혁펜하임의 강화학습
Greedy Action
=> Greedy하게 한 Path만 추구
Exploration
앱실론 Greedy
앱실론 : 0~1 사이의 값
앱실론 만큼 Random하게 탐험.
Exploration & Exploitation(Greedy) => Trade off 관계
장점
- 새로운 Path
- 새로운 목적지
Decaying 앱실론
=> 앱실론을 0.9로 시작해서 점점 줄여나감.
탐험을 점점 줄여나감.
Discount Factor
=> 0~1사이의 값으로 Reward에 곱해지는 값.
감마가 클 수록 미래의 값을 더 생각하는 것
Q-update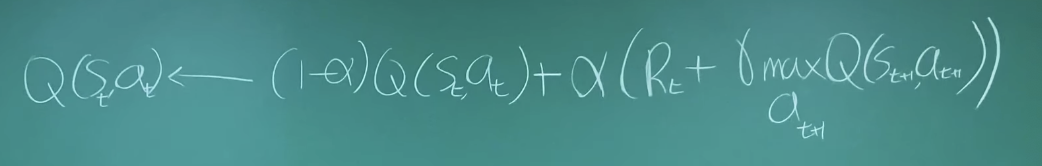
알파: 새로운 값을 얼마나 받아들일 것인가?
Markov Decision Process
Policy: P(At|St)
Transition Probability: P(St|St-1,At-1)
Goal: Maximize Expected Return
Return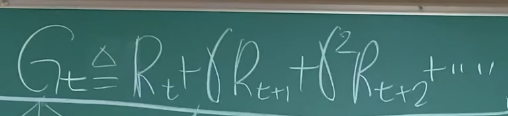
=> Return을 Maximize하는 Policy를 찾는 것이 강화학습의 목표이다.
Optimal Policy
=> State Value Function을 Maximize하는 Policy
State Value Function
=> 지금(S)부터 기대되는 Return
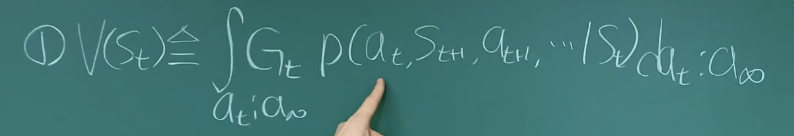
이렇게 되는 이유: 위에서 Return 값이 다음과 같다고 했다.
기댓값 E[f(x)] = f(x)p(x)의 적분으로 정의된다.
Action Value Function
=> 지금(S) 행동(A)으로부터 기대되는 Return
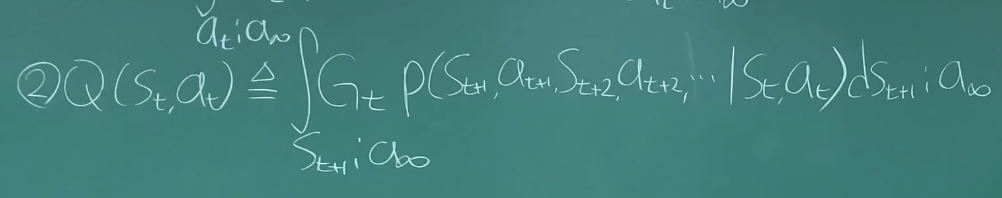
Bellman equation(잘 모르겠다)
위의 State Value Function과 Action Value Function로부터 나온 식.
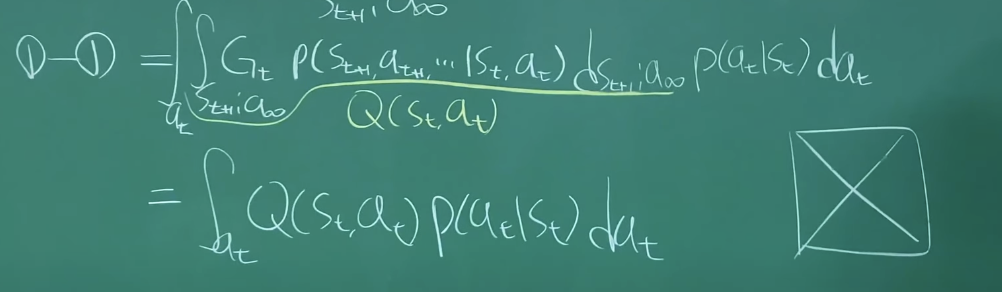 현재 State에서 각 Action의 Reward의 평균이 Action Value이다.
현재 State에서 각 Action의 Reward의 평균이 Action Value이다.
Optimal Policy 최댓값
=> Q가 정해져 있을 때 최댓값은 Q를 Maximize하는 Action을 고르는 것이다. Action = policy P
그렇다면 어떻게 Q*를 얻는가?
