71.5% (88/123일)
1. 개 요
[과제]
-
고양이와 강아지의 이미지를 분류하는 DNN 모델을 만들고 활성화 함수를 sigmoid와 ReLU를 각각 사용했을 때와 성능이 월등하게 좋은 CNN 모델의 적용하여 결과 확인
-
데이터 셋 링크: https://www.kaggle.com/datasets/uciml/mushroom-classification
[데이터셋 구조]
실습을 위해 사용할 데이터 셋은 강아지와 고양이 이미지 데이터 셋 구조로서 train과 test 폴더 하위에 고양이와 강아지 이미지가 있으며, labels에는 각 이미지 파일 경로와 라벨이 담겨있다. 라벨은 고양이는 0, 강아지는 1이다.
cats_and_dogs
├── test
│ ├── cats
│ ├── dogs
│ └── label.csv
└── train
├── cats
├── dogs
└── label.csv
DNN VS CNN
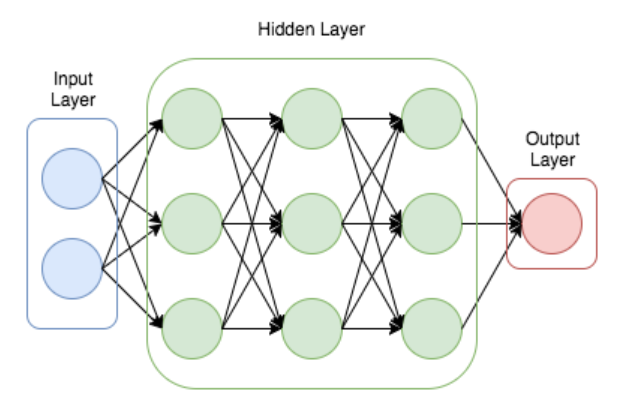
DNN(Deep Neural Network) - 심층 신경망
-
데이터를 구분 짓는 과정을 반복하여 최적의 구분선을 도출해 내며, 출력과 실제 수치 간의 오차를 계산해서 각 레이어의 가중치를 최적싱태로 조절하는 기법, 오류역전파(backpropagation)
-
가중치와 편향을 조정하여 입력 데이터를 출력 데이터로 매핑하는 방식으로, 이 과정은 비선형적인 변환을 수행하며, 각 은닉층은 입력 데이터의 새로운 특징을 추출함
-
2개 이상의 은닉층 존재히고, 망이 복잡한 경우 시간이 오래 걸리며, 결과가 일정하지 않을 수 있으며, 가중치의 의미를 정확하게 해석하기 어려움
CNN(Convolution Neural Network) - 합성곱 신경망
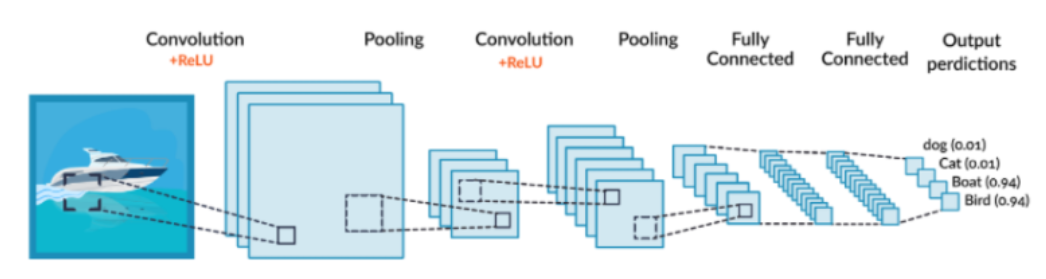
- 정보 추출, 문장 분류, 얼굴인식 등에 널리 사용, Convolution 과정에서 이미지를 특징 계산하고, Pooling 과정에서 이미지 특징 추출 Fully Connected layer을 통과하여 분류 작업된 후 결과 도출
- 이미지에 행렬 형태의 필터를 곱해주어 특정 피쳐를 뽑아내는 기법
- Convolution Layer를 사용하며, 오류 역전파를 이용해서 loss가 최소화 되도록 Convolution 필터 값들을 학습시키는 것
Sigmoid vs ReLU
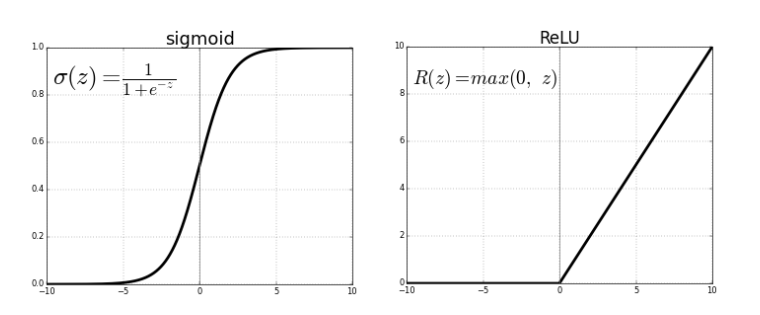
1) 범위:
- Sigmoid: 출력값이 0과 1 사이의 범위로 제한 (sigmoid(x) = 1 / (1 + e^(-x))).
- ReLU: 출력값은 0 이상 (ReLU(x) = max(0, x))입니다.
2) 기울기 소실 문제:
- Sigmoid: 출력값이 0에 가까울 때, 기울기가 크게 감소하여 기울기 소실 문제가 발생할 수 있으며, 학습을 어렵게 만들 수 있음
- ReLU: ReLU는 기울기 소실 문제가 없음
3) 비선형성:
- Sigmoid: 강한 비선형성을 제공
- ReLU: ReLU 함수는 입력값이 양수일 때 선형적인 변환을 제공하며, 입력값이 음수일 때만 비선형성
4) 학습 속도:
- Sigmoid: 시그모이드 함수는 기울기가 작고 부드러운 특성을 가지므로, 학습 속도가 느릴 수 있음
- ReLU: 기울기 소실 문제가 없기 때문에 ReLU는 일반적으로 시그모이드보다 학습 속도가 빠를 수 있음
시그모이드는 출력값을 0과 1 사이의 범위로 제한해야 하는 분류 문제에 적합할 수 있고, ReLU는 깊은 신경망에서 학습 속도를 향상시키고 기울기 소실 문제를 방지하는 데 유용할 수 있음
model 학습 때 고려할 점
1) 디바이스 일치: 모델, 데이터, 레이블을 같은 디바이스(CPU, GPU - CUDA)
2) 메모리 관리: 대용량 데이터 처리 시
3) 손실함수와 옵티마이저 설정: 모델과 데이터에 맞는 함수 선택, loss function, CrossEntropyLoss, MSELoss, Adam, SGD, learning rate etc.
