
Visualizing and Understanding

첫번째 layer의 weight를 시각화해보면 image에서 oriented edge를 찾는걸 볼 수 있다.
Feature을 찾는 것이라 볼 수 있다.
필터들이 layer가 깊어지면서, 합성곱이 이뤄지고 점점 더 복잡해지며 나중에 깊은 layer의 필터들을 보면 직관적으로는 이해할 수 없는 필터들이 된다.

첫번째 layer는 image와 직접적으로 연관되어 있으므로 interpret 할 수 있지만, 두번째 layer부터는 쉽게 interpret할 수 없다.
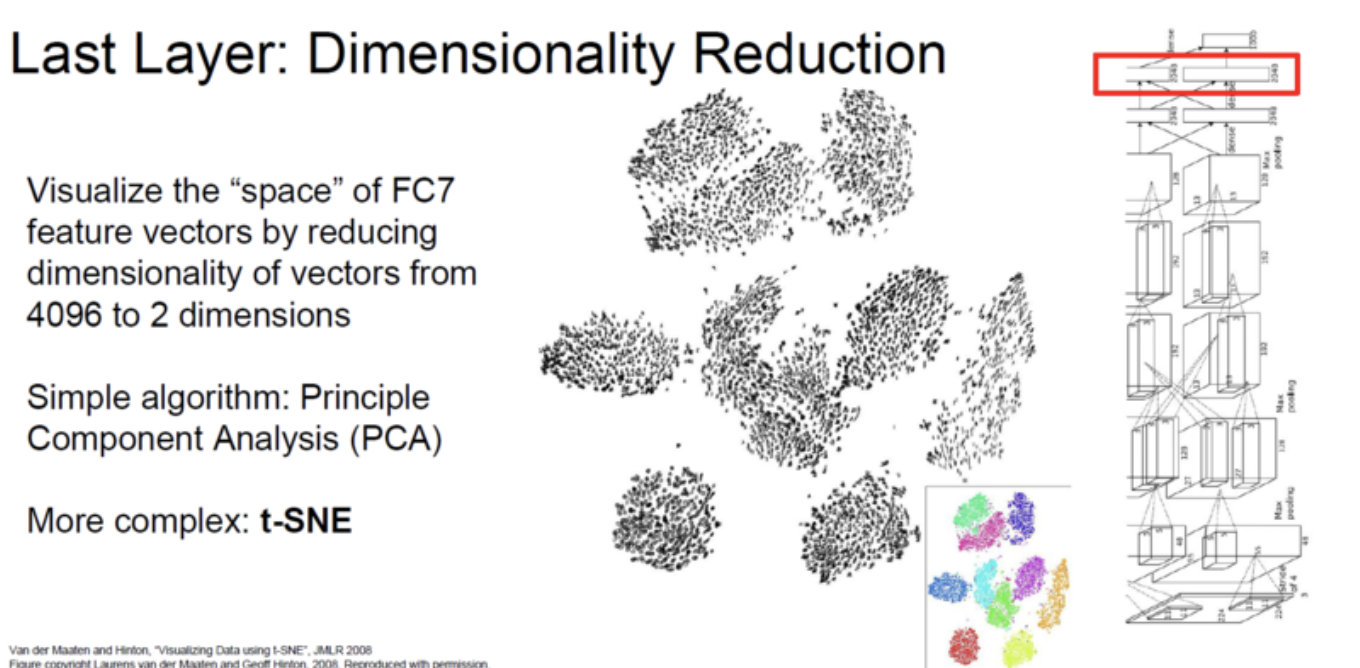
그리고 마지막 Layer인 FC7을 이미지의 feature vector로 사용할 수 있는데, Test image에 대해서 NN(Nearest Neighbor)를 찾아본 figure를 보여준다.
오른쪽 방향으로 서있는 코끼리가 test image일때 왼쪽을 보는 코끼리도 거의 비슷한 위치에 있는 것을 알 수 있다. pixel space에서는 굉장히 큰 차이가 있지만 feature space에서는 비슷하다.
Triplet network: 특정한 metric space를 갖도록 학습
2D로 Embedding할때 PCA라는 방법을 머신러닝에서 많이사용하는데, 딥러닝에서는 t-SNE라는 non-linearity를 가진 함수를 이용하여 feature를 compression합니다.

