
04-1. 연결리스트의 개념적인 이해
연결리스트 : ‘malloc’ 함수와 ‘free’ 함수를 기반으로 하는 메모리의 동적할당
- 배열은 메모리의 특성이 정적이어서 메모리의 길이를 변경하는 것이 불가능하다. 메모리의 크기에 유연하게 대처하지 못한다.
#include <stdio.h>
int main(void)
{
int arr[10];
int readCount = 0;
int readData;
int i;
while(1)
{
printf("자연수 입력: ");
scanf("%d", &readData);
if(readData < 1) break;
arr[readCount++] = readData;
}
for(i = 0;i<readCount;i++) printf("%d ", arr[i]);
return 0;
}- 동적인 메모리의 구성
#include <stdio.h>
#include <stdlib.h>
typedef struct _node
{
int data;
struct _node *next;
} Node;
int main(void)
{
Node * head = NULL;
Node * tail = NULL;
Node * cur = NULL;
Node * newNode = NULL;
int readData;
// 데이터를 입력 받는 과정 //
while(1)
{
printf("자연수 입력: ");
scanf("%d", &readData);
if(readData < 1) break;
// 노드의 추가과정
newNode = (Node*)malloc(sizeof(Node));
newNode->data = readData;
newNode->next = NULL:
if(head == NULL) head = newNode;
else tail->next = newNode;
tail = newNode;
}
printf("\n");
// 입력 받은 데이터의 출력과정 //
printf("입력 받은 데이터의 전체출력! \n");
if(head == NULL)
{
printf("저장된 자연수가 존재하지 않습니다. \n");
}
else
{
cur = head;
printf("%d ", cur->data); // 첫 번째 데이터 출력
while(cur->next != NULL) // 두 번째 이후의 데이터 출력
{
cur = cur->next;
printf("%d ", cur->data);
}
}
printf("\n\n");
// 메모리의 해체과정 //
if(head == NULL)
{
return 0; // 해체할 노드가 존재하지 않는다.
}
else
{
Node * delNode = head;
Node *delNextNode = head->next;
printf("%d을(를) 삭제합니다. \n", head->data);
free(delNode); // 첫 번째 노드 삭제합니다
while(delNextNode != NULL) // 두 번째 이후 노드 삭제
{
delNode = delNextNode;
delNextNode = delNextNode->next;
printf("%d을(를) 삭제합니다. \n", delNode->data);
free(delNode);
}
}
return 0;
}구조체
typedef struct _node
{
int data; // 데이터를 담을 공간
struct _node * next; // 연결의 도구
}- next : node와 node를 연결할 목적
연결리스트의 기본 원리 : ‘malloc’ 또는 그와 유사한 성격의 함수를 호출하는 메모리의 동적 할당
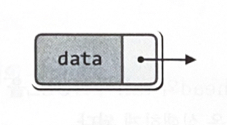
’데이터를 저장할 장소’와 ‘다른 변수를 가리키기 위한 장소’가 구별되어 있다

연결리스트에서의 데이터 삽입
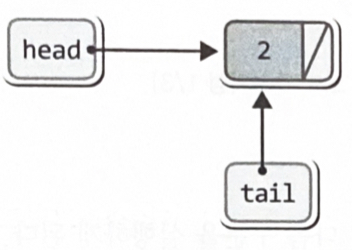
head는 리스트의 머리를 가리키고, tail은 리스트의 꼬리를 가리킨다.