4) 모델의 올바른 입력 차원: 모델에 맞는 입력 크기를 확인, 입력 데이터의 차원과 실제 데이터의 차원이 일치 여부
5) 배치 사이즈 관리: 너무 크면 메모리 초과, 너무 작으면 학습 속도 느림
6) 텐서를 NumPy 배열로 변환하려면 반드시 .cpu()를 사용해야 함
2. 이미지 전처리 및 학습 준비
-
콜랩에서 압축파일 풀기
!unzip "./drive/MyDrive/multicampus/cats_and_dogs.zip" -d "/content" -
CustomImageDataset 클래스
. torch.utils.data.Dataset 클래스를 상속받아서 init, len, getitem 3개의 메서드를 구현
. init: 클래스 초기화 메서드, 이미지 데이터셋의 경로와 변환 함수 (transform)를 인자로 받으며, CSV 파일을 로드하여 이미지 파일 경로와 레이블을 저장함
len: 데이터셋의 총 샘플 수를 반환하는 메서드, 즉, CSV 파일의 행 수를 반환함
getitem: 인덱스로 데이터셋에서 샘플을 가져오는 메서드, 인덱스에 해당하는 이미지 파일 경로와 레이블을 가져오며, 이미지를 로드하고 변환 함수를 적용한 후, 이미지와 레이블을 튜플로 반환함. 이미지 데이터셋을 생성하고, 변환 함수를 적용하여 데이터를 전처리할 수 있음 -
입력 데이터 : train data 8,000마리, test data 2,000마리
len(train_dataset), len(test_dataset)
(8000, 2000) -
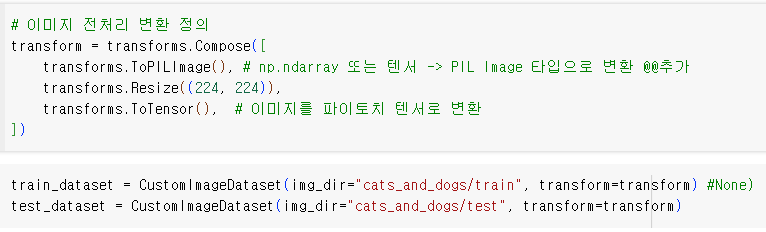
이미지 전처리 변환 정의
transforms.Resize(224, 224),