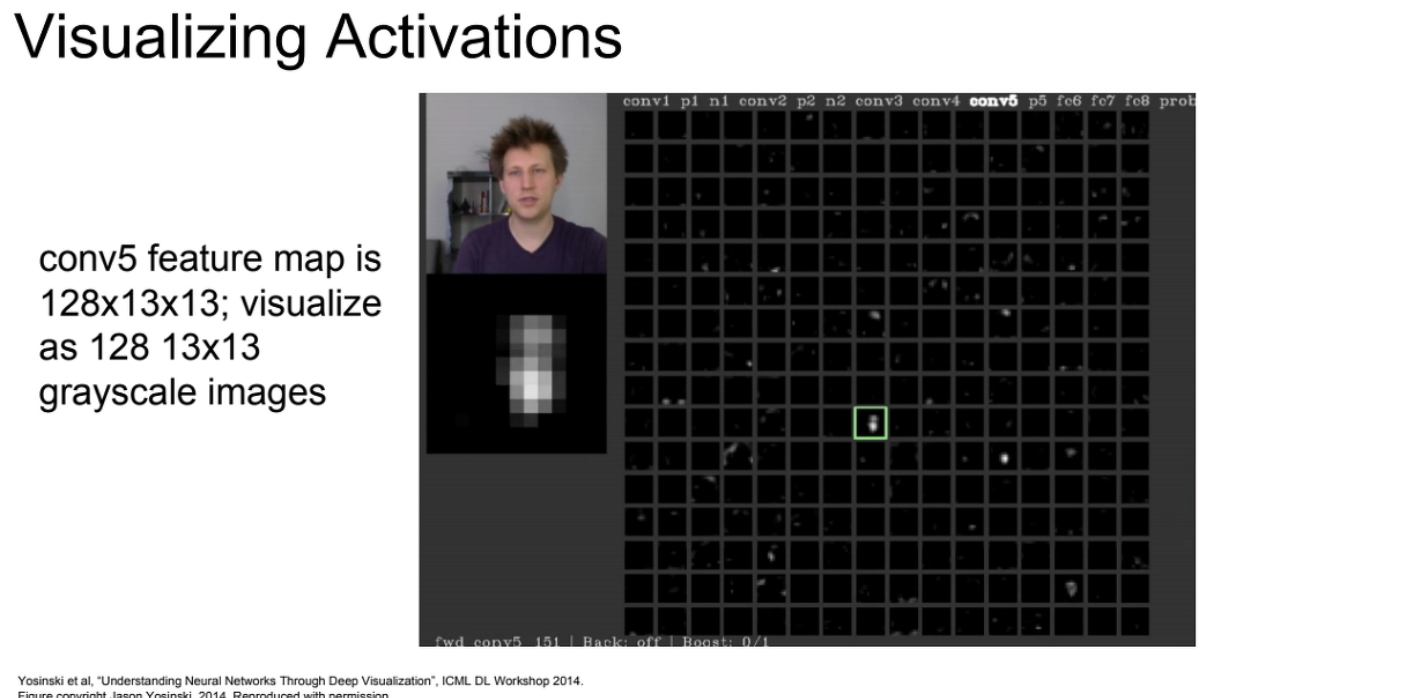
Maximally Activating patches
특정 neuron에서 activation이 가장 큰 patch를 시각화하는 방법.
image patch가 있고 kernel 혹은 filter가 있을때 inner product로 통과시키면 하나의 activation 값이 나오게 된다.
이 activation 값이 높다는 것은 해당 filter에 대해 높에 반응했다는 것인데, image를 처리하는 데 있어서 주목하고 있는 부분이라는 것을 의미한다.
따라서 activation 값이 높은 부분을 캡쳐해보면 neural network가 중요하게 보는 부분을 확인할 수 있다.

Occlusion Experiments
특정 구간을 block 했을때 score가 drastically changed하다면 그 부분이 classification하는데 매우 중요한 부분이라고 판단하는 것.
특정 부분을 제거을때 softmax에서 probability가 적어지는 것을 시각화한 것이고 빨간 부분일 수록 중요한 부분임을 나타낸다.

Saliency Maps
Saliency Maps는 classification score를 image의 각 pixel의 gradient를 map으로 시각화한 것. 파라미터 같은 경우 학습된 모델에 대해서는 변화가 없겠지만, image에는 변화를 가하지 않기 때문에 activation이 있는 부분에서 backward를 하게 되면 값이 살아있게 된다.
따라서 Neural Net이 image에서 어느 부분을 보고 있는지 알 수 있다.

