부스트캠프 AI Tech
1.[U] Week 1 - 벡터(Vector)

숫자를 원소로 가지는 리스트(list) 혹은 배열(array)공간에서 한 점을 나타내고 원점으로부터 상대적 위치를 표현한다. (1차원, 2차원, 3차원 ...)벡터에 숫자를 곱해주면(스칼라 곱) 길이만 변한다. (음수를 곱하면 방향이 반대로)벡터끼리 같은 모양을 가지면
2.[U] Week 1 - 행렬
행렬은 벡터를 원소로 가지는 2차원 배열.numpy에서는 행(row)이 기본 단위.
3.[U] Week 1 - 경사하강법
미분은 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구로 최적화에서 제일 많이 사용하는 기법.미분은 함수 f의 주어진 점 (x, f(x))에서의 접선의 기울기를 구한다.한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가하는지/감소하는지
4.[U] Week 1 - 딥러닝 학습방법
분류와 같은 복잡한 문제를 해결할 때는 기본적으로 선형 모델이 아닌 비선형 모델이다.소프트맥스(Softmax) 함수는 모델의 출력을 지수함수를 통해 확률로 해석할 수 있게 변환해주는 연산이다.분류(Classification) 문제를 해결할 때 선형모델과 소프트맥스 함수
5.[U] Week 1 - 확률론
딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고 있다.기계학습에서 사용되는 손실함수(loss function)들의 작동 원리는 데이터 공간을 통계적으로 해석해서 유도하게 된다.예측이 틀릴 위험을 최소화하도록 데이터를 학습하는 원리는 통계적 기계학습의 기본 원리이다.
6.[U] Week 1 - 통계학
통계적 모델링은 적절한 가정 위에서 확률분포를 추정(Inference)하는 것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표이다.유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정할 수 밖에 없다
7.[U] Week 1 - 베이즈 통계학
조건부확률 P(A|B)는 사건 B가 일어난 상황에서 사건 A가 발생할 확률을 의미한다.베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려준다.A라는 새로운 정보가 주어졌을 때 P(B)로부터 P(A|B)를 계산하는 방법을 제공한다.Evidence: 데이터 자
8.[U] Week 1 - CNN 첫걸음
Convolution 연산은 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조이다. Convolution 연산의 수학적인 의미는 신호(signal)를 커널을 이용해 국소적으로 증폭 또는 감소시켜 정보를 추출 또는 필터링하는 것이다.C
9.[U] Week 1 - RNN 첫걸음
독립적으로 들어오는 데이터가 아닌 시계열과 같이 시퀀스 형태의 데이터를 다루기 위한 네트워크.순차적으로 구성된 시계열(time-series), 소리, 문자열, 주가 등의 데이터를 시퀀스(sequence) 데이터로 분류한다.시퀀스 데이터는 독립동등분포(i.i.d.) 가정
10.[U] Week 2 - PyTorch
Facebook 인공지능 연구팀이 개발한 Deep learning framework으로 다음과 같은 특징을 가진다.Numpy 구조를 가지는 Tensor 객체로 array를 표현자동미분을 지원하여 DL 연산을 지원다양한 형태의 DL을 지원하는 함수와 모델을 지원연산의 과
11.[U] Week 2 - AutoGrad & Optimizer
