1. 개요
-
각 국가별 사회적, 경제적 지표들이 들어있는 data set을 이용하여, 이들 국가들을 다양한 계층적 군집 분석을 통해서, 대륙은 다르지만 같은 군집으로 분류되는 국가들은 어떤 특징을 가지고 있는지 분석해 본다.
-
data set url: https://www.kaggle.com/datasets/ashydv/country-socioeconomic-data
-
DataSet의 records: 167건
-
DataSet의 13개 columns:
country: 국가 이름
child_mort: 1000명당 5세 미만 아동 사망률
exports: 상품 및 서비스 수출. 총 GDP 대비 백분율로 표시됨
health: 총 건강 지출. 총 GDP 대비 백분율로 표시됨
imports: 상품 및 서비스 수입. 총 GDP 대비 백분율로 표시됨
Income: 개인 당 순소득
Inflation: 총 GDP의 연간 성장률 측정
life_expec: 현재 사망률 패턴이 지속된다고 할 때, 신생아의 평균 수명
total_fer: 현재의 연령별 출산율이 유지된다고 할 때, 각 여성당 출산될 아이의 수
gdpp: 1인당 GDP. 총 GDP를 총 인구로 나눈 값
region_1: 지역 구분 1
region_2: 지역 구분 2
continent: 대륙 -
참고 자료: https://www.kaggle.com/code/ashydv/country-clustering-hierarchical-clustering-pca
