이번 방학부터는 졸업작품을 한이음에 출품하게 되면서 스파르타에서 무료로 강의를 들을 수 있는 기회가 생겨 머신러닝 기초 강의를 들을 수 있게 되었다. 이전에는 머신러닝은 소프트웨어의 영역이라고 생각했으나 이제는 하드웨어 개발자도 기초적인 부분은 알 필요성이 있다고 느꼈다. 그래서 앞으로 한달동안 머신러닝 공부를 하고 강의에서 들은 내용을 정리하고 기록할 예정이다.
📚1. 머신러닝이란?
기계 학습 또는 머신 러닝(machine learning)은 경험을 통해 자동으로 개선하는 컴퓨터 알고리 즘의 연구이다. 인공지능의 한 분야로 간주되고 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다.
머신러닝으로 해결할 수 있는 문제는 예를들어 "오늘의 온도와 습도 데이터를 활용하여, 내일 미세먼지 농도를 예측할 수 있을까?", "이 사진에 찍힌 사람 수는 몇 명 일까?" 등이 있다.
📗1. 회귀와 분류
머신러닝에서 문제를 풀 때, 해답을 내는 방법을 크게 회귀 또는 분류로 나눌 수 있다.
🔍1. 회귀
💡 사람의 얼굴 사진을 보고 몇 살인지 예측하는 문제
위와 같은 문제를 푼다고 가정해보자. 모든 문제를 풀기 위해서는 먼저 입력값(Input)과 출력값(Output)을 정의해야 하고 이 문제에서 입력값은 [얼굴사진]이 되고 출력값은 [예측한 나이]가 된다.

나이의 값은 연속적이다. 이런식으로 출력값이 연속적인 소수점으로 예측하게 하도록 푸는 방법을 회귀라고 한다.
🔍2. 분류
💡 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 이수 여부(Pass or fail)를 예측하는 문제
이 문제에서 입력값은 [공부한 시간] 그리고 출력값은 [이수 여부]가 된다. 우리는 이수 여부를 0,1이라는 이진 클래스(Binary class)로 나눌 수 있고 이런 경우를 이진 분류(Binary Classification)이라고 부른다.

다른 예로 아래와 같은 문제는 클래스를 5개로 나누는 다중 분류(Multi-class classification, Multi-label classification)를 사용한다.
💡 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 성적(A,B,C,D,F)를 예측하는 문제
📌 몇몇 문제는 회귀/분류 두 가지 방법으로 접근하여 해결할 수 있다. 예를 들어 얼굴 사진을 보고 나이를 예측하는 문제를 나이를 범위에 따른 클래스로 나누어서 생각하면 다중 분류 문제로 바꿔 풀 수 있게 된다.
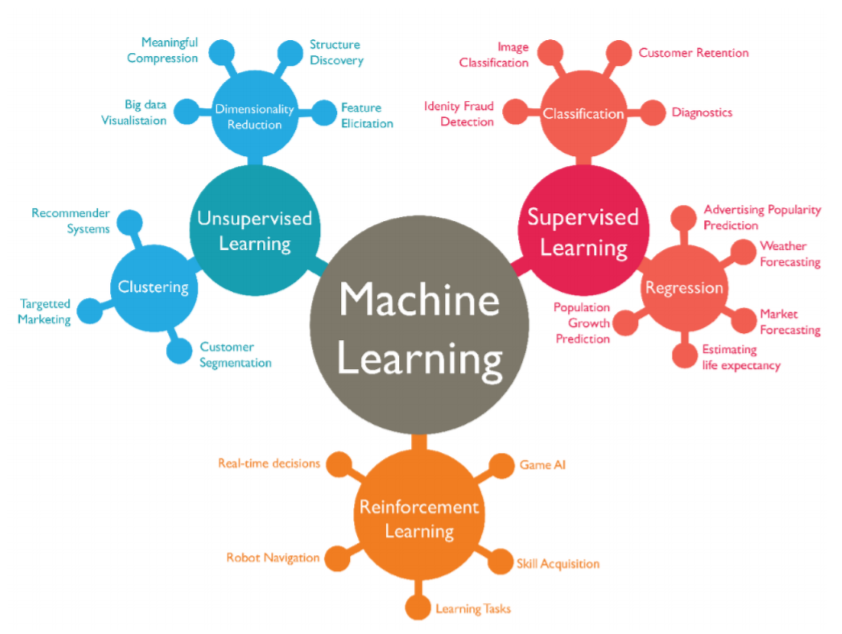
📕2. 머신러닝의 분류
머신러닝은 크게 지도 학습, 비지도 학습, 강화 학습 3가지로 분류한다.
