1. 개요
게임 회사에서 실시한 A/B 테스트를 통해 게임의 첫 번째 게이트가 30레벨에서 40레벨로 이동했을 때 어떤 일이 발생하는지 조사하고 유저들을 사로잡기 위한 방안을 모색하는 것이었는데요! 통계적인 의사결정을 위해 EDA 작업과 t-test, 카이 제곱 검정을 진행한다.
게임 사용자가 첫번째 게이트에 도달하는 시점을 30 라운드에서 40 라운드로 옮겼을 때, 리텐션에 어떤 변화가 있는 지를 AB 테스트를 한 데이터이다. 게임사용자에게 무작위로 gate_30 혹은 gate_40에 할당한다. 고 설치 후 1일 뒤에도 다시 접속했는지 (retention 1), 설치 후 7일 뒤에도 다시 접속했는지 여부 (retention 7)를 측정해 본다.
데이터 출처 :
https://www.kaggle.com/datasets/mursideyarkin/mobile-games-ab-testing-cookie-cats
2. 목표
- 기본적인 EDA와 전처리 진행하기
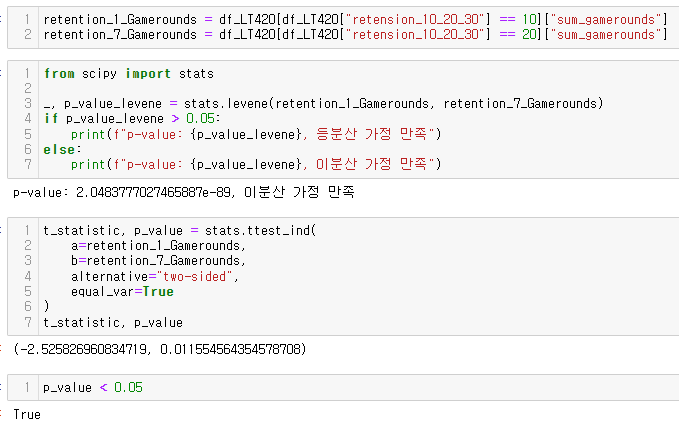
