미분
미분은 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구로 최적화에서 제일 많이 사용하는 기법.
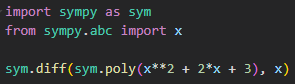
미분은 함수 의 주어진 점 에서의 접선의 기울기를 구한다.
한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가하는지/감소하는지 알 수 있다.
- 미분값이 음수라서 는 왼쪽으로 이동하여 함수값이 증가
- 미분값이 양수라서 는 오른쪽으로 이동하여 함수값이 증가
미분값을 더하면 경사상승법(gradient ascent)이라 하며 함수의 극대값의 위치를 구할 때 사용한다. (목적함수 최대화)
미분값을 빼면 경사하강법(gradient descent)이라 하며 함수의 극소값의 위치를 구할 때 사용한다. (목적함수 최소화)
- 경사상승/경사하강 방법은 극값에 도달하면 움직임을 멈춘다. (극값에선 미분값이 0이므로 더 이상 업데이트가 안 된다. 그러므로 목점함수 최적화가 자동으로 끝난다.)
벡터가 입력인 다변수 함수의 경우 편미분(partial differentiation)을 사용한다.
- 벡터는 n차원 공간에서 계산되는 한 점이기 때문에 이동할 때 많은 방향으로 움직일 수 있어서 특정 방향에 좌표 축으로 이동하는 형식인 편미분을 사용한다.
각 변수 별로 편미분을 계산한 그레디언트(gradient) 벡터를 이용하여 경사하강/경사상승법에 사용할 수 있다.
벡터는 절대값 대신 norm을 계산해서 경사하강법 적용 시 종료 조건을 설정한다.
선형 회귀
n개의 변수로 데이터들이 이루어져있는 상황에서 데이터를 가장 잘 표현하는 선형 모델을 찾는 문제.
선형 모델의 경우 무어-펜로즈 역행렬을 이용해서 계수를 찾을 수 있고 회귀분석이 가능하다.
선형 모델이 아닌 다양한 경우네는 경사하강법을 이용하는 최적화 방법이 가능하다.
선형회귀의 목적식은 이고 이를 최소화하는 (beta)를 찾아야 하므로 목적식을 로 미분하여 그레디언트 벡터를 구해야 한다.
선형회귀 알고리즘 사용 시 경사하강법 수렴을 위해 특정 조건이 아닌 학습 횟수(epochs)로 조절한다.
- 경우에 따라 올바르게 감소하여 수렴할 수도 있지만 그렇지 못한 경우 특정 조건을 적용한 반복문을 사용하면 무한 루프에 빠질 수도 있을 거 같다는 이유인 것 같다.
경사하강법 알고리즘은 무어-펜로즈 역행렬을 이용하는 것처럼 정확한 값에 도달할 때까지 계속해서 수렴하는 것은 아니므로 학습 횟수를 너무 작게 잡으면 목표로 하는 계수를 찾지 못할 수도 있다. (학습률과 학습 횟수 적절하게 적용)
- 학습률이 너무 작으면 수렴이 늦게, 너무 크면 경사하강법 알고리즘이 불안정해진다.
이론적으로 경사하강법은 미분 가능하고 볼록(convex)한 함수에 대해선 적절한 학습률과 학습 횟수를 선택했을 때 수렴이 보장되어 있다.
- 볼록한 함수는 그레디언트 벡터가 항상 최소점을 향한다.
- 특히 선형회귀의 경우 목적식 은 회귀계수 에 대해 볼록함수이기 때문에 알고리즘을 충분히 돌리면 수렴이 보장된다.
- 하지만 비선형회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지는 않는다. (특히 딥러닝을 사용하는 경우 목적식은 대부분 볼록함수가 아니다)
확률적 경사하강법
확률적 경사하강법(stochastic gradient descent)은 모든 데이터를 사용해서 업데이트하는 대신 데이터 한 개 또는 일부 활용하여 업데이트한다.
볼록이 아닌(non-convex) 목적식은 SGD를 통해 최적화할 수 있다. (데이터가 한 개면 SGD, 데이터의 일부를 사용하면 mini-batch SGD)
- SGD라고 해서 만능은 아니지만 딥러닝의 경우 SGD가 경사하강법보다 실증적으로 더 낫다고 검증되었다.
SGD는 데이터의 일부를 가지고 파라미터를 업데이트하기 때문에 연산지원을 좀 더 효율적으로 활용하는데 도움이 된다.
- 전체 데이터 를 쓰지 않고 mini-batch 를 써서 업데이트 하므로 연산량이 로 감소한다.
- SGD를 사용한 그레디언트 벡터는 경사하강법을 사용한 그레디언트 벡터와 동일하지 않을 수 있지만 확률적으로 기대값에 관점에서는 유사하게 사용할 수 있기 때문에 정확하진 않더라고 연산량을 더 효율적으로 사용하면서 경사하강법과 유사한 효과를 발휘할 수 있기 때문에 SGD를 사용하여 목적식을 최적화할 수 있다.
- mini-batch를 가지고 목적식의 그레디언트를 근사해서 계산한다.
- 확률적으로 매번 다른 mini-batch 사용하기 때문에 목적식의 곡선 모양이 바뀌게 된다.
- 극소점이나 극대점에서 목적식이 확률적으로 바뀌기 때문에 본 극소점이 더 이상 극소점이 아니게 되면 목적식이 바뀐 상태에서 그레디언트 벡터를 계산하게 되어 극소점을 탈출할 수 있어서 SGD는 non-convex한 함수라 하더라도 최소점을 찾는 데 활용할 수 있는 원리가 된다.
- 수렴 방향은 다를 수 있어도 연산 속도는 경사하강법보다 효율적으로 빠르게 연산된다.
- 다만 SGD에서 mini-batch size를 너무 작게 잡게 되면 경사하강법 알고리즘보다 훨씬 더 느리게 수렴할 수도 있다)
- 하드웨어 관점에서 현실적인 문제로 인해 경사하강법은 딥러닝에 적용하기 힘들다.