🔍1. 지도 학습(Supervised learning)
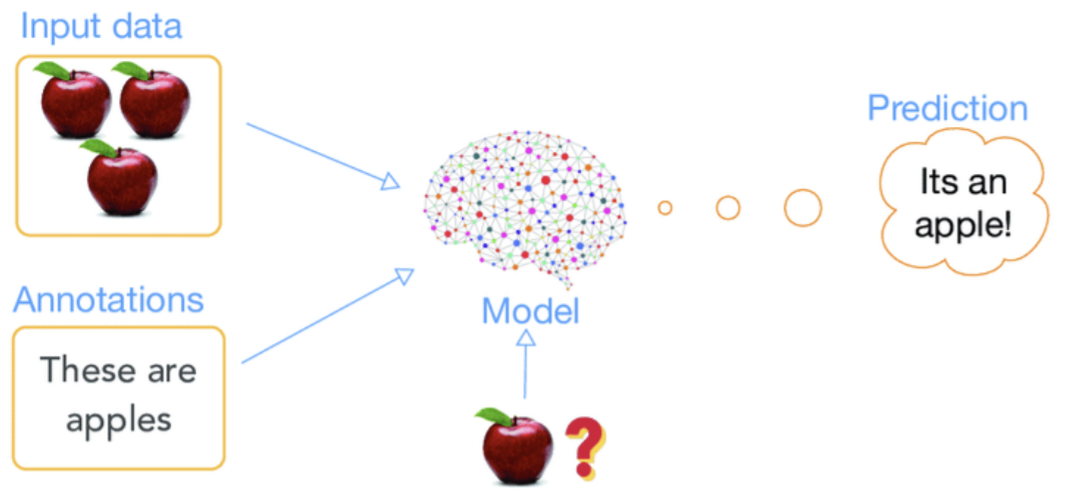
정답을 알려주면서 학습시키는 방법으로 위에서 배웠던 회귀와 분류 문제가 대표적인 지도 학습에 속한다. 지도 학습은 기계에게 입력값과 출력값을 전부 보여주면서 학습시킨다. 우리는 이미 정답을 알고 있기 때문에 정답을 잘 맞추었는지 아닌지를 쉽게 파악할 수 있으나 정답(출력값)이 없으면 이 방법으로 학습시킬 수 없다.
📌 회사에서 머신러닝 엔지니어로 근무한다면 문제를 풀기 위해 많은 데이터를 필요로 하나 대부분의 회사에는 데이터가 없는 경우가 많다. 혹은 입력값에 해당하는 데이터는 있어도 출력값에 해당하는 데이터가 없는 경우가 비일비재하다. 따라서 입력값에 정답을 하나씩 입력해주는 작업을 하게 되는 경우가 있는 그 과정을 라벨링(Labeling, 레이블링) 또는 어노테이션(Annotation)이라고 한다.
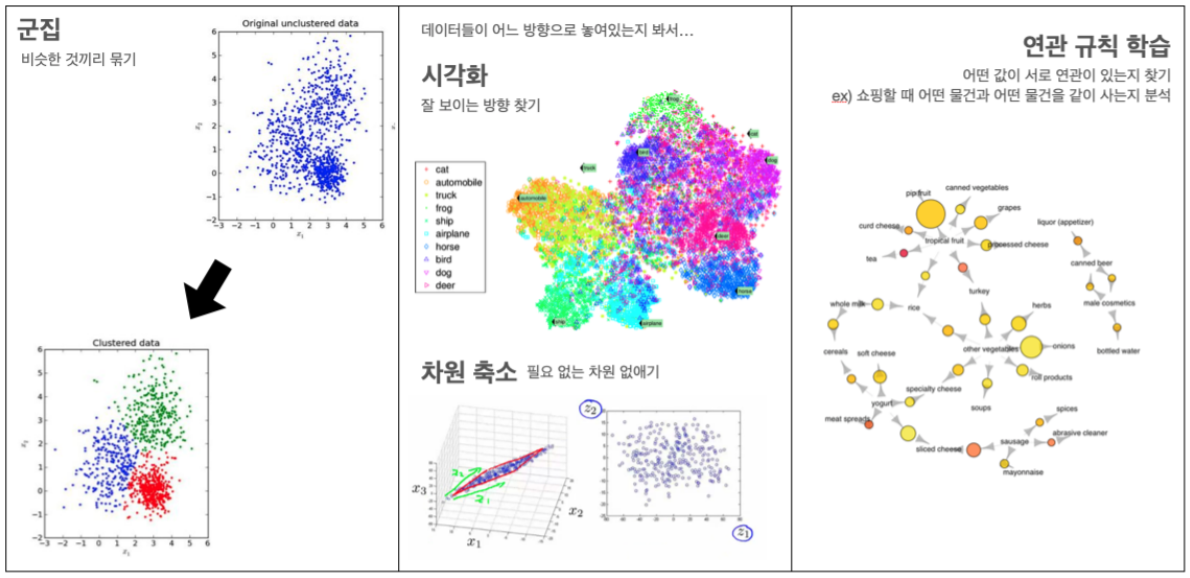
🔍2. 비지도 학습(Unsupervised learning)
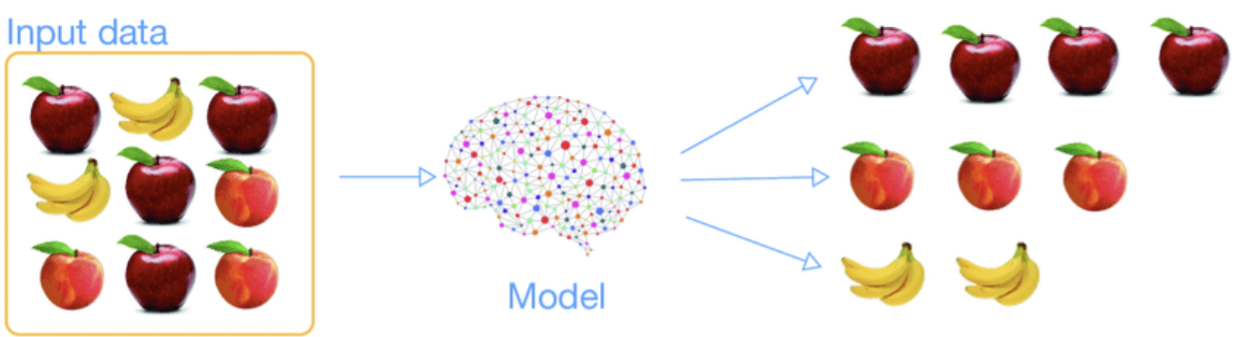
정답을 알려주지 않고 군집화(Clustering)하는 방법으로 그룹핑 알고리즘(Grouping algoritm)의 성격을 띄고 있다. 우리가 가지고 있는 데이터에 출력값에 해당하는 데이터가 없을 때 비지도 학습 방법을 사용한다. 학습시간이 오래 걸리고 어렵다는 단점이 있다.
💡 수 백만개의 음원 파일이 있는데, 각 음원 파일에 대한 장르 데이터는 없을 때 비지도 학습 방법을 사용하면 기계가 알아서 비슷한 것끼리 분류한다.