aliency map을 이용하면 저희가 따로 label을 주지 않고도 Un-supervised로 segmentation 작업을 학습할 수 있다.(supervision task보다는 정확도가 매우 떨어짐)
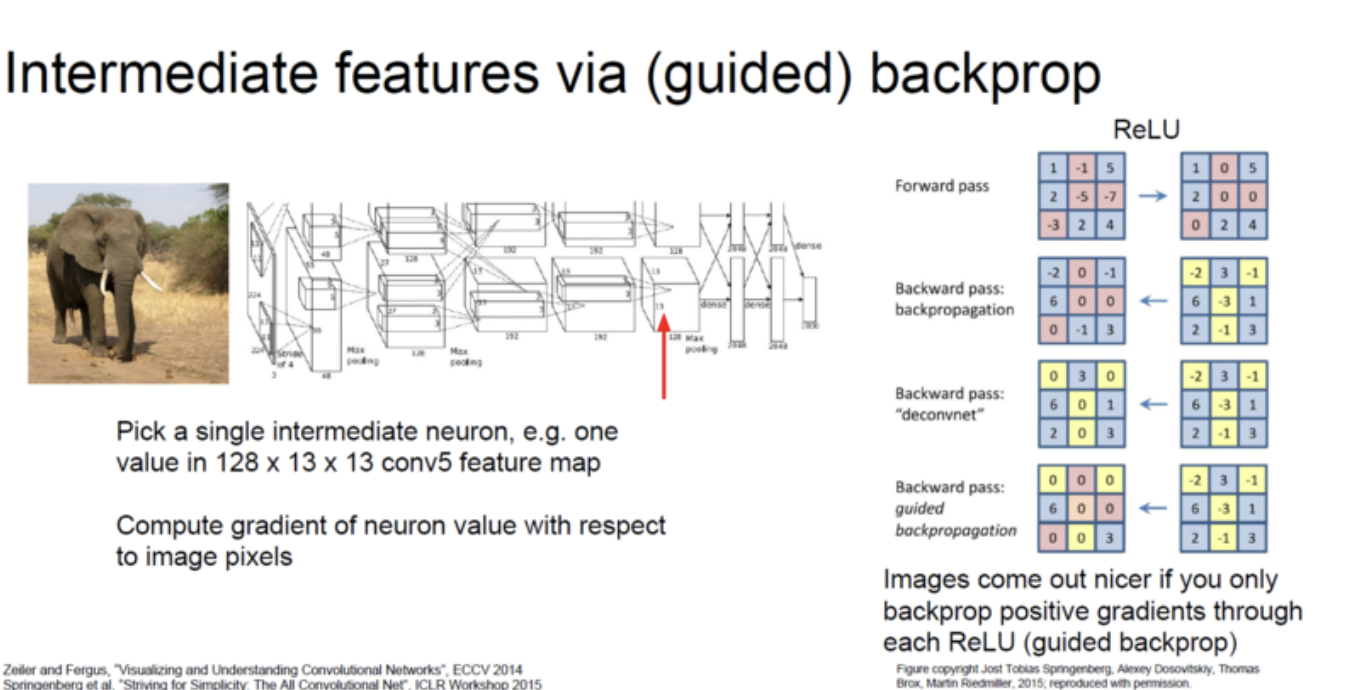
Intermediate features via backprop
일guided backprop은 backprop을 할때 양의 gradient만 뒤로 보내겠다는 뜻. -> activation이 높은 부분만 뒤로 갈수록 살아있게 되는데 이것은 Network가 classification에 이용했다는 걸로 interpret가능.
이전의 방법과 같이 image쪽으로 backprop을 시도하여 (fixed input image에 대한 함수), 양의 gradient만 보냄으로써 더 clean한 image를 만들 수 있다.