-
img, label = train_dataset[4500]
plt.imshow(img.numpy().transpose(1, 2 ,0), cmap="Greys")

-
img, label = train_dataset[4500]
plt.imshow(img.numpy().transpose(1, 2 ,0), cmap="Pastel1")
-
plot_img_tensor(train_dataset[254][0])

-
batch_size = 128 #--> 32, 64, 128, 256 변경test
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True) -
batch.shape, labels.shape
(torch.Size([32, 3, 224, 224]), torch.Size([32]))
3. DNN, CNN 학습 및 결과 시각화
DNN single 모델
SingleLayerPerceptron(
(fc): Linear(in_features=150528, out_features=10, bias=True)
(softmax): Softmax(dim=1)
)
- 3x224x224 (설정 수정 후의 결과) <-- 224x224x3 (설정 착오)
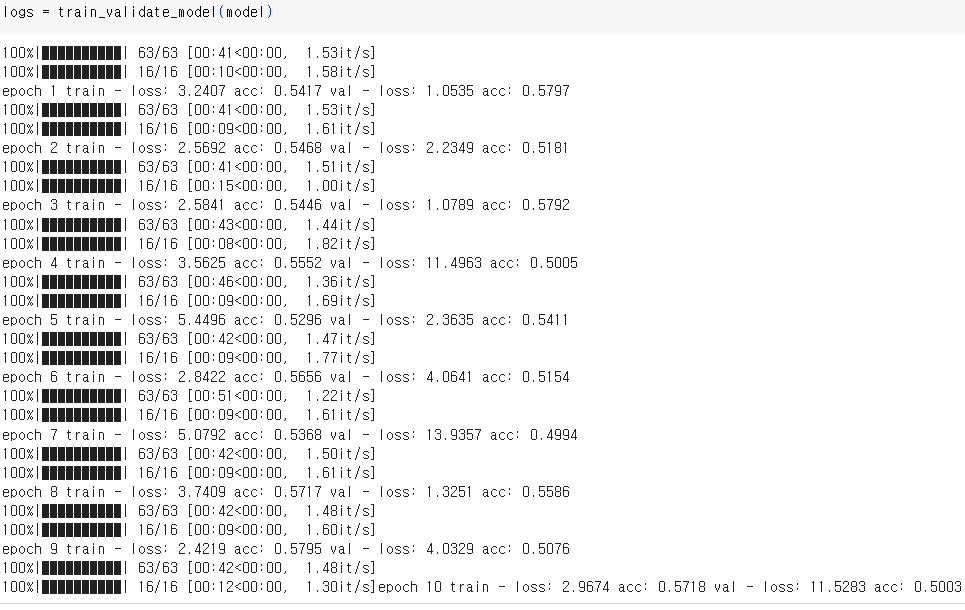
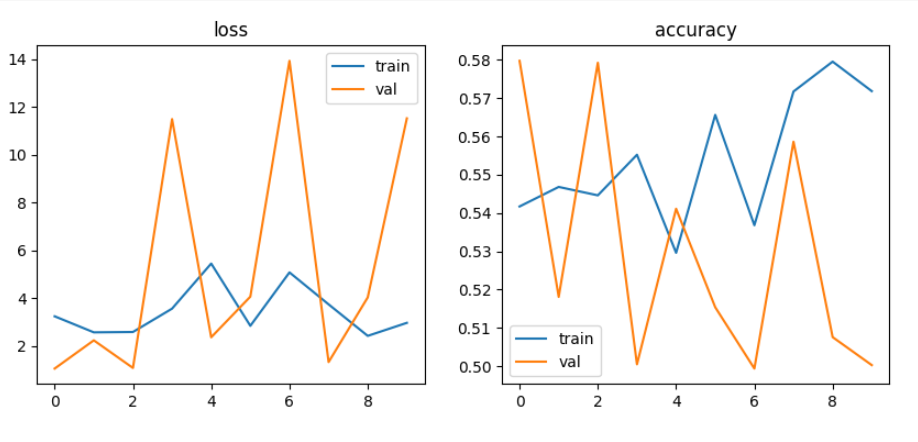
파라미터 변경하여 학습 및 시각화
- batch_size = 32
하이퍼 파라미터 셋팅
learning_rate = 0.0001
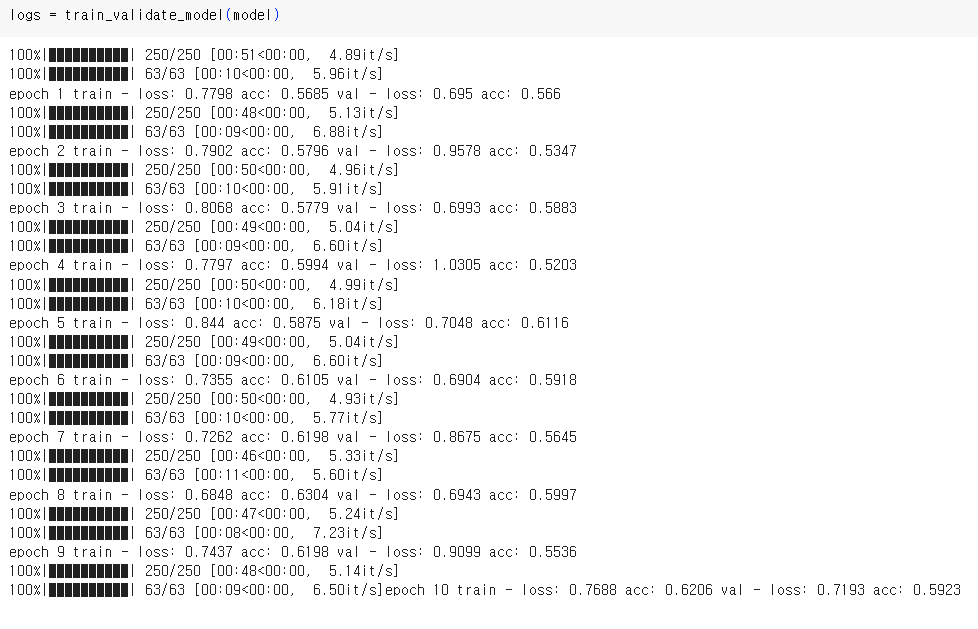