- 포인터 변수의 선언
Node * head = NULL;
Node * tail = NULL;
Node * cur = NULL;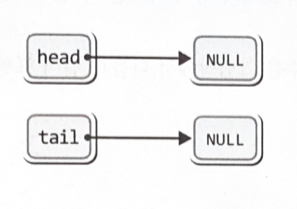
- 노드의 생성과 초기화
newNode = (Node *) malloc(sizeof(Node)); // 노드의 생성
newNode->data = readData; // 노드에 데이터 저장
newNode->next = NULL: // 노드의 Next를 NULL로 초기화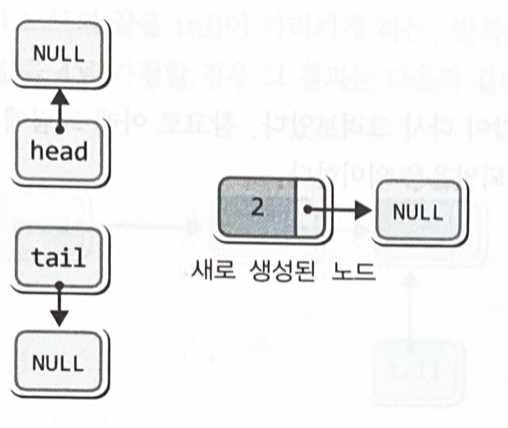
if(head == NULL)
head = newNode;
else
tail->next = newNode;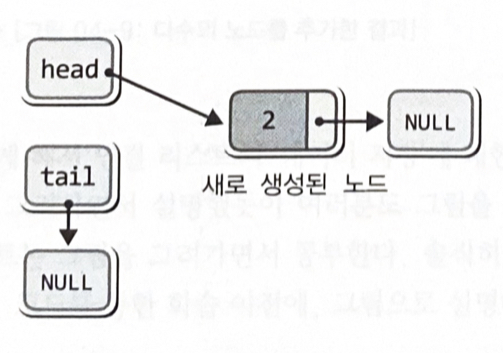
tail = newNode;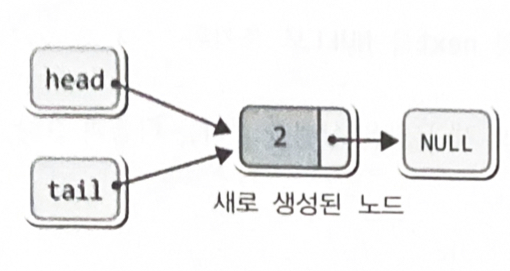
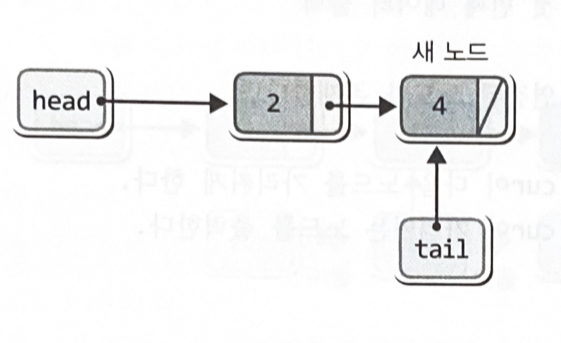
- 두 번째 이후 노드를 추가하는 과정
while(1)
{
// 일부 과정 생략 //
newNode = (Node*)malloc(sizeof(Node));
newNode->data = readData;
newNode->next = NULL:
if(head == NULL) head = newNode;
else tail->next = newNode;
tail = newNode; // 노드의 끝이 tail이 가리키게 함
}tail->next = newNode;
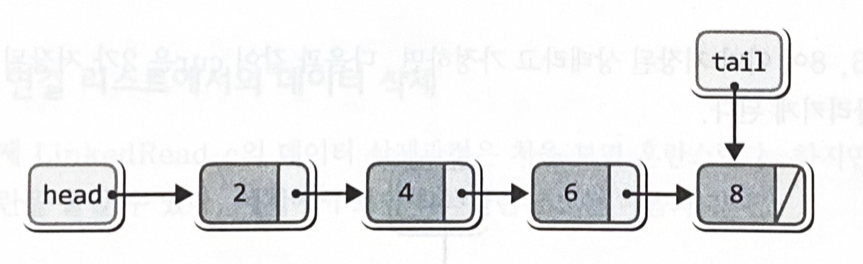
연결리스트에서의 데이터 조회
if(head == NULL)
{
printf("저장된 자연수가 존재하지 않습니다. \n");
}
else
{
cur = head;
printf("%d ", cur->data); // 첫 번째 데이터 출력
while(cur->next != NULL) // 두 번째 이후의 데이터 출력
{
cur = cur->next;
printf("%d ", cur->data);
}
}cur = head;
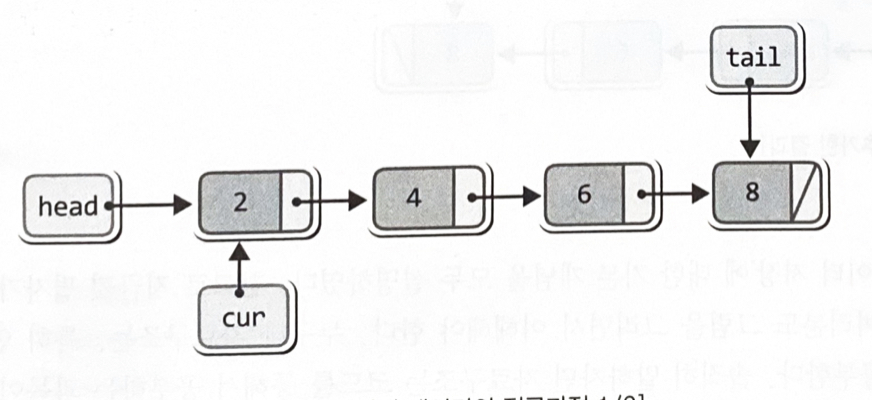
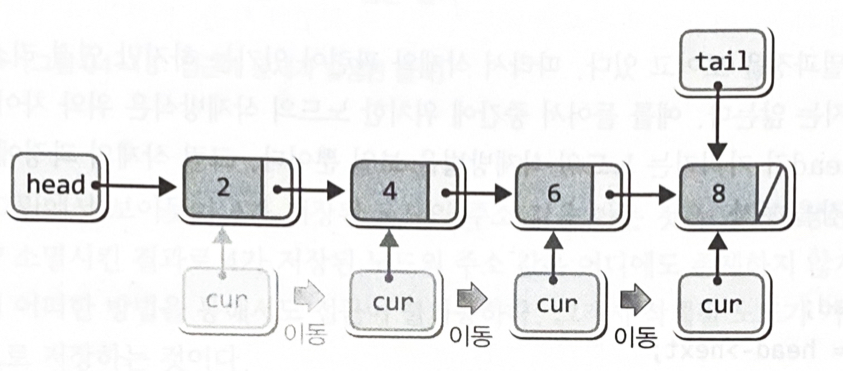
while(cur->next != NULL) // 두 번째 이후의 데이터 출력
{
cur = cur->next;
printf("%d ", cur->data);
}cur = cur->next;
연결리스트에서의 데이터 삭제
if(head == NULL)
{
return 0; // 해체할 노드가 존재하지 않는다.
