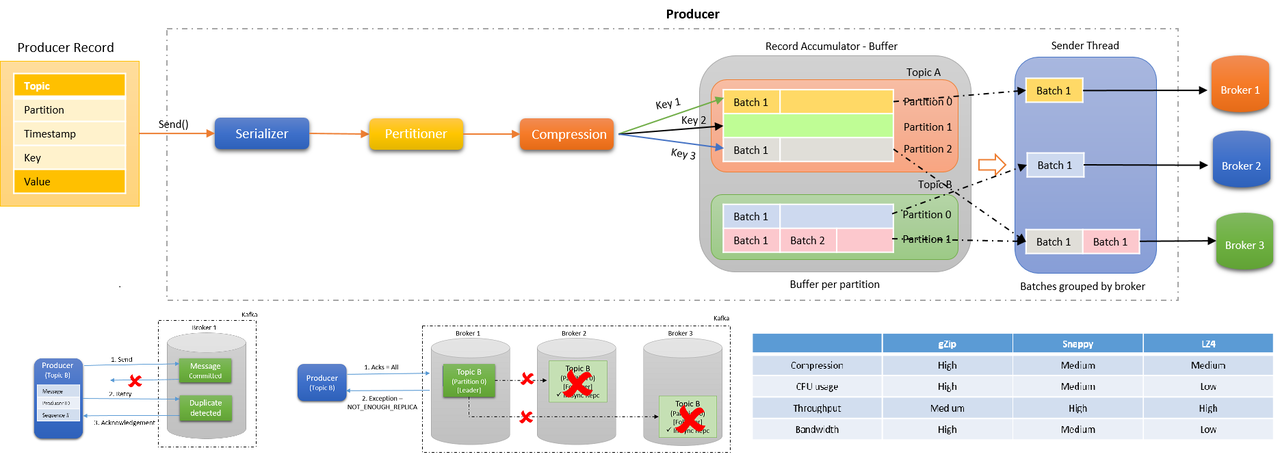
Kafka 설명들음
Rebalancing
Coordinator : 컨슈머 관리, 컨슈머 리더 선출등
Partition 갯수랑 consumer 갯수 맞춰야 유휴자원이 없음 (
컨슈머가 polling 대기 상태, Commit , 과 producer 가 prodcue 해도 제대로 commit 안되면 어딘가에서 message가 남아있다가 commit 되는 순간 중복 메시지로 들어옴
이유는 kafka broker와 proudce flow 사이에 step 때문임.
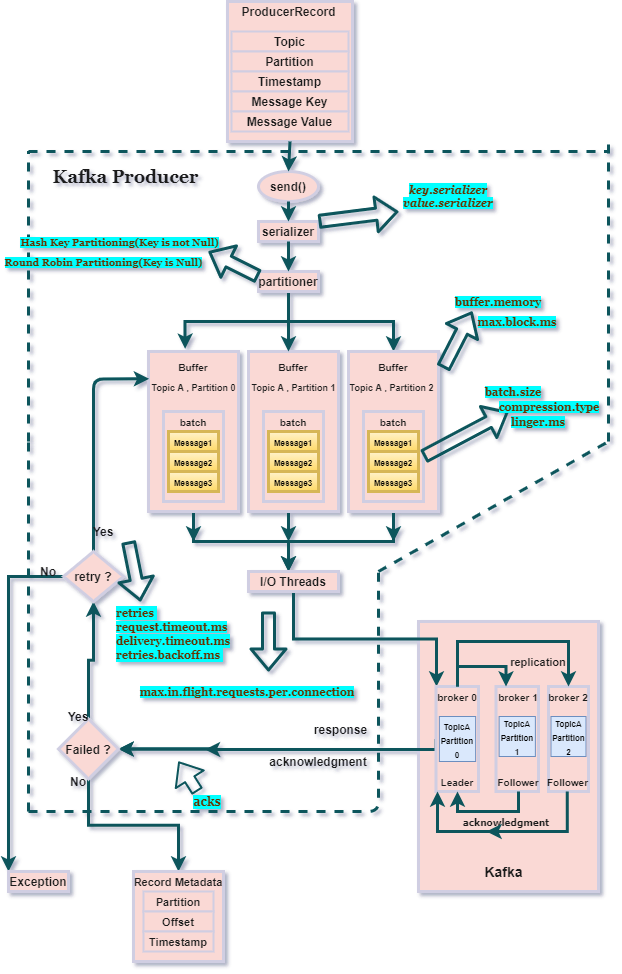
-
deserialize, serialize
json, dictionary 형태로 데이터를 받아도 producer는 이를 broker 에 저장할때 binary 형태로 저장함 -
메시지를 쪼개서 저장함
위 글이 이해가 안갔음.