딥러닝을 구성하는 Layer의 base class.Input, Output, Forward, Backward 정의학습의 대상이 되는 parameter(tensor) 정의Tensor 객체의 상속 객체nn.Module 내에 attribute가 될 때는 reqired_gra
12.[U] Week 2 - Dataset & DataLoader
데이터 입력 형태를 정의하는 클래스데이터를 입력하는 방식의 표준화Image, Text, Audio 등에 따라 다른 입력 정의Dataset 클래스 생성시 유의점데이터 형태에 따라 각 함수를 다르게 정의모든 것을 데이터 생성 시점에 처리할 필요는 없음image의 Tenso
13.[U] Week 2 - Model Loading
모델 훈련 시 예외상황을 방지하거나 최선의 결과를 보존하기 위해 중간중간 혹은 종료된 뒤 학습 결과를 저장 및 로드할 필요가 있다.학습의 결과를 저장하기 위한 함수모델 형태(architecture)와 파라미터를 저장모델 학습 중간 과정의 저장을 통해 최선의 결과모델을
14.[U] Week 2 - Monitoring tools
TensorFlow의 프로젝트로 만들어진 시각화 도구이다.학습 그래프, metric, 학습 결과의 시각화 지원PyTorch도 연결 가능DL 시각화 기본 도구scalar: metric 등 상수 값의 연속(epoch)을 표시graph: 모델의 computational gr
15.[U] Week 2 - Multi GPU
다중 GPU에 학습을 분산하는 두 가지 방법으로 모델을 나누는 것과 데이터를 나누는 방법이 있다.모델을 나누는 것은 alexnet에서 사용한 것처럼 생각보다 예전보다 썼다모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제이다데이터를 나누는 것은
16.[U] Week 3 - Optimization
일반적으로 train error와 test error의 차이를 말한다.학습 데이터 및 테스트 데이터에서 유사한 성능이 나오는 것이 좋다학습 데이터에 대해서 잘 동작을 하지만 테스트 데이터에서는 그렇지 않은 경우를 말한다.네트워크가 간단하거나 학습이 충분하지 못해서 학습
17.[U] Week 3 - Regularization
Generalization이 잘 되도록 학습에 규제를 걸어서 학습 및 테스트 데이터에 잘 동작할 수 있도록 하는 방법이다.검증 데이터를 활용했을 때 loss가 어느 시점부터 감소하지 않고 증가하기 시작하면 학습을 종료시킨다.Nurel network 파라미터가 너무 커지
18.[U] Week 3 - Convolutional Neural Networks
$$ \\small (fg)(t)=\\int f(\\tau)g(t-\\tau)d\\tau=\\int f(t-\\tau)g(t)d\\tau \\ \\tiny{Continous \\, convolution}\\{}\\ \\small (fg)(t)=\\sum^{\\inft
19.[U] Week 3 - Recurrent Neural Networks
Seqeuntial한 데이터를 다루기 위한 네트워크들이 있다.$$\\prod^\\Tau\_{t=1}p(x_t|x_t-1)$$입력 데이터와 이전 time step 1개만 고려해서 다음을 예측한다.과거에 많은 정보를 고려할 수가 없다$$\\hat{x}=p(xt|h_t) \
20.[U] Week 3 - 데이터 시각화
데이터 시각화(Data Visualization)란 데이터를 그랴픽 요소로 매핑하여 시각적으로 표현하는 것이다.데이터가 우선적으로 필요데이터셋 관점 (global)개별 데이터의 관점 (local)데이터셋은 수많은 종류가 존재정형 데이터시계열 데이터지리 데이터관계형(네트
21.[U] Week 3 - Matplotlib

Matplotlib은 Python에서 사용할 수 있는 시각화 라이브러리로 numpy와 scipy를 베이스로 하여 다양한 라이브러리와 호환성이 좋고 다양한 시각화 방법론을 제공한다.막대그래프선그래프산점도etc..matplotlib에서 그리는 시각화는 Figure라는 큰