- t-test를 이용하여 gate_30 그룹과 gate_40 그룹의 플레이 라운드 수의 평균이 같은지, 다른지 검정하기
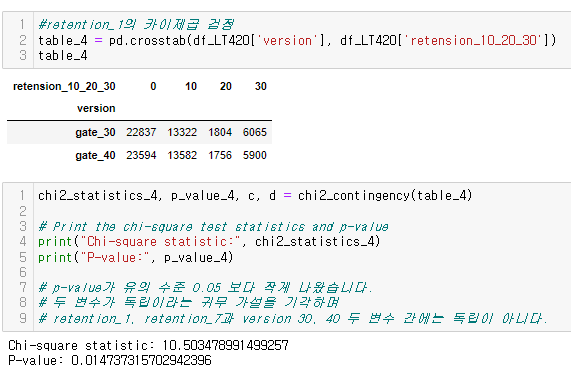
- chi_squre test를 이용하여 version과 retention_1이 서로 독립인지 검정하기
- chi_squre test를 이용하여 version과 retention_2이 서로 독립인지 검정하기
검정 결과를 해석하고, AB 테스트의 결론 내려보기
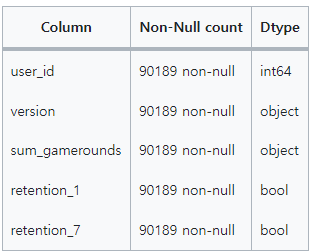
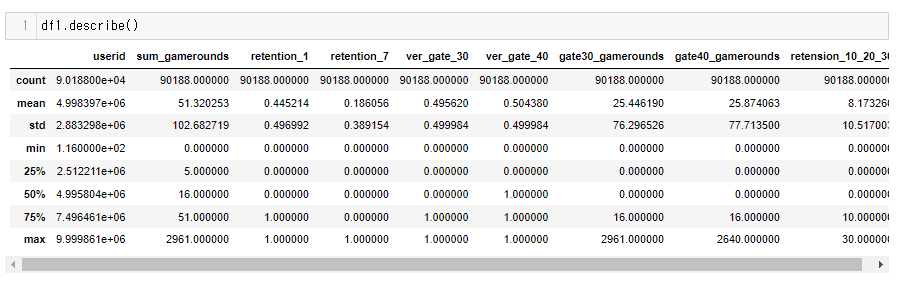
3. 데이터 구조
userid: 사용자마다 부여된 고유번호
version: 사용자가 gate_30을 부여받았는지, gate_40을 부여받았는지의 여부
sum_gamerounds: 설치 후 14일 동안 플레이어가 플레이한 게임 라운드 수
retention_1: 설치 후 1일 후에 다시 플레이했는지의 여부
