
AI 모델링
- 1. 데이터에 적합한 AI 알고리즘 선택요소
- 타겟변수
- 지도학습
- 분류를 위한 데이터
- 수치 예측(회귀)을 위한 데이터
- Linear Regression
- 지도학습
- 목적
- 설명
- 결과의 원인 분석
- 결과에 영향을 주는 변수(컬럼) 분석
- 예) 월별 커피 매출 원인, 변수 분석
- 예측
- 결과 자체가 중요한 경우
- 미래 상황에 대비하고, 정확히 알아야 하는 경우
- 예) 다음주에 팔린 커피 수량을 예측
- 커피가 팔리는 원인, 영향 변수가 목적이 아니라 팔리는 량이 목적이므로 예측
- 설명

- 타겟변수
-
2. 준비된 데이터로 모델 학습
- 손실함수를 최소화하는 과정
- 개념
- 목적함수
- 비용함수
- 손실함수
- 작을수록 좋음
- 가중치
- 목적함수
- 훈련데이터, 평가 데이터 분리
- 보통 Train 70%, Test 20%, Valid 10%로 분리
- 과소 적합
- 학습을 너무 적게 진행한 상태
- 학습 반복 횟수를 더 많이 늘려주면 해결 가능
- 과대 적합
- 학습용 훈련 데이터가 대표성을 띄지않는 경우
- 훈련 데이터로 지나치게 많은 학습을 한 경우
- 훈련 데이터에 너무 편향된 상태
- 해결방법
- Early Stop
- 과대 적합을 막기 위해 Epoch 횟수 전에 학습을 조기 종료하기 위한 파라미터
- Drop Out(Deep Learning 적용 가능)
- 과대적합을 줄이기 위해 임의로 노드를 제거해주는 확률 수준
- 하이퍼 파라미터
- 1. Epochs
- 훈련 데이터 전체를 몇번 반복해서 학습을 할지 정하는 파라미터
- 과소적합시 해당 수치를 늘림
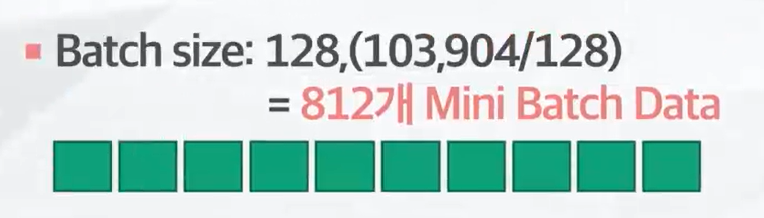
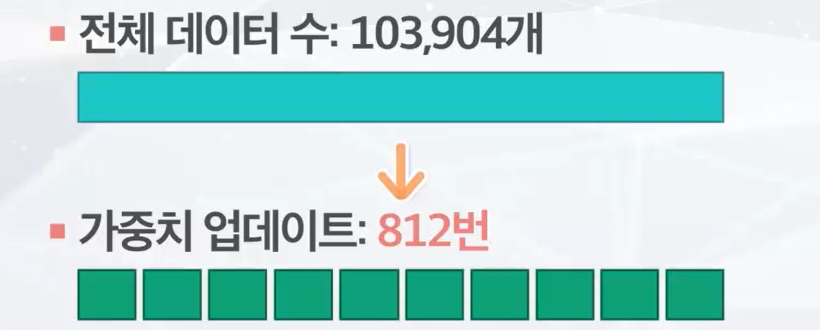
- 2. Batch Size
- 데이터를 학습을 위해 미니 배치로 나누는 파라미터
- 1Epoch에서 모델 가중치 업데이트 횟수?
- 이터레이션
- 데이터의 크기를 배치 사이즈로 나눈 횟수
- 미니배치 사이즈 만큼 모델의 가중치가 업데이트 된다.
- 이터레이션
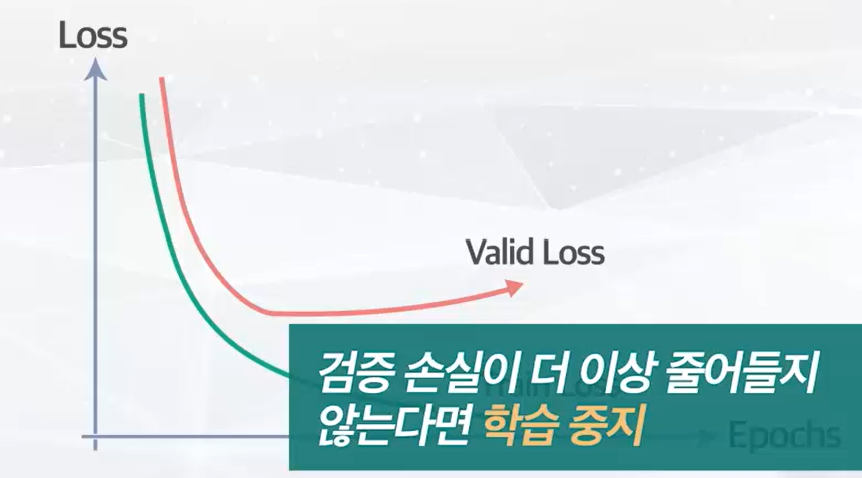
- 3. Early Stop
- 조건 충족시, 학습을 조기 종료
- 1. Epochs
-
3. 모델 평가 및 개선
-
평가 지표 선택
-
회귀 모델
-
오차를 직접적 표현
-
MAE(Mean Absolute Error)
-
MSE(Mean Squared Error)
-
RMSE(Root Mean Squared Error)
-
-
값이 1에 가까울수록 좋은 모델 성능
- R2 Score(R Squared)
- '회귀 모델이 얼마나 설명력이 있냐'의 지표
- 예측값&실제값의 강한 상관관계 여부로 요약
- R2 Score(R Squared)
-
-
분류 모델
- 정확도(Accuracy)
- 전체 데이터 중에 몇 개나 정확하게 예측을 했는가?