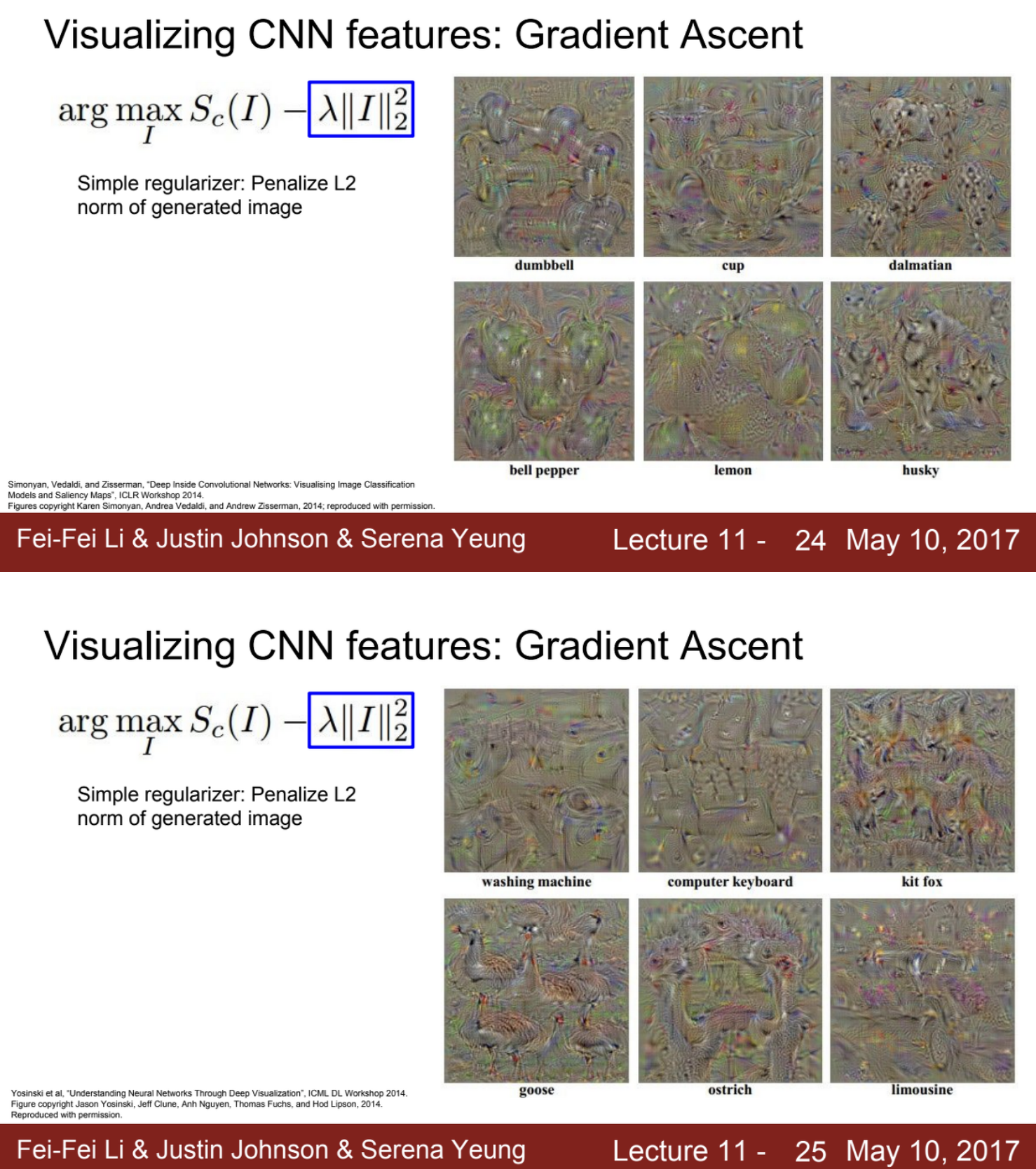
Visualizing CNN features: Gradient Ascent
Gradient Ascent는 최적의 image를 찾는 문제를 푸는 것.
input image에 대한 의존을 없애서 어떤 type의 image에서 generally, 어떤 neuron을 activating 하는지를 알아보는 것.
특정 intermediate neuron 혹은 some class에 대한 score를 높이는 방향으로 이미지를 합성하는 것이 바로 Gradient Ascent.
input image의 pixel들이 score를 높이는 방향으로 바뀌도록 processing.
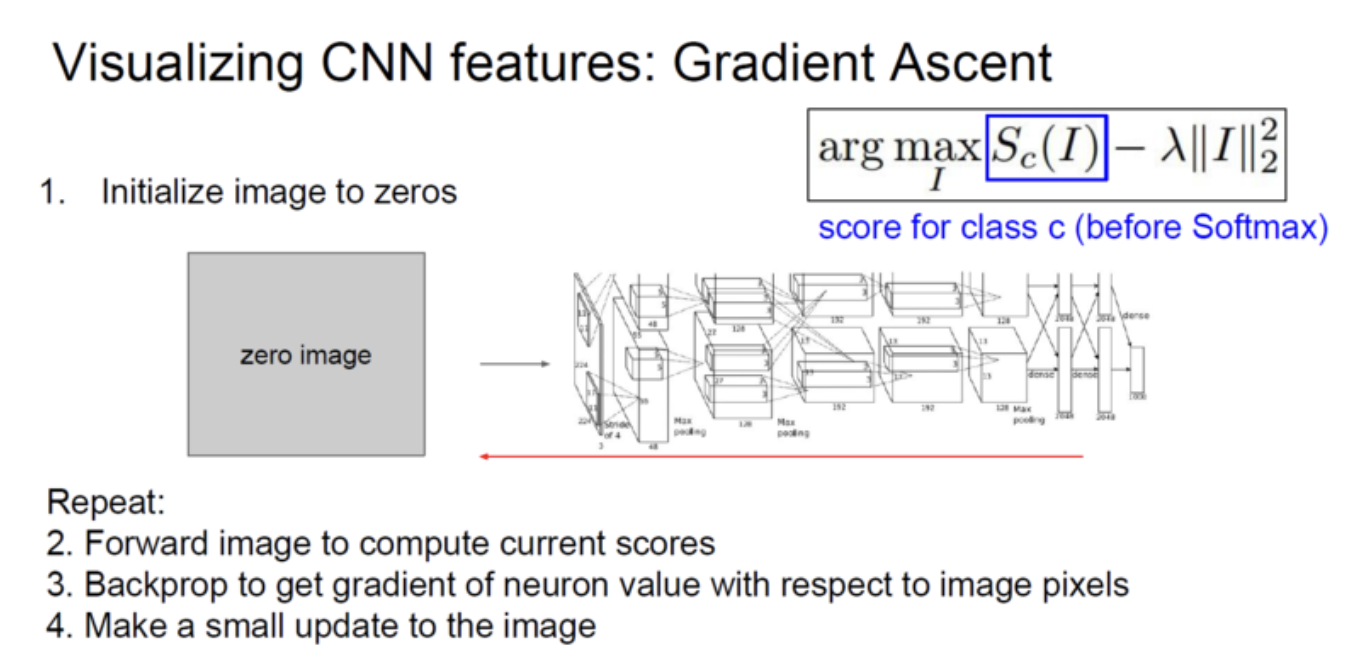
그 순서가 나와있음
1. 이미지 픽셀을 전부 0값으로 초기화.