retention_7: 설치 후 7일 후에 다시 플레이했는지의 여부
4. 실습한 파이썬 코드
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv("./data/cookie_cats.csv")
df = df.replace({True: 1, False: 0})
df
df.info()
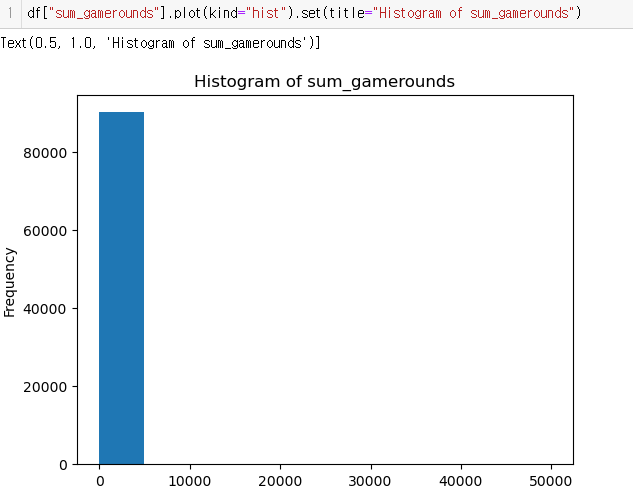
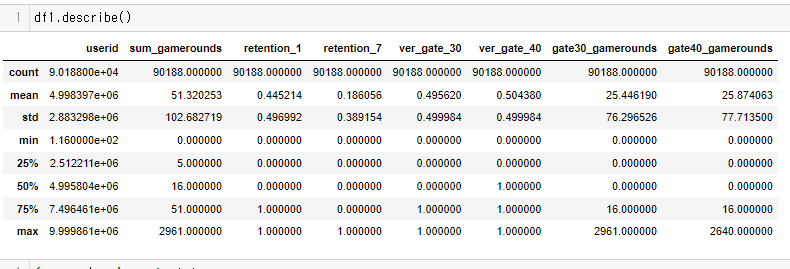
count 90189.000000
mean 51.872457
std 195.050858
min 0.000000
25% 5.000000
50% 16.000000
75% 51.000000
max 49854.000000
Name: sum_gamerounds, dtype: float64
df.shape
(90189, 5)
df.isnull().sum()
userid 0
version 0
sum_gamerounds 0
