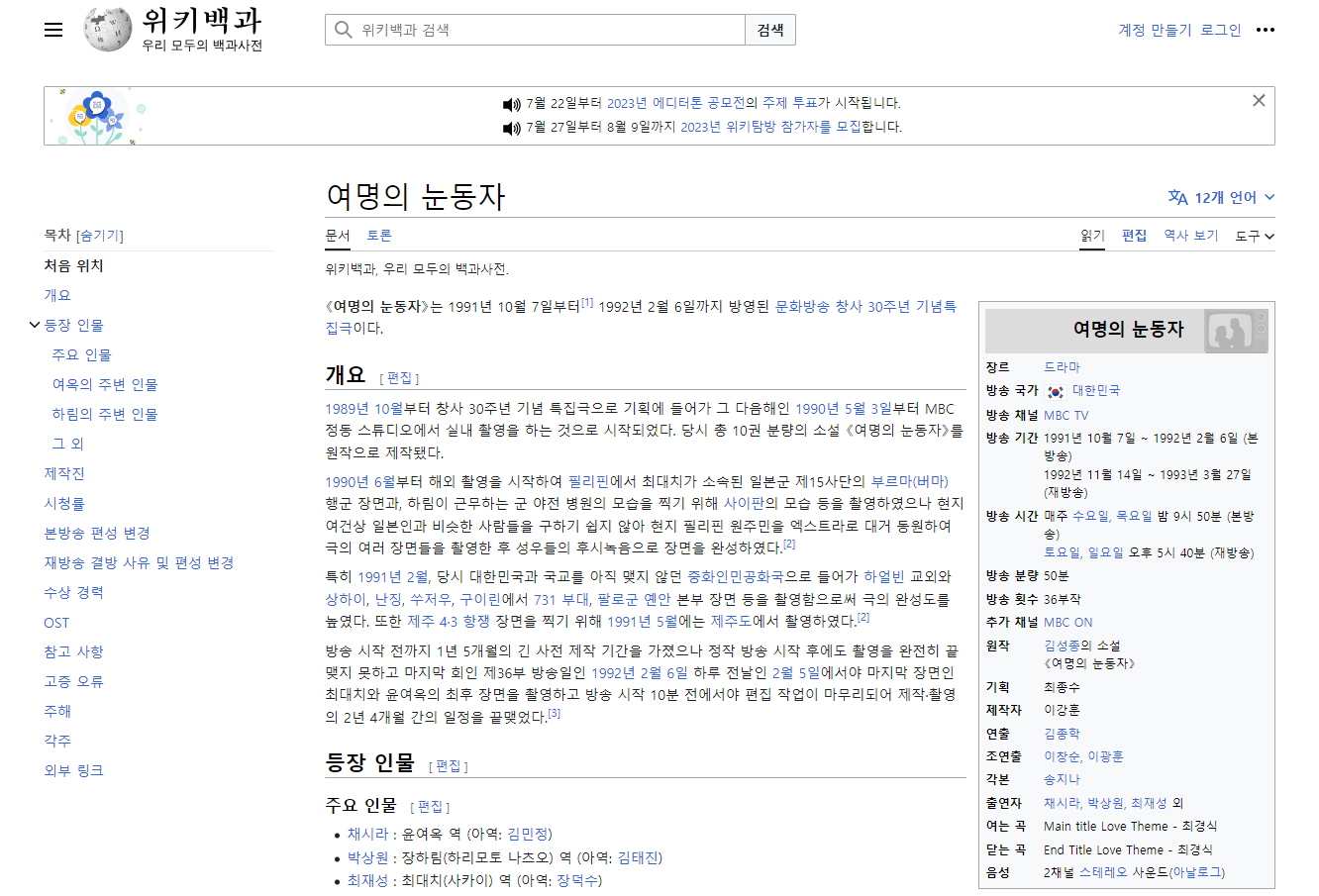
- 검색한 드라마의 주요인물 이름을 뽑아보자 !
- 그리고 주소를 복사할 때 맨 끝의 '여명의 눈동자' 부분의 인코딩이 깨져서 복사된다.
