
추천 시스템 방식
- Contents Based Filtering
- 컨텐츠의 요소들을 기반으로 개인의 취향을 매칭
- Collaborative Filtering
- 성향이 비슷한 다른 사람들의 선택을 기반으로 매칭
- Hybrid(Contents Based + Collaborative Filtering)
컨텐츠 기반 필터링
(Contents Based Filtering)
감독, 배우, 영화 설명, 장르 등 영화를 구성하는 다양한 컨텐츠들을 텍스트 기반 문서 유사도로 비교하여 추진함
- 컨텐츠에 대한 텍스트 정보들을 피처 벡터화
- 코사인 유사도로 컨텐츠별 유사도 계산
- 컨텐츠 별로 가중 평점을 계산
- 유사도가 높은 컨텐츠 중에 평점이 좋은 컨텐츠 순으로 추천
TMDB 5000 Movie Dataset
1. 컨텐츠에 대한 텍스트 정보들을 피처 벡터화
🔔
ast
Abstract Syntax Trees의 약자인데 말 그대로 문자를 자동으로 parsing해서 파이썬 문법에 맞는 구조로 구조화(객체화)해줍니다. Tree형의 자료구조이며, 각각의 노드를 갖게 됩니다.
실제로 1.2 + 3.4의 AST를 뜯어보면 다음과 같습니다.> import python > ast.dump(ast.parse('1.2 + 3.4')) Module(body=[Expr(value=BinOp(left=Num(n=1.2), op=Add(), right=Num(n=3.4)))])🔔
ast.literal_eval
eval함수와 비슷하게 문자그대로(literal) 계산을 실행해주는 함수입니다. eval함수와 다른 점은 파이썬 문법에 맞지 않으면 함수를 실행하지 않는 다는 것입니다. 따라서, 둘 중에 사용을 고민한다면literal_eval을 사용한 것이 더 안전합니다.
그 이유는, eval 함수를 사용한 프로그램을 배포하면 사용자가 의도적으로 틀린 파이썬 문법을 사용하여 공격할 수 있기 때문입니다.
import pandas as pd
import numpy as np
import warnings; warnings.filterwarnings('ignore')
movies =pd.read_csv('./tmdb_5000_movies.csv')
movies_df = movies[['id','title', 'genres', 'vote_average', 'vote_count',
'popularity', 'keywords', 'overview']]
pd.set_option('max_colwidth', 100)
movies_df[['genres']][:1]genres
[{"id": 28, "name": "Action"}, {"id": 12, "name": "Adventure"}, {"id": 14, "name": "Fantasy"}, {... 텍스트 문서 1차 가공, 파이썬 딕셔너리 변환 후 리스트 형태로 변환
from ast import literal_eval
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
print(movies_df['genres'].head(1))
movies_df['genres'] = movies_df['genres'].apply(lambda x : [ y['name'] for y in x])
print(movies_df[['genres']][:1])0 [{'id': 28, 'name': 'Action'}, {'id': 12, 'name': 'Adventure'}, {'id': 14, 'name': 'Fantasy'}, {...
Name: genres, dtype: object
genres
[Action, Adventure, Fantasy, Science Fiction]2. 코사인 유사도로 컨텐츠별 유사도 계산
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer를 적용하기 위해 공백문자로 word 단위가 구분되는 문자열로 변환.
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x : (' ').join(x))
count_vect = CountVectorizer(min_df=0, ngram_range=(1,2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)
# 유사도가 높은 영화의 index를 얻음
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
print(genre_sim_sorted_ind[:1])유사도가 높은 순으로 영화의 index를 추출
[[ 0 3494 813 ... 3038 3037 2401]]특정 영화와 장르별 유사도가 높은 영화를 반환하는 함수 생성
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
# 인자로 입력된 movies_df DataFrame에서 'title' 컬럼이 입력된 title_name 값인 DataFrame추출
title_movie = df[df['title'] == title_name]
# title_named을 가진 DataFrame의 index 객체를 ndarray로 반환하고
# sorted_ind 인자로 입력된 genre_sim_sorted_ind 객체에서 유사도 순으로 top_n 개의 index 추출
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n)]
