
DB 접근에 대한 카프카 적용은 사실 설정에 기본값만 넣는다면 그 자체로 큰 어려움은 없다. 카프카가 뭐지?라는 뜬구름이 좀 있어서 이벤트에 대한 토픽 메세지를 설계할 때에만 잠깐 막히다가, 그 외의 설정에 대한 고민은 없어도 기능 구현은 사실 구글 검색을 통해 해결할 수 있기 때문이다. 우선은 적용한 코드에 대해 먼저 정리하고, 다음 포스팅에서 카프카를 적용한 아키텍처에 대해 정리하기로 한다.
Spring Kafka 카프카 클라이언트 설정
우선 스프링 카프카 의존성을 설정한다. 스프링과 함께 적용해주면 되는데, Spring Boot Starter는 진작에 추가되어있던 것이므로 Spring Kafka만 추가해주면 된다. Spring Kafka는 카프카를 스프링에서 쉽게 사용할 수 있도록 만들어진 라이브러리이다.
pom.xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>그리고 바로 YAML 설정
application.yml
spring:
kafka:
bootstrap-servers: localhost:9092,localhost:9093,localhost:9094브로커 개수는 권장 최솟값인 3개로 설정해주었다. 그리고 각 브로커의 포트는 9092, 9093, 9094로 열어 연결시켰다. 참고로 현재 주키퍼 모드로 돌리고 있으며, 이들은 직접 커맨드로 실행시키지 않고 도커 컴포즈를 통해 가동할 수 있도록 하였다.
docker-compose.yml
version: '3'
services:
zookeeper:
image: 'bitnami/zookeeper:3.7.2'
container_name: zookeeper
ports:
- 2181:2181
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
volumes:
- ./.data/zookeeper/data:/bitnami/zookeeper/data
- ./.data/zookeeper/datalog:/bitnami/zookeeper/datalog
- ./.data/zookeeper/logs:/bitnami/zookeeper/logs
kafka1:
image: 'bitnami/kafka:3.6.0'
container_name: kafka1
ports:
- 19092
- "9092:9092"
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:19092,EXTERNAL://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka1:19092,EXTERNAL://localhost:9092
- KAFKA_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
volumes:
- ./.data/kafka1:/bitnami/kafka/data
kafka2:
image: 'bitnami/kafka:3.6.0'
container_name: kafka2
ports:
- 19092
- "9093:9093"
environment:
- KAFKA_BROKER_ID=2
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:19092,EXTERNAL://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka2:19092,EXTERNAL://localhost:9093
- KAFKA_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
volumes:
- ./.data/kafka2:/bitnami/kafka/data
kafka3:
image: 'bitnami/kafka:3.6.0'
container_name: kafka3
ports:
- 19092
- "9094:9094"
environment:
- KAFKA_BROKER_ID=3
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:19092,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka3:19092,EXTERNAL://localhost:9094
- KAFKA_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
volumes:
- ./.data/kafka3:/bitnami/kafka/data
kafka-ui:
image: 'provectuslabs/kafka-ui:v0.7.1'
container_name: kafka-ui
ports:
- "8089:8080"
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:19092,kafka2:19092,kafka3:19092
depends_on:
- zookeeper
- kafka1
- kafka2
- kafka3그리고 도커 컴포즈 파일에서 볼 수 있듯이, 나는 Kafka-UI를 통해 브로커와 컨슈머, 토픽 등을 관리할 수 있도록 하였다.
그럼 마지막 설정인 프로듀서와 컨슈머를 설정하는 KafkaConfig.java를 보도록 하자.
KafkaConfig.java
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean
@Primary
@ConfigurationProperties("spring.kafka")
public KafkaProperties kafkaProperties() {
return new KafkaProperties();
}
@Bean
@Primary
public ProducerFactory<String, Object> producerFactory(KafkaProperties kafkaProperties) {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.ACKS_CONFIG, "-1");
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
return new DefaultKafkaProducerFactory<>(props);
}
@Bean
@Primary
public KafkaTemplate<String, ?> kafkaTemplate(KafkaProperties kafkaProperties) {
return new KafkaTemplate<>(producerFactory(kafkaProperties));
}우선 설정 중 프로듀서 설정 먼저 살펴보자. 스프링 카프카 라이브러리를 통해 kafkaTemplate의 의존성을 자동으로 주입받을 수 있는데, 기본으로 사용되는 kafkaTemplate이 아닌 직접 설정하기 위한 kafkaTemplate을 위해 @Primary 어노테이션을 붙여준다. 그리고 동시에 생성되는 producerFactory의 설정을 보도록 하자.
