
Set 인터페이스
- Set은 Java에서 제공하는 컬렉션 중 하나이다.
- 중복된 요소를 허용하지 않는다.
- 요소의 저장 순서를 유지하지 않는다.
- 내부적으로 해시 테이블(Hash Table)을 사용하여 요소를 저장한다.
Set은 HashSet, TreeSet, LinkedHashSet 등 존재
Set 인터페이스 메소드
Set 인터페이스는 Collection 인터페이스를 상속받으므로, Collection 인터페이스에서 정의한 메소드도 모두 사용할 수 있다.
boolean add(E e)
해당 집합(set)에 전달된 요소를 추가함. (선택적 기능)
void clear()
해당 집합의 모든 요소를 제거함. (선택적 기능)
boolean contains(Object o)
해당 집합이 전달된 객체를 포함하고 있는지를 확인함.
boolean equals(Object o)
해당 집합과 전달된 객체가 같은지를 확인함.
boolean isEmpty()
해당 집합이 비어있는지를 확인함.
Iterator<E> iterator()
해당 집합의 반복자(iterator)를 반환함.
boolean remove(Object o)
해당 집합에서 전달된 객체를 제거함. (선택적 기능)
int size()
해당 집합의 요소의 총 개수를 반환함.
Object[] toArray()
해당 집합의 모든 요소를 Object 타입의 배열로 반환함.
1. HashSet<E> 클래스
Set 컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이며, 해시 알고리즘(hash algorithm)을 사용하여 검색 속도가 매우 빠르다. 이러한 HashSet<E> 클래스는 내부적으로 HashMap 인스턴스를 이용하여 요소를 저장한다.
HashSet<E> 클래스는 Set 인터페이스를 구현하므로, 요소를 순서에 상관없이 저장하고 중복된 값은 저장하지 않는다. 만약 요소의 저장 순서를 유지해야 한다면 LinkedHashSet<E> 클래스를 사용하면 된다.
예제
import java.util.HashSet;
import java.util.Set;
import java.util.Iterator;
public class SetExample {
public static void main(String[] args) {
HashSet<String> hs01 = new HashSet<String>();
HashSet<String> hs02 = new HashSet<String>();
// hs01 요소 추가
hs01.add("홍길동");
hs01.add("이순신");
System.out.println(hs01.add("임꺽정")); // 출력: true
System.out.println(hs01.add("임꺽정")); // 출력: false -> 중복된 요소의 add()은 'false' 출력
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (String e : hs01) {
System.out.print(e + " "); // 출력: 홍길동 이순신 임꺽정
}
System.out.println();
// hs02 요소 추가
hs02.add("임꺽정");
hs02.add("홍길동");
hs02.add("이순신");
// iterator() 메소드를 이용한 요소의 출력
Iterator<String> iter02 = hs02.iterator();
while (iter02.hasNext()) {
System.out.print(iter02.next() + " "); // 출력: 홍길동 이순신 임꺽정
}
System.out.println();
// size() 메소드를 이용한 요소의 총 개수
System.out.println("집합의 크기 : " + hs02.size()); // 출력: 집합의 크기 : 3
}
}위의 예제에서 요소의 저장 순서를 바꿔도 저장되는 순서에는 영향을 미치지 않는 것을 확인할 수 있다. 또한, add() 메소드를 사용하여 해당 HashSet에 이미 존재하는 요소를 추가하려고 하면, 해당 요소를 저장하지 않고 false를 반환하는 것을 볼 수 있다.
이때 해당 HashSet에 이미 존재하는 요소인지를 파악하기 위해서는 내부적으로 다음과 같은 과정을 거치게 된다.
- 해당 요소에서
hashCode()메소드를 호출하여 반환된 해시값으로 검색할 범위를 결정한다. - 해당 범위 내의 요소들을
equals()메소드로 비교한다.
따라서 HashSet에서 add() 메소드를 사용하여 중복 없이 새로운 요소를 추가하기 위해서는 hashCode()와 equals() 메소드를 상황에 맞게 오버라이딩해야 한다.
다음 예제는 사용자가 정의한 Animal 클래스의 인스턴스를 HashSet에 저장하기 위해 hashCode()와 equals() 메소드를 오버라이딩한 예제이다.
class Animal {
String species;
String habitat;
Animal(String species, String habitat) {
this.species = species;
this.habitat = habitat;
}
public int hashCode() {
return (species + habitat).hashCode();
}
public boolean equals(Object obj) {
if(obj instanceof Animal) {
Animal temp = (Animal)obj;
return species.equals(temp.species) && habitat.equals(temp.habitat);
} else {
return false;
}
}
}
public class Set02 {
public static void main(String[] args) {
HashSet<Animal> hs = new HashSet<Animal>();
hs.add(new Animal("고양이", "육지"));
hs.add(new Animal("고양이", "육지"));
hs.add(new Animal("고양이", "육지"));
System.out.println(hs.size()); // 출력: 1
}
}add() 메소드를 통해 같은 값을 가지는 Animal 인스턴스를 여러 번 저장하지만, size() 메소드를 통해 살펴본 HashSet 요소의 총 개수는 1개만 저장되었음을 확인할 수 있다.