import urllib
from urllib.request import urlopen, Request
# https://ko.wikipedia.org/wiki/여명의_눈동자
html = "https://ko.wikipedia.org/wiki/{search_words}"
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자")))
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())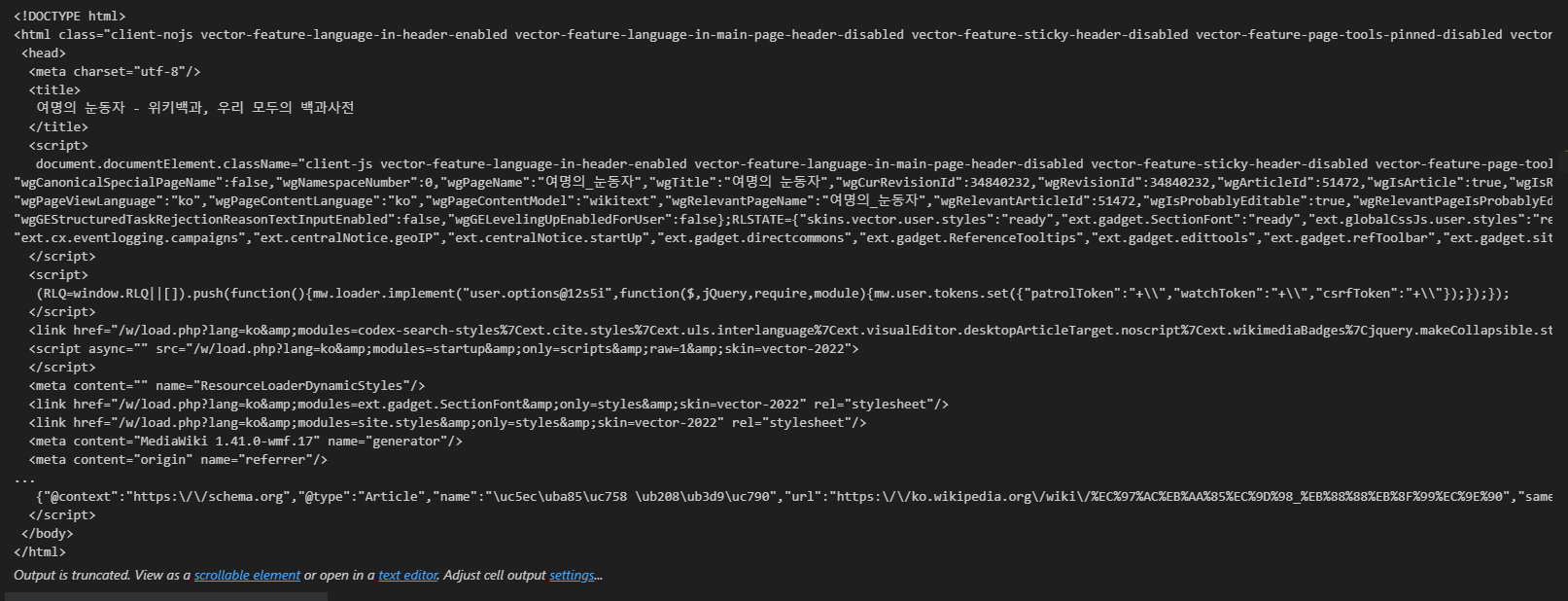
n = 0
for each in soup.find_all("ul"):
print("=>" + str(n) + "========================")
print(each.get_text())
n += 1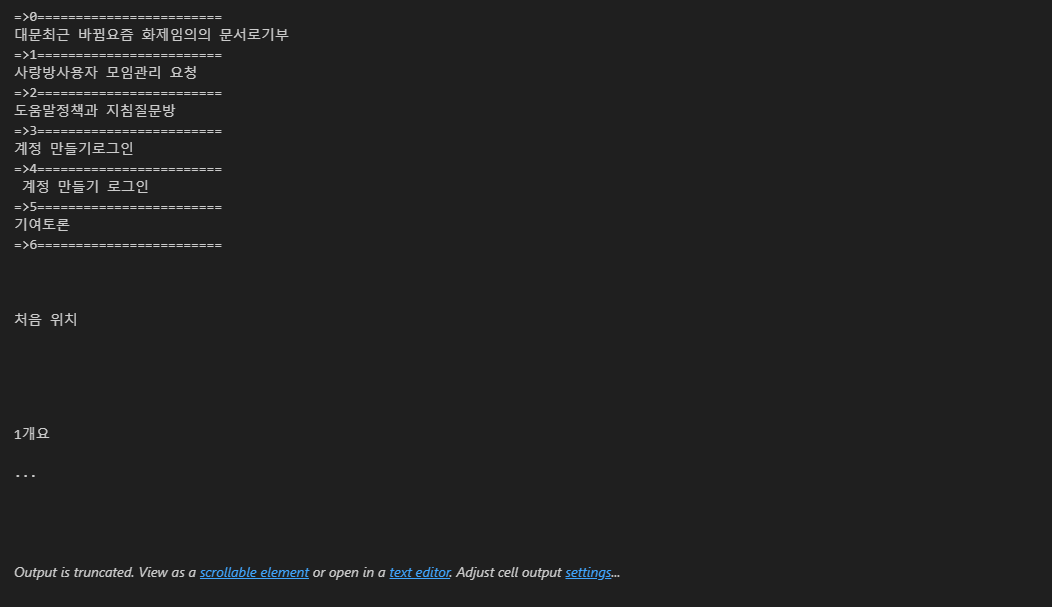
32번째 줄에 원하는 정보가 있다.
soup.find_all("ul")[32].text
# 예쁘게 정리
soup.find_all("ul")[32].text.strip().replace("\xa0", "").replace("\n", "")

데이터 관련 학습 일지