P Stage가 시작되었다. 5주차는 스스로 정리된 것이 많지 않아서 학습 정리로 표현하지 못했는데 6주차도 실습에 뛰어들다보니 금요일이 되서야 기본적인 부분이 정리되어 이렇게 한 주를 마무리하는 방식으로 진행하게 되었다. P Stage가 진행되는 이번 주는 강의와 미션과 함께 마스크에 착용 상태에 따른 분류가 주제인 Classification 대회가 시작되었다.
문제 정의
해결해야할 문제는 성별, 나이, 마스크 착용 상태에 따른 18가지 클래스로 분류하는 문제이다.
EDA
주어진 데이터를 분석해보았을 때 발견한 특징들이 있다.
- 데이터의 RGB 평균 및 표준편차가 ImageNet과는 조금 다른 경향이 있는 것 같다
- 성별을 기준으로 여성의 비율이 더 많다
- 나이의 범위는 동일하지만 평균 나이가 여성은 중년층, 남성은 청년층이 많다
- 마스크를 올바르게 착용한 데이터가 이외에 데이터보다 수가 많다
- 올바른 착용 : 이상한 착용 : 미착용 = 5 : 1 : 1
- 남성이지만 여성으로, 여성이지만 남성으로 라벨이 오표기된 경우들이 존재한다
- 마스크 착용 상태 오표기 등도 존재
- 전체 클래스 개수가 imbalance 하다
크게 6가지의 특징들을 발견하였고 우선 데이터를 클래스에 맞게 분류한 뒤 훈련을 진행하기로 계획했다. 모델은 pretrain을 사용하는데 classifier를 교체하고 fine-tuning할 계획이며 아키텍처는 효율적인 구조로도 준수한 성능을 보여준 EfficientNet으로 선정했다.
- Feature Extraction: freeze + (classifier train)
- Fine-tuning: (backbone + classifier train)
Dataset Class & Project Template
우선적으로 Custom Dataset class를 구현하고자 했다. 이 과정에서 데이터와 label을 어떻게 매칭시킬까를 많이 고민했던 것 같다. 결과적으로는 데이터 정보가 담겨있는 raw 파일에 label을 추가한 뒤 읽어들이는 방법을 취했다.
- 파일에 label을 추가하는 과정이 번거로울 순 있지만 Dataset class 안에서 코드 구현이 덜 복잡하고 편하지 않을까 하는 생각이었던 거 같다
코드를 작성하면서 프로젝트 템플릿 혹은 구조에 대해서 고민이 많았고 기능별로 정리가 잘 되어있으면 좋겠다는 생각에 다음과 같이 설계를 하여 진행하고 있는데 세부적인 구현 측면에서 감이 잡히지 않는 부분들은 baseline를 참고하여 구성했다.
- 구조는 대회를 진행하면서 추가 혹은 변경될 수 있다
|-- Dataset
| |-- Dataset.py
| `-- ...
|-- Modules
| |-- EfficientNet.py
| |-- loss.py
| `-- ...
|-- EDA
| |-- data_visualizaion.py
| `-- ...
|-- utils
| |-- model_manage.py
| |-- data_add_label.py
| `-- ...
|-- logger
| |-- tensorboard.py
| |-- wandb.py
| `-- ...
|-- runs
| |-- log...
| `-- ...
|-- train.py
|-- trainer.py
|-- inference.py
|-- inference_val.py
|-- ...loss function
적용하고자 하는 손실 함수에 대해서도 고민을 하게 되었다. 큰 이유는 데이터가 imbalance 하기 때문에 일반적으로 사용되는 CrossEntropy가 아닌 개선된 loss function을 사용하면 좋을 거 같다는 생각이었다.
- 클래스간 예측 난이도가 상이할 거 같고 개수가 많이 다른데 CrossEntropy는 잘 예측하였을 경우에 보상이 없고 데이터 개수에 상관없이 같은 비율로 loss를 업데이트하는 것으로 학습하여 다른 방법도 고민해보았다
클래스 간 비율이 다른 점에 대한 문제를 보완하기 위한 Balanced CrossEntropy가 존재하는 것을 발견했다. '' 와 같이 loss 비율을 조절하는 weight를 곱해줌으로써 class imbalance 문제를 개선하고자 한 방법이다.
- class 갯수가 많으면 weight을 크게, 적으면 weight을 작게만 적용하는 방법이므로 easy/hard example을 구분할 수 없다는 한계가 있다고 한다
이보다 더 개선된 loss로 Object Detection 네트워크인 RetinaNet에서 제안된 Focal loss가 있다. 수식을 먼저 살펴보면 다음과 같다.
CrossEntropy에서 Loss에 곱해지는 항이 추가되었는데 의 값을 잘 조절해야 좋은 성능을 얻을 수 있다고 한다. 제안된 논문에서는 를 사용하였다.