우선 BOOTSTRAP_SERVERS_CONFIG는 application.yml에서 설정한 브로커 리스트로 지정하고, KEY_SERIALIZER_CLASS_CONFIG와 VALUE_SERIALIZER_CLASS_CONFIG는 모두 StringSerializer.class로 지정하였다. 그리고 왠만한 비즈니스 로직에 적용되는 카프카 프로듀서 설정에서는 ACKS_CONFIG을 -1로 지정되는데, ACKS_CONFIG로 가능한 설정 값으로는 0, 1, -1이 있다.
ACKS
acks=0: 프로듀서가 리더 파티션으로 데이터를 전송했을 때 리더 파티션으로 데이터가 저장되었는지 확인하지 않는다. 이 경우, 응답값을 필요로 하지 않기 때문에 데이터 전송 속도가 1과 -1의 경우보다 훨씬 빠르지만, 데이터가 일부 유실될 수 있다.acks=1: 프로듀서는 보낸 데이터가 리더 파티션에만 정상적으로 적재되었는지 확인한다. 만약 리더 파티션에 정상적으로 적재되지 않았다면 적재될 때까지 재시도할 수 있다. 다만 적재된 이후 동기화되기 직전에 리더 파티션이 있는 브로커에 장애가 발생한다면 데이터는 유실될 수 있다.acks=-1 (acks=all): 프로듀서는 보낸 데이터가 리더 파티션과 팔로워 파티션에 모두 정상적으로 적재되었는지 확인한다. 이로 인해 0 또는 1 옵션보다도 속도가 느리다. 그럼에도 불구하고 팔로우 파티션에 데이터가 정상 적재되었는지 기다리기 때문에 일부 브로커에 장애가 발생하더라도 프로듀서는 안전하게 데이터를 전송하고 저장할 수 있음을 보장할 수 있다.
ISR
여기서 ISR(In-sync-replicas)에 대해서도 같이 알아두면 좋은데, 아주 간단하게만 언급하고 지나가자면, 이는 프로듀서가 리더 파티션과 팔로워 파티션에 데이터가 적재되었는지 확인하기 위한 최소 ISR 그룹의 파티션 개수를 말한다. 이는 min.insync.replicas 옵션을 통해 설정할 수 있는데, 이를 설정할 때에는 복제 개수도 함께 고려해야 한다. 왜냐하면 운영하는 카프카 브로커 개수가 min.insync.replicas의 옵션값보다 작은 경우에는 프로듀서가 더는 데이터를 전송할 수 없기 때문이다. 실제 카프카 클러스터를 운영하면서 브로커가 동시에 2개가 중단되는 일은 극히 드물기 때문에 리더 파티션과 팔로워 파티션 중 1개에 데이터가 적재 완료되었다면 데이터는 유실되지 않는다고 볼 수 있으므로, 많은 경우 min.insync.replicas의 옵션값을 2로 설정하게 된다.
멱등성 프로듀서
다시 돌아와서, ACKS_CONFIG를 ALL로 지정하였고, 이제는 ENABLE_IDEMPOTENCE_CONFIG에 대해서 살펴보자면, 멱등성 프로듀서의 개념에 대해 알아둘 필요가 있다. 멱등성 프로듀서는 동일한 데이터를 여러 번 전송하더라도 카프카 클러스터에 단 한 번만 저장됨을 말한다. 기본 프로듀서는 적어도 한번 전달(at least once delivery)를 지원한다면, enable.idempotence 옵션을 통해 정확히 한번 전달(exactly once delivery)을 지원하는 멱등성 프로듀서는 데이터를 브로커로 전달할 때 PID(Producer unique ID)와 시퀀스 넘버(Sequence number)를 함께 전달한다. 그러면 브로커는 프로듀서의 PID와 시퀀스 넘버를 확인하여 동일한 메시지의 적재 요청이 오더라도 단 한 번만 데이터를 적재함으로써 프로듀서의 데이터는 정확히 한번 브로커에 적재되도록 동작한다. 그래서 ACKS_CONFIG를 ALL로 지정하면 데이터의 중복이 발생할 수 있지만, 멱등성 프로듀서를 설정해줌으로써 데이터 중복을 방지한다.