2. Forward를 통해 이미 weight를 fix한 network에 집어넣어 현재 스코어를 계산.
3. Image pixel의 neuron 값들의 gradient를 backprop으로 구함.
4. 이미지를 특정 뉴런들의 최대화를 위해 pixel 단위로 update를 진행.
score의 최댓값을 가진 이미지가 되도록 계속해서 반복해주는 과정.

Fooling Images: image를 넣고 arbitary class로 분류한 뒤, 다른 class에 대한 값을 높도록 이미지를 변형하고 arbitary class로 분류하도록 네트워크를 바꾸는 작업.
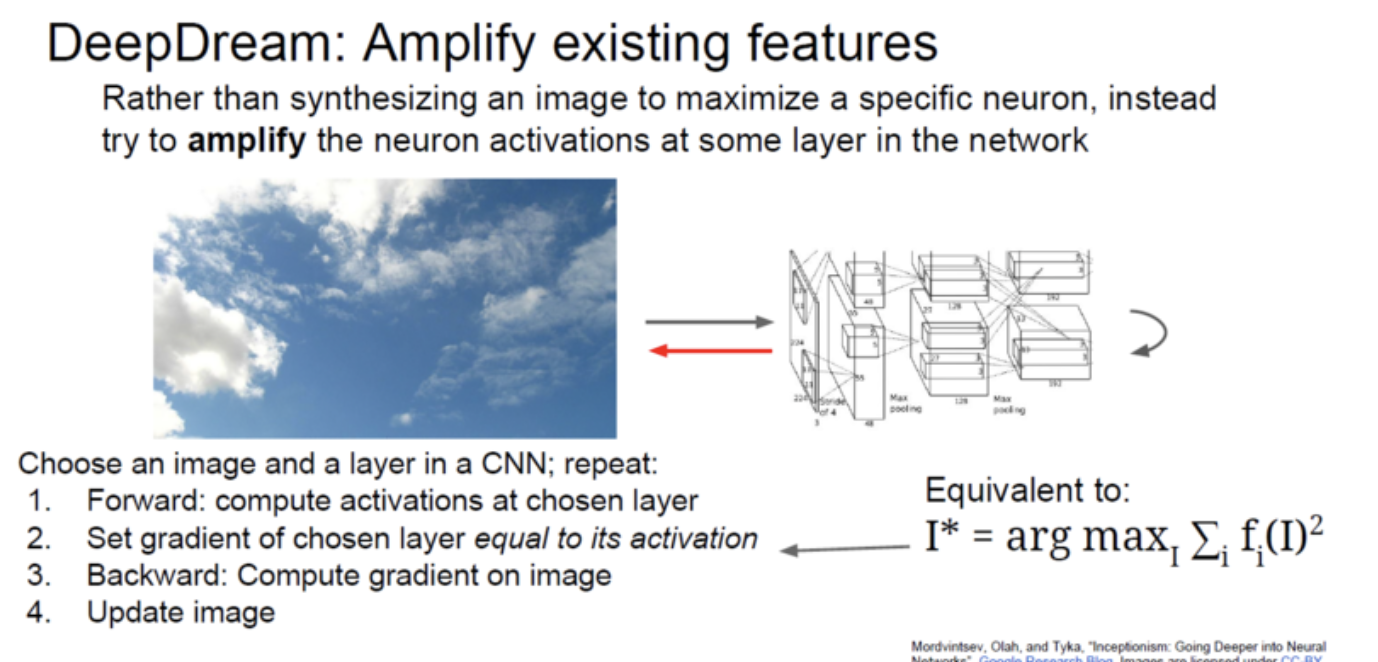
DeepDream.
위에서 synthetic image를 만들 때의 목적은 중요했던 양수의 gradient를 가진 특정 뉴런들을 maximize했었다면, 이번에는 그냥 중간의 layer에서의 모든 뉴런 값들을 확대시키려는 것.
- forward 과정에서 선택했던 layer의 activation 값들을 계산한다.
- 그 activation 값들을 gradinet 값들로 set한다.
- backward를 통해 그대로 학습시킨다.