해시 알고리즘(hash algorithm)
해시 알고리즘(hash algorithm)이란 해시 함수(hash function)를 사용하여 데이터를 해시 테이블(hash table)에 저장하고, 다시 그것을 검색하는 알고리즘이다.
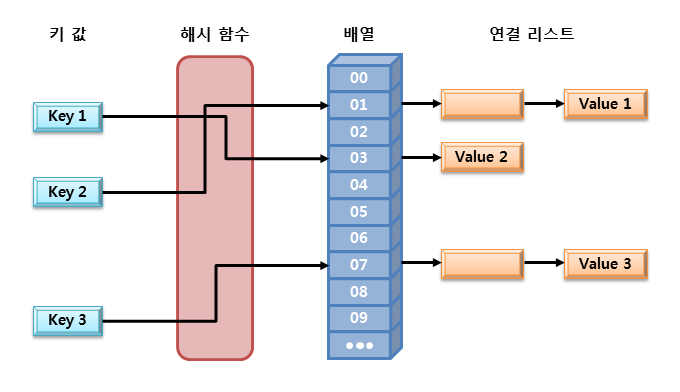
자바에서 해시 알고리즘을 이용한 자료 구조는 위의 그림과 같이 배열과 연결 리스트로 구현된다. 저장할 데이터의 key값을 해시 함수에 넣어 반환되는 value으로 배열의 인덱스를 구한다. 그리고 해당 인덱스에 저장된 연결 리스트에 데이터를 저장하게 된다.
예를 들어, 정수형 데이터를 길이가 10인 배열에 저장한다고 한다면 1,000,002를 검색하는 방법은 다음과 같을 수 있다. 1,000,002를 10으로 나눈 나머지가 2이므로 배열의 세 번째 요소에 연결된 연결 리스트에서 검색을 시작한다.
매우 간략화한 예제이지만 이렇게 해시 알고리즘을 이용하면 매우 빠르게 검색 작업을 수행할 수 있다.
2. TreeSet<E> 클래스
TreeSet<E> 클래스는 데이터가 정렬된 상태로 저장되는 이진 검색 트리(Binary Search Tree)의 형태로 요소를 저장한다.
이진 검색 트리는 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠르다.
TreeSet<E> 클래스는 NavigableSet 인터페이스를 기존의 이진 검색 트리의 성능을 향상시킨 레드-블랙 트리(Red-Black tree)로 구현한다.
TreeSet<E> 클래스는 Set 인터페이스를 구현하므로, 요소를 순서에 상관없이 저장하고 중복된 값은 저장하지 않는다.
예제
import java.util.Set;
import java.util.TreeSet;
import java.util.Iterator;
public class SetExample {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<Integer>();
// 요소 저장
ts.add(30);
ts.add(40);
ts.add(20);
ts.add(10);
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (int e : ts) {
System.out.print(e + " "); // 출력: 10 20 30 40
}
System.out.println();
// remove() 메소드를 이용한 요소의 제거
ts.remove(40);
// iterator() 메소드를 이용한 요소의 출력
Iterator<Integer> iter = ts.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " "); // 출력: 10 20 30
}
System.out.println();
// size() 메소드를 이용한 요소의 총 개수
System.out.println("이진 검색 트리의 크기 : " + ts.size()); // 출력: 이진 검색 트리의 크기 : 3
// subSet() 메소드를 이용한 부분 집합의 출력
/*①*/ System.out.println(ts.subSet(10, 20)); // 출력: [10]
/*②*/ System.out.println(ts.subSet(10, true, 20, true)); // 출력: [10, 20]
}
}위의 예제처럼 TreeSet 인스턴스에 저장되는 요소들은 모두 정렬된 상태로 저장된다. 또한, 위의 예제에서 사용된 subSet() 메소드는 TreeSet 인스턴스에 저장되는 요소가 모두 정렬된 상태이기에 동작이 가능한 해당 트리의 부분 집합만을 보여주는 메소드이다.
①번 라인에서 사용된 subSet() 메소드는 첫 번째 매개변수로 전달된 값에 해당하는 요소부터 시작하여 두 번째 매개변수로 전달된 값에 해당하는 요소의 바로 직전 요소까지를 반환한다.
②번 라인에서 사용된 subSet() 메소드는 두 번째와 네 번째 매개변수로 각각 첫 번째와 세 번째 매개변수로 전달된 값에 해당하는 요소를 포함할 것인지 아닌지를 명시할 수 있다.
참고 자료
http://www.tcpschool.com/java/java_collectionFramework_set