retention_1 0
retention_7 0
dtype: int64
- 결측지 없음
mean = df["sum_gamerounds"].describe()["mean"]
std = df["sum_gamerounds"].describe()["std"]
var = std * std
print("sum_gamerounds의 평균:", mean, " 분산:", var, " 표준편차:", std)
sum_gamerounds의 평균: 51.8724567297564 분산: 38044.83702787581 표준편차: 195.05085754201596
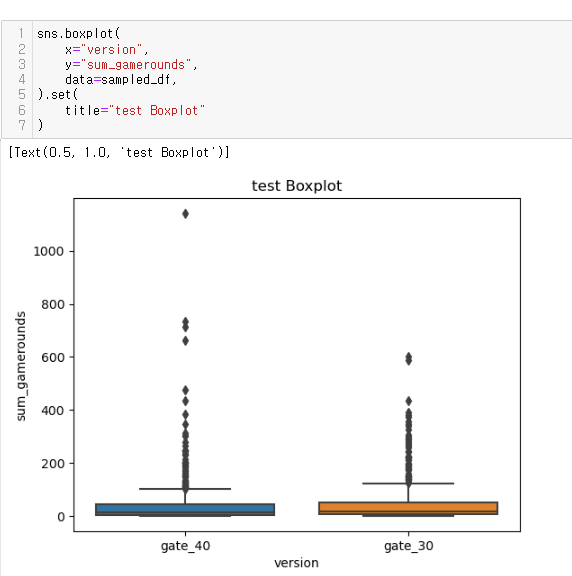
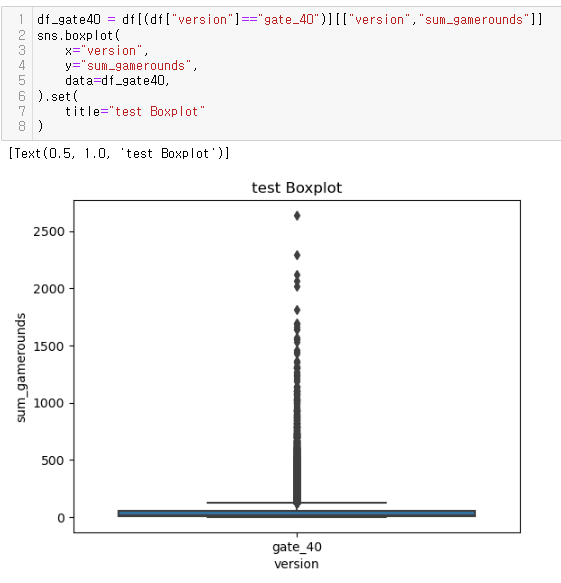
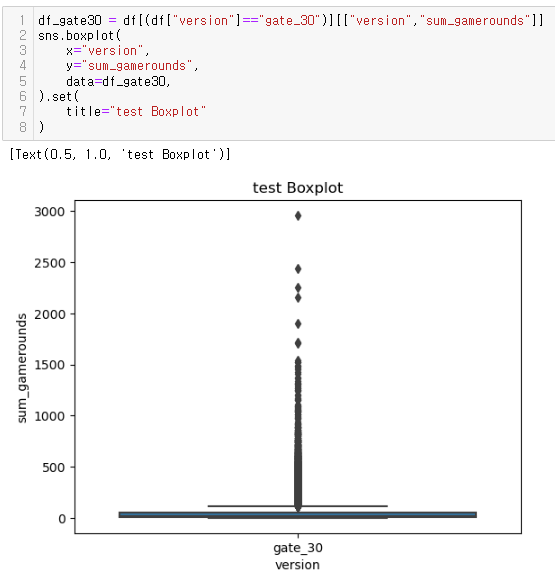
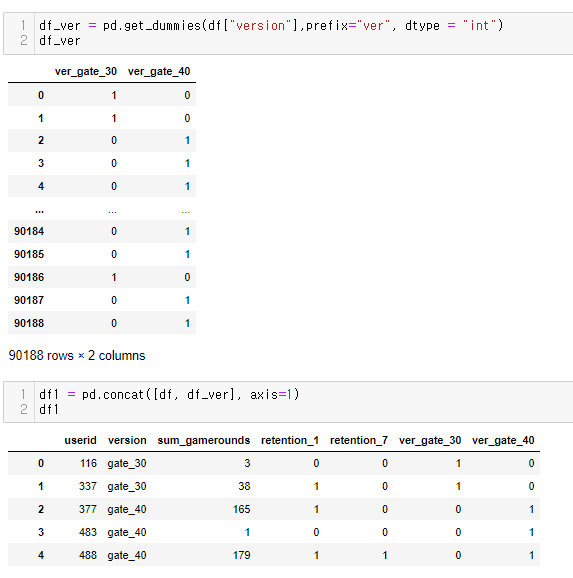
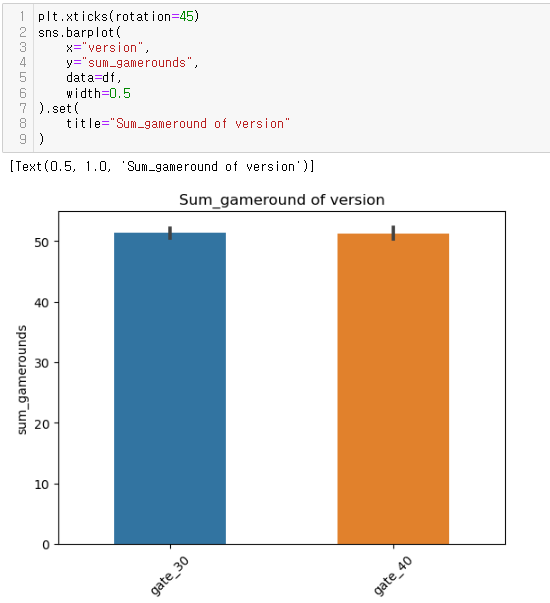