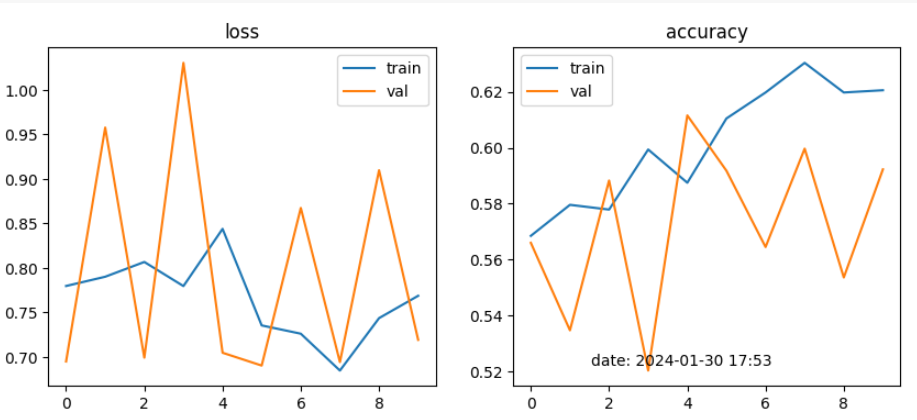
DNN Multilayer Perceptron Classifier
MultiLayerPerceptron(
(fc1): Linear(in_features=150528, out_features=50, bias=True)
(fc2): Linear(in_features=50, out_features=10, bias=True)
(activation): Sigmoid()
)
하이퍼 파라미터 셋팅
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10
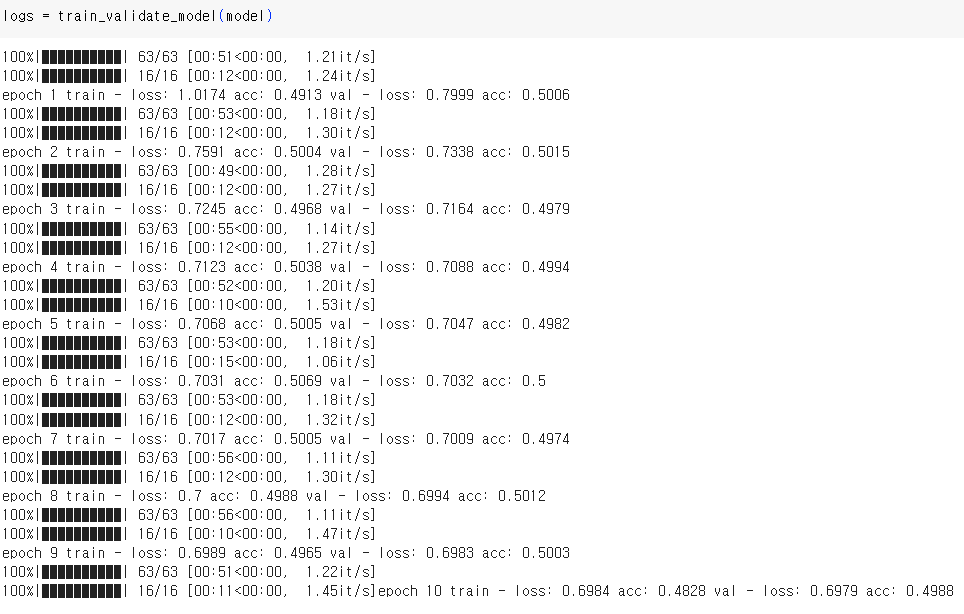
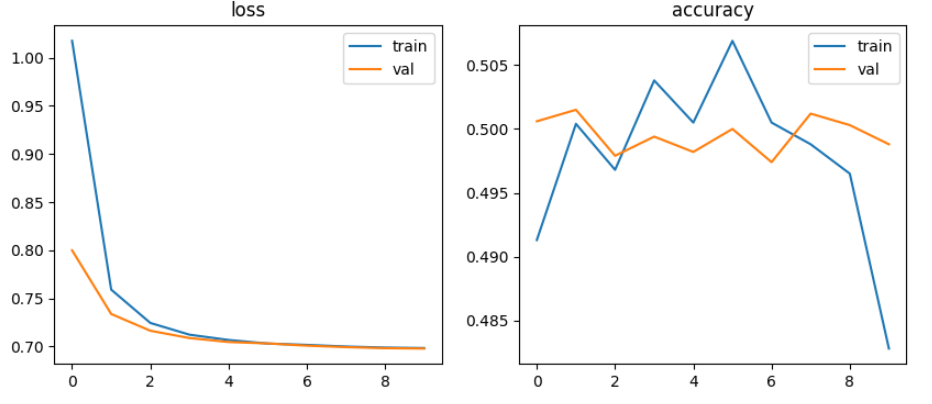
파라미터 변경하여 학습 및 시각화
- batch_size = 32
하이퍼 파라미터 셋팅
learning_rate = 0.0001
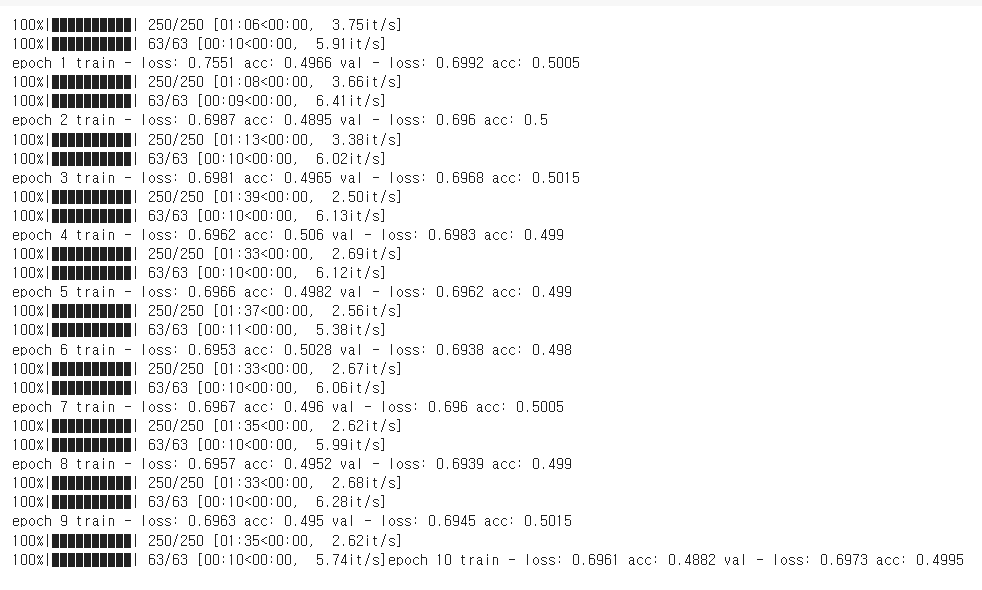
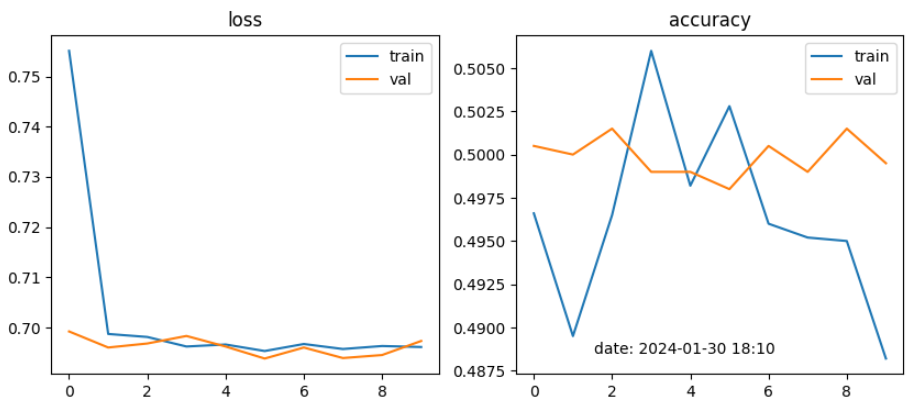
DNN Vanishing Gradient, ReLU
- 10층으로 구성된 깊은 신경망 모델
- 하이퍼 파라미터 셋팅
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10
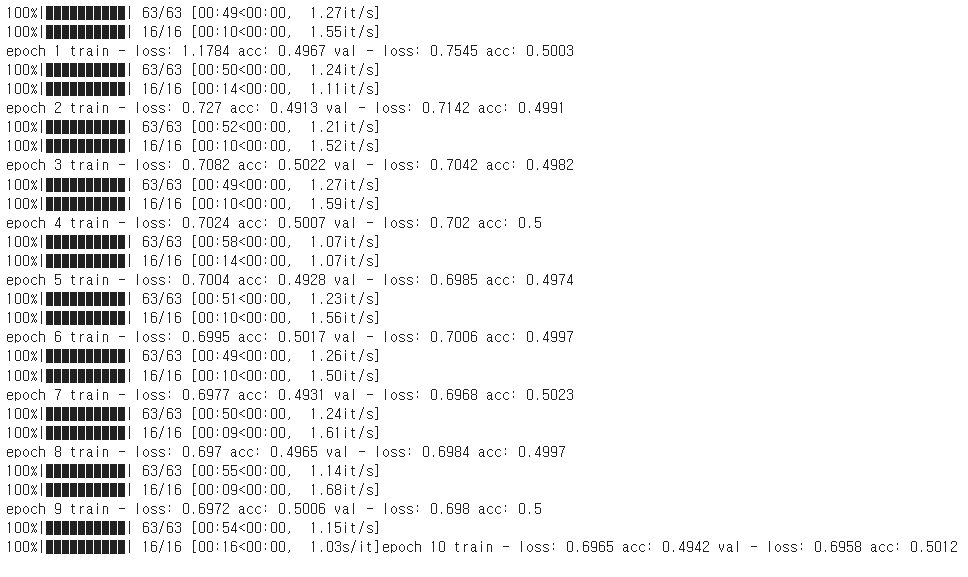
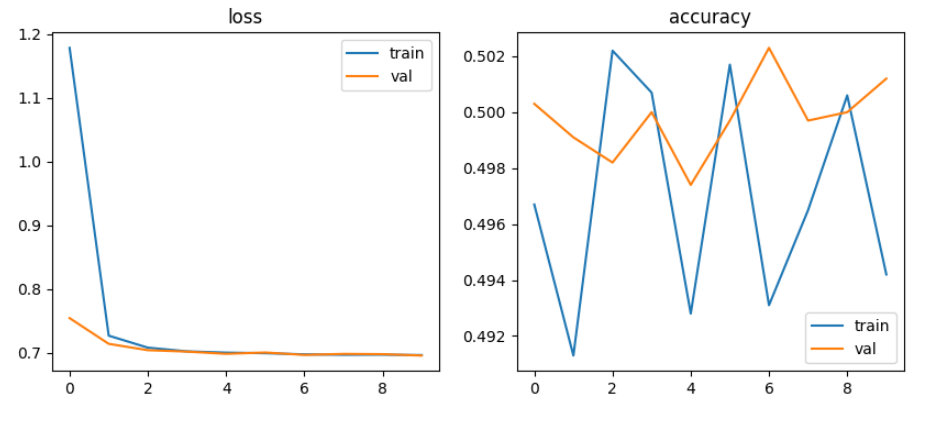
파라미터 변경하여 학습 및 시각화
- batch_size = 32
하이퍼 파라미터 셋팅
learning_rate = 0.0001

