SNU 강화학습의 기초(6) Approximation Method
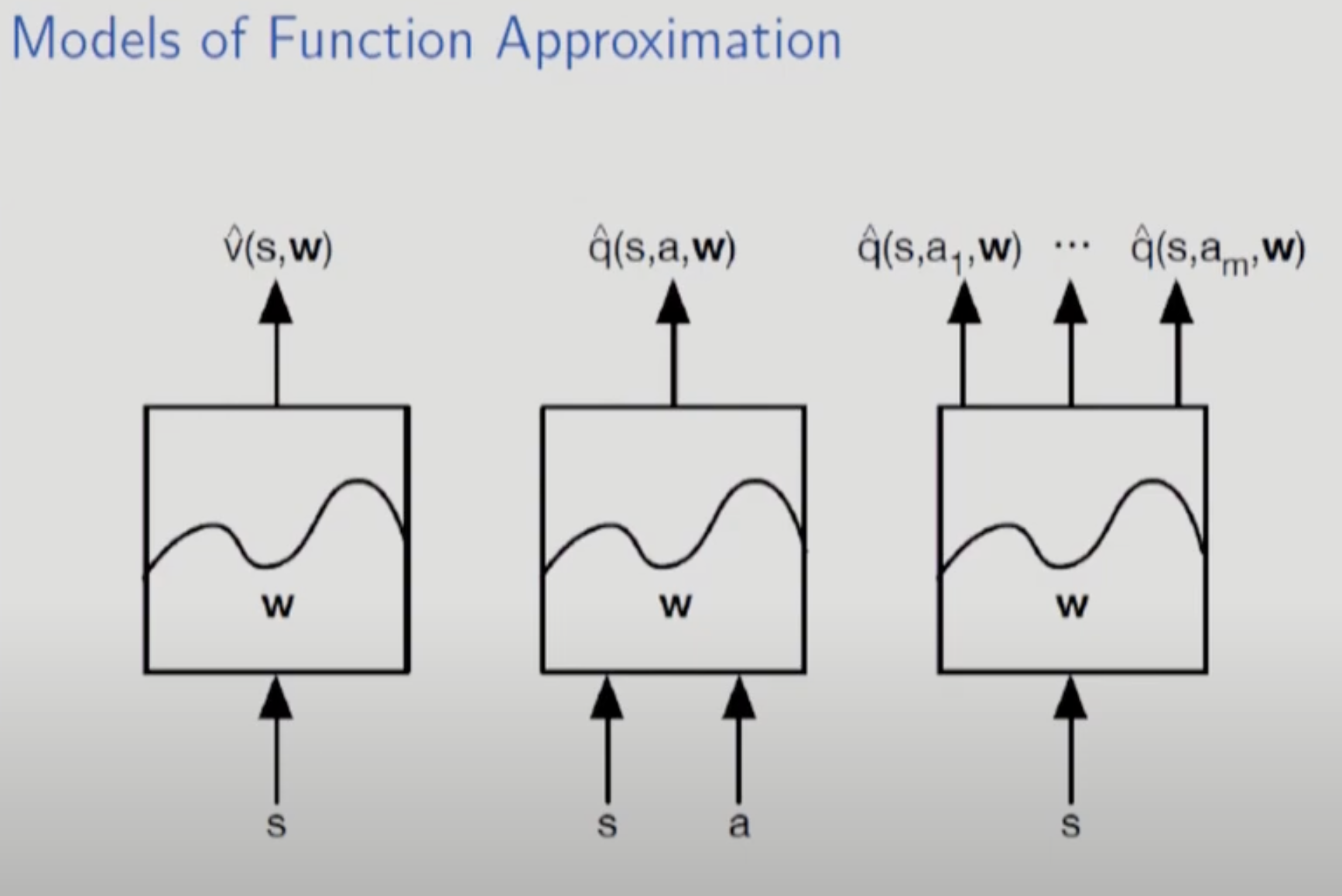
실제 프로그래밍 할 때 state Value function과 action value function을 어떻게 쓰는지이다. avf같은 경우 3번처럼 쓴다 실제로는. input이 s 하나이고 a는 그 다음에 선택하는 것 처럼.

approximation을 할 때 가정이 하나 붙는다. w가 실제 state의 수보다 적어야 한다는 것이다. approximation이니까 어찌보면 당연한 말이다.
mc, q-learning, sarsa에서는 state별로 제각각 update가 이루어졌다. state간 독립적으로 움직였다는 뜻이다. 하지만 approximation에서는 w를 update하므로 이런 호사를 누릴 수 없다.
approximation에 regression deep learning을 사용하므로 loss functiond은 mean squared가 사용된다.

자주방문하는 state에서 loss를 더 줄여주기 위해 weighted factor가 존재한다.
gradient descent를 사용하여 error를 줄인다.

state의 feature들을 Column vector로 표현할 수 있다.

끊임없이 공부하는 개발자