그럼 이제 이어서 컨슈머 설정에 대해 살펴보자.
@Bean
@Primary
public ConsumerFactory<String, Object> consumerFactory(KafkaProperties kafkaProperties) {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG, "false");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
@Primary
CommonErrorHandler errorHandler() {
CommonContainerStoppingErrorHandler containerStoppingErrorHandler = new CommonContainerStoppingErrorHandler();
AtomicReference<Consumer<?, ?>> alternativeConsumer = new AtomicReference<>();
AtomicReference<MessageListenerContainer> alternativeContainer = new AtomicReference<>();
DefaultErrorHandler errorHandler = new DefaultErrorHandler((record, ex) -> {
containerStoppingErrorHandler.handleRemaining(
ex, Collections.singletonList(record), alternativeConsumer.get(), alternativeContainer.get());
}, generateBackOff()) {
@Override
public void handleRemaining(Exception thrownException, List<ConsumerRecord<?, ?>> records,
Consumer<?, ?> consumer, MessageListenerContainer container) {
alternativeConsumer.set(consumer);
alternativeContainer.set(container);
super.handleRemaining(thrownException, records, consumer, container);
}
};
errorHandler.addNotRetryableExceptions(JsonProcessingException.class);
return errorHandler;
}
@Bean
@Primary
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory(
ConsumerFactory<String, Object> consumerFactory, CommonErrorHandler errorHandler) {
ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setCommonErrorHandler(errorHandler);
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.RECORD);
return factory;
}
private BackOff generateBackOff() {
ExponentialBackOff backOff = new ExponentialBackOff(1000, 2);
backOff.setMaxAttempts(3);
return backOff;
}
}kafkaListenerContainerFactory라는 것을 통해서 consumerFactory와 errorHandler의 의존성을 주입받게 되고, 여기서 AckMode는 컨슈머의 커밋에 대한 설정을 말하는데, 기본으로 많이 사용되는 RECORD로 지정하였다.
consumerFactory에서 KEY_DESERIALIZER_CLASS_CONFIG와 VALUE_DESERIALIZER_CLASS_CONFIG는 StringDeserializer.class로 지정하였으며, 토픽은 브로커에서 직접 만들어줄 것이므로 ALLOW_AUTO_CREATE_TOPICS_CONFIG은 false, ENABLE_AUTO_COMMIT_CONFIG는 메시지 손실을 방지하기 위해 메시지 처리가 문제없이 완료되었을 경우에만 commit을 수행하도록 컨슈머의 offset commit을 수동으로 설정하기 위해 false로 지정하였다.
컨슈머 예외 통제
프로듀서에서는 메시지를 만들어서 토픽에 쌓아두면 컨슈머는 이 메시지들을 읽어오게 되는데, 프로듀서는 메시지를 만들어 보내기만 하면 그 이상의 책임은 없지만, 컨슈머는 만들어진 메시지를 직접 처리해야 하다보니 각종 상황 대응을 할 수 있어야 한다. 이때 컨슈머 관점에서의 예외는 크게 JsonProcessingException과 TimeoutException이 있다. 전자의 경우 파싱 과정에서 문제가 있는 것이다보니 이는 애초에 코드 레벨에서 수정을 해주어야 하는 경우이고, 후자는 몇번의 재시도를 통해 해결할 수도 있는 문제이다. 그래서 전자는 Not Retryable, 후자는 Retryable로 분류해볼 수 있다. Not Retryable의 경우에는 서비스 운영 중에 조치할 수 있는 다른 방법은 없는 부분이고, 그렇기에 컨슈머에서는 Retryable 예외에 대해 처리할 수 있도록 해야 한다.
그 방법으로 Retry Policy가 있고, 보다 유연하게 하기 위해 이를 Exponential하게 설정할 수 있다. 그리고 재시도를 했음에도 불구하고 결국 실패하게 된다면, 해당 레코드는 읽지 않고 건너 뛸 수도 있지만, 그렇지 않고 모든 레코드를 하나씩 순차적으로 읽고자 한다면 해당 컨슈머를 중단시킨 뒤에 재생시켜볼 수도 있다. 이는 에러 핸들링을 통해 가능하다.
errorHandler에서는 BackOff를 통해 재시도 방식을 설정할 수 있는데, 여기서는 ExponentialBackOff 방식으로 1초 단위로 2의 제곱수씩 증가하여 최대 3번의 재시도를 하도록 하였다. 예를 들어, 첫 번째 재시도는 1초 뒤에, 이후 두 번째 재시도는 2초 뒤에, 이후 세 번째 재시도는 4초 뒤에 한다. 이 과정이 실패한다면 해당 컨슈머를 중단시키고 나서 재생할 수 있도록 대체 컨슈머와 대체 컨테이너를 두도록 하였다. JsonProcessingException에 대해서는 Not Retryable한 예외이므로 errorHandler.addNotRetryableExceptions()로 포기하도록 했다.