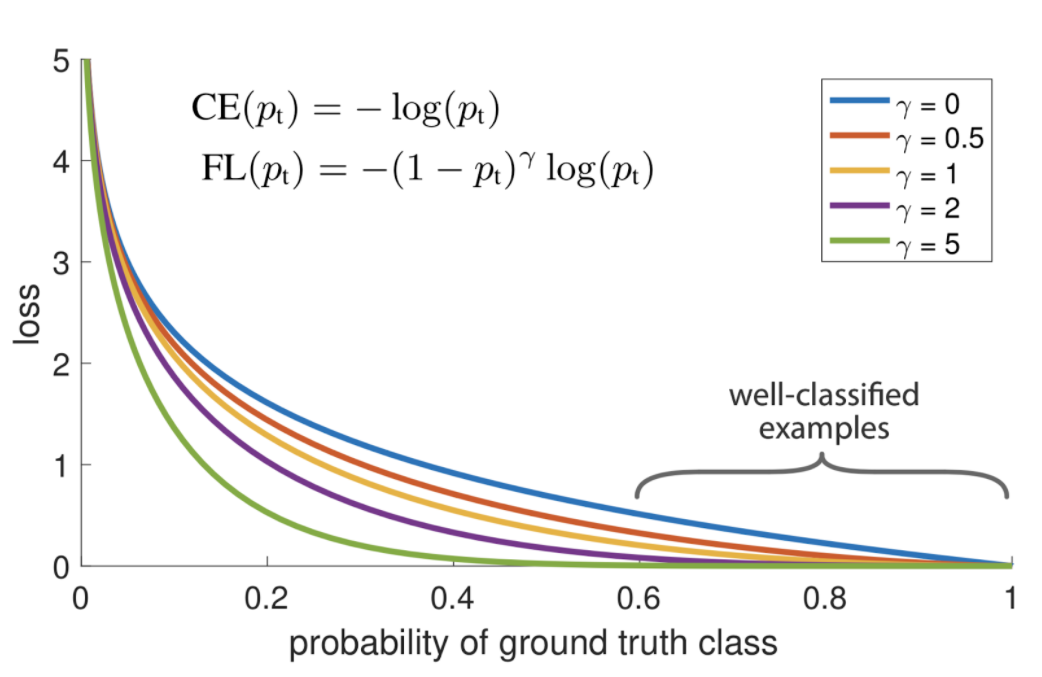
Reference: https://gaussian37.github.io/dl-concept-focal_loss/
결론으로 loss function은 CE, Balanced CE, label smoothing, Focal loss에 대한 비교 실험을 통해 선정하고자 했다.
Experiments
각 실험에 대한 logging은 wandb를 통해 진행했다.
- 실험 log와 학습 파라미터 등을 같이 비교해볼 수 있어 편했다
우선 loss 이외에 다른 변수들은 동일하게 하여 실험을 진행했고 focal loss를 사용했을 때 결과가 가장 좋았다. 기본적으로 데이터 개수가 많이 적어 imbalance한 문제를 다른 function들에 비해 보완이 잘 된다고 판단해 loss로는 focal loss를 사용하고 다른 변수들을 변경해보며 실험을 진행했다.
이미지 해상도는 원본 크기를 사용하거나 비율에 맞춰 작게 resize 해보며 3가지 경우에 대해 진행 해보았는데 성능은 유사했다. 추가적으로 CenterCrop을 사용하거나 배경을 제거하는 등 배경적인 요소를 줄이고 인물 위주로 학습하도록 다른 방법들도 적용해볼 계획이다.
전반적으로 학습 수렴 속도는 굉장히 빨랐는데 f1-score을 바탕으로 validation 기준으로도 예측을 잘 한다고 생각했고 어떤 경우를 잘못 예측하는지 분석해보기 위해 CM(Confusion Matrix)을 사용했다.

CM을 살펴본 결과 성별과 마스크 착용 여부에 대해서는 높은 확률로 올바르게 예측을 하지만 나이에 대해 많이 어려워한다고 생각했다.
- 이에 대해 다른 팀원이 각 특징을 분류해 multi-tasking으로 학습해보았을 때 다른 특징들에 비해 나이를 비교적 예측을 못하는 경향이 있다는 결과를 공유해주었다
팀원들과 분업하고자 추후 실험으로는 나이와 성별은 어느 정도 상관관계가 있을 것으로 판단해 결합하여 예측하고 마스크 착용 여부는 따로 예측하도록 2가지에 대한 multi-tasking을 진행해보려고 한다. K-Fold도 적용해보고 피부나 얼굴을 선명하게 하면 나이 예측에 효과가 있을까 하여 음영을 조절해보는 방법 등도 실험해볼 계획이다.
회고
- 대회가 진행되다보니 팀원들과 문제에 더욱 집중해서 학습하고 시도해본 거 같다
- 문제를 해결하기 위해 여러 가설을 세우고 단계별로 검증해보며 실험을 진행했고 결과를 분석해보며 다양한 경험을 얻을 수 있었다
- 구현적인 부분에서 생각 못했던 부분을 baseline을 보고 해결하는 방법을 고민할 수 있었고 배운 점이 많았다
- 이번 주는 특히 시간이 빠르게 지나간 거 같고 대회가 종료되는 날까지 잘 달려보는 것이 목표다