Monte-carlo
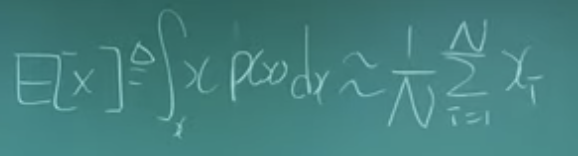
x를 여러개 뽑아서(끝까지 다 진행) N으로 나누면 평균
Monte Carlo를 통해서 모든 경우의 수를 다 찾으며(도착점까지) 탐험하다가 탐험 비율을 점점 줄여가며 Greedy하게 움직인다. 그렇게 Q*를 찾는다.
Temporal Difference
1 step만 진행해서 N으로 나누어 평균
MC VS TD
- MC: unBiased(편향없음), Variance가 크다 => 엄청 많이하는게 아니면 수렴이 힘들다.
- TD: biased, Variance가 작다.(다음값만 보므로) => 금방 수렴
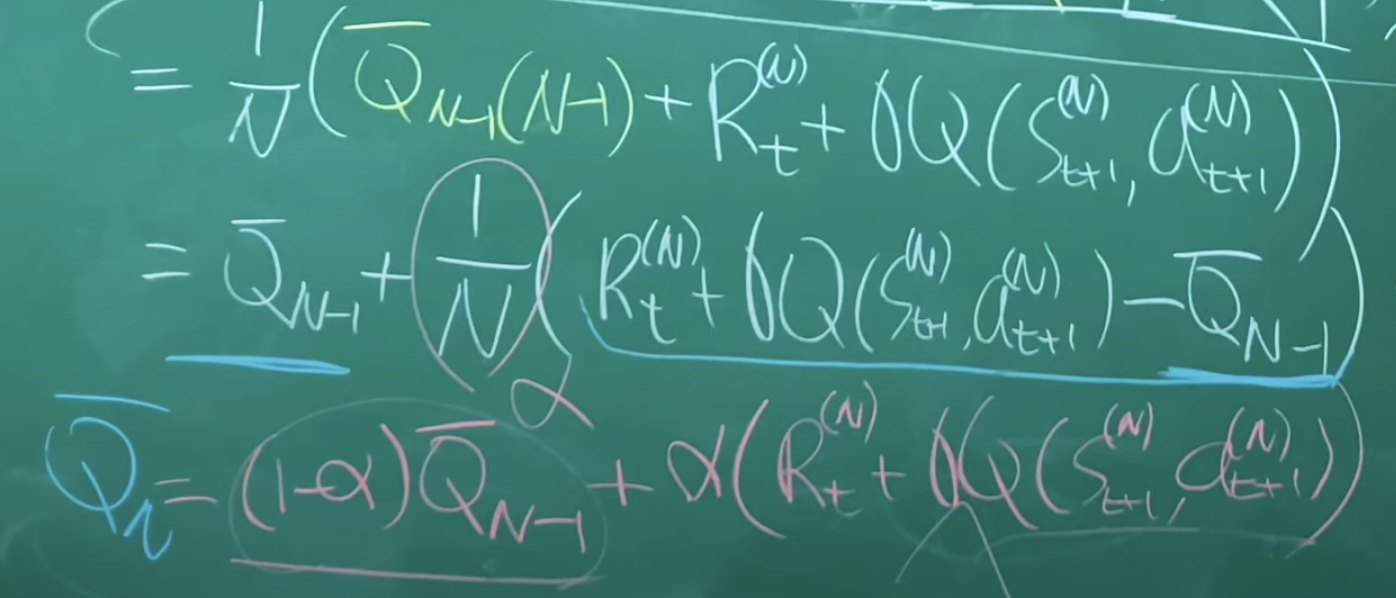
Action Value Function에 벨만 방정식 적용하여 다음 Action Value 로 표현한 식에 MC적용해서 정리하면 Incremental MC 나옴. (9개까지의 평균에 10번째 샘플 적용) 이거에서 1/N을 알파로 치환하면 마지막 빨간식(SARSA)이 나옴. 알파가 크면 최근 샘플을 많이 반영하는 것.