여기까지 카프카 클라이언트의 설정을 살펴봤다.
카프카 토픽 메시지 설계
개인적으로는 토픽 메시지를 설계하는 것을 어떻게 해야할지가 꽤 막막했다. 그러한 이유로는 우선 어떠한 메시지가 필요한건지, 즉 어떠한 이벤트에 의해 메시지를 발행하도록 할 건지가 정해지지 않았기 때문인 듯하다. 그리고 이벤트를 어떻게 잡았다고 쳐도, 메시지는 어떠한 형태가 되어야하는지에 대해 여전히 걱정이었다. 왜냐하면 이 메시지는 간소화되어야할지, 아니면 모든 데이터를 담은 복잡한 메시지가 되어야할지 등에 대해서도 이 메시지의 사용처를 어디에 두는지에 따라 달라질 것 같은데, 당장 와닿는 느낌이 없었기 때문이다. 이는 프로듀서와 컨슈머의 구조 자체가 낯설었던 것도 있다. 이렇게 막연한 느낌은 본래 추상적인 이벤트라는 속성 때문일텐데, 이로 인해 카프카를 적용한 아키텍처를 이벤트 기반 아키텍처라고 부르는 이유일 것이다.
아무튼, 지금 이 글에서는 전체 토픽에 대해서 살펴보는 것이 아니라, 주문서비스의 토픽 메세지에 대해서만 공유하고자 한다.
Topic.java
public class Topic {
public static final String ORDER_TOPIC = "order.topic";
public static final String DELIVERY_TOPIC = "delivery.topic";
}주문서비스에서는 order.topic이라는 토픽과 delivery.topic이라는 토픽의 메세지를 발행하고 구독하고자 한다. 사실 여기서 설계 미스가 있음을 느꼈는데, 주문서비스에서 배송 관련 서비스는 별도의 분리된 애플리케이션에서 구현되어야 했다. 안타깝게도 프로젝트를 마무리하는 시점에서 서비스의 밑부분을 건드리는 게 상당한 부담이라 아쉬운대로 어쩔 수 없었다.
OperationType.java
public enum OperationType {
CREATE, UPDATE, DELETE
}메시지를 발행할 때 OperationType에 값을 지정해서 전송하면 컨슈머 측에서 이 설정값에 따라 데이터를 처리하는 방식을 달리하도록 하였다.
OrderTopicMessage.java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class DeliveryTopicMessage {
private Long id;
private Payload payload;
private OperationType operationType;
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Payload {
private Long id;
private DeliveryStatus deliveryStatus;
private TransceiverInfoData transceiverInfo;
private AddressData address;
private List<DeliveryTrackingData> deliveryTrackings;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class TransceiverInfoData {
private String ordererName;
private String receiverName;
private String receiverPhoneNumber;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class AddressData {
private String city;
private String street;
private String details;
private String zipcode;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class DeliveryTrackingData {
private String courier;
private String contactNumber;
private String postLocation;
private LocalDateTime postDateTime;
}
}주문서비스의 토픽 메시지로 OrderTopicMessage도 있으나 여기서는 DeliveryTopicMessage만 살펴본다. DeliveryTopicMessage에는 필드로 id, payload, operationType이 있는데, id는 키(key)로 사용할 것이다. 카프카에서 메시지의 순서 보장은 토픽의 파티션을 기준으로 이루어지는데, 이때 동일한 키(key)의 메시지는 순서 보장에 의해 해당 파티션에서 가장 최신의 메시지를 읽을 수 있도록 한다. 따라서 해당 메시지의 데이터에 변경사항이 발생한다면 UPDATE라는 operationType 값에 따라 동일한 키(key)의 메시지들 중 가장 높은 오프셋에 최신화된 데이터가 위치함에 따라 데이터 정합성 관련 문제를 해결한다. 예를 들어, 배송 관련 데이터에서 배송 현황 정보가 업데이트될 경우, 그 시간 순서가 꼬이지 않고 가장 최근에 업데이트 된 데이터를 정상적으로 읽을 수 있도록 보장한다.