# 추출된 top_n index들 출력. top_n index는 2차원 데이터 임.
#dataframe에서 index로 사용하기 위해서 1차원 array로 변경
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average']] title vote_average
2731 The Godfather: Part II 8.3
1243 Mean Streets 7.2
3636 Light Sleeper 5.7
1946 The Bad Lieutenant: Port of Call - New Orleans 6.0
2640 Things to Do in Denver When You're Dead 6.7
4065 Mi America 0.0
1847 GoodFellas 8.2
4217 Kids 6.8
883 Catch Me If You Can 7.7
3866 City of God 8.13. 가중 평점(Weighted Rating) 계산
- v: 개별 영화에 평점을 투표한 횟수
- m: 평점을 부여하기 위한 최소 투표 횟수
- R: 개별 영화에 대한 평균 평점.
- C: 전체 영화에 대한 평균 평점
C = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
def weighted_vote_average(record):
v = record['vote_count']
R = record['vote_average']
return ( (v/(v+m)) * R ) + ( (m/(m+v)) * C )
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1) 4. 유사도가 높은 컨텐츠 중, 평점이 좋은 컨텐츠 순으로 추천
앞의 find_sim_movie함수를 수정
후보군을 더 많이(2배) 뽑고 (가중)평점 순으로 top_n만큼 선택
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
# top_n의 2배에 해당하는 쟝르 유사성이 높은 index 추출
similar_indexes = sorted_ind[title_index, :(top_n*2)]
similar_indexes = similar_indexes.reshape(-1)
# 기준 영화 index는 제외
similar_indexes = similar_indexes[similar_indexes != title_index]
# top_n의 2배에 해당하는 후보군에서 weighted_vote 높은 순으로 top_n 만큼 추출
return df.iloc[similar_indexes].sort_values('weighted_vote', ascending=False)[:top_n]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average', 'weighted_vote']] title vote_average weighted_vote
2731 The Godfather: Part II 8.3 8.079586
1847 GoodFellas 8.2 7.976937
3866 City of God 8.1 7.759693
1663 Once Upon a Time in America 8.2 7.657811
883 Catch Me If You Can 7.7 7.557097
281 American Gangster 7.4 7.141396
4041 This Is England 7.4 6.739664
1149 American Hustle 6.8 6.717525
1243 Mean Streets 7.2 6.626569
2839 Rounders 6.9 6.530427협업 필터링(Collaborative Filtering)
취향이 비슷한 친구에게 물어보자!
-
최근접 이웃 기반(Nearst Neighbor), 일반적으로 아이템 기반이 선호됨
- 사용자 기반
- 특정 사용자와 비슷한 고객들을 기반으로 비슷한 고객들이 선호하는 다른 상품을 추천
- 비슷한 상품을 구매해온 고객들은 비슷한 고객으로 간주
당신과 비슷한 고객들이 이 상품도 구매했습니다!
- 아이템 기반
- 특정 상품과 유사한 좋은 평가를 받은 다른 비슷한 상품을 추천
- 사용자들로부터 특정 상품과 비슷한 평가를 받은 상품들은 비슷한 상품으로 간주
이 상품을 선택한 다른 고객들은 다음 상품도 구매했습니다!