- 주요 관심사는 군집화 과정에서 몇년 전에 활동했던 아프리카 국가들, 그리고 한국이 어떤 국가들과 그룹화가 되는지?
2. EDA(Exploratory Data Analysis)
-
결측치 확인
df.isnull().sum() --> region_2 101건
null값이 아닌 66건(df[df["region_2"].notna()]) 확인 결과 값은 남미 카리브 "Latin America and the Caribbean"와 사하라 이남 블랙아프리카 "Sub-Saharan Africa"의 2종류로만 구분되어 있음. 따라서 null값은 "Unclassified area"로 값을 채워 주었음.
df.fillna("Unclassified area") -
seaborn에서 clustermap 시각화
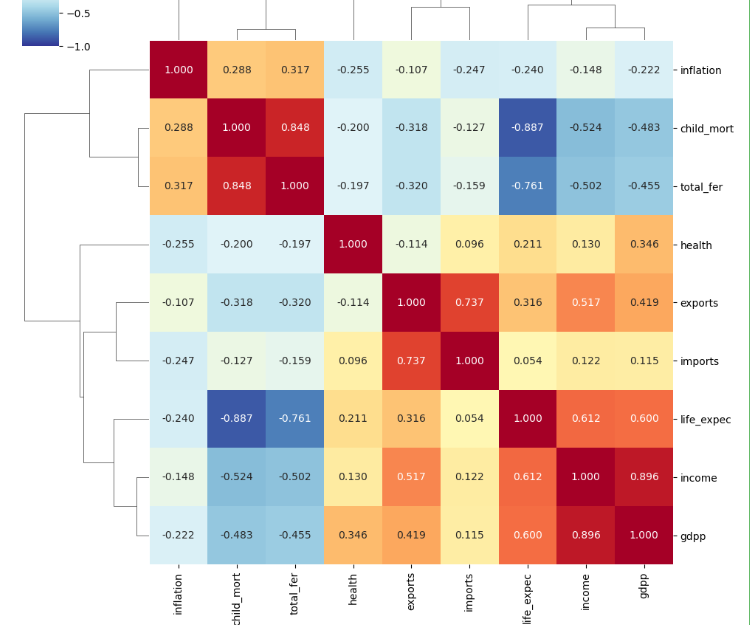
-
상관관계가 높은 항목
gdpp, income (1인당 GDP, 개인 당 순소득)
imports, exports (수입, 수출)
total_fer, child_mort (여성당 출산될 아이, 5세 미만 아동 사망률)
-
각 대륙별 수치항목에 대한 비교
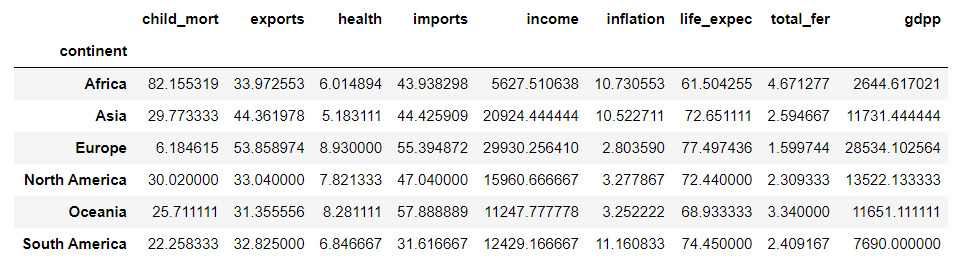
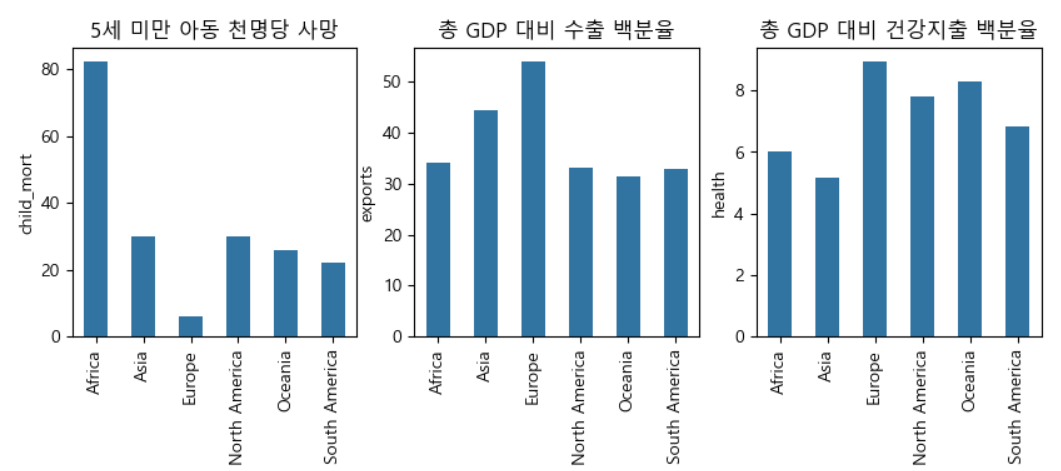
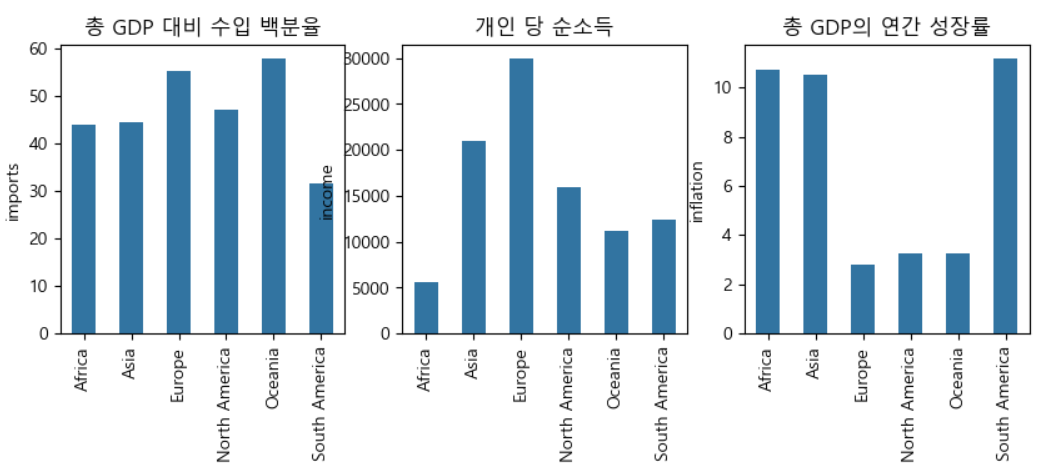
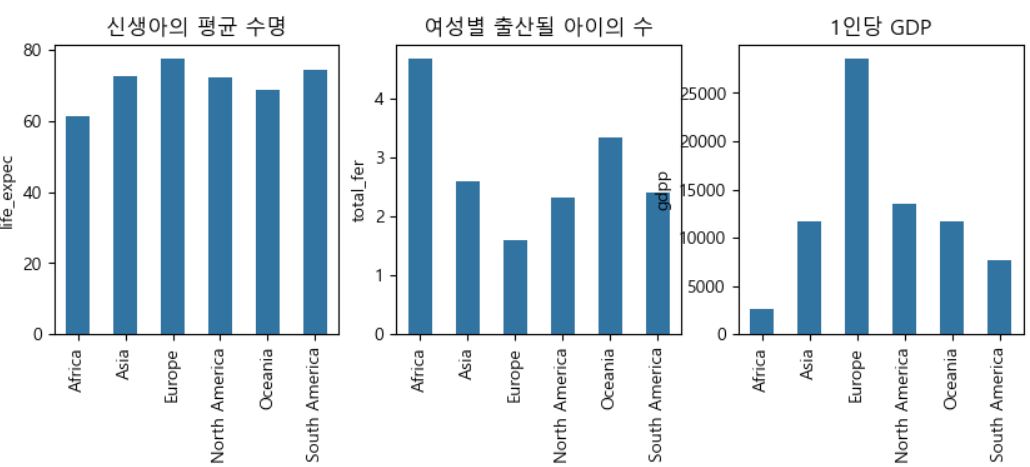
-