처음엔 메시지 내용을 어느 기준으로 쪼개는개념인가 함
메시지의 저장 위치를 (정확하게는 consumer의 최근 read 한 offset 위치만) index 처럼 저장하는 개념임
= 사물함이 있으면 해당 사물함에 물건의 위치! -
PageCache
빠르게 읽고 처리하는건 cache 를 통해서
KAFKA도 stream이 있음(java를 활용해 사용가능)
즉 data stream 대용량 데이터 처리에 맞는 queue의 개념인 만큼 해당 내용을 저장보다 전달에 초점이 있다
message를 순서대로 처리하기 위해 offset을 쓰는거고
비교
Redis 사용이유
1) 유사 구조 : 같은 큐, in-memory, 대용량 stream에 적합( cluster 형태도 제공)
2) 캐시 사용: page cache 대신 redis 자체의 cache를 이용해 merge를 진행한다 (kafka topic은 pub/sub에만 집중)
3) 저장 기능: dlq 를 처리할 수 있는 메모리에 데이터를 저장하는 오픈 소스의 비관계형 데이터베이스 관리 시스템
주의사항
-
redis는 싱글톤 패턴이라 import를 이상하게 하면. 순환참조 에러가 당연히 난다
.
scan메서드란 무엇인가?5.1.
Redis SCAN명령 -
목적: Redis 데이터베이스에서 키를 반복적으로 탐색하는 데 사용됩니다.
-
장점:
KEYS명령과 달리 Redis 서버의 성능에 큰 영향을 주지 않으며, 대규모 키셋에서도 안전하게 사용할 수 있습니다. -
반환값:
(cursor, keys)형태의 튜플을 반환합니다.cursor: 다음 스캔을 시작할 위치.keys: 현재 스캔된 키 목록.
활용 방향
- 성공/실패 로그 저장
- 의미 없음: 모든 로그를 저장하는 것은 성능과 저장 비용 측면에서 비효율적일 수 있습니다. 성공적인 로그도 필요하지만, 주요 에러와 경고 위주로 저장하는 것이 효율적입니다. 예를 들어, ID를 저장할 필요가 없다면, 성공 로그에서 필수적인 정보만 기록하는 것이 좋습니다.
- Redis와 DLQ 활용
- DLQ 관리: Redis는 메시지 큐로 사용할 수 있으며, 카프카와 비슷한 방식으로 Dead Letter Queue(DLQ)로 활용 가능합니다. 이 경우 Critical, Warning 레벨의 메시지만 기록하고, 알림 설정을 통해 중요한 로그만 처리하는 방식이 좋습니다.
- 카프카 이벤트 블로킹 문제
- 원인: 카프카 이벤트가 블로킹된 원인은 비동기 처리 부족일 수 있습니다. 카프카는 기본적으로 비동기 메시징 시스템이므로, 이벤트 블로킹을 피하려면 비동기 처리를 철저히 해야 합니다.
- 해결책: 비동기 처리, 특히 코루틴을 사용하여 동시성을 개선해야 합니다.
- 비동기 처리
- 비동기 처리 필수: 비동기 처리가 필요한 경우, async/await을 사용하여 이벤트 블로킹을 방지해야 합니다. 비동기 처리를 하지 않으면, 동기 방식처럼 차례대로 처리되기 때문에, 이벤트 블로킹이 발생할 수 있습니다.
- 로그 처리
- 로그 저장: 성공 로그(info)는 저장할 필요가 없는 경우가 많습니다. 그러나 에러/경고 로그는 반드시 저장하고 모니터링을 위해 Prometheus, Grafana와 같은 툴을 사용할 수 있습니다.