- 사용자 기반
-
잠재 요인 기반(Latent Factor)
- 행렬 분해 기반 (ex. SVD)
- User Behavior에만 기반하여 추천
- 상품, 영화 등 사용자가 아직 평가하지 않은 item에 대한 평가를 예측하는 것이 중요한 문제
- 사용자 - 아이템 평점 데이터 행렬 형태가 필요(희소 행렬)
- 사용자 기반 :사용자(행) X 아이템(열)
- 아이템 기반 :아이템(행) X 사용자(열)
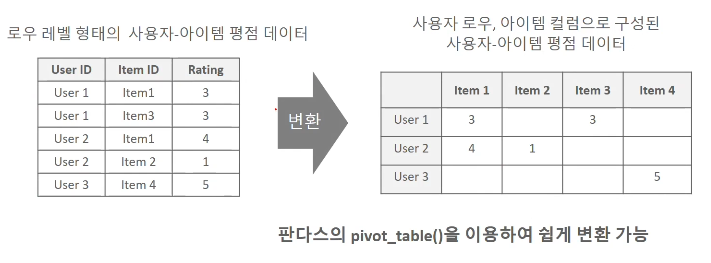
아이템 기반 협업 필터링
- 사용자-아이템 행렬 데이터를 아이템-사용자 행렬 데이터로 변환
- 아이템간의 코사인 유사도로 아이템 유사도 산출
- 사용자가 관람하지 않은 아이템들 중에서 아이템간 유사도를 반영한 예측 점수 계산
- 예측 점수가 가장 높은 순으로 아이템 추천
Weighted Rating Sum
- : 사용자 u, 아이템 i의 개인화된 예측 평점 값
- : 아이템 i와 가장 유사도가 높은 Top-N개 아이템의 유사도 벡터
- : 사용자 u의 아이템 i와 가장 유사도가 높은 TOP-N개 아이템에 대한 실제 평점 벡터
MovieLens Latest Dataset
1. 아이템-사용자 행렬 데이터
import pandas as pd
import numpy as np
movies = pd.read_csv('./ml-latest-small/movies.csv')
ratings = pd.read_csv('./ml-latest-small/ratings.csv')
#로우레벨 사용자 평점 데이터를 사용자-아이템 평점 행렬로 변환
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
# columns='title' 로 title 컬럼으로 pivot 수행.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# NaN 값을 모두 0 으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix_T = ratings_matrix.transpose()
print(ratings_matrix_T.shape)(9719, 610)2. 영화들 간 유사도 산출
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
# cosine_similarity() 로 반환된 넘파이 행렬을 영화명을 매핑하여 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns,
columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df["Inception (2010)"].sort_values(ascending=False)[1:6](9719, 9719)
title
Dark Knight, The (2008) 0.727263
Inglourious Basterds (2009) 0.646103
Shutter Island (2010) 0.617736
Dark Knight Rises, The (2012) 0.617504
Fight Club (1999) 0.615417
Name: Inception (2010), dtype: float643. 아이템 기반 인접 이웃 협업 필터링으로 개인화된 영화 추천(가중 평점합 기반)
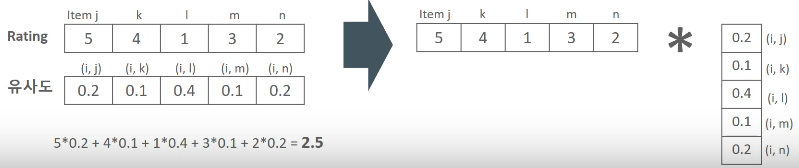
# Weighted Rating Sum(행렬 연산, 내적)
def predict_rating(ratings_arr, item_sim_arr ):
ratings_pred = ratings_arr.dot(item_sim_arr)/ np.array([np.abs(item_sim_arr).sum(axis=1)])
return ratings_pred
ratings_pred = predict_rating(ratings_matrix.values , item_sim_df.values)
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)
print(ratings_pred_matrix.shape)(610, 9719)top-n 유사도를 가진 데이터들에 대해서 예측 평점 계산
def predict_rating_topsim(ratings_arr, item_sim_arr, n=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기만큼 Loop 수행.