}
else
{
Node * delNode = head;
Node *delNextNode = head->next;
printf("%d을(를) 삭제합니다. \n", head->data);
free(delNode); // 첫 번째 노드 삭제합니다
while(delNextNode != NULL) // 두 번째 이후 노드 삭제
{
delNode = delNextNode;
delNextNode = delNextNode->next;
printf("%d을(를) 삭제합니다. \n", delNode->data);
free(delNode);
}
}Node *delNode = head;
Node *delNextNode = head->next;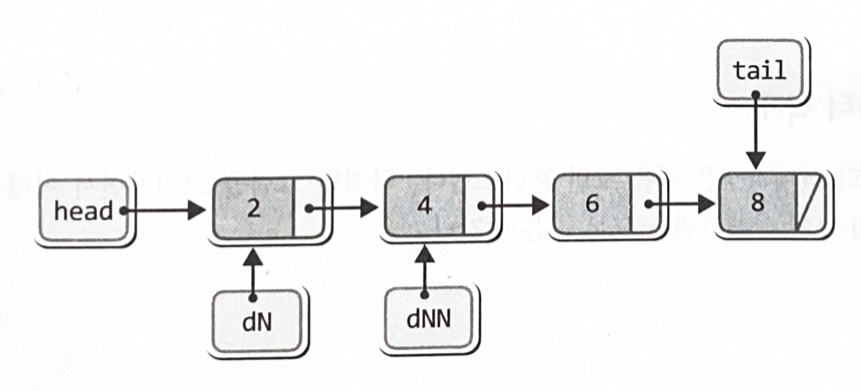
head가 가리키는 노드를 그냥 삭제해 버리면, 그 다음 노드에 접근이 불가능하다
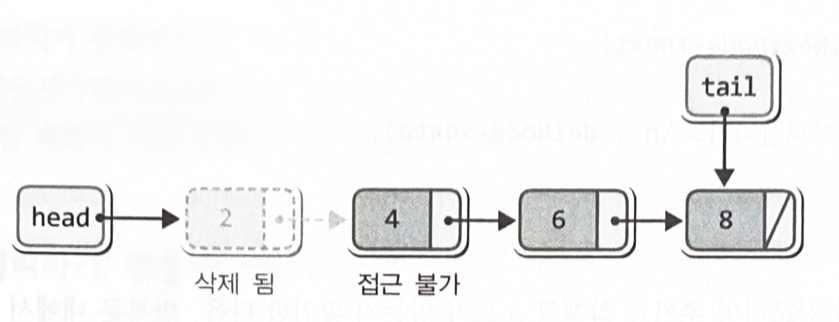
free(delNode);
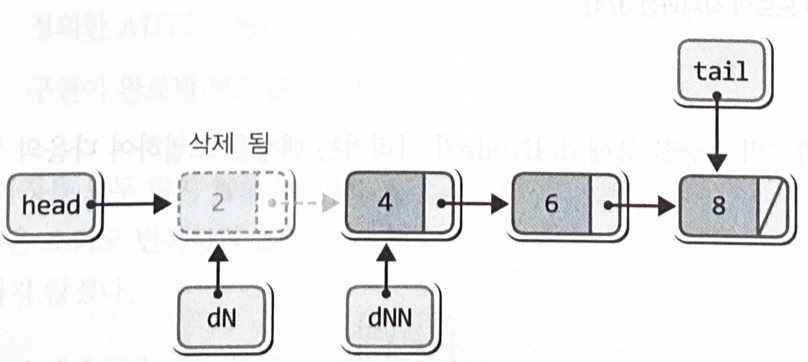
while(delNextNode != NULL) // 두 번째 이후 노드 삭제
{
delNode = delNextNode;
delNextNode = delNextNode->next;
printf("%d을(를) 삭제합니다. \n", delNode->data);
free(delNode);
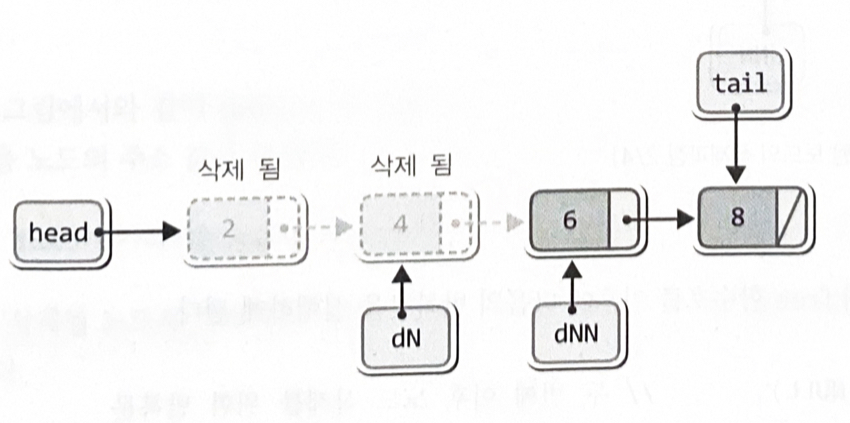
}delNode = delNextNode;
delNextNode = delNextNode->next;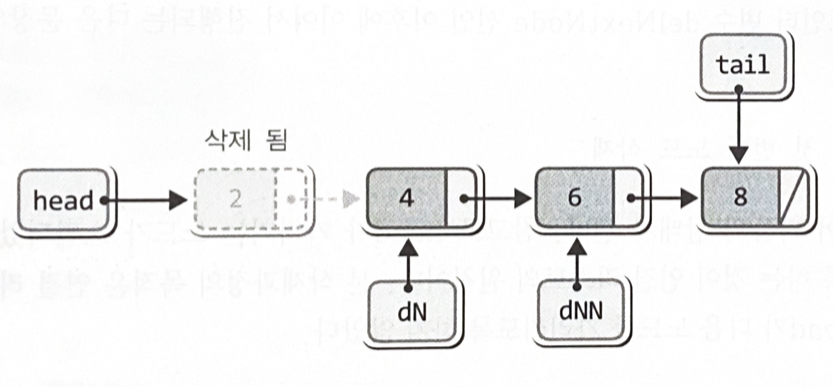
04-2. 단순 연결 리스트의 ADT와 구현
단순 연결 리스트
연결의 형태가 한쪽 방향으로 전개되고 시작과 끝이 분명히 존재한다.
추가된 ADT
void SetSortRule(List *plist, int (*comp)(LData d1, LData d2));- 새 노드를 추가할 때
- 머리에 추가
- 장점 : 포인터 변수 tail이 불필요
- 단점 : 저장된 순서를 유지하지 않는다
- 꼬리에 추가
- 장점 : 저장된 순서가 유지
- 단점 : 포인터 변수 tail이 필요