사하라 이남 불랙 아프리카 및 남아메리카 지역 특성치 비교
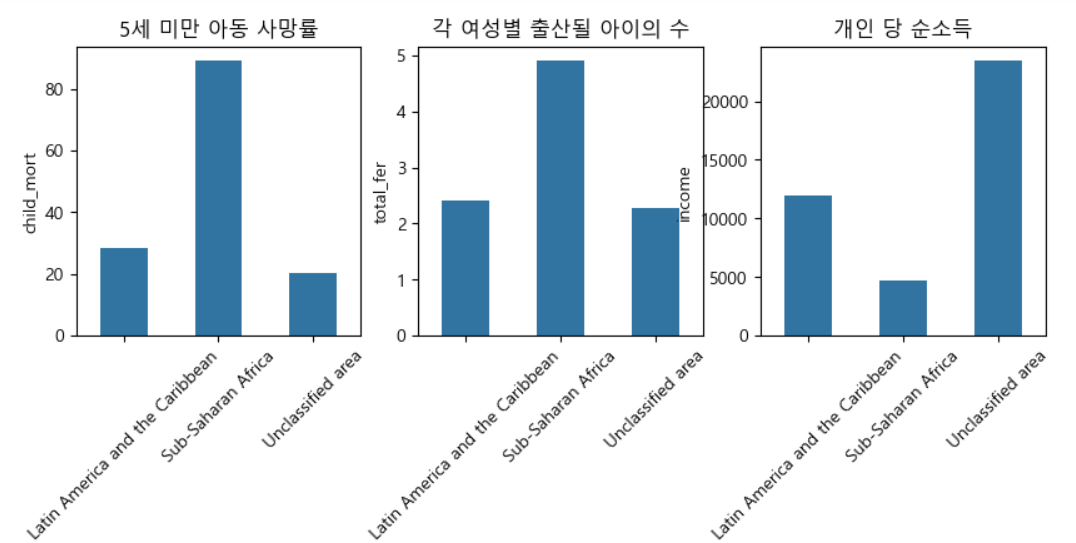
-
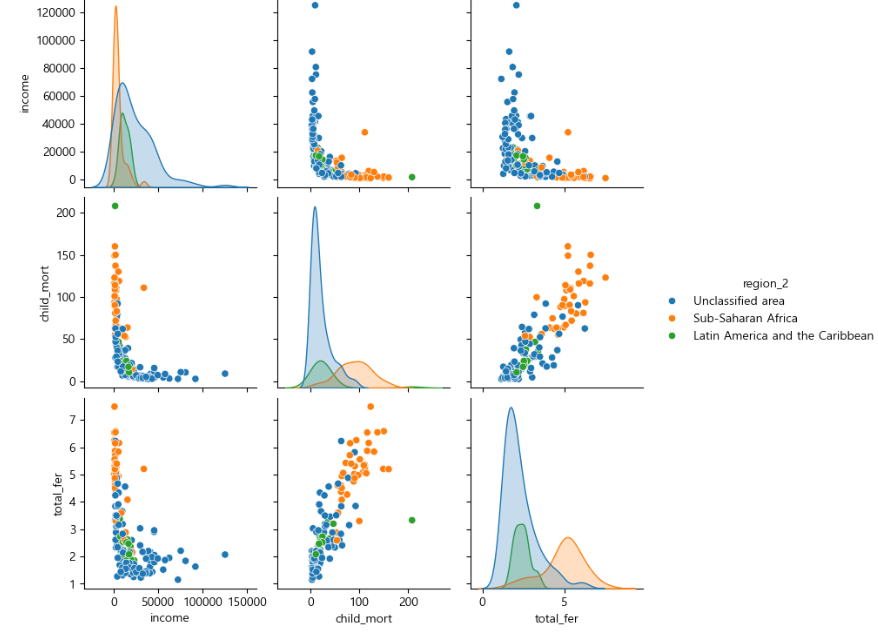
변수들간에 상관관계 및 분포를 비교하기 위해 pairplot 시각화
3. 군집화 및 특징 분석
계층적 군집화(hierachical clustering)는 한 군집 내에 부분 군집을 허용하는 방법으로 서로 가까운 데이터 샘플끼리 군집으로 묶어나가면서 최종적으로는 전체 데이터 샘플을 하나의 클러스터로 묶는 방법, 즉 여러개의 군집 중에서 가장 유사도가 높거나 거리가 가까운 군집 두 개를 선택하여 하나로 합치면서 군집 개수를 줄여 가는 방법
펭추리가 알려준 군집화 절차
군집화를 위한 절차는 일반적으로 다음과 같아요:
-
데이터 전처리: 누락된 값 처리, 범주형 데이터 인코딩, 특성 스케일링(정규화 또는 표준화)
-
거리 측정 방법 선택: 유클리드, 맨해튼, 민코우스키 등
-
연결 방식 결정:
- 최단 연결법(Single Linkage): 클러스터 간의 가장 짧은 거리
- 최장 연결법(Complete Linkage): 클러스터 간의 가장 긴 거리
- 평균 연결법(Average Linkage): 클러스터 간의 평균 거리
- 와드 연결법(Ward's Method): 클러스터 내 분산을 최소화하는 방향
-
Dendrogram 생성 및 해석: scipy의
dendrogram함수 사용 -
적절한 클러스터 수 결정: 덴드로그램을 보고 클러스터 수 결정