🔍3. 강화 학습(Reinforcement learning)
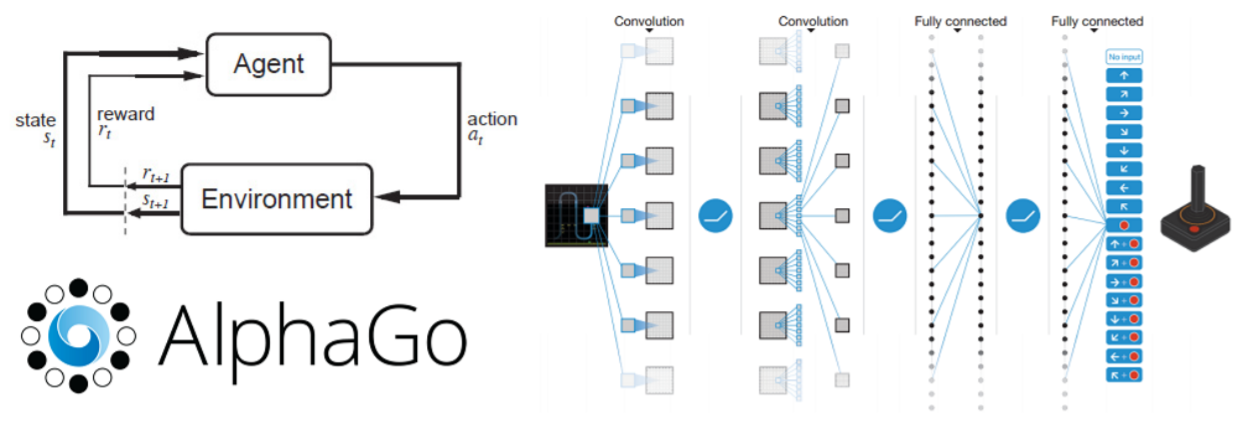
주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법으로 알파고를 탄생시킨 방법이다. 자신이 한 행동에 대한 보상(Reward)를 받으며 학습하는 것을 말한다.
게임을 예로 들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(Environment)에서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(Reward)를 획득할 수 있는 전략이 형성되게 된다. 단, 행동(Action)을 위한 행동 목록(방향키, 버튼) 등은 사전에 정의가 되어야 한다.
만약 이것을 지도 학습의 분류를 통해 학습을 한다고 가정하면 모든 상황에 대해 어떠한 행동을 해야 하는지 모든 상황을 예측하고 답을 설정해야 하기 때문에 엄청난 데이터가 필요하다. 예를 들어 바둑을 학습한다고 했을 때, 지도 학습의 분류를 이용해 학습하는 경우 아래와 같은 개수의 데이터가 필요해지게 된다.
💡 바둑의 경우의 수 : 20816819938197998469947863334486277 0286522453884530548425639456820927419612738015
강화 학습은 이전부터 존재했던 학습법이지만 이전에 알고리즘은 실생활에 적용할 수 있을 만큼 좋은 결과를 내지 못했다. 하지만 딥러닝의 등장 이후 강화 학습에 신경망을 적용하면서부터 바둑이나 자율주행차와 같은 복잡한 문제에 적용할 수 있게 되었다.