리스트 자료구조는 저장된 순서를 유지해야 하는 자료구조가 아니다
int (*comp)(LData d1, LData d2)
”반환형이 int이고 LData형 인자를 두 개 전달받는 함수의 주소 값을 두 번째 인자로 전달하라”
- SetSortRule함수의 두 번째 인자에 오는 함수
int WhoIsPrecede(LData d1, LData d2)
{
if(d1 < d2) return 0; // d1이 정렬 순서상 앞선다.
else return 1; // d2가 정렬 순서상 앞선다.
}- D1이 head에 더 가깝다
head . . . D1 . . . D2 . . . tail - D2가 head에 더 가깝다
head . . . D2 . . . D1 . . . tail
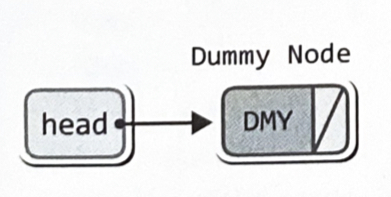
더미 노드(Dummy Node) 기반의 단순 연결 리스트

처음 추가되는 노드가 구조상 두 번째 노드가 되므로, 삭제 및 조회의 과정을 일관된 형태로 구성할 수 있다
더미노드(Dummy Node) 단순 연결 리스트의 초기화와 노드 삽입
- 구조체
typedef struct _node
{
Node * head; // 더미 노드를 가리키는 멤버
Node * cur; // 참조 및 삭제를 돕는 멤버
Node *before; // 삭제를 돕는 멤버
int numOfData; // 저장된 데이터의 수를 기록하기 위한 멤버
int (*comp)(LData d1, LData d2); // 정렬의 기준을 등록하기 위한 멤버
} LinkedList;- 초기화
void ListInit(List *plist)
{
plist->head = (Node*)malloc(sizeof(Node));
plist->head->next = NULL;
plist->comp = NULL;
plist->numOfData = 0;
}
- 노드의 추가
void LInsert(List *plist, LData data)
{
if(plist->comp == NULL) // 정렬기준이 마련되지 않았다면,
FInsert(plist, data) // 머리에 노드를 추가
else // 정렬기준이 마련되었다면,
SInsert(plist, data) // 정렬기준에 근거하여 노드를 추가!