알고리즘 진행 과정은 대략 이렇게 되죠:
- 데이터셋에서 모든 관측치를 각각 하나의 클러스터로 시작해요.
- 가장 가까운 두 클러스터를 찾아서 하나로 합쳐요.
- 이 과정을 계속 반복하면서 클러스터 수를 줄여나가요.
- 클러스터 수가 사용자가 정한 값에 도달하면 중지해요.
해석 방법:
- 덴드로그램을 통해 어떤 클러스터들이 언제 합쳐졌는지를 설명할 수 있어요.
- 거리 또는 높이를 기준으로 클러스터를 결정하고, 이를 데이터의 자연스러운 분할로 해석할 수 있죠.
- 클러스터 간의 상대적인 거리를 통해 클러스터 내의 결합도와 클러스터 간의 분리도를 평가할 수 있어요.
단, 클러스터링은 탐색적 데이터 분석 기법이기에, 결과에 대한 해석은 주관적일 수 있고 데이터의 맥락에 따라 달라질 수 있어요. 그래서 해석에는 주의가 필요하답니다! 🐧💡
실루엣 계수와 덴드로그램은 클러스터 개수를 결정하는 데 사용되는 두 가지 다른 접근 방식이에요.
-
실루엣 계수(Silhouette Score): 클러스터 내의 데이터 포인트 간 코히전(응집성)과 서로 다른 클러스터 간의 분리도(분리성)를 평가해요. 높은 실루엣 점수는 잘 분리된 클러스터를 나타내요.
-
덴드로그램(Dendrogram): 계층적 클러스터링에서 사용됩니다. 덴드로그램은 클러스터가 어떻게 합쳐지는지를 시각화해요. "긴 브랜치"를 보고 적당한 클러스터 개수를 결정할 수 있어요.
실루엣은 클러스터의 품질을, 덴드로그램은 계층 구조를 각각 반영해요!