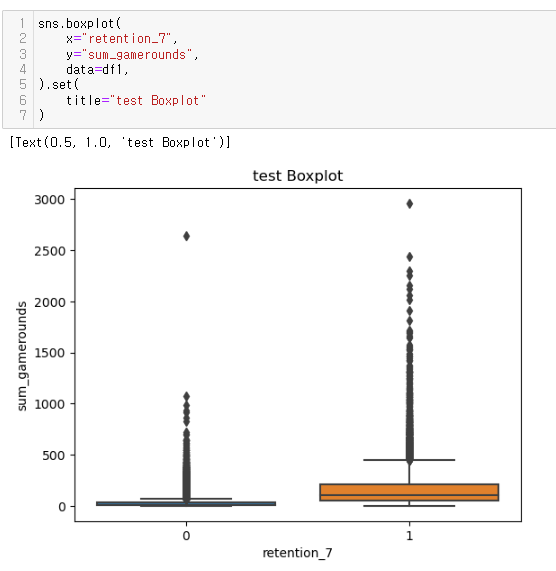
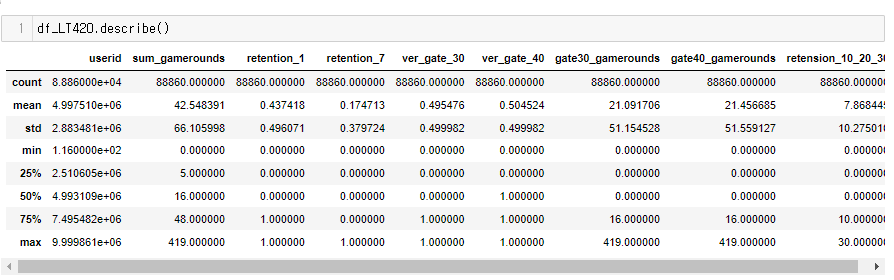
좀 더 심도있게 분석...

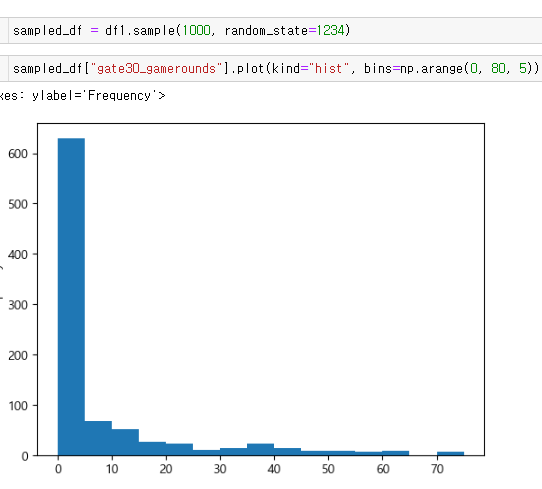
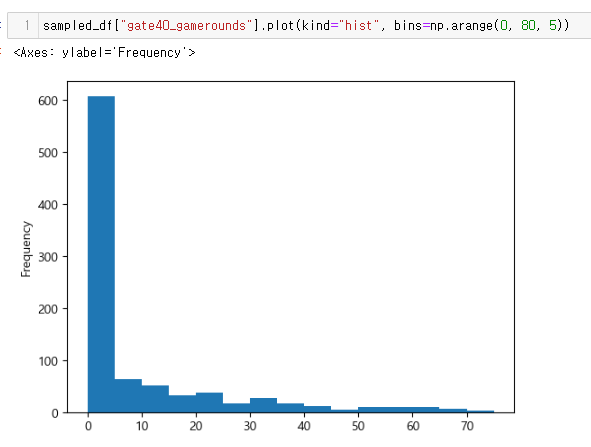
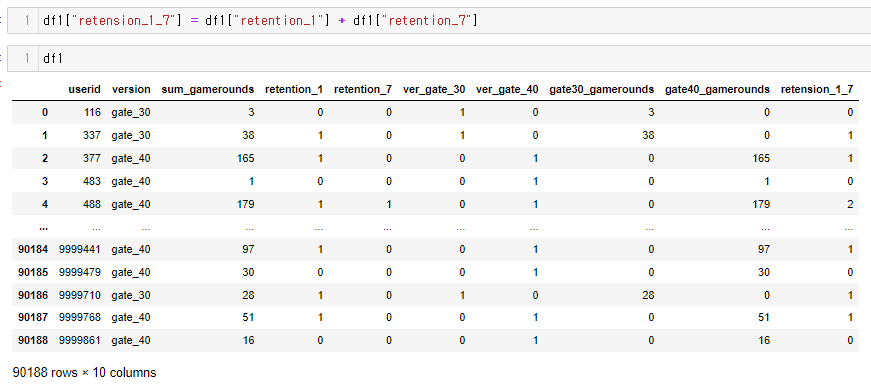
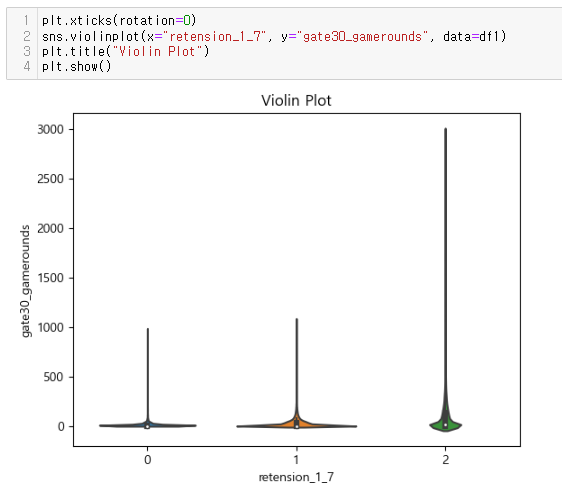
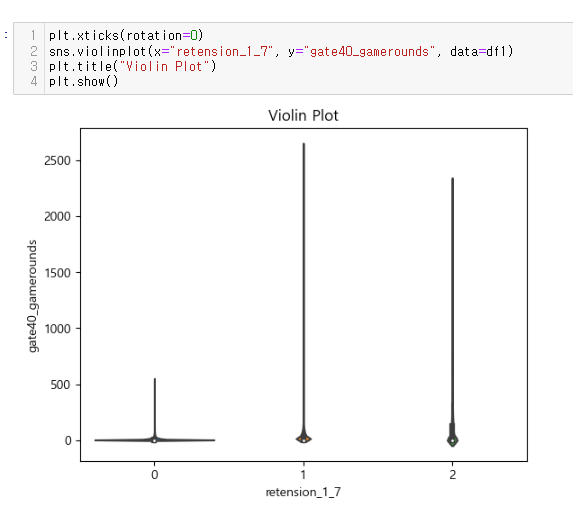
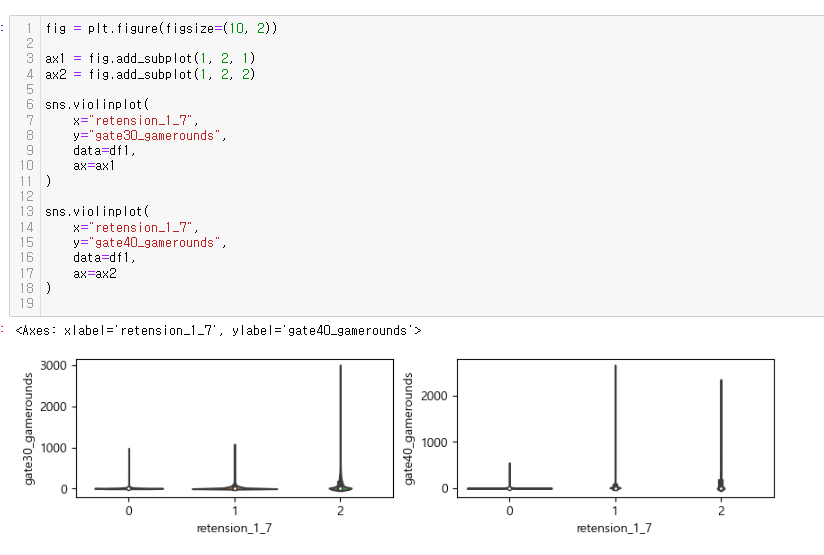
00, 10, 20, 30(retention-1 10 + retention 20 으로 각각 구분작업 해결함. 00: 접속무, 10: 1일후 접속, 20ㅣ 7일후 접속, 30: 모두 접속)**
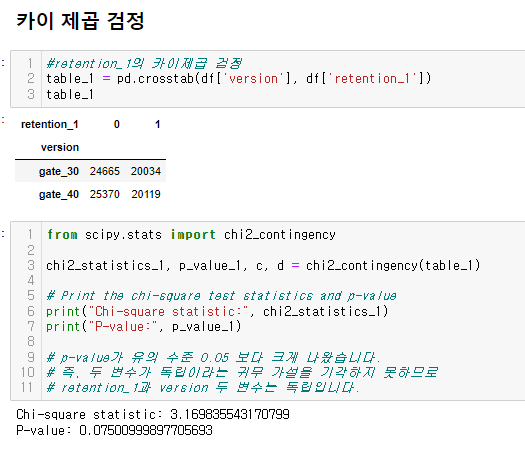