- 정확도가 너무 높으면 정밀도, 재현율을 통해 추가 성능 평가가 필요
- 정밀도(Precision)
- 양성이라고 예측한 개수 중에 실제로 양성인 개수의 비율
-
- 스팸 진단에는 정밀도가 중요
- 양성(진단)이라고 예측한거중에 실제로 양성이여야함, 최대한 높아야 음성(스팸아님)
이 잘못 예측이 안되기 때문
- 음성(스팸아님)이 양성(스팸)으로 분류되는게 문제 - 재현율(Recall)
- 실제로 양성인 개수 중에 양성이라고 잘 맟춘 개수의 비율

- 암진단 모델에서는 재현율이 중요
- 최대한 많은 양성(진단)을 잡아야하기 때문
- 양성(암)이 음성(암아님)으로 분류되는게 문제
- 양성(불량)이 음성(불량X)으로 분류되는게 문제
- F1-Score
- TRADE-OFF 관계에 있는 정밀도와 재현율을 조화평균하여 포괄적으로 보기 위한 지표

- 정확도(Accuracy)
-
-
평가 기준 세우기
- 비교대상과 베이스라인 모델을 비교
- 1. 유사 AI 과제의 모델 성능을 비교 대상으로 잡기
- 2. 기존 방식의 성능을 지표화해서 비교 대상으로 잡기
- 예) 수작업으로 진행한 경우 VS 자동화 도구로 진행한 경우
- 3. 설문조사 등으로 사용자의 만족 기준 설정
- 비교대상과 베이스라인 모델을 비교
-
더 나은 모델 만들기
- 더 많은 수의 학습 데이터 사용
- AI 알고리즘 변경
- 알고리즘을 바꾸며 성능 비교
- AI 알고리즘이 하이퍼 파라미터 변경
- 딥러닝
- 은닉층 개수 변경
- 노드 개수 변경
- 피처엔지니어링을 통한 파생 변수 생성
- 데이터 분석후 파생 변수 찾기
- 많은 시도가 있어야 성능 향상 가능
-
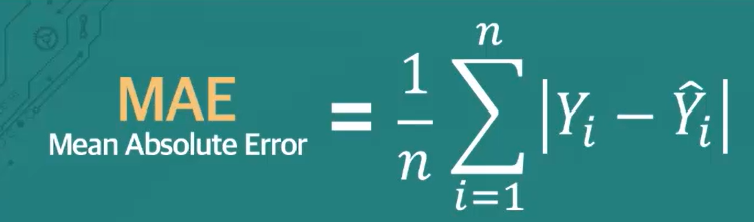
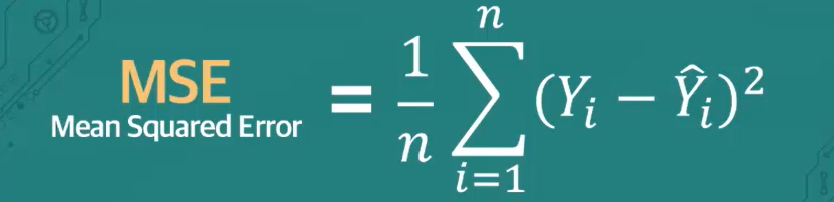

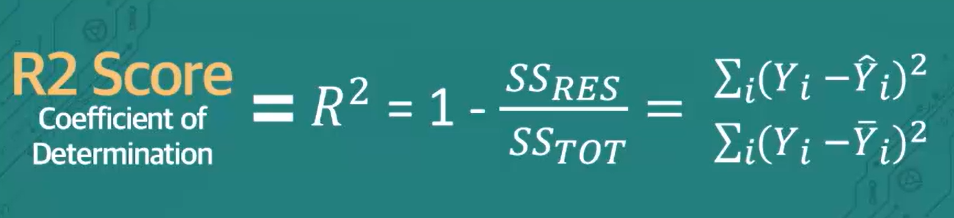

Back-end Developer를 목표로 하고 있는 전진구입니다.