- 반복하여 이미지를 뽑아낸다.
synthetic image: to maximize a specific neuron
DeepDream: try to amplify the neuron activations


Feature Inversion
Feature Inversion
주어진 Image가 있을때 forword하여 얻은 feature와 주어진 feature vector 간의 차이를 줄이는 image를 찾는 것.
constraints로 Total Variation regularizer를 사용.

network가 deeper할 수록 variation은 심해지지만, 기초적인 형태는 유지하고 있는 것을 확인 가능

texture synthesis:
texture의 input patch를 얻는 목적.
고전적인 방식으로는 Nearest Neighbor를 사용.
픽셀을 line으로 훑어가면서 이미 생성된 주변의 neighbor 픽셀들을 계산해서 그 자리에 입력 텍스쳐 패치에서 한 픽셀을 복사하는 방식.
NN에서는 활용x
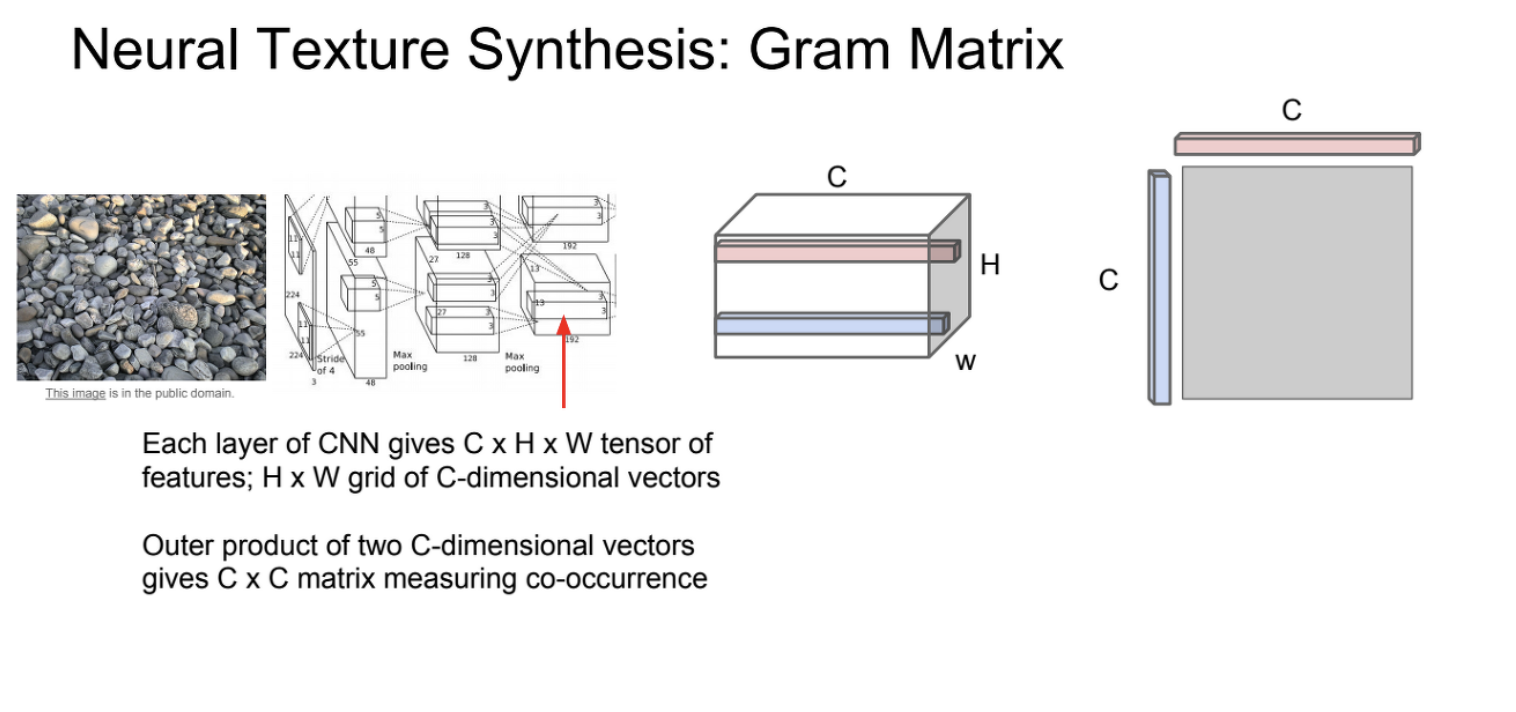
Gram Matix
1. input data를 뉴럴넷에 입력.
2. 몇몇 layer에서 feature map을 가져옴.
3. 이 feature map에서 슬라이드 처럼 서로 다른 특정 픽셀의 특징 벡터를 feature map의 차원으로 추출.
4. 그렇게 뽑아낸 특정 feature 벡터를 서로 외적해서 슬라이드 맨 오른쪽 그림처럼 새로운 matrix를 만듦.
5. 이런 과정을 모든 HxW 차원에 대해서 수행해 그 결과들을 평균 내면, CxC 크기의 gram matrix가 완성.