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
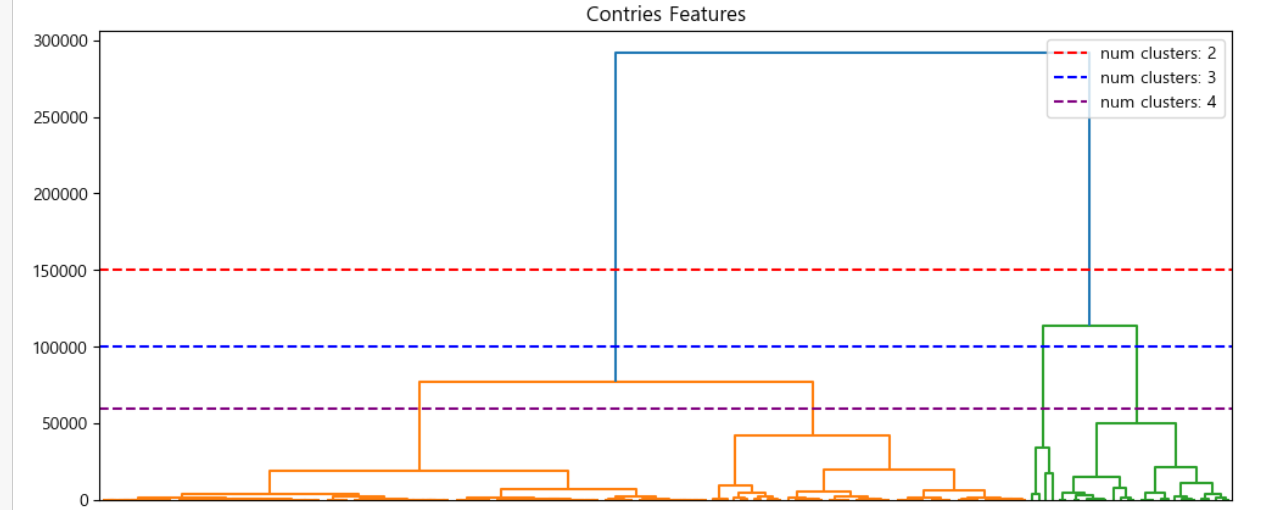
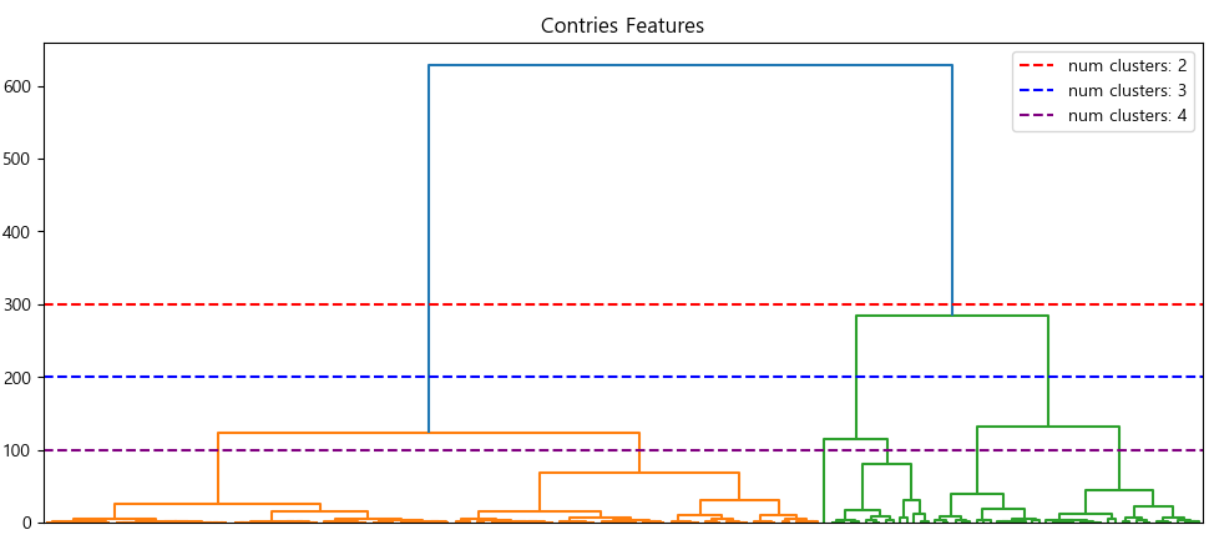
댄드로그램을 이용한 클러스터 개수 결정
dendrogram의 "ward"기법을 사용하여 시각화 결과
각 독립변수를 적용하여 개인당 순소득의 종속변수를 적용한 결과
크러스터 갯수를 2,3,4... 으로 구분해 봄
- 개인 당 순소득의 종속변수의 변화
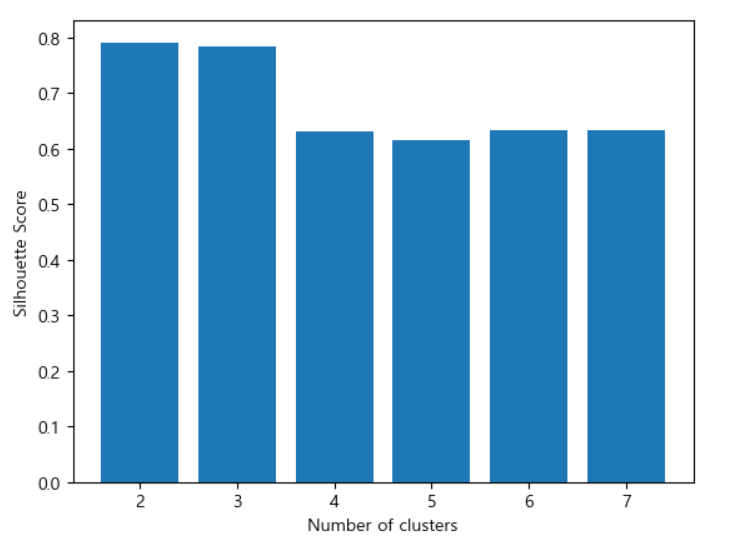
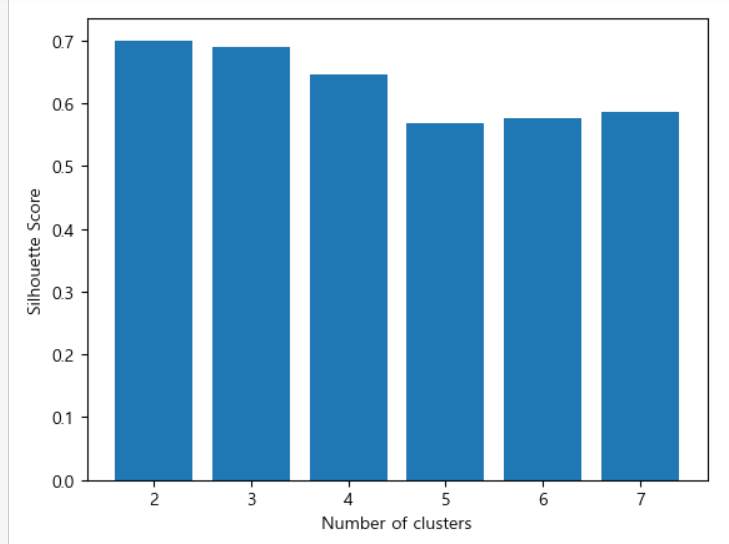
실루엣 계수를 이용한 클러스터 개수 결정
클러스터가 2,3개가 거의 비슷하며 3개로 정해서 테스트 해 봄
계층적 군집 모델 학습 및 시각화(1)
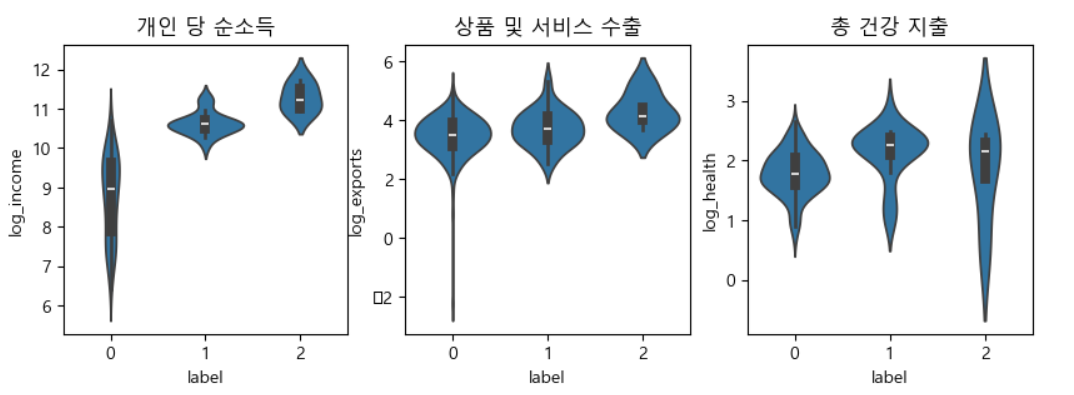