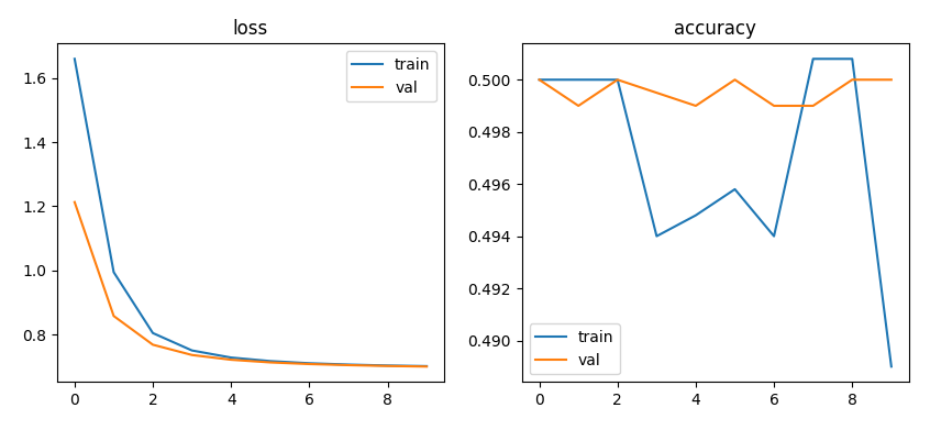
simpleCNN, Pretrained Model, fine-tuning
- Simple CNN 적용
착안 사항 : in_features=165656

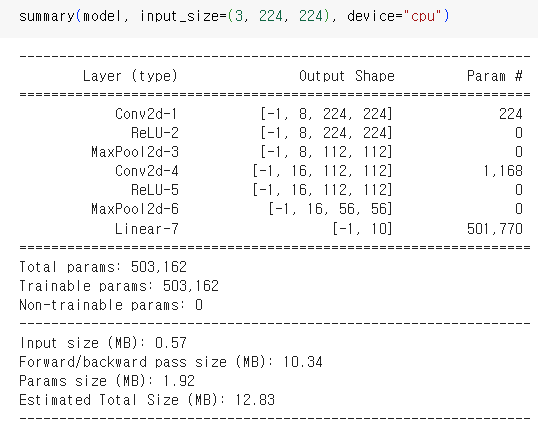
learning_rate = 0.001

CNN Pretrained Model 적용
- ResNet18 모델을 fine-tuning 준비
from torchvision.models import resnet18, ResNet18_Weights
weights = ResNet18_Weights.IMAGENET1K_V1
transform = weights.transforms()
train_dataset = CustomImageDataset("./cats_and_dogs/train", transform=transform)
test_dataset = CustomImageDataset("./cats_and_dogs/test", transform=transform)
-(3, 224, 224) 크기로 입력 이미지를 Resize한 다음, 정규화를 통해 소수로 변환시켜 줌


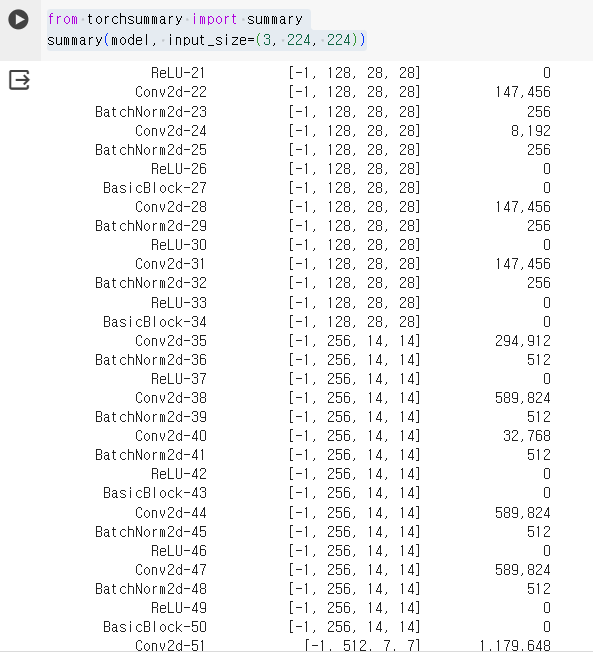
- 모델 준비
torch에 내장된 resnet18 모델을 불러와서 마지막 FC layer를 2진 분류에 맞게 교체해 줌
model = resnet18()
model.fc = torch.nn.Linear(in_features=512, out_features=2)
.........................................................