이벤트?
이 토픽 메시지의 Payload는 사실 DB에 저장되는 Delivery 엔티티와 동일한 필드를 갖고 있다. 이는 카프카를 적용하는 데에 있어서 이벤트를 DB 접근 시 비동기 처리에 초점을 맞추다보니 엔티티와 동일한 형태를 갖는 자연스러운 귀결이었다. 왜냐하면 데이터를 DB에 저장할 때 메시지가 발행되고, 또 데이터를 DB에서 읽는 지점에서 DB가 아닌 컨슈머가 갖는 최신화된 데이터를 가져오면 되기 때문이다.
이벤트 및 프로듀서 구현
토픽 메시지를 설계했으니, 메시지를 발행하는 프로듀서를 구현해야 한다.
DeliveryProducer.java
@Component
@RequiredArgsConstructor
public class DeliveryProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
private final CustomObjectMapper objectMapper = new CustomObjectMapper();
private final DeliveryMapper deliveryMapper;
public void sendMessage(DeliveryTopicMessage message) {
try {
kafkaTemplate.send(Topic.DELIVERY_TOPIC,
String.valueOf(message.getId()),
objectMapper.writeValueAsString(message));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}보통은 operationType에 따라 메시지 발행 방식을 달리 하기 위해 sendCreateMessage, sendUpdateMessage, sendDeleteMessage를 하나씩 구현해주기도 할텐데, 현재 내 프로젝트의 카프카를 적용하는 목적 상에서는 별도로 구현할 필요는 없었다. 그리고 메시지의 키(key)는 String.valueOf(message.getId()), 메시지의 id로 지정하였다.
프로듀서까지 구현되었으니, 메시지 발행 방식을 어떻게 해야할까.
CDC
여기서 잠깐 CDC(Change Data Capture)에 대해서 알아둘 필요가 있다. 큰 의미로는 DB 데이터의 변경사항을 카프카 메시지로 발행하는 작업을 말하는데, 이에 대한 세 가지 방식이 있다.
try-catch@TransactionalEventListener@EntityListeners
내 프로젝트에서는 두 번째 @TransactionalEventListener 방식을 채택하였는데, 이유는 다음과 같다. try-catch 방식에서는 try-catch 문 내에서 DB 접근과 바로 이어서 카프카 프로듀싱을 이루게 되는데, 만일 DB 접근과 카프카 프로듀싱을 마찬 이후에 에러가 발생한다면 DB는 롤백되지만 카프카 메시지는 롤백되지 않아 데이터 정합성이 깨지게 된다. 그리고 @EntityListener의 경우에는 엔티티의 상태를 직접 참조할 수 있어 DB 접근이나 엔티티 상태를 기반으로 한 작업을 쉽게 수행할 수 있지만, 기본적으로 동기 방식으로 동작하여 비동기 처리를 직접적으로 구현하기는 어렵다. 반면 @TransactionalEventListener는 @Transactional의 트랜잭션의 커밋 이후에 별개로 실행되기 때문에, @TransactionalEventListener 부분에서 예외가 발생해도 DB 롤백이 이루어지지 않아 비교적 카프카를 통한 비동기 처리에 적합하다고 판단했다.
이에 따라 이벤트와 이벤트 리스너 객체를 별도로 작성했다.
DeliveryEvent.java
@Getter
public class DeliveryEvent extends ApplicationEvent {
private final Long id;
private final DeliveryTopicMessage.Payload payload;
private final OperationType operationType;
public DeliveryEvent(Object source, Long id, DeliveryTopicMessage.Payload payload, OperationType operationType) {
super(source);
this.id = id;
this.payload = payload;
this.operationType = operationType;
}
}DeliveryEventListener.java
@Component
@RequiredArgsConstructor
public class DeliveryEventListener {
private final DeliveryProducer deliveryProducer;
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
@Async
public void transactionalEventListenerAfterCommit(DeliveryEvent event) {
System.out.println("DeliveryEventListener.transactionalEventListenerAfterCommit");
deliveryProducer.sendMessage(new DeliveryTopicMessage(event.getId(), event.getPayload(), event.getOperationType()));
}
}DB 접근에 대한 비동기 처리가 목적인 이벤트인만큼, 이벤트 객체가 카프카 토픽 메시지와 형태가 달라져야 할 이유는 없었다. 그리고 이벤트 리스너 객체에서는 @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)를 통해 트랜잭션 커밋 이후에 해당 이벤트가 동작하여 프로듀서의 메시지 발행이 이루어지도록 하였다.