=> Q-learning이랑 다른 것은 Q-learning은 새로운 샘플을 가져올 때 At+1을 최적화 해서 가져옴
Off-Policy VS On-policy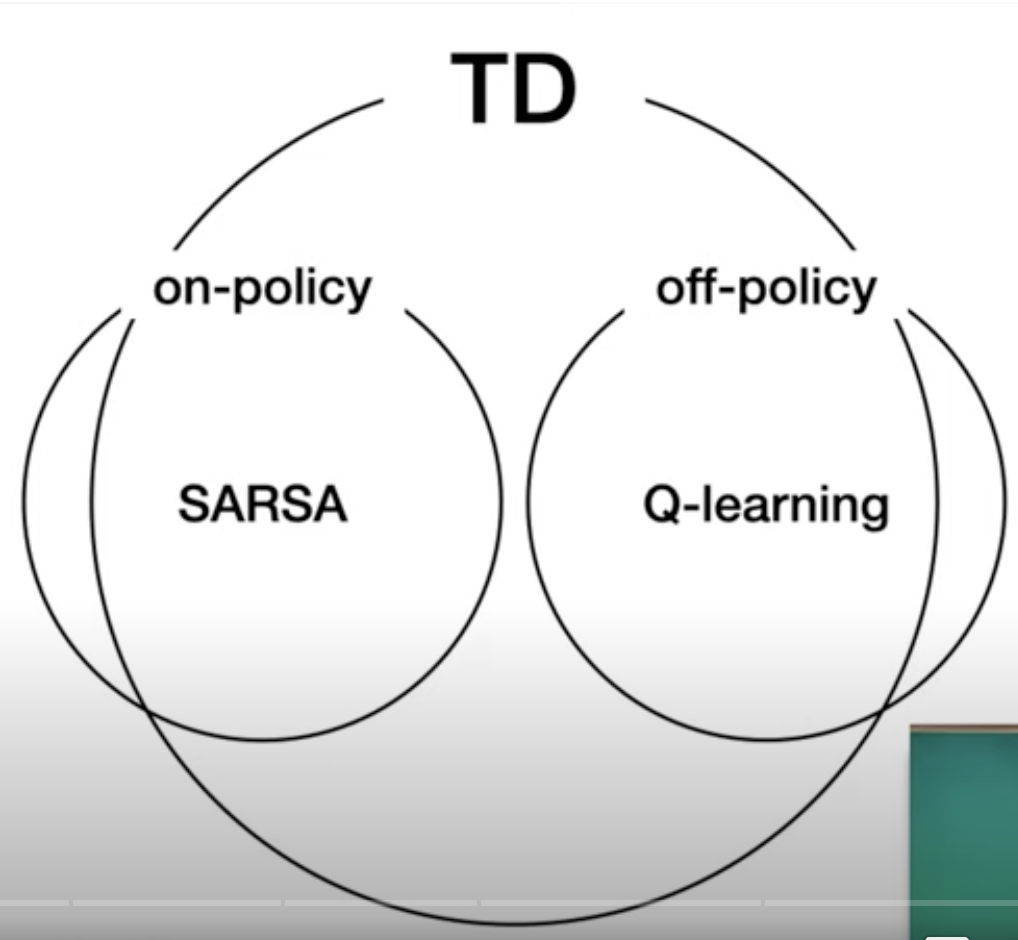
On Policy => Behavior Policy = Target Policy
Off Policy => Behavior Policy != Target Policy
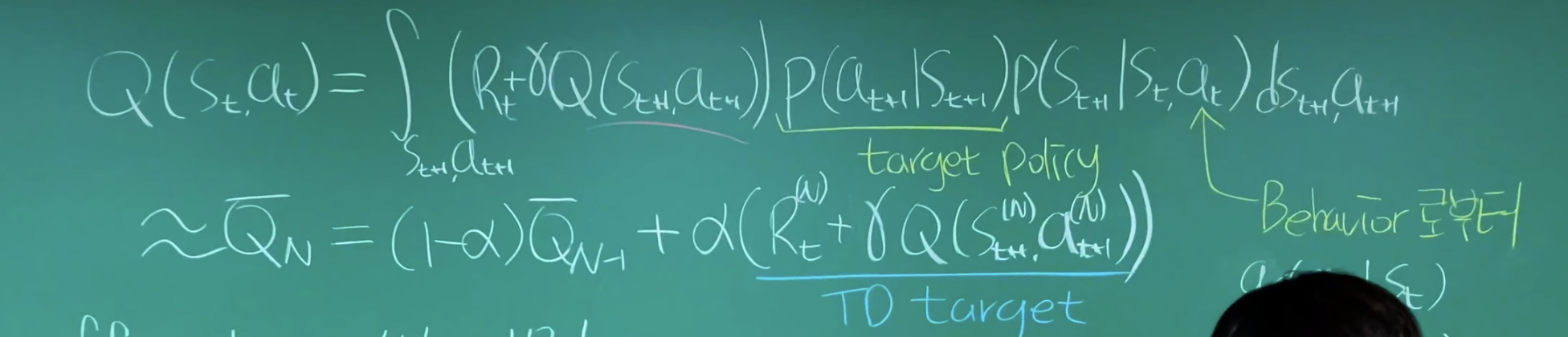
Policy랑 Transition Probability가 일치하면 On Policy 아니면 Off Policy정도로 이해했다.
Off Policy의 강점
- 실컷 탐험하면서 Optimal Policy 탐색(Greedy)
- 재평가 가능 (On Policy에서는 Target Policy와 Behavior Policy가 같아서 Q에 의해 Target Policy가 이미 다 결정된 상태(?))