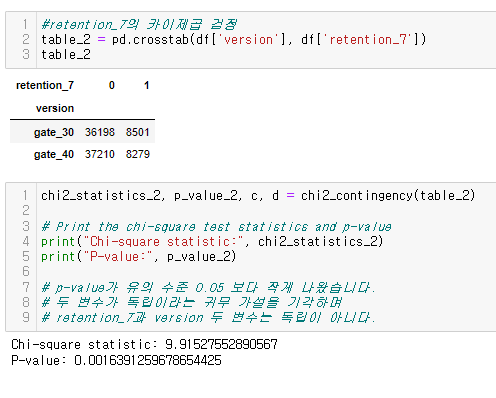
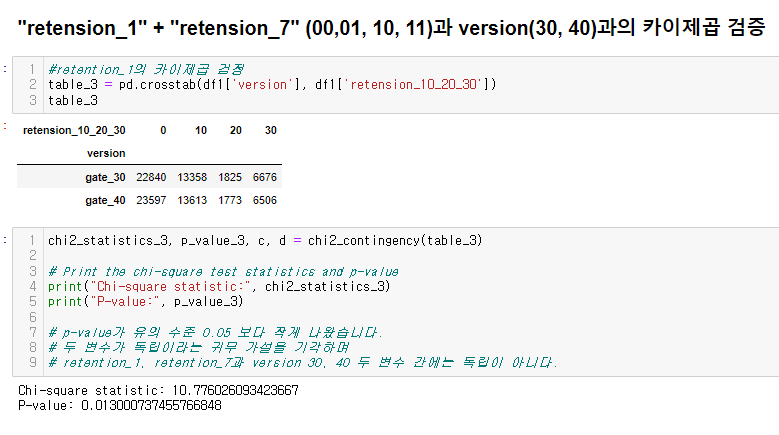

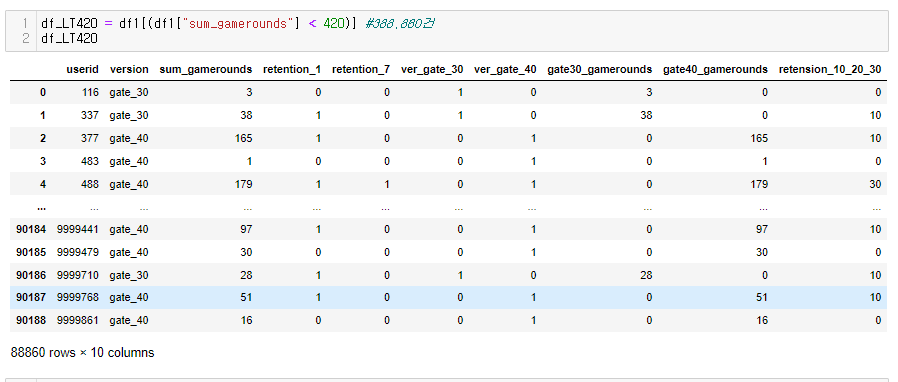
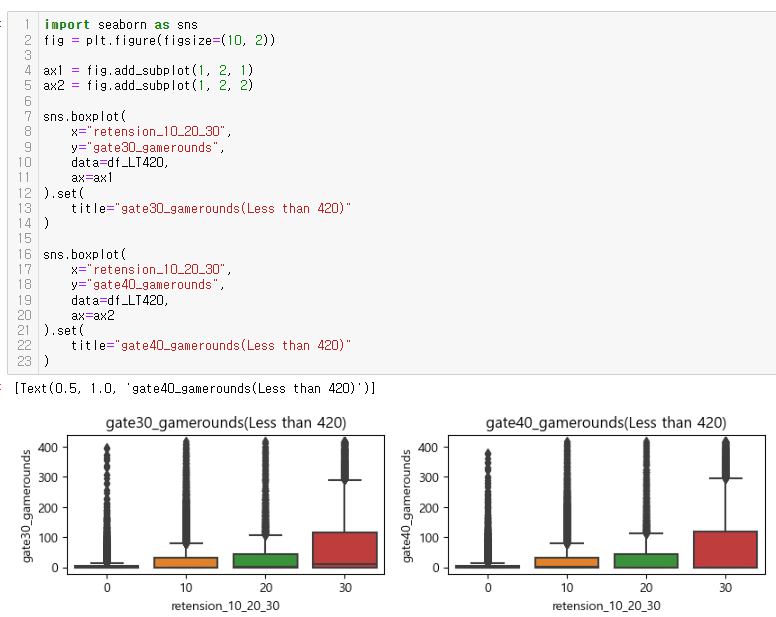
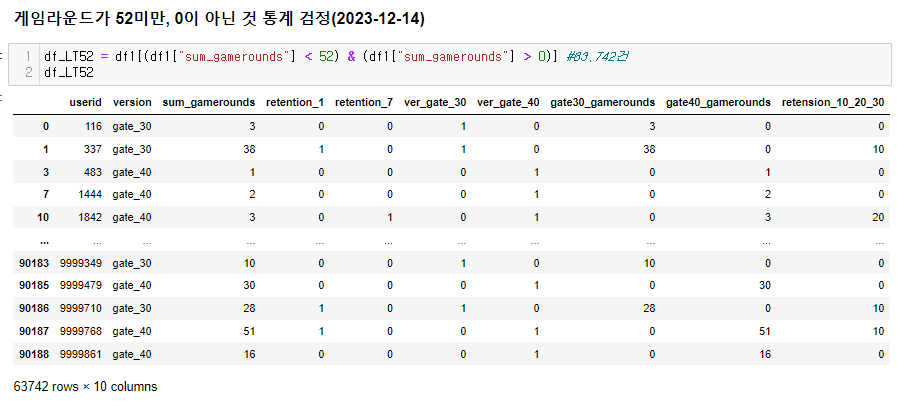
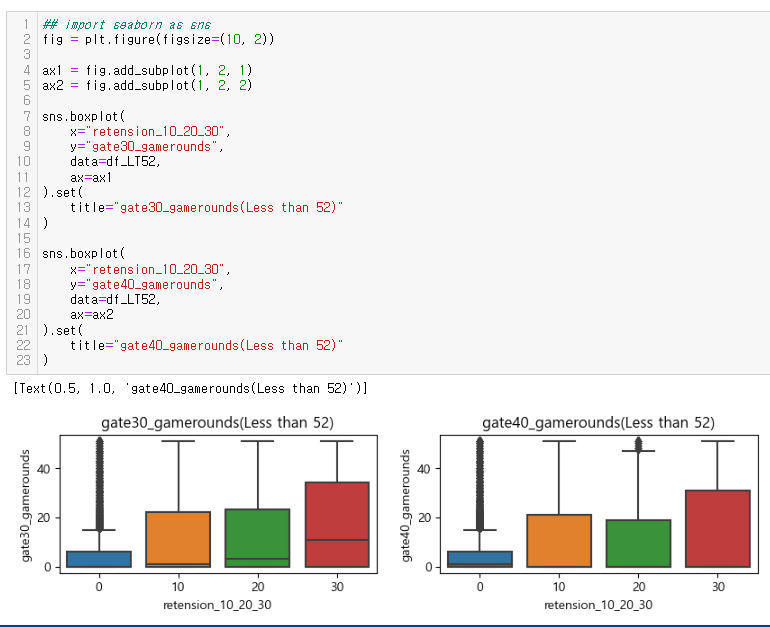
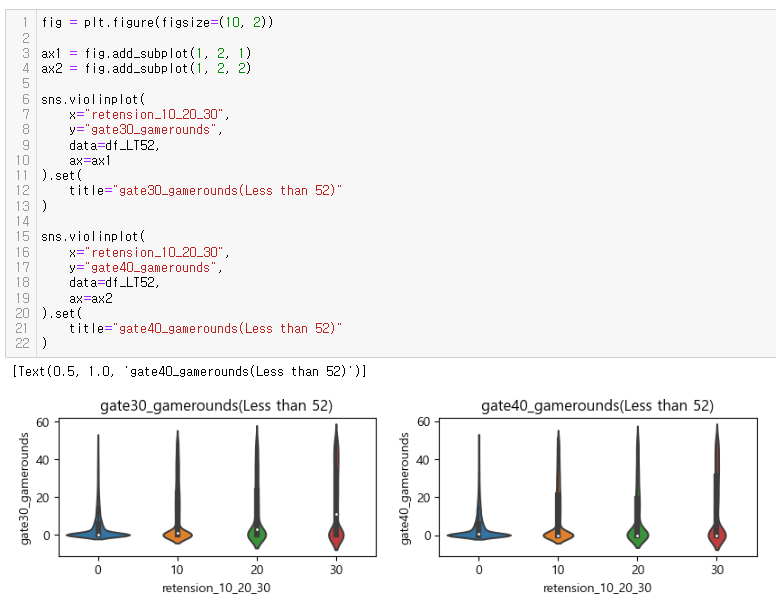
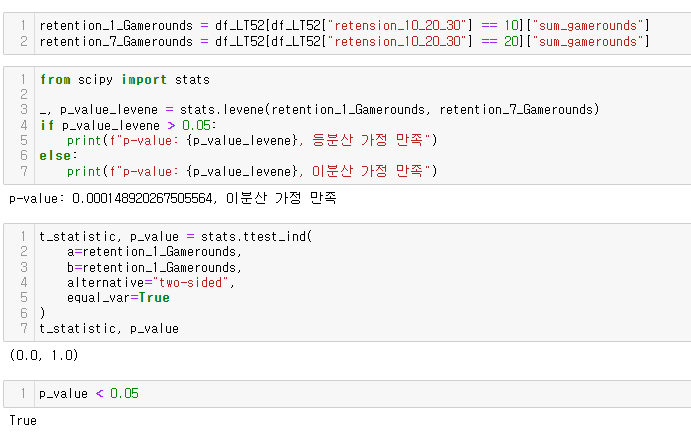
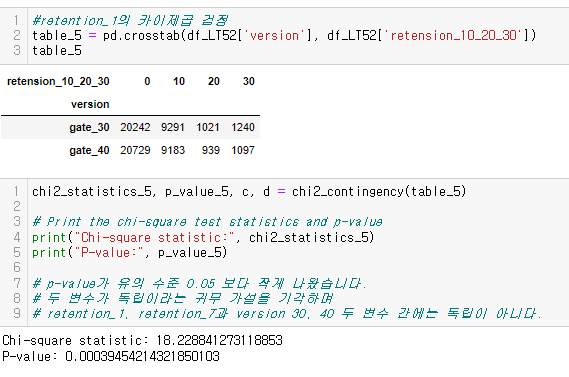
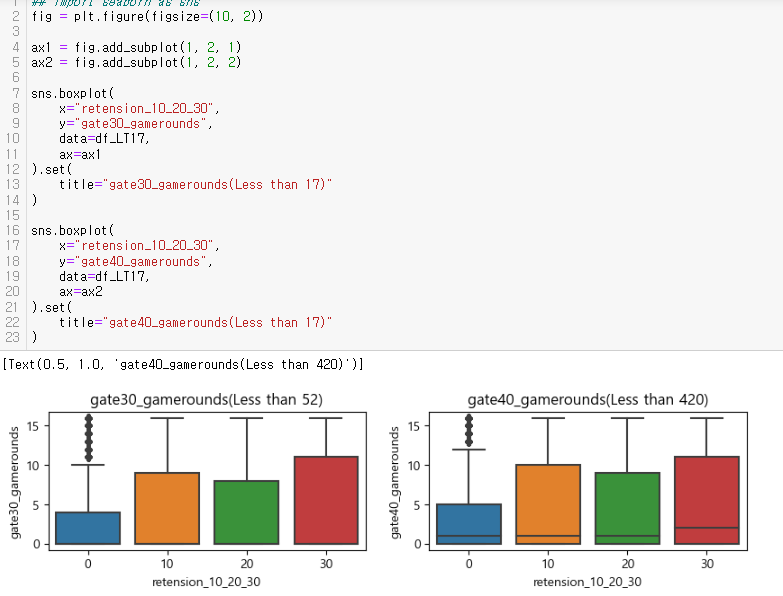
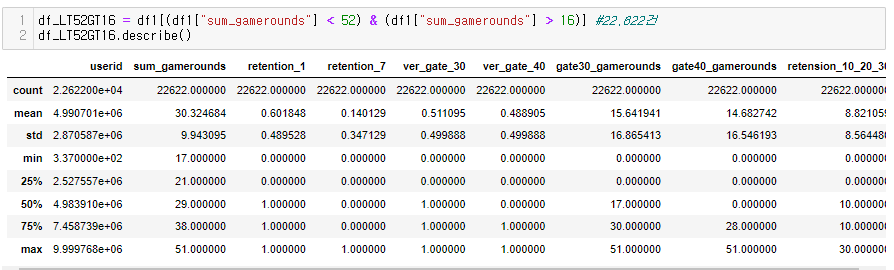
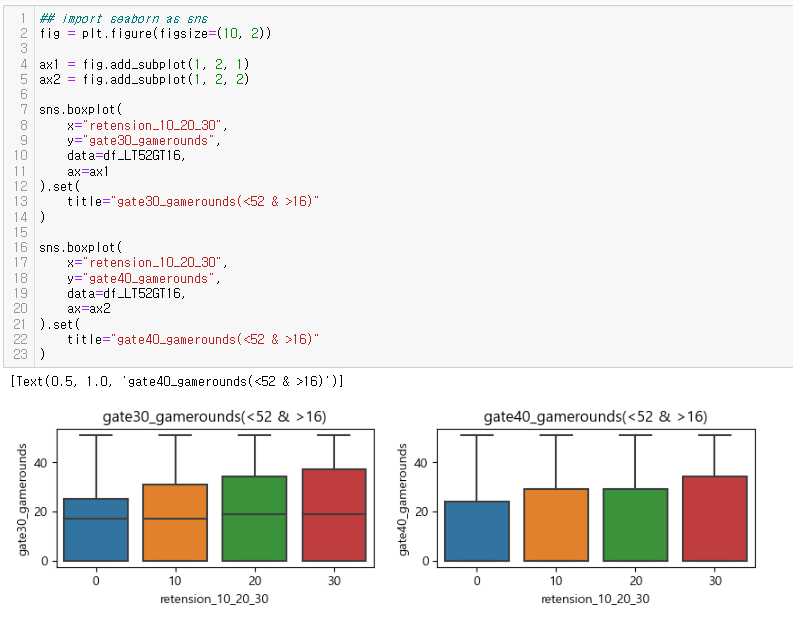
드디어 심봤다... 차이가 있는 구간을.....