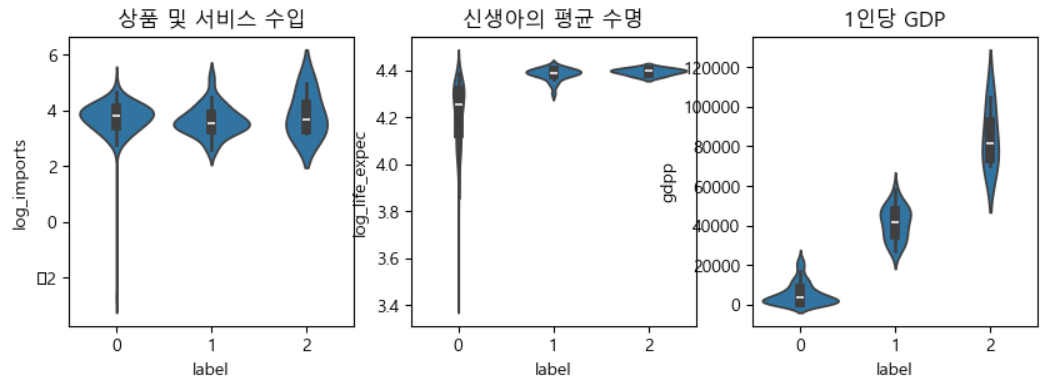
X = df[['exports', 'health', 'imports', 'life_expec','gdpp']]
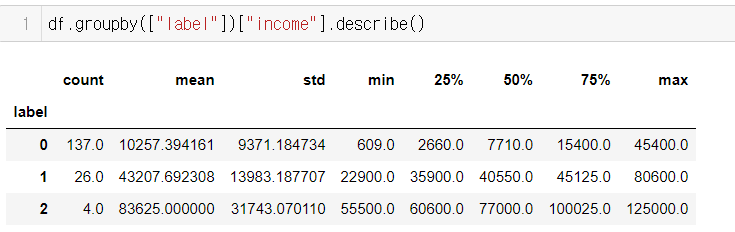

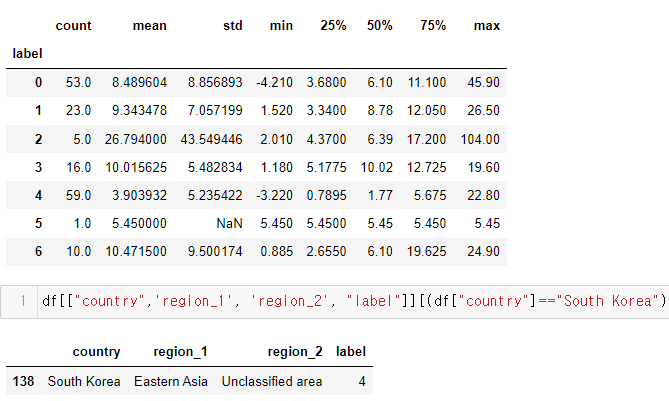
label 2의 4개국은 Luxembourg, Norway, Qatar, Switzerland 으로 income 5만 이상이면서 gdpp 7만이상의 국가이며, label 1의 26개국은 Australia, Austria, ..., Spain, Sweden, Arab Emirates, United Kingdom, United States 등의 국가가 이 분류에 포함되었음
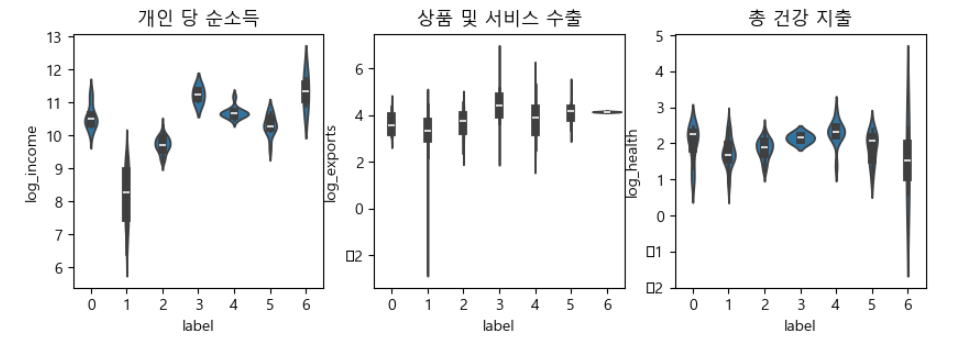
계층적 군집 모델 학습 및 시각화(2)
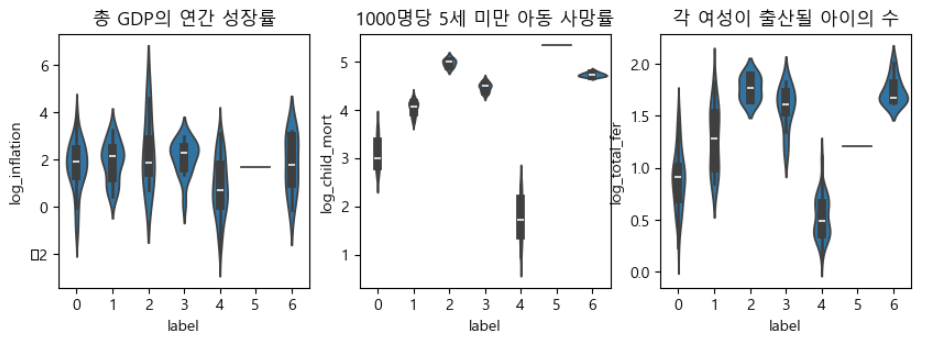