}- FInsert함수void FInsert(List *plist, LData data)
{
Node *newNode = (Node*)malloc(sizeof(Node)); // 새 노드 생성
newNode->data = data; // 새 노드에 데이터 저장
newNode->next = plist->head->next; // 새 노드가 다른 노드를 가리키게 함
plist->head->next = newNode; // 더미 노드가 새 노드를 가리키게 함
(plist->numOfData)++; // 저장된 노드의 수를 하나 증가시킴
}void FInsert(List *plist, LData data)
{
Node *newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
. . . .
}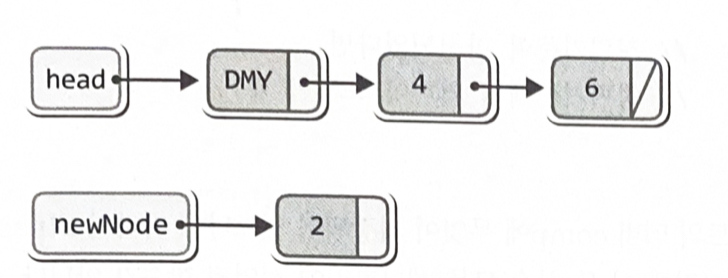
newNode->next = plist->head->next; // 새 노드가 다른 노드를 가리키게 함
plist->head->next = newNode; // 더미 노드가 새 노드를 가리키게 함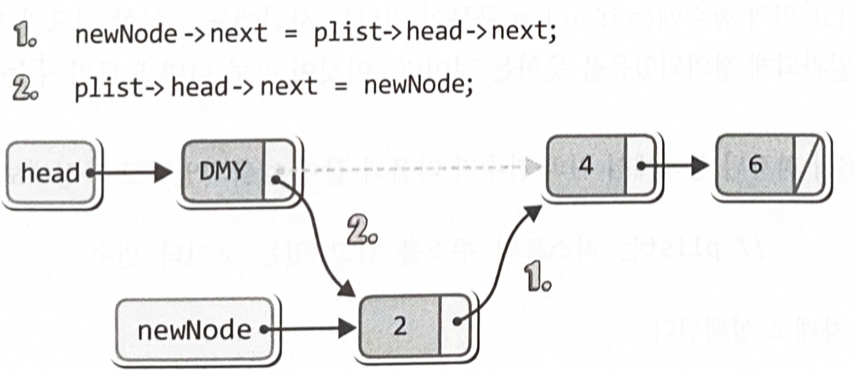
더미노드(Dummy Node) 단순 연결 리스트의 데이터 조회
- LFirst 함수
int LFirst(List *plist, LData *pdata)
{
if(plist->head->next == NULL) // 더미 노드가 NULL을 가리킨다면
return FALSE; // 반환할 데이터가 없다
plist-> before = plist-> head; // before는 더미 노드를 가리키게 함
plist->cur = plist->head->next; // cur은 첫 번째 노드를 가리키게 함
*pdata = plist->cur->data; // 첫 번째 노드의 데이터를 전달
return TRUE; // 데이터 반환 성공!