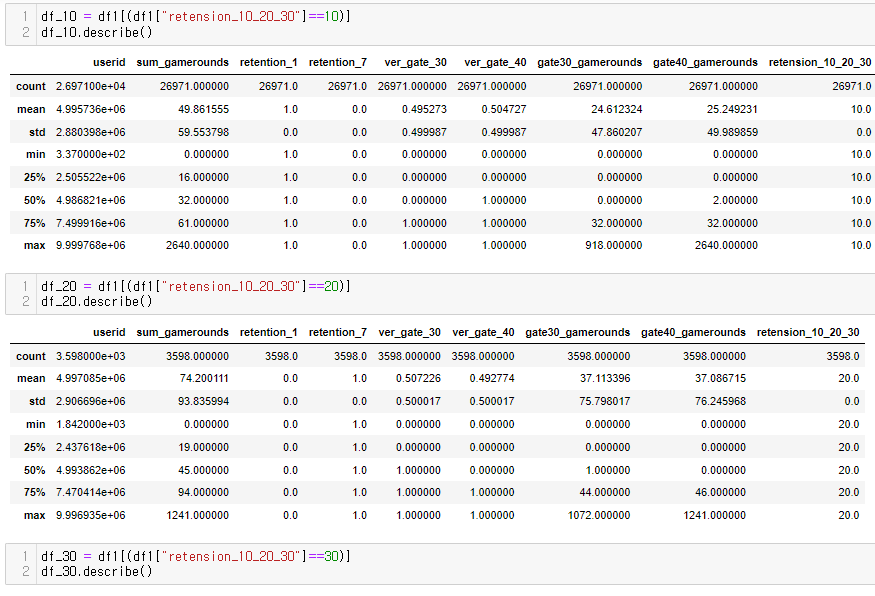
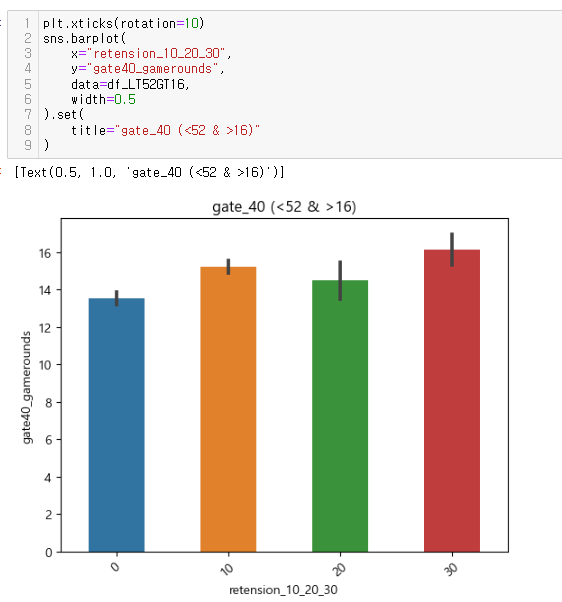
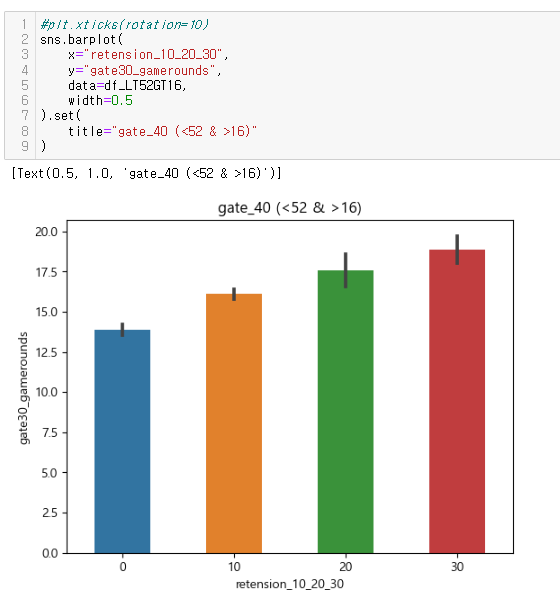
소위 STEP 5 (Finally!!!) 전체 사용자의 50%~75%인 안정적인 플레이어로 나누어 확인
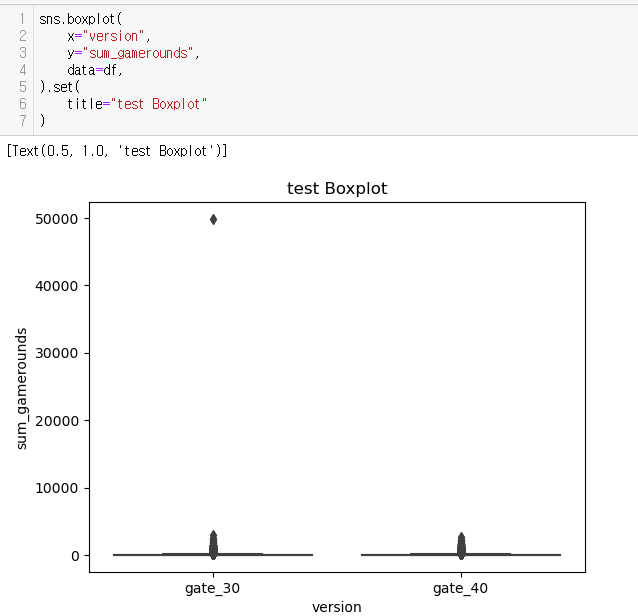
: gate_30의 사용자들은 20회 내외의 중앙값을 보임
: 반면 gate_40의 사용자들의 중앙값이 보이지 않아 게임라운드 평균이 낮을 것이라 판단
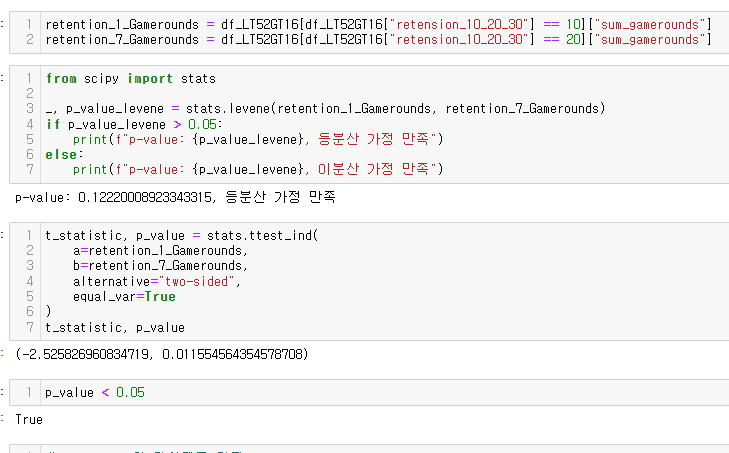
등분산 가정을 만족했고, 귀무가설이 기각되었네ㅋ
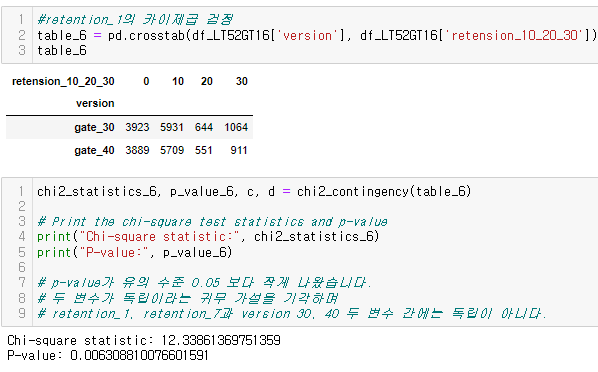
5. 인사이트와 한계점
같은 팀원 velog에서 살짝 훔쳐서 복-붙 했음
🧚♀️인사이트
1) 죄송하지만... 이 게임은 초기 이탈자가 많으세요...💧🙏
: gate 횟수가 다르다 하여 게임 플레이 수에 차이가 있는 것도 아니며, 초기 이탈자가 많기 때문에, 초반에 확실히 기강을 잡아야 한다.