22.[U] Week 3 - Matplotlib 2
Bar Plot은 직사각형 막대를 사용하여 데이터의 값을 표현하는 차트 및 그래프로 막대 그래프, bar chart, bar graph 등의 이름으로 사용된다.범주(category)에 따른 수치 값을 비교하기에 적합한 방법개별 비교, 그룹 비교 모두 적합막대의 방향에
23.[U] Week 4 - Image Classification
AI는 사람의 지능을 컴퓨터 시스템으로 구현을 하는 것인데 이때 지능은 인지 능력과 지각 능력, 사고 능력까지도 포함하는 넓은 영역을 말한다.사람으로 따지면 시각 능력을 사용하는 분야로 시각 정보를 사용해 데이터로 표현 혹은 분석하는 것으로 말할 수 있을 거 같다. 반
24.[U] Week 4 - Segmentation & Detection
Semantic segmentation은 모든 픽셀에 대해 class를 예측하는 방법이다. 의료 영상, 자율 주행 등 분야에 사용된다입력으로 임의에 해상도를 가지는 데이터를 사용이 가능하다.FC layer에 Linear가 아닌 average pooling 및 1x1 컨
25.[U] Week 4 - CNN Visualization
CV 분야에서 CNN이 큰 효과를 보이고 있는데 CNN 구조가 어떻게 이루어지는지, 왜 성능이 잘 나오는지, 성능 향상을 위해 어떤 방법을 도입할 수 있는지에 대해 시각화를 통해 분석 및 확인할 수 있다.간단한 방법으로는 filter를 visualization 하는 방
26.[P] Week 6 - Classification Competition
Classification 대회가 진행되었고 마스크에 착용 상태에 따른 분류가 주제이다.해결해야할 문제는 성별, 나이, 마스크 착용 상태에 따른 18가지 클래스로 분류하는 것이다.주어진 데이터를 분석해보았는데 이 과정에서 발견한 특징들이 있다.데이터의 RGB 평균 및
27.[P] Week 7 - Classification Competition
P stage의 첫 대회가 종료되었다. 해보고 싶은 걸 다 하지는 못했지만 팀원들과 다양한 시도를 해보고 그 과정에서 많은 것을 배울 수 있었다. 이전 주와 다르게 github로 상황을 공유하며 템플릿을 맞추고 의미있었던 기능 혹은 방법들을 추가하여 실험을 진행했다.먼
28.[P] Week 9 - Neck
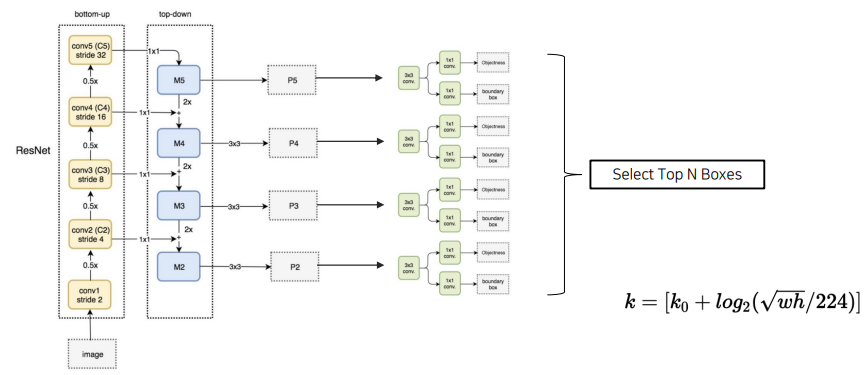
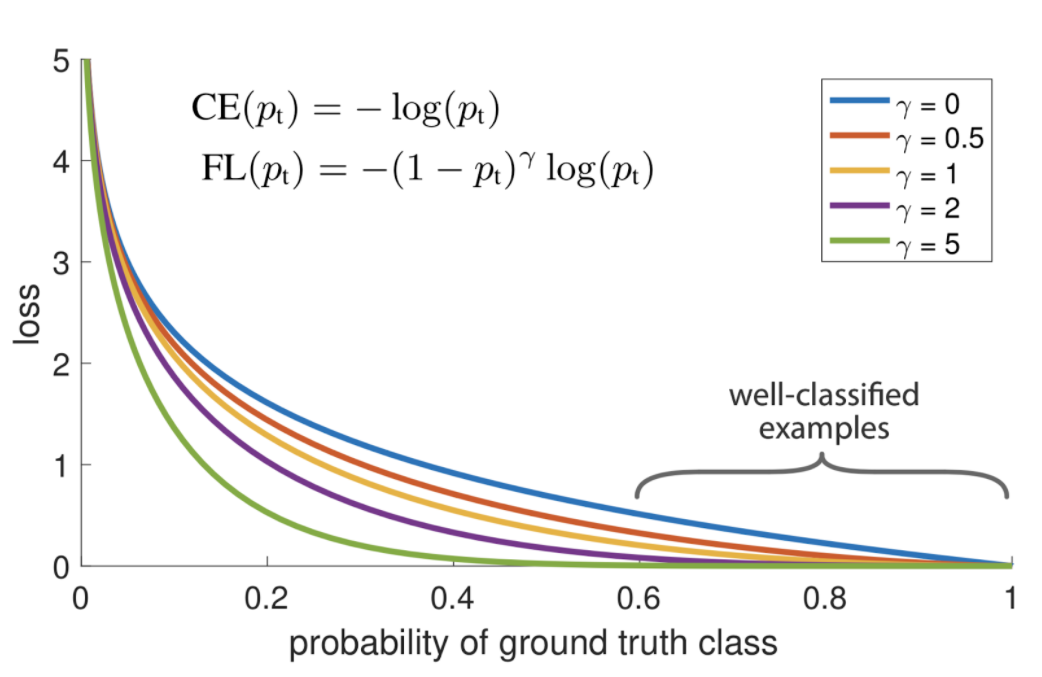
기존 2 stage는 주어진 input 데이터를 backbone을 통해 나온 마지막 feature map을 가지고 region proposal을 한다. Concept: 마지막 feature map만 사용하지 말고 중간중간 만들어지는 feature map들도 사용하면 더
29.[P] Week 9 - 1 Stage Detectors
일반적으로 2 stage detector는 Localization을 수행하고 Classification을 진행하기 때문에 속도가 느리다는 단점이 있어 real-time에 적용하기 힘든 문제로 1 stage detector 연구가 진행되었다.1 stage에서는 RPN 과
30.[P] Week 10 - Efficiency
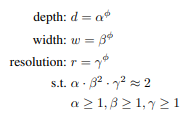
ImageNet 챌린지 이후 Deep learning model들이 크고 복잡해지고 있지만 어느 순간부터 레이어를 깊게만 쌓으면 성능 개선은 크게 이루어지지 않고 모델은 커져 속도는 느려지게 된다. 점점 빠르고 작은 모델에 대한 요구가 증가하고 있고 효율성과 정확도의