for col in range(ratings_arr.shape[1]):
# 유사도 행렬에서 유사도가 큰 순으로 n개 데이터 행렬의 index 반환
top_n_items = [np.argsort(item_sim_arr[:, col])[:-n-1:-1]]
# 개인화된 예측 평점을 계산
for row in range(ratings_arr.shape[0]):
pred[row, col] = item_sim_arr[col, :][top_n_items].dot(ratings_arr[row, :][top_n_items].T)
pred[row, col] /= np.sum(np.abs(item_sim_arr[col, :][top_n_items]))
return pred
ratings_pred = predict_rating_topsim(ratings_matrix.values , item_sim_df.values, n=20)
user_rating_id = ratings_matrix.loc[9, :]
user_rating_id[ user_rating_id > 0].sort_values(ascending=False)[:10]title
Adaptation (2002) 5.0
Austin Powers in Goldmember (2002) 5.0
Lord of the Rings: The Fellowship of the Ring, The (2001) 5.0
Lord of the Rings: The Two Towers, The (2002) 5.0
Producers, The (1968) 5.0
Citizen Kane (1941) 5.0
Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981) 5.0
Back to the Future (1985) 5.0
Glengarry Glen Ross (1992) 4.0
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.0
Name: 9, dtype: float64사용자가 관람하지 않은 영화 중에서 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list4. 사용자가 관람하지 않은 영화들 중 예측 평점이 가장 높은 영화를 추천
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies pred_score
title
Shrek (2001) 0.866202
Spider-Man (2002) 0.857854
Last Samurai, The (2003) 0.817473
Indiana Jones and the Temple of Doom (1984) 0.816626
Matrix Reloaded, The (2003) 0.800990
Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001) 0.765159
Gladiator (2000) 0.740956
Matrix, The (1999) 0.732693
Pirates of the Caribbean: The Curse of the Black Pearl (2003) 0.689591
Lord of the Rings: The Return of the King, The (2003) 0.676711잠재 요인 협업 필터링
- 사용자-아이템 평점 행렬 속에 숨어 있는 잠재 요인을 추출해 추천
- 대규모 다차원 (희소) 행렬을 SVD 같은 행렬 분해를 통해 잠재 요인을 추출하는데, 이 잠재 요인을 기반으로 평점 행렬을 재구성하면서 추천을 구현합니다.
- 잠재 요인이 무엇이라고 정확히 특정짓기는 매우 어렵다.