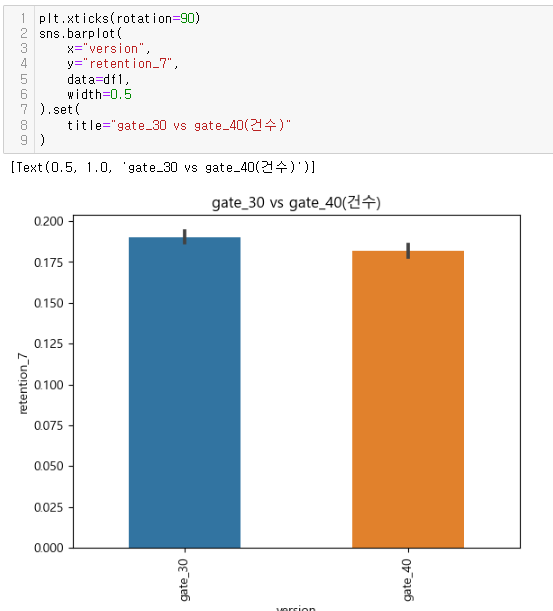
2) 의외로 gate_30을 부여받은 사용자의 충성도가 높았다.
: 보통 Lock을 걸거나 광고를 때리는 걸 최대한 미루는 게 사용자의 흥미를 유발할 것이라 생각했지만, gate_30의 총 게임 플레이 수 평균이 gate_40의 사용자보다 높았다.
3) 게임을 재밌게 다시 바꾸던지 아니면 초반에 보상을 최대화하여 꿈에서도 퍼즐을 맞추게 하고, 게임의 문턱인 gate_30(또는 그 후 gate)을 넘었을 때, 당근을 주며 잠재고객 --> 충성고객으로의 전환을 시도해 보면 어떨까! (당근당근 먹힌당근당근)
🤯한계점
gate 횟수가 다르다 해서 다음 날 접속하는 것과는 관계 없고, 일주일 후에 다시 게임을 하는 것에는 차이가 난다는 검정 결과에 따라 둘 중 어디에서 retention_7의 비율이 더 많은지 확인하려 했지만, 이상치가 많아 분석하기 어려웠다.
상식적으로, 제한을 풀기 위해 일주일 뒤에 찾아오는 수가 많다는 건 당연한거고! 확실한 데이터 가 있었다면 효과가 먹히는 게이트 수를 찾아 조정할 수 있지 않을까!