}plist-> before = plist-> head; // before는 더미 노드를 가리키게 함
plist->cur = plist->head->next; // cur은 첫 번째 노드를 가리키게 함
*pdata = plist->cur->data;
before가 cur보다 하나 앞선 노드를 가리킨다
- LNext 함수
int LNext(List *plist, LData *pdata)
{
if(plist->cur->next = NULL) // 더미노드가 NULL을 가리킨다면
return FALSE;
plist->before = plist->cur; // cur이 가맄던 것을 beore가 가리킴
plist->cur = plist->cur->next; // cur이 그 다음 노드를 가리킴
*pdata = plist->cur->data; // cur이 가리키는 노드의 데이터 전달
return TRUE; // 데이터 반환 성공
}plist->before = plist->cur; // cur이 가맄던 것을 beore가 가리킴
plist->cur = plist->cur->next; // cur이 그 다음 노드를 가리킴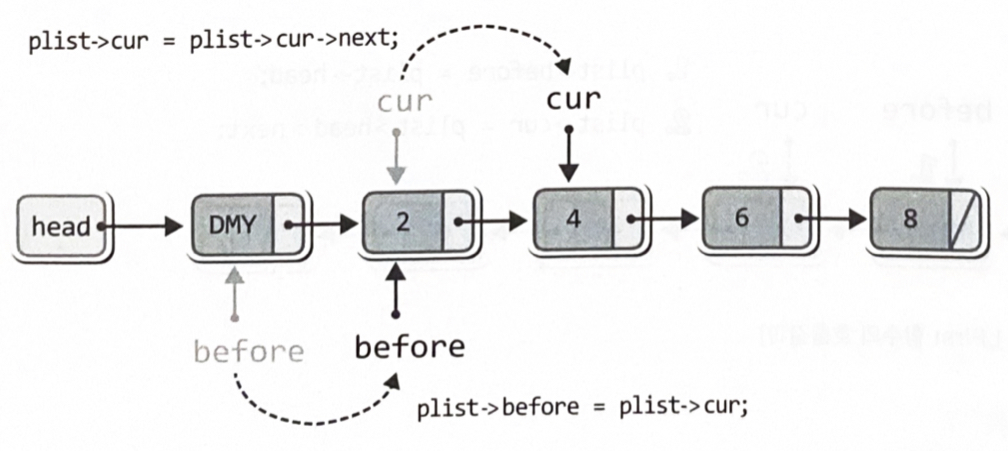
더미 노드(Dummy Node) 단순 연결 리스트의 노드 삭제
LRemove함수 : 바로 이전에 호출된 LFirst 혹은 LNext 함수가 반환한 데이터를 삭제한다
LFirst혹은 LNext함수가 재차 호출된다면 before는 다시 cur보다 하나 앞선 노드를 가리키게 되므로 before의 위치까지 재조정할 필요는 없다
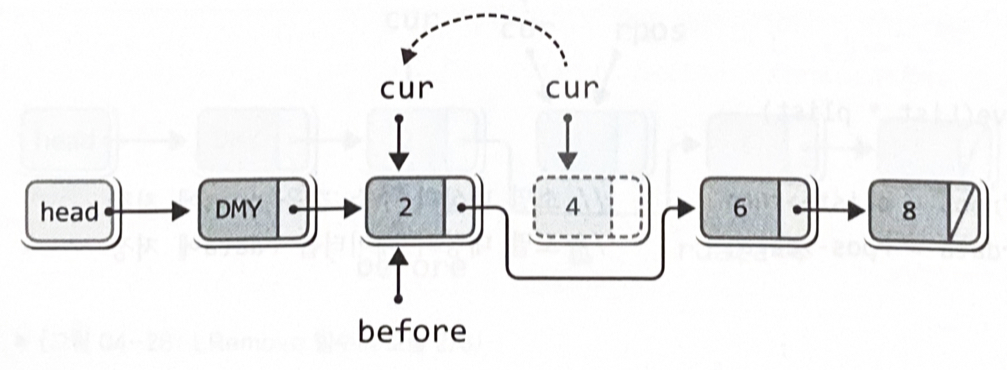
LData LRemove(List *plist)
{
Node *rpos = plist->cur; // 소멸 대상의 주소 값을 rpos에 저장
LData rdata = rpos->data; // 소멸 대상의 데이터를 rdata에 저장
plist->before->next = plist->cur->next; // 소멸 대상을 리스트에서 제거
plist->cur = plist->before; // cur이 가리키는 위치를 재조정
free(rpos); // 리스트에서 제거된 노드 소멸
(plist->numOfData)—; // 저장된 데이터의 수 하나 감소