- 사용자 레벨의 잠재요인 ~ 아이템 레벨의 잠재요인
- 목표는 희소 행렬 형태의 사용자-아이템 평점 행렬을 밀집 행렬 형태의 _사용자-잠재요인 행렬과 잠재 요인-아이템 행렬로 분해해서 이를 밀집 형태의 사용자-아이템 평점 행렬을 생성해 추천에 사용하는 것
= (사용자-잠재요인 행렬)*(잠재요인 - 아이템 행렬)'

Singular Value Decomposition(SVD)
- Factor의 개수 K는 분석가가 정해주어야함
- P의 개별 행은 개별 사용자에 대한 잠재요인을 반영
- Q의 개별 열은 개별 아이템에 대한 잠재요인을 반영
아직 사용자가 평점을 매개지 않은 아이템 [i, j]에 대한 예측평점
= (P의 i 행 벡터)*(Q의 j열 벡터)'
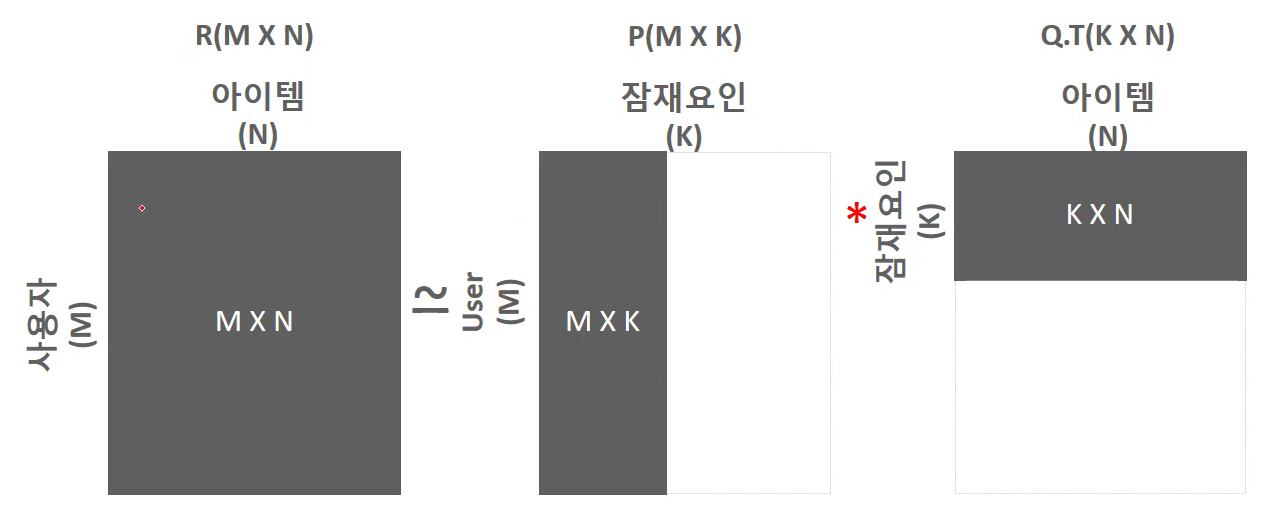
행렬 분해 이슈
- SVD는 결측값이 없는 행렬에 적용 가능함, 일반적인 SVD방식으로 분해 불가
경사하강법을 이용해 P와 Q에 기반한 예측 R값이 실제 R값과 가장 최소의 오차를 가질 수 있도록 비용함수 최적화를 통해 P와 Q 최적화
- P와 Q를 임의의 값을 가진 행렬로 설정
- P와 Q를 곱해 예측 R 행렬을 계산하고 실제 R 행렬에 해당하는 오류값 계산
- 이 오류값이 적절히 최소화할 수 있도록 업데이트
(실제값과 예측값의 오류 최소화) + (과적합 개선을 위한 L2 규제)
경사하강을 이용한 행렬 분해 예제
원본 행렬 R 및 R을 분해할 P와 Q를 임의의 정규분포를 가진 랜덤값으로 초기화
import numpy as np
# 원본 행렬 R 생성, 분해 행렬 P와 Q 초기화, 잠재요인 차원 K는 3 설정.
R = np.array([[4, np.NaN, np.NaN, 2, np.NaN ],
[np.NaN, 5, np.NaN, 3, 1 ],
[np.NaN, np.NaN, 3, 4, 4 ],
[5, 2, 1, 2, np.NaN ]])
num_users, num_items = R.shape
K=3
# P와 Q 매트릭스의 크기를 지정하고 정규분포를 가진 random한 값으로 입력합니다.
np.random.seed(1)
P = np.random.normal(scale=1./K, size=(num_users, K))
Q = np.random.normal(scale=1./K, size=(num_items, K))비용계산 함수를 생성. 분해된 행렬 P와 Q.T를 내적하여 예측 행렬 생성하고 실제 행렬에서 널이 아닌 값의 위치에 있는 값만 예측 행렬의 값과 비교하여 RMSE값을 계산하고 반환
from sklearn.metrics import mean_squared_error
def get_rmse(R, P, Q, non_zeros):
error = 0
# 두개의 분해된 행렬 P와 Q.T의 내적으로 예측 R 행렬 생성
full_pred_matrix = np.dot(P, Q.T)
# 실제 R 행렬에서 널이 아닌 값의 위치 인덱스 추출하여 실제 R 행렬과 예측 행렬의 RMSE 추출
x_non_zero_ind = [non_zero[0] for non_zero in non_zeros]
y_non_zero_ind = [non_zero[1] for non_zero in non_zeros]
R_non_zeros = R[x_non_zero_ind, y_non_zero_ind]
full_pred_matrix_non_zeros = full_pred_matrix[x_non_zero_ind, y_non_zero_ind]
mse = mean_squared_error(R_non_zeros, full_pred_matrix_non_zeros)
rmse = np.sqrt(mse)