from torchsummary import summary
summary(model, input_size=(3, 224, 224))
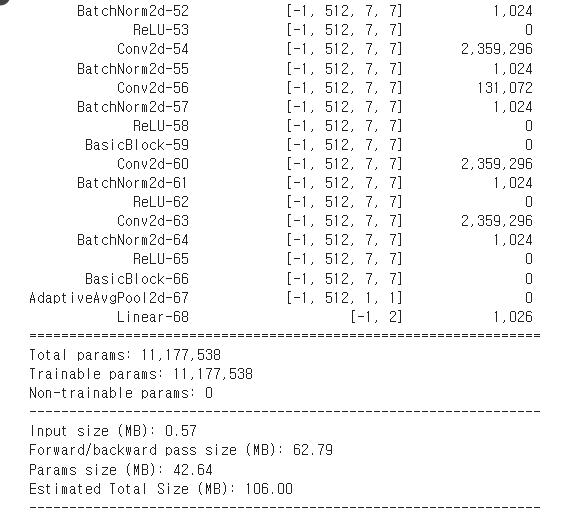
-
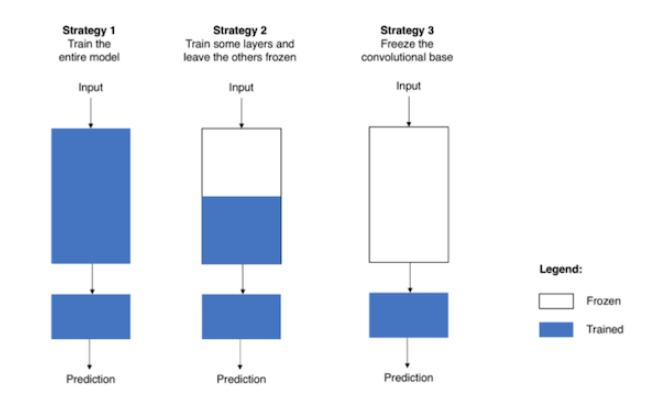
Strategy 1: pretrained 모델을 가져와 전체 레이어들을 fine-tuning하는 방법
-
Strategy 2: 일부 Convolution Layer와 Fully Connected Layer를 학습시키는 방식
-
Strategy 3: 마지막 Fully Connected Layer만 학습시키는 방식
Strategy 0. Train from scratch
- pretrained weight 없이 모델을 가져와서 처음부터 학습을 시킴
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10
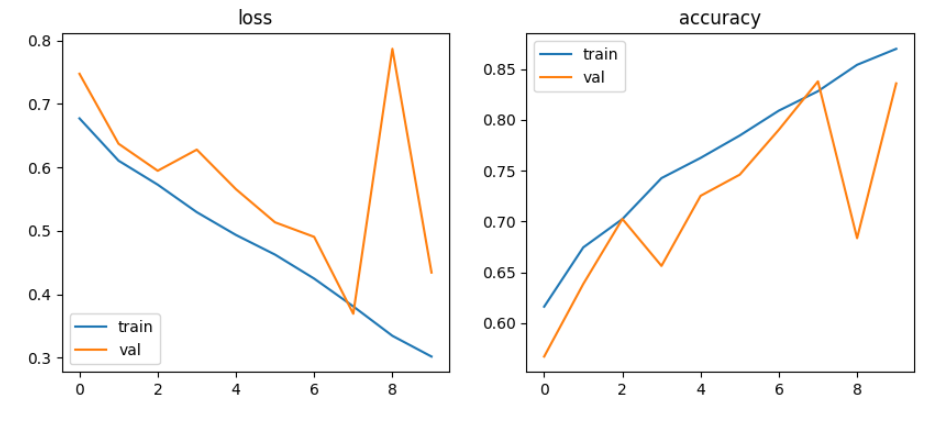
learning_rate = 0.002

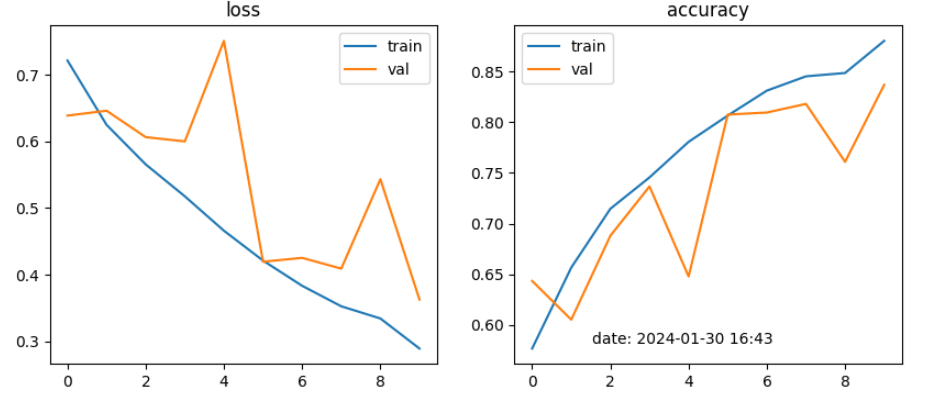
learning_rate = 0.00001

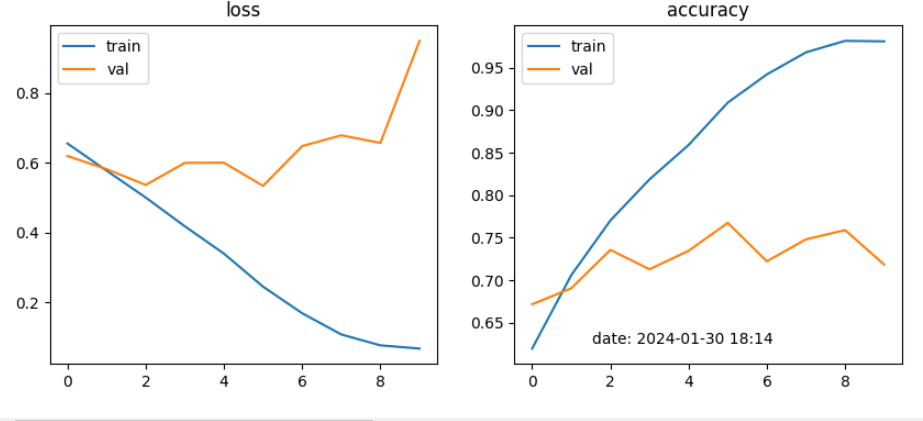
Strategy 1. Finetune entire model
model = resnet18(weights=weights)
