SNU 강화학습의 기초 (1)
Bellman Equation
- S state에서의 Value function은 최종 State까지 가서 구할 필요가 없고 다음 state s'의 Value Function의 평균과 S에서의 Reward의 기댓값으로 표현이 가능하다. => 현재 State의 Value Function은 다음 State의 Value Function에 의해 결정된다.


-
Value Function v = (I-감마P)^(-1)*R 이다.
R: 현재 state의 리워드
감마: discount factor
P: 전이행렬
v: 다음 state에서의 value function -
어떤 n*n행렬의 inverse는 O(n^3)으로 알려져 있다.
=> 이론은 좋지만 현대 컴퓨터로는 계산 불가능
MDP
-
MRP에 Action을 추가한것.
-
MDP < S,A,P,R,감마 >
S: finite set of states
A: finite set of actions
P: P(s+1|s,a) transition probability matrix
R: reward function
감마: discount factor
-
Policy가 deterministic할 수도 있지만 stochastic할 수도 있다. 이 때 각 action을 취할 확률로 표현된다. P(a|s)
-
강화학습의 목적은 Policy를 구하는 것이다.

-
MDP에서 Policy는 현재 state에 의해서만 결정된다.
-
가정: Policy는 시간에 대해 불변한다. => 너무 복잡해져서
-
MDP를 다시 MRP관점에서 볼 수 있다. state와 Policy만 뽑아내면 순수한 Markov process가 된다. MDP에서 A만 빼면 MRP가 된다. 뽑아낼 때 Action 확률에 대해 평균을 취하면 된다.

첫번째 식 MDP를 MRP의 Transition Probability로 바꾸는 것. a에 대해 평균 취한것.
두번째 식도 MDP의 Reward를 MRP의 Reward로 바꾼 것.

-
MDP의 State Value Function은 state s와 policy 파이에 의한 기댓값이다.(policy가 추가) E파이로 쓰는 이유는 Stochastic Policy이기 때문이다. 이전에는 State밖에 Random variable이 없었는데 여기서는 action까지 random variable이다.
-
MDP의 Action Value Function은 조건부확률 조건에 action이 추가된다.

- 3번쨰 줄에서 3번째 줄로 넘어갈 때 action에 대해서도 평균을 취하고 action이 정해졌을 때 다음 state와 reward에 대해서도 평균을 취한다.
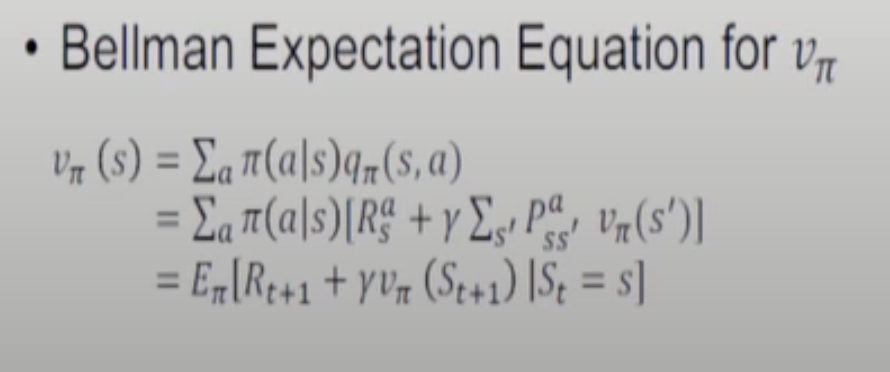
action value function이랑 policy 곱으로 action에 대해 평균을 취하면 stae value function이 나온다.



(1), (2) 두 개의 수식을 조합하여 마지막 (3)수식이 나온다.

다음과 같이 벡터로 표현될 수 있다. 여기서 모델은 우리가 알고 있다고 가정하는데 이것은 P Matrix, R 모델을 알고 있다는 뜻이다.
=> 현실적인 문제에서는 계산 불가능한 식이다. 너무 오래걸려서.
Optimal Value Function

Optimal Value Function은 Optimal Policy 가 정해지면 찾을 수 있다.

정의: 모든 State에 대해서 1번 Policy가 2번 Policy보다 Value Function이 크면 1번 Policy가 2번 Policy보다 크다고 나타낸다.
(Policy는 스칼라 값이 아니므로 원래는 부등호로 나타낼 수 없음)
만약 일부 state에서는 1번 Policy가 좋고 나머지 state에서는 2번 Policy가 좋다면 두 개를 합쳐서 제일 좋은 3번 Policy를 만들 수 있다.