return rmse경사하강법에 기반하여 P와 Q의 원소들을 업데이트 수행
# R > 0 인 행 위치, 열 위치, 값을 non_zeros 리스트에 저장.
non_zeros = [ (i, j, R[i,j]) for i in range(num_users) for j in range(num_items) if R[i,j] > 0 ]
steps=1000
learning_rate=0.01
r_lambda=0.01
# SGD 기법으로 P와 Q 매트릭스를 계속 업데이트.
for step in range(steps):
for i, j, r in non_zeros:
# 실제 값과 예측 값의 차이인 오류 값 구함
eij = r - np.dot(P[i, :], Q[j, :].T)
# Regularization을 반영한 SGD 업데이트 공식 적용
P[i,:] = P[i,:] + learning_rate*(eij * Q[j, :] - r_lambda*P[i,:])
Q[j,:] = Q[j,:] + learning_rate*(eij * P[i, :] - r_lambda*Q[j,:])
rmse = get_rmse(R, P, Q, non_zeros)
if (step % 250) == 0 :
print("### iteration step : ", step," rmse : ", rmse)### iteration step : 0 rmse : 3.2388050277987723
### iteration step : 250 rmse : 0.029248328780879088
### iteration step : 500 rmse : 0.01697365788757103
### iteration step : 750 rmse : 0.01657420047570466pred_matrix = np.dot(P, Q.T)
print('예측 행렬:\n', np.round(pred_matrix, 3))예측 행렬:
[[3.991 0.897 1.306 2.002 1.663]
[6.696 4.978 0.979 2.981 1.003]
[6.677 0.391 2.987 3.977 3.986]
[4.968 2.005 1.006 2.017 1.14 ]]파이썬 추천 패키지 Surprise
! 주의할 점
Input 데이터의 형식이 정해져 있습니다.
user_id(1열), item_id(2열), rating(3열) 열들이 사용자를 기준으로 한 row레벨의 평점 데이터 세트만 입력 가능(네 번째 열 이후부터는 아에 사용하지않음)
test() : 사이킷런의 predict()와 같습니다.
predict() : 개별 사용자 한명에 대한 예측(전체X)
Reader클래스로 파일의 포맷팅 지정하고 Dataset의 load_from_file()을 이용하여 데이터셋 로딩
from surprise import accuracy
from surprise.model_selection import train_test_split
from surprise import Reader
reader = Reader(line_format='user item rating timestamp', sep=',', rating_scale=(0.5, 5))
data=Dataset.load_from_file('./ml-latest-small/ratings_noh.csv',reader=reader)학습과 테스트 데이터 세트로 분할하고 SVD로 학습후 테스트데이터 평점 예측 후 RMSE평가
trainset, testset = train_test_split(data, test_size=.25, random_state=0)
# 수행시마다 동일한 결과 도출을 위해 random_state 설정
# SVD 학습은 TrainSet 클래스를 이용해야 함
algo = SVD(n_factors=50, random_state=0)
# 학습 데이터 세트로 학습 후 테스트 데이터 세트로 평점 예측 후 RMSE 평가
algo.fit(trainset)
predictions = algo.test( testset )
accuracy.rmse(predictions)
# Cross-Validation
from surprise.model_selection import cross_validate
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
# GridSearchCV
from surprise.model_selection import GridSearchCV
# 최적화할 파라미터들을 딕셔너리 형태로 지정.
param_grid = {'n_epochs': [20, 40, 60], 'n_factors': [50, 100, 200] }
# CV를 3개 폴드 세트로 지정, 성능 평가는 rmse, mse 로 수행 하도록 GridSearchCV 구성
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3)
gs.fit(data)