model.fc = torch.nn.Linear(in_features=512, out_features=2)
model = model.to(device)
learning_rate = 0.001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
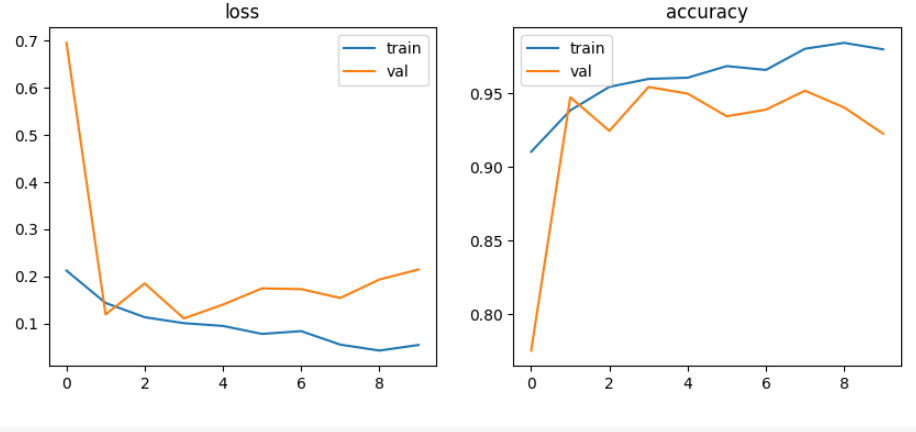
learning_rate = 0.002
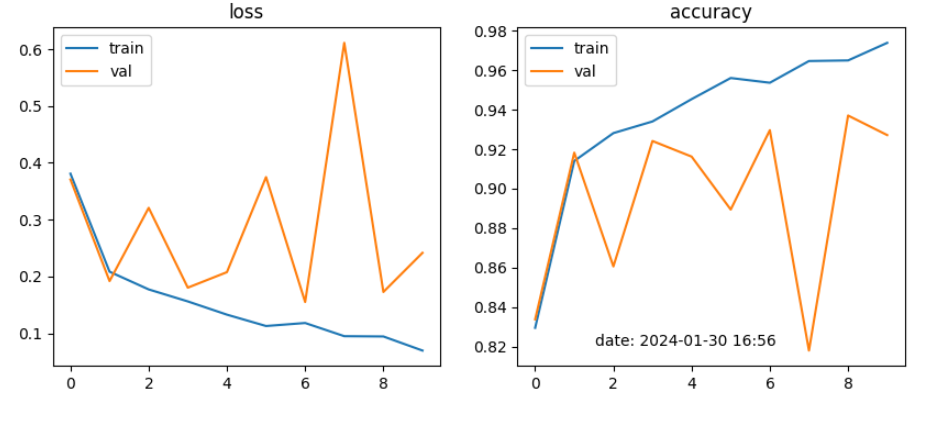
learning_rate = 0.00001
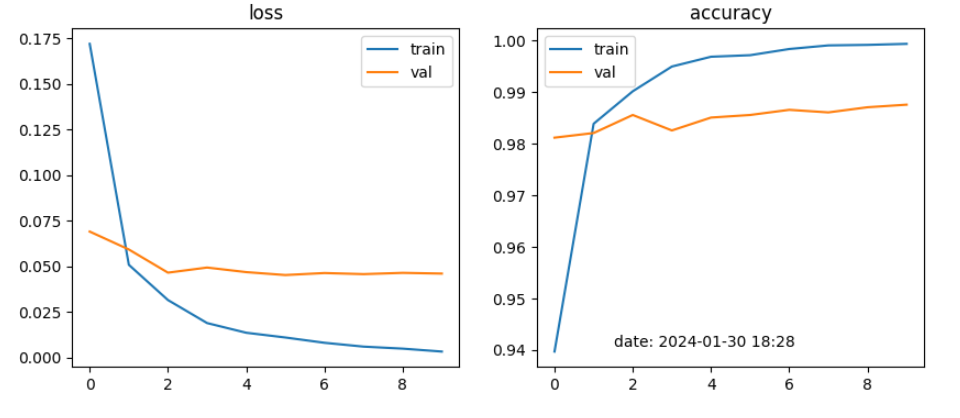
Strategy 2. Finetune some convolution layer

learning_rate = 0.001

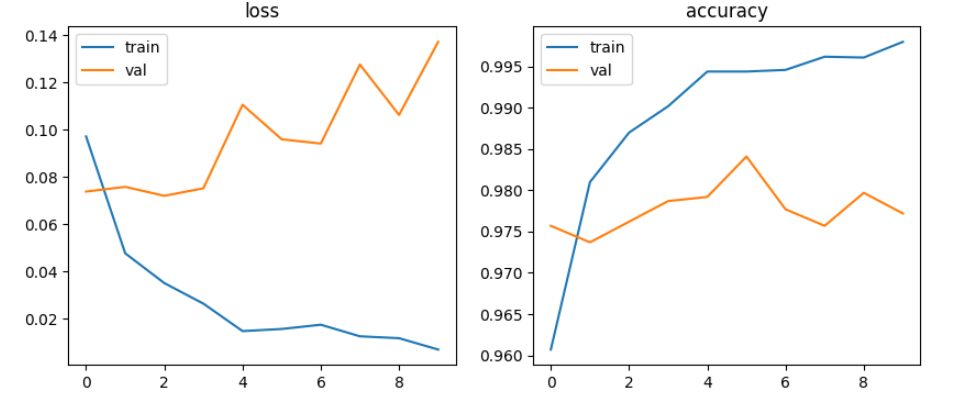
learning_rate = 0.002
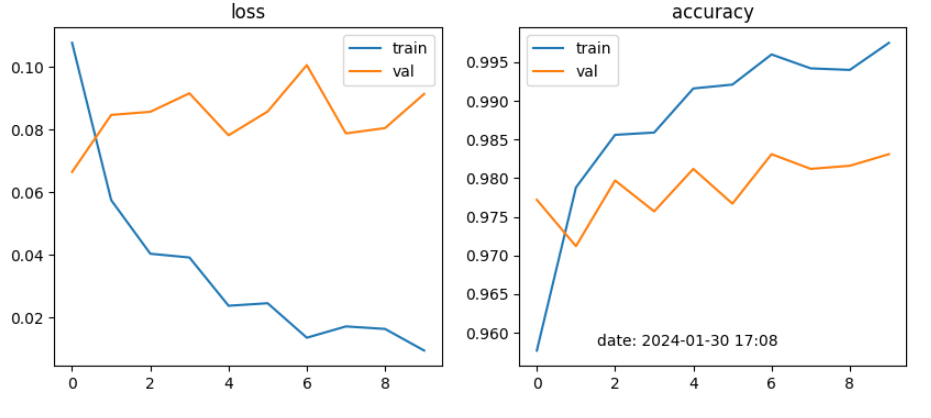
learning_rate = 0.00001
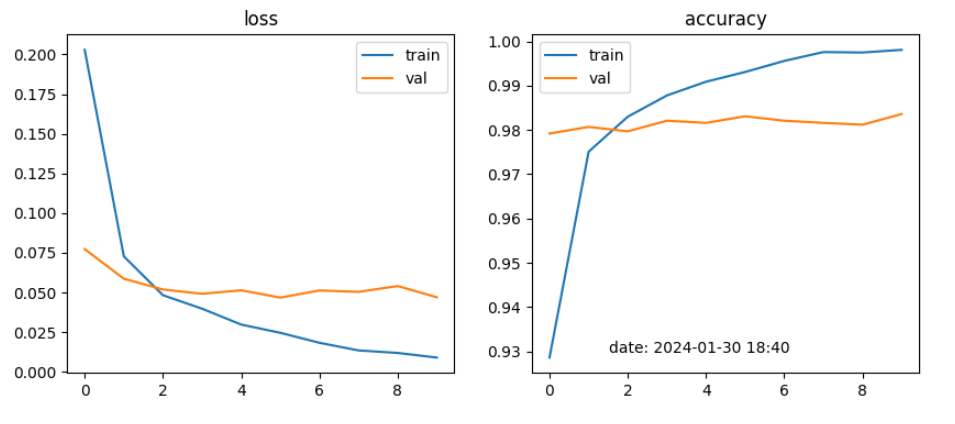
Strategy 3. Finetune only FC layer

learning_rate = 0.001


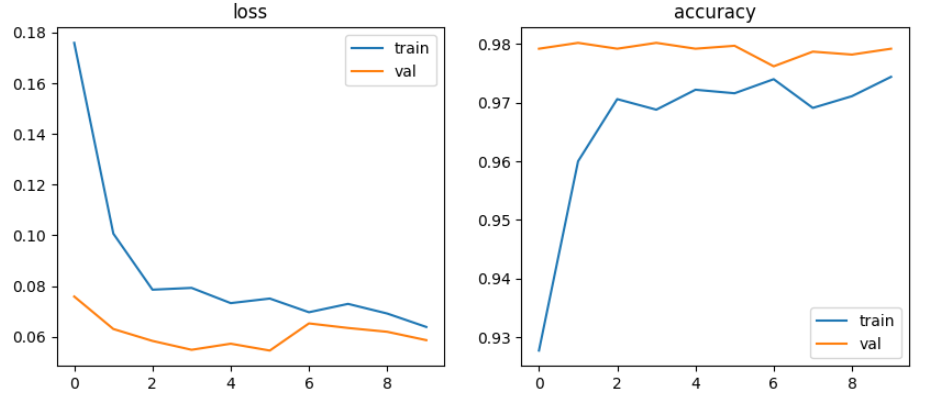
learning_rate = 0.002