return rdata; // 제거된 노드의 데이터 반환
}Node *rpos = plist->cur; // 소멸 대상의 주소 값을 rpos에 저장
LData rdata = rpos->data; // 소멸 대상의 데이터를 rdata에 저장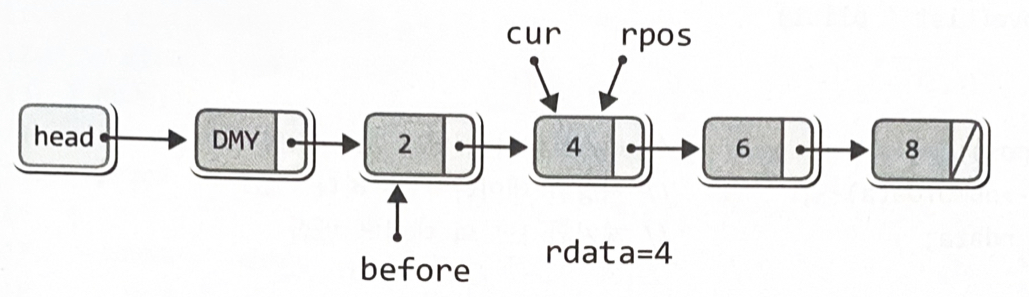
plist->before->next = plist->cur->next; // 소멸 대상을 리스트에서 제거
plist->cur = plist->before; // cur이 가리키는 위치를 재조정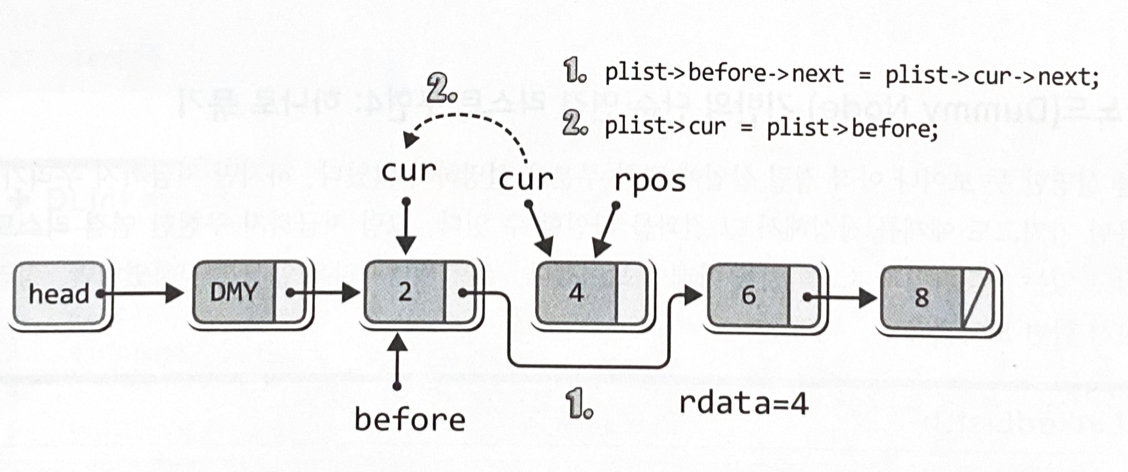
free(rpos); // 리스트에서 제거된 노드 소멸
(plist->numOfData)—; // 저장된 데이터의 수 하나 감소
return rdata; // 제거된 노드의 데이터 반환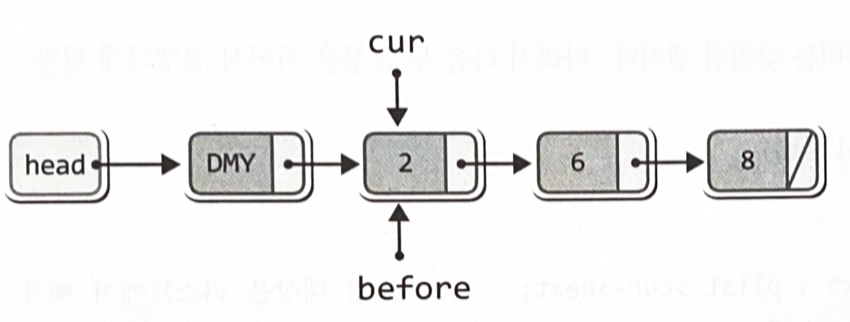
연결 리스트의 정렬 삽입의 구현
- 연결 리스트의 정렬기준이 되는 함수를 등록하는 SetSortRule 함수
- SetSortRule 함수를 통해서 전달된 함수 정보를 저장하기 위한 LinkedList 함수의 멤버 Comp
- comp에 등록된 정렬기준을 근거로 데이터로 저장하는 SInsert 함수
SetSortRule함수가 호출되면서 정렬의 기준이 리스트의 멤버 comp 에 등록되면, SInsert함수 내에서는 comp에 등록된 정렬의 기준을 근거로 데이터를 정렬하여 저장한다
void SetSortRule(List *plist, int (*comp)(LData d1, LData d2))
{
plist->comp = comp;
}void SInsert(List *plist, Ldata data)
{
Node *newNode = (Node*)malloc(sizeof(Node)); // 새 노드의 생성
Node *pred = plist->head; // pred는 더미 노드를 가리킴
newNode->data = data; // 새 노드에 데이터 저장
// 새 노드가 들어갈 자리를 찾기 위한 반복문
while(pred->next != NULL && plist->comp(data, pred->next->data) != 0)
{
pred = pred->next; // 다음 노드로 이동
