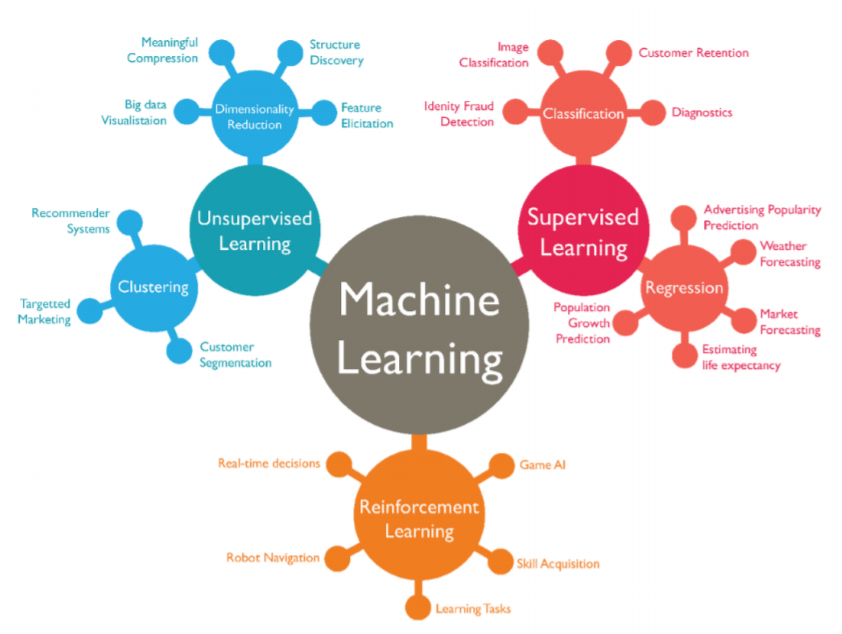
3. 📚다양한 머신러닝 모델
1. 📕Support vector machine(SVM)
강아지와 고양이를 구분하는 문제를 푼다고 가정해보자. 구분하는 문제를 푸는 것은 분류 문제(Classification problem)이고 분류 문제를 푸는 모델을 분류기(Classifier)라고 부른다.

강아지와 고양이를 나누는 모델을 만들기 위해 한 개의 직선을 긋는다.

그런데 어떻게 그려야 잘 구분할 수 있을까?💭
❗ 각 고양이, 강아지 간의 거리가 최대가 되는 직선을 그리면 구분이 잘되겠다!
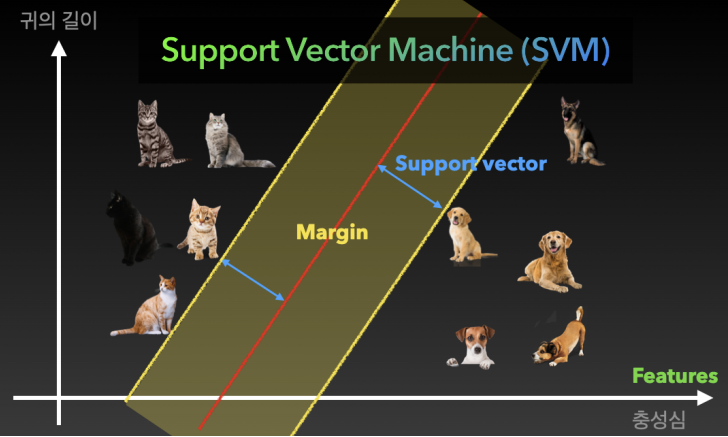
각 그래프의 축을 Feature(특징)라고 부르고 각 고양이, 강아지와 우리가 그린 빨간 벡터를 Support vector라고 부른다. 그리고 그 벡터의 거리를 Margin이라고 부른다. 우리는 Margin이 넓어지도록 이 모델을 학습시켜 훌륭한 Support vector machine을 만들 수 있다.
📌 만약 충성심이 강한 개냥이가 등장한다면?
그럴 경우에는 Feature(특성)의 개수를 늘려서 학습시키는 것이 일반적이다. 현재는 "귀의 길이", "충성심"의 2개의 특성만 있지만, "목소리의 굵기"라는 특성을 추가시켜 3차원 그래프를 그려 구분할 수 있다. 이것이 바로 분류 문제의 기초 개념이고 딥러닝을 더 낮은 차원에서 이해할 수 있는 방법이다.
2. 📗기타 머신러닝 모델 간단 소개
1. 🔎k-Nearest neighbors (KNN)
KNN은 비슷한 특성을 가진 개체끼리 군집화하는 알고리즘이다. 예를 들어 하얀 고양이가 새로 나타났을 때 일정 거리안에 다른 개체들의 개수(k)를 보고 자신의 위치를 결정하게 하는 알고리즘이다.

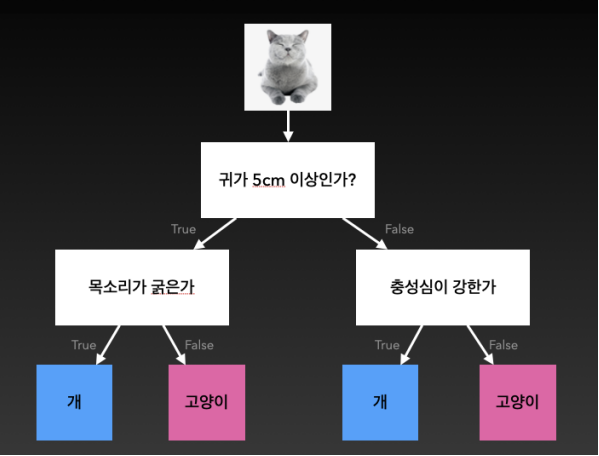
2. 🔎Decision tree(의사결정나무)
예, 아니오를 반복하며 추론하는 방식이다.
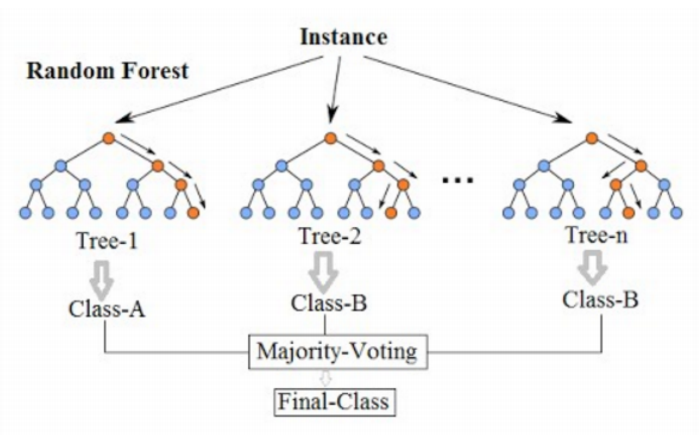
위 그림은 의사결정나무를 여러개 합친 모델이다. 의사결정나무는 한 사람이 결정하는 것이라고 하면 랜덤 포레스트는 각각의 의사결정나무들이 결정을 하고 마지막에 투표(Majority voting)을 통해 최종 답을 결정한다.