- 총 GDP의 연간 성장율, 1000명당 5세 미만 아동 사망률, 각 여성당 출산될 아이의 수 항목에 대하여 덴드로그램, 실루엣 계수를 적용한 후 계층화
X = df[['child_mort', 'total_fer']]
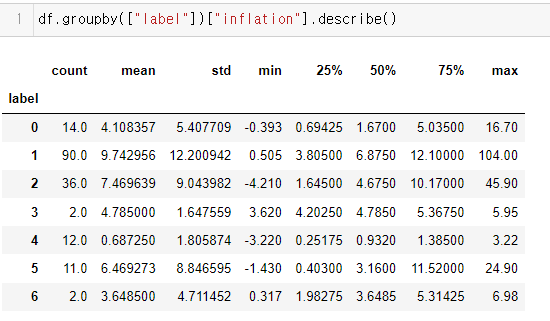
y = df['inflation']
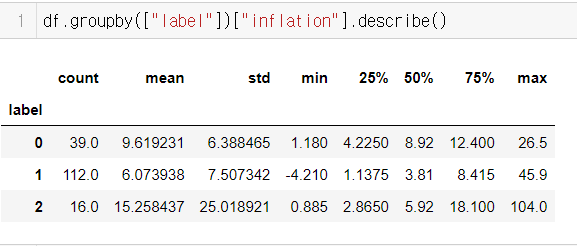
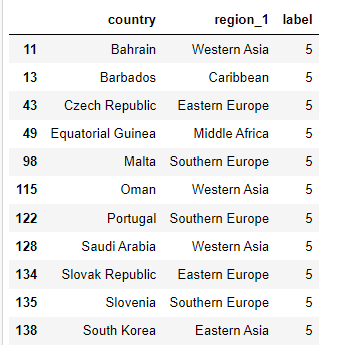
label 0의 39개국은 주로 동남아시아, 아프리카 저개발국가이며, label 2의 16개국은 사하라 이남 블랙아프리카 저개발국과 Haiti(Caribbean)국가가 포함되었음. 한국은 label 1에 포함되었음
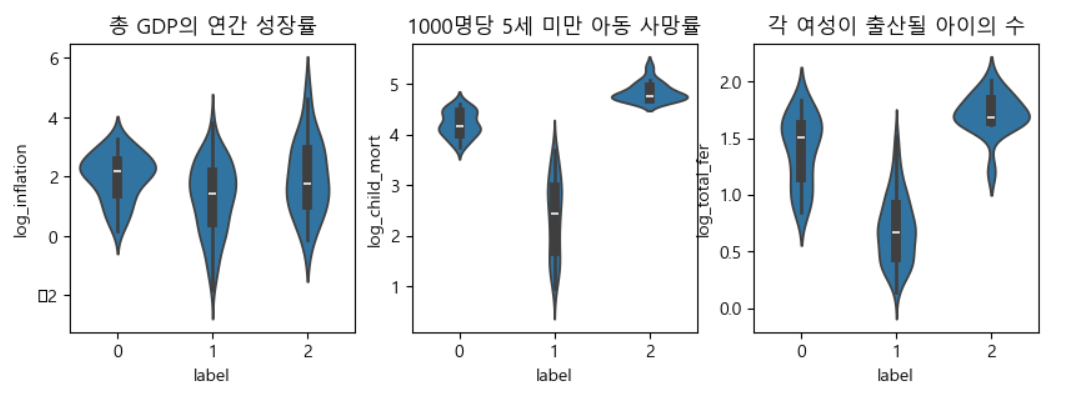
log연산후 시각화
4. Insight
-
1000명당 5세 이하 영아 사망률과 출산율의 Sub-Saharan Africa지역의 저개발국가들이 상당수 차지하고 있었다. 한국은 다수국 그룹에 포함되었으나, 각 여성이 출산될 아이의 수가 싱가폴(1.15)-한국(1.23)-헝가리(1.25)....콩고공화국(6.54)-말리(6.55)- 차드(6.59)-니제르(7.49)순으로서 한국은 전세계 하위 2번째로 매우 낮은 현상으로 인구감소 우려가 예상됨
-
또한 국가 GDP 관련에서는 특정 계층그룹 4개국은 Luxembourg, Norway, Qatar, Switzerland로서 income 5만 이상이면서 gdpp 7만이상의 국가들이었고, label 1의 26개국은 Australia, Austria, ..., Spain, Sweden, Arab Emirates, United Kingdom, United States 등의 국가들이 이 분류에 포함되어 있었다. 소위 부국이다. 우선 나라는 경제대국 운운하지만, 그런 그룹에 포함되지 않아서 아쉬웠다. 우선 나라가 잘 살고 봐야 되겠다.