}
newNode->next = pred->next; // 새 노드의 뒤를 연결
pred->next=newNode; // 새 노드의 앞을 연결
(plist->numOfData)++; // 저장된 데이터의 수 하나 증가
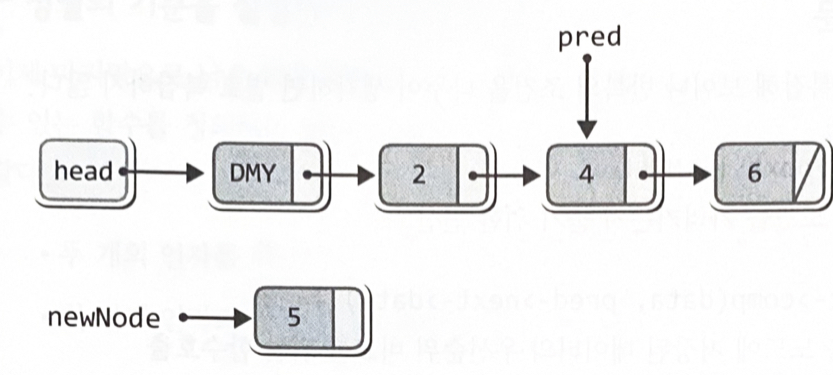
} Node *newNode = (Node*)malloc(sizeof(Node)); // 새 노드의 생성
Node *pred = plist->head; // pred는 더미 노드를 가리킴
newNode->data = data; // 새 노드에 데이터 저장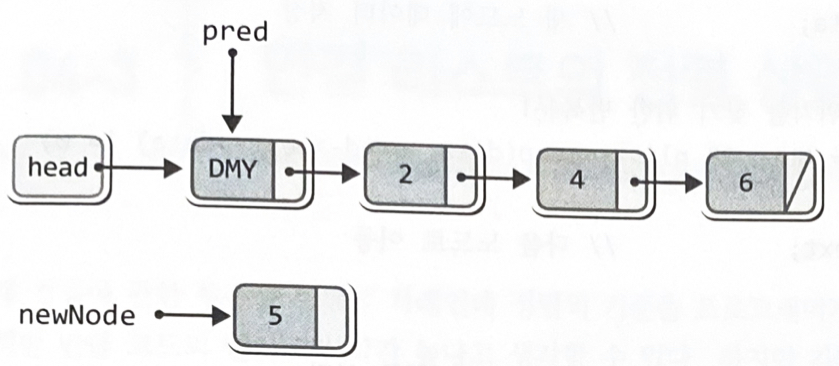
while(pred->next != NULL && plist->comp(data, pred->next->data) != 0)
{
pred = pred->next; // 다음 노드로 이동
}
newNode->next = pred->next; // 새 노드의 뒤를 연결
pred->next=newNode; // 새 노드의 앞을 연결
(plist->numOfData)++; // 저장된 데이터의 수 하나 증가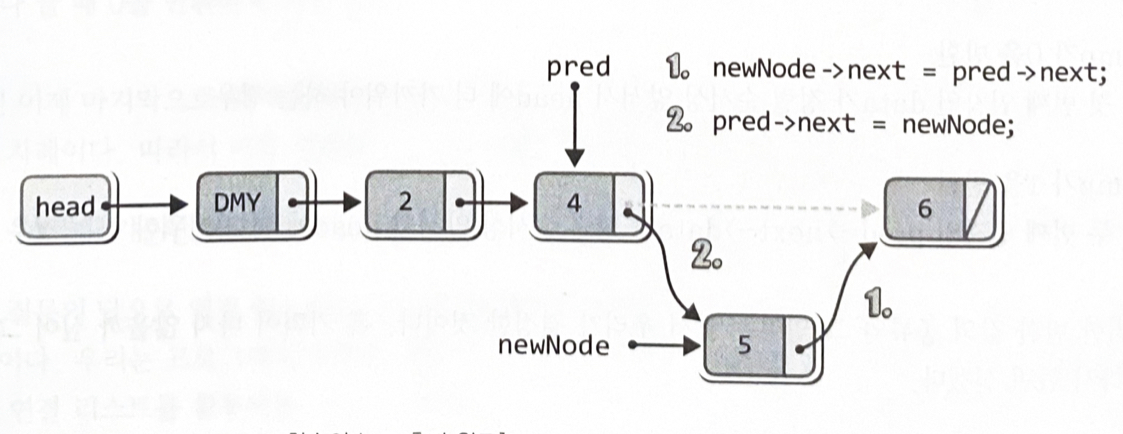
정렬의 핵심인 while 반복문
- pred->next != NULL
- plist->comp(data, pred->next->data) != 0
- comp가 0을 반환
: 첫 번째 인자인 data가 정렬 순서상 앞서서 head에 더 가까워야 하는 경우 - comp가 1을 반환
: 두 번째 인자인 pred->next->data가 정렬 순서상 앞서서 head에 더 가까워야 하는 경우
SetSortRule함수의 정의
- 두 개의 인자를 전달받도록 정의
- 첫 번째 인자의 정렬 우선순위가 높으면 0을, 그렇지 않으면 1을 반환한다
int WhoIsPrecede(int d1, int d2) // typedef int LData;
{
if(d1 < d2)
return 0; // d1이 정렬 순서상 앞선다
else
return 1; // d2가 정렬 순서상 앞서거나 같다
}오름차순 정렬 : 값이 작을수록 정렬 우선순위가 높다
내림차순 정렬 : 첫 번째 인자인 d1의 값이 두 번째 인자인 d2보다 클 때 0을 반환한다