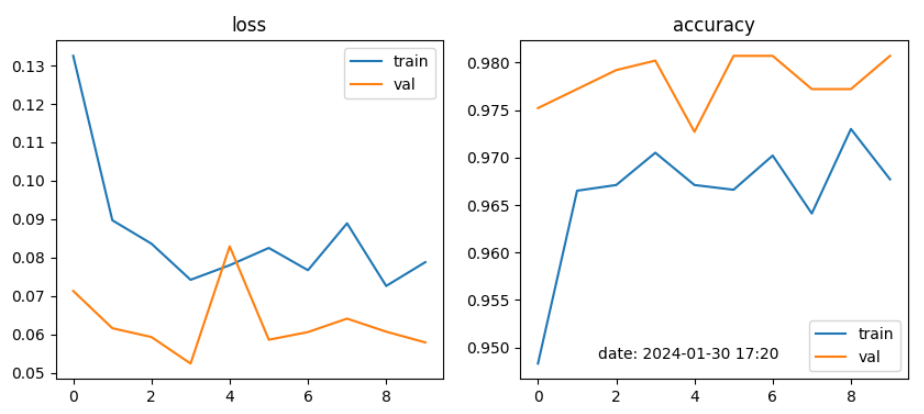
learning_rate = 0.00001

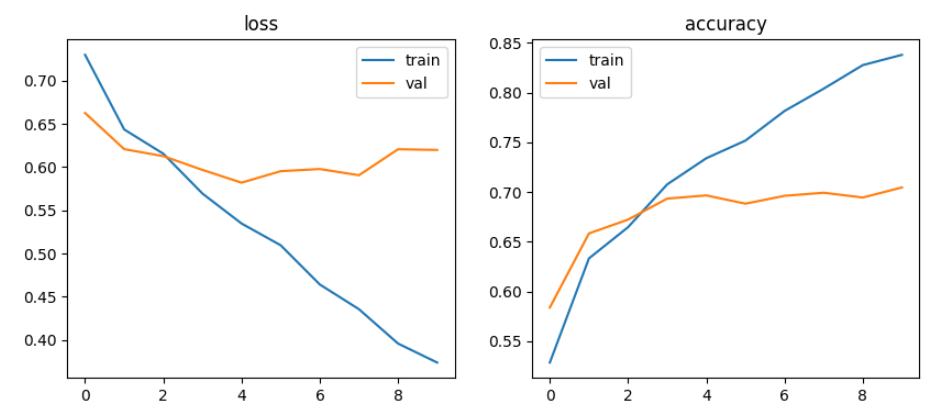
결론
-
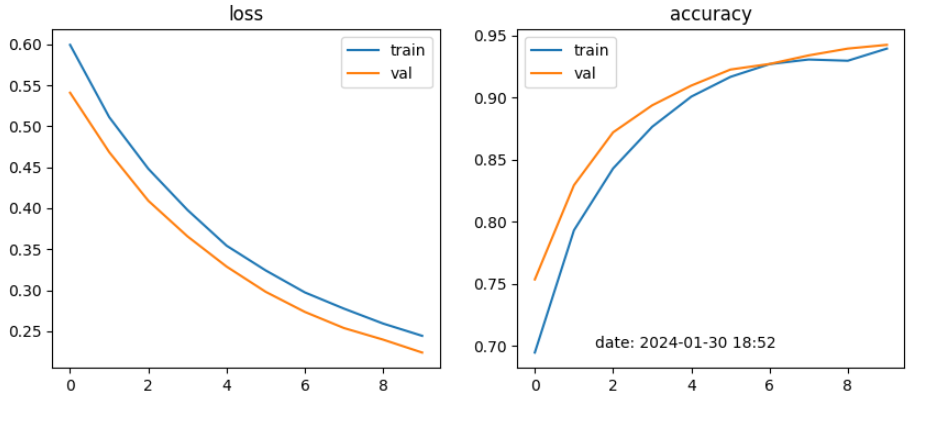
cats and dogs 이미지 데이터 10,000건(train_data 8,000건, test_data 2,000건)을 DNN 및 CNN 모델 학습과정에서 validation data의 accuracy가 DNN에서는 50% 전후 였으나, CNN모델에서 95~98%의 월등한 정확성을 나타내었음
-
DNN모델에서 batch size를 128, 32로 learning rate를 0.001, 0.0001로 적용해 본 결과 Multilayer Perceptron, Vanishing Gradient, ReLU에서는 정확도가 50% 전후로 별 상이함이 없었으나, single모델에서 32, 0.0001로 설정했을 때 55%~61% 다소 높았음
-
CNN모델에서는 4가지 전략을 학습한 결과, Strategy 2와 Strategy 3가 각각 97% 이상 높은 성능을 보였으며, Strategy 3이 98%로 좋은 결과가 나타났음.
-
CNN모델에서는 4가지 전략에서 learning rate를 각각 0.001, 0.002, 0.000001로 변경하여 적용 결과, 0.001이 성능이 가장 좋았음