공간 정보를 가지고 있는 HxW에서 뽑아낸 서로 다른 feature vector들을 외적한 것 -> gram matrix의 성분들이 co-occurrence를 의미한다고 하며, 공분산과도 비슷한 역할을 한다.
co-variance matrix는 연산량이 더 많기 때문에 gram matrix를 이용함.

특정 layer에서 뽑은 Neural Texture Synthesis는 레이어가 깊을수록 더 잘 표현됨.

Neural Style Transfer
Neural Texture Synthesis를 artwork에 적용-> Neural Style Transfer
Texture Synthesis와 Feature Inversion을 합친 개념

style image는 gram matrix를 이용하여 texture를 뽑음.
Content image는 Feature Inversion을 이용하여 네트워크를 거쳐서 나온 Feature map들로 원본 이미지보다는 디테일이 약간 떨어진 image들을 생성
loss
style image에서 나온 gram matrix loss와
content image에서 나온 feature reconstruction loss 이 두 개를 최소화하는 방향으로 new image를 만들어내는 것.
이 두 loss를 합해서 minimize하도록 update.
output image가 학습이 다끝났을 때에는 아래 슬라이드처럼 content image에서 style image의 texture를 가진 image가 만들짐.
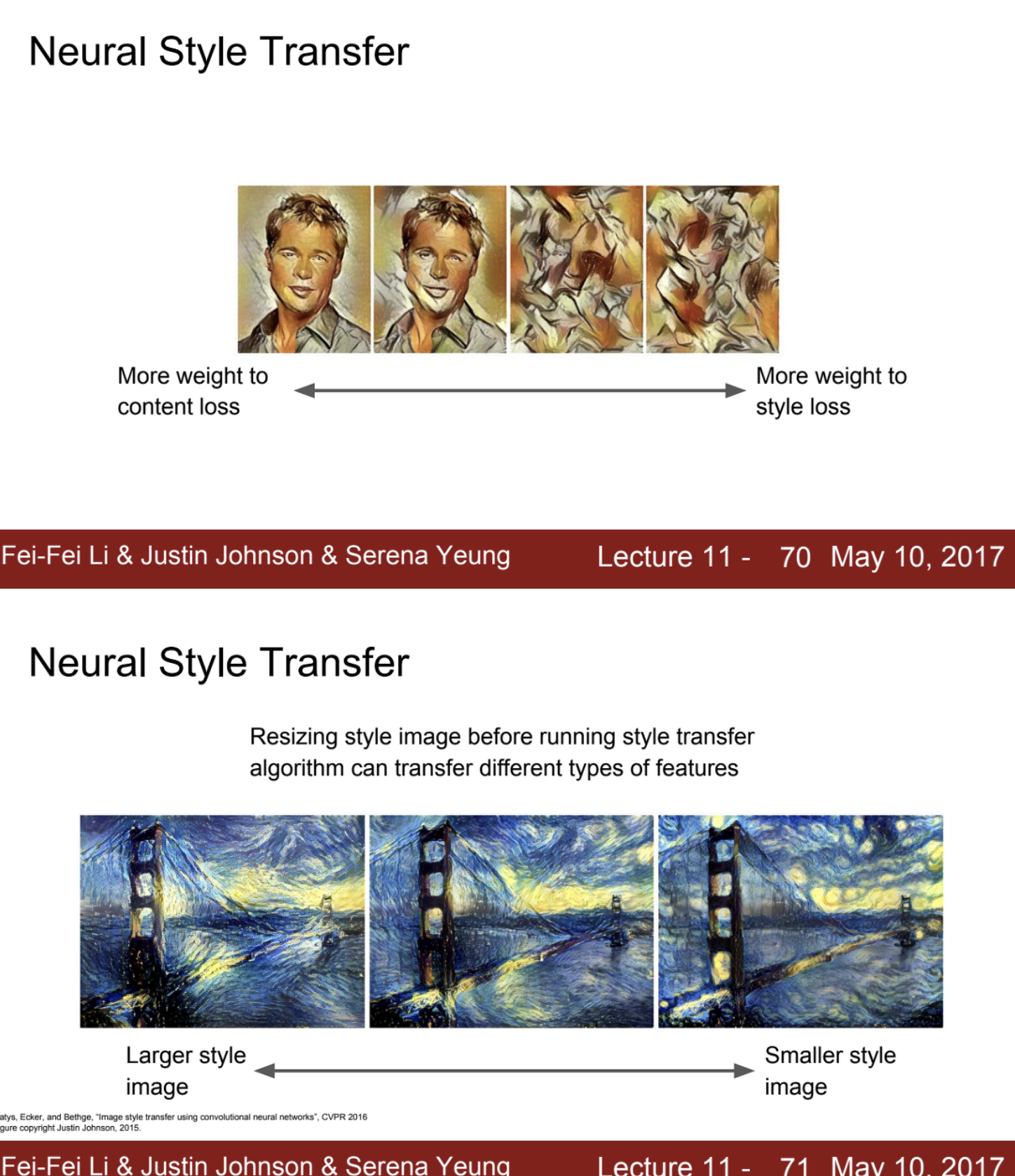
하이퍼 파라미터는 위에 google의 deep dream보다 많아서 훨씬 자유도가 있음
output image는 loss를 어느쪽에 더 치중하느냐에 혹은 어떤 style image의 크기에 따라서 결과물이 위처럼 달라짐.