어떤 MDP던 Deterministic Optimal Policy 가 항상 존재한다. 이때까지 Action에 대해 평균취한 값은 Optimal Policy 를 선택했을 때 Value Function보다 항상 작거나 같다. 따라서 평균을 취할 필요가 없다.
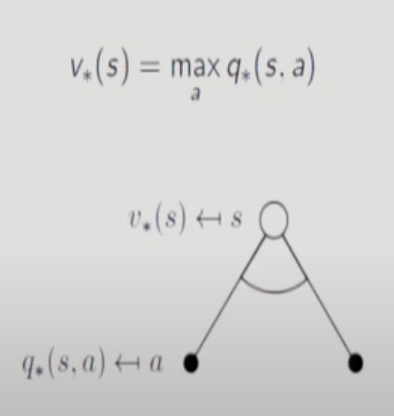
다이어 그램에 곡선이 들어가면 그중에 하나를 고른다는 뜻임. action value function을 최대화 하는 a를 선택.
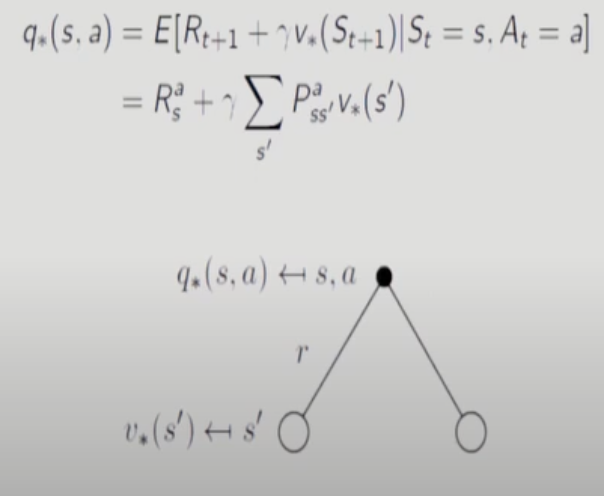
a를 선택해도 state는 확정되지 않으니까 state 평균취함.
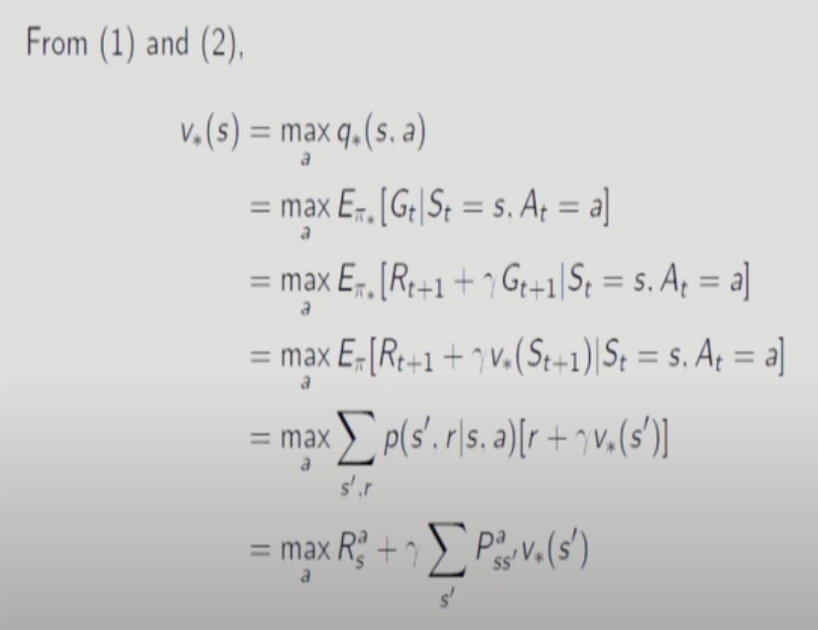
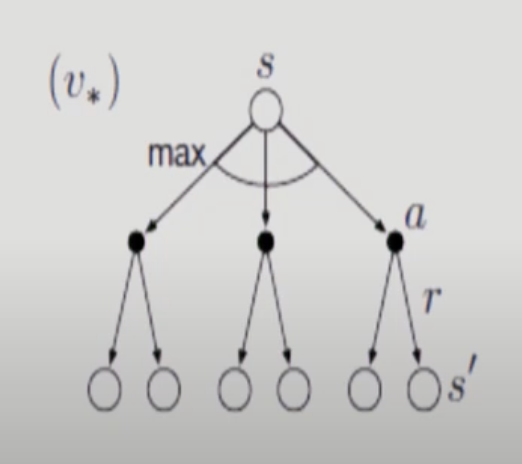
action value function을 state 평균 취한값으로 구한 후 그 값이 최대가 되는 a를 선택
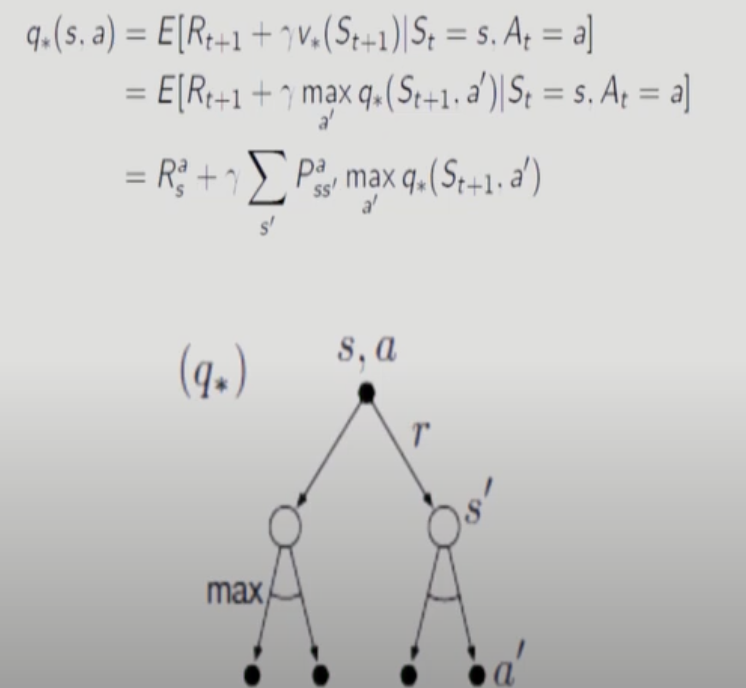
action value function 평균 취하는데 이때 각 state(T+1)에서 action value function을 최대화 하는 a를 선택해서 평균을 취한다.
POMDPs

State를 직접 알 수 없음 => 확률적으로 state를 예측하는데 그것을 belief state라고 함.

Ergodic Markov Process

state가 주기적으로 반복되지 않고, 재방문이 가능한 Markov Process.
특정 state로 수렴함. => 선형대수로 증명 가능