- 로그 전달 방식: 보통 웹훅이나 메시징 시스템(예: 카프카)을 통해 로그를 전달하며, 관리자는 대시보드나 알림 시스템을 통해 실시간으로 확인합니다.
- 파이썬의 NoneType과 객체
- NoneType 사용: 파이썬에서
None은 값이 없음을 나타내는 특별한 객체입니다. 이를 명시적으로 사용할 때, 값이 없다는 의도를 전달하려고 할 때 사용합니다. - 객체 처리:
None은 객체로 취급되지만, 이를 코루틴 처리에서 문제가 될 수 있는 예외로 간주해야 할 경우도 있습니다. - 타입 선언:
None을 타입으로 선언하는 것은 드물며, 파이썬은 동적 타이핑을 사용하므로 명시적인 타입 선언이 없을 때 이를 처리하는 방식이 다를 수 있습니다.
- 파이썬에서 모든 것이 객체화
- 파이썬은 모든 것이 객체로 취급되는 객체 지향 언어입니다. 예를 들어, 함수나 클래스 자체도 객체입니다.
- 파이썬에서는 객체를 선언하고 초기화하는 방식이 명시적이지 않더라도 자동으로 관리하는 경우가 많습니다.
- 클래스 상속은 파이썬에서 사용 가능하며,
import를 통한 모듈화와 상속은 동시에 존재할 수 있습니다.
- 상속과 오버라이딩
- 파이썬의 상속: 파이썬에서도 상속은 자주 사용됩니다.
super()를 통해 부모 클래스의 메서드를 호출하거나, 오버라이드하여 자식 클래스에서 기능을 재정의할 수 있습니다. - 순환 참조 문제: 모듈화된 구조에서 순환 참조를 방지하려면, 명확한 의존성 관리가 필요합니다.
- 에러 타입 선언
- 파이썬은 에러 타입을 별도로 선언할 수 있으며, 커스텀 예외를 정의할 수 있습니다. 예를 들어,
ValidationError와 같은 오류를 선언하여 try-except 블록 내에서 처리할 수 있습니다. - 순환 참조 오류는 일반적으로 재귀적 호출이나 모듈 의존성 문제에서 발생합니다.
- 코루틴과 비동기 처리
- 코루틴:
async와await는 비동기 프로그래밍을 다루기 위한 도구이며, 모든 코루틴이 병렬 처리를 보장하는 것은 아닙니다. 비동기를 사용할 때도 완전한 병렬 처리는 아니므로, CPU 바운드 작업은 다른 방식으로 처리해야 할 수 있습니다. - sleep() 사용 지양:
sleep()은 비동기 함수에서 시간 지연을 유발하며, 병렬 처리의 의미를 상실하게 할 수 있습니다.
- 로그 레벨과 처리
- 로그 레벨:
INFO는 일반적으로 성공적인 작업을 기록하지만, 중요하지 않은 정보는 기록하지 않는 것이 효율적입니다.ERROR,WARNING같은 중요한 로그는 반드시 기록해야 합니다. - Kafka 로그: 카프카 health check 로그와 토픽 생성 로그는 각각 별도의 로그로 다룰 수 있지만, 모두 모니터링 목적으로 전달하는 것이 좋습니다.
- 삽질과 간단한 구현
- 간단한 구현 찾기: 처음에는 간단한 방식으로 구현을 시작하고, 나중에 최적화하는 것이 좋습니다. 삽질은 필요한 학습의 일환일 수 있습니다.
- AI 관제 로그: AI 관제 시스템에서는 구체적인 로그 형식 (예: JSON 형식, 텍스트 로그 등)을 사용하고, 로그 수준을 정의하여 처리합니다.
결론:
- 비동기 처리, 코루틴 사용 시 이벤트 블로킹을 피하려면 반드시 비동기 코드 작성을 신경 써야 합니다.
- 로그 처리는 필수적인 에러와 경고 로그를 중심으로, 성공적인 로그는 필요하지 않을 수 있습니다.
- 파이썬에서는 모든 것이 객체화되어 있으며, 상속과 오버라이드는 일반적으로 사용됩니다.
- 비동기 처리에서는 sleep() 사용 지양하고, 코루틴을 잘 활용해야 합니다.