Style Transfer는 Content Image와 style Image를 함께 넣어 학습을 진행하는 방식이다보니, Content Image가 바뀔 때마다 다시 학습을 시켜야 하므로 많은 연산을 필요.
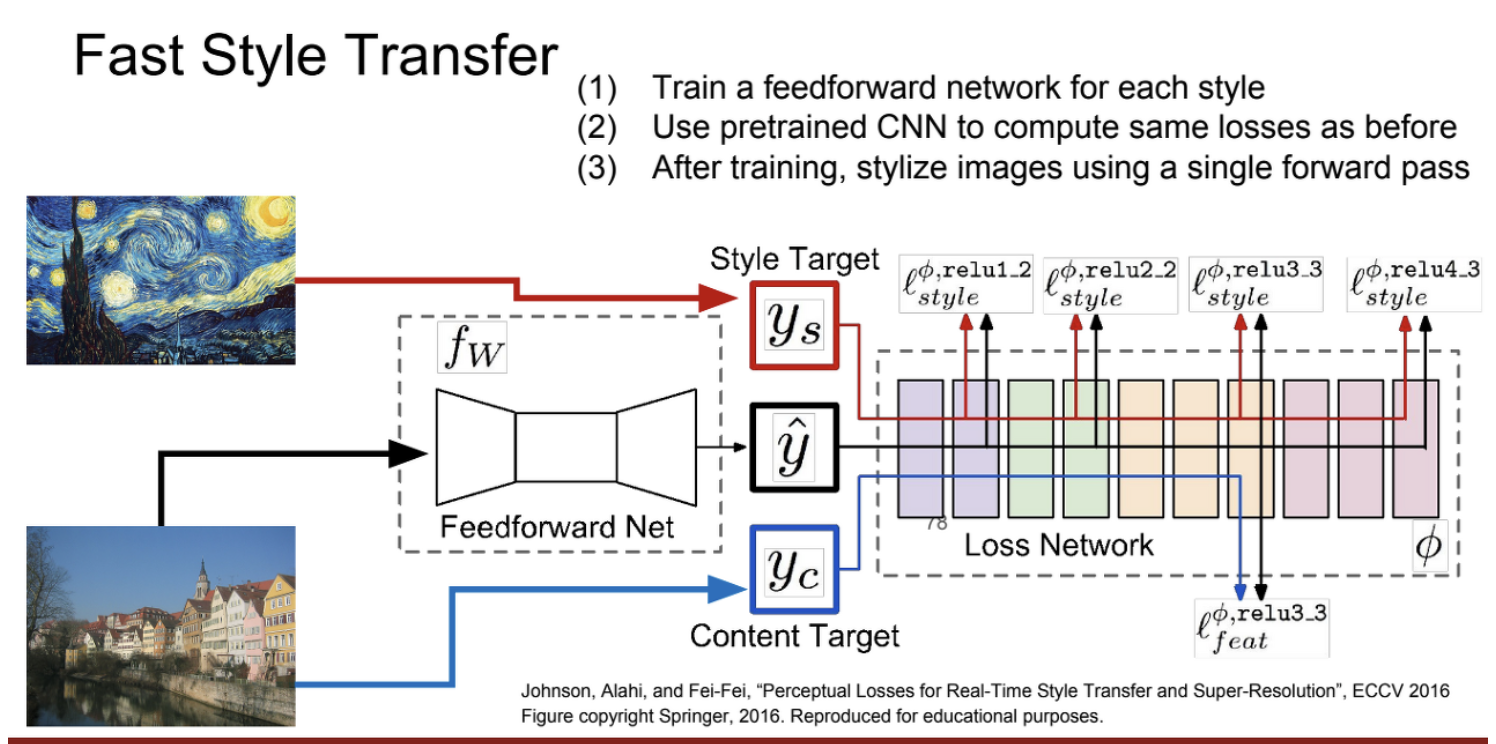
Fast Style Transfer
위의 단점을 보완.
원하는 몇몇 style의 image를 학습시켜서 고정시켜놓고, input image를 content image만 넣어서 single-Network를 학습.
content image를 feed forward로 train하는 동안에는 style과 content loss들을 똑같이 계산하는데, 이전과 똑같은 weight로 학습이 진행됨.
방법은 같으나 속도 향상.