그럼 이제 마지막으로 컨슈머를 살펴보도록 하자.
컨슈머 구현
OrderServiceConsumer.java
@Service
@RequiredArgsConstructor
@Slf4j
public class OrderServiceConsumer {
private final CustomObjectMapper objectMapper = new CustomObjectMapper();
private final DeliveryMapper deliveryMapper;
private final DeliveryDocumentRepository deliveryDocumentRepository;
/** 생략 **/
@KafkaListener(topics = { Topic.DELIVERY_TOPIC }, groupId = "order-consumer-group", concurrency = "2")
public void listenDeliveryTopic(ConsumerRecord<String, String> record) throws JsonProcessingException {
DeliveryTopicMessage message = objectMapper.readValue(record.value(), DeliveryTopicMessage.class);
if (message.getOperationType() == OperationType.CREATE) {
handleDeliveryCreate(message);
} else if (message.getOperationType() == OperationType.UPDATE) {
handleDeliveryUpdate(message);
} else if (message.getOperationType() == OperationType.DELETE) {
handleDeliveryDelete(message);
}
}
private void handleDeliveryCreate(DeliveryTopicMessage message) {
try {
DeliveryTopicMessage.Payload payload = message.getPayload();
log.info("[{}] Consumed DeliveryTopicMessage: {}",
message.getOperationType(), objectMapper.writeValueAsString(payload));
deliveryDocumentRepository.save(deliveryMapper.toDeliveryDocument(payload));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
private void handleDeliveryUpdate(DeliveryTopicMessage message) {
try {
DeliveryTopicMessage.Payload payload = message.getPayload();
log.info("[{}] Consumed DeliveryTopicMessage: {}",
message.getOperationType(), objectMapper.writeValueAsString(message.getPayload()));
deliveryDocumentRepository.addDeliveryTracking(message.getId(), payload.getDeliveryTrackings().get(0), payload.getDeliveryStatus());
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
private void handleDeliveryDelete(DeliveryTopicMessage message) {
try {
log.info("[{}] Consumed DeliveryTopicMessage: {}",
message.getOperationType(), objectMapper.writeValueAsString(message.getPayload()));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}ORDER_TOPIC에 대해 리스닝하는 listenOrderTopic 메서드도 있으나, 여기서는 listenDeliveryTopic에 대해서만 살펴본다.
아래 3개의 메서드는 메시지의 operationType이 CREATE, UPDATE, DELETE 중 무엇인지에 따라 달리 동작하도록 한 것이다. 컨슈머는 @KafkaListener을 통해 메시지를 읽도록 하는데, 이때 topics, groupId, concurrency 등을 지정하도록 한다. 각각 구독하는 토픽과 컨슈머 그룹을 지정해주면 되는데, 여기서 concurrency는 쉽게 말해 스레드 수라고 보면 된다. 스레드마다 하나의 컨슈머가 할당됨에 따라 이는 컨슈머 수라고 볼 수도 있는데, 여기서 그 값은 2로 지정한 이유는 해당 애플리케이션을 3개의 인스턴스로 가동시킬 것을 고려하여 하나의 컨슈머 그룹에 총 6개의 컨슈머가 배정되도록 한 것이다. 보다 자세한 설명은 다음 포스팅에서 할 예정이다.
RDB + NoSQL
카프카 컨슈밍은 클라이언트의 호출에 따라 작업이 이루어지는 것이 아니라, 컨슈머가 가져와야할 메시지가 있을 때 스스로 가져오도록 이루어지는 메커니즘이다보니, 서비스에서 컨슈밍 메시지를 읽을 수 있기 위해서는 메시지를 담아둘 저장소가 필요했다. 나는 그 저장소를 MongoDB로 선택했다. 왜냐하면 RDB는 쓰고 읽는 속도가 느리지만, 그에 비해 비교적 속도가 빠른 NoSQL이면서 다양한 형식의 메시지 데이터를 JSON 형식으로 저장할 수 있기 때문이다.
여기서 MySQL과 MongoDB의 속도를 비교하는 게 글의 목적은 아니지만, 그래도 nGrinder 테스트 결과를 같이 살펴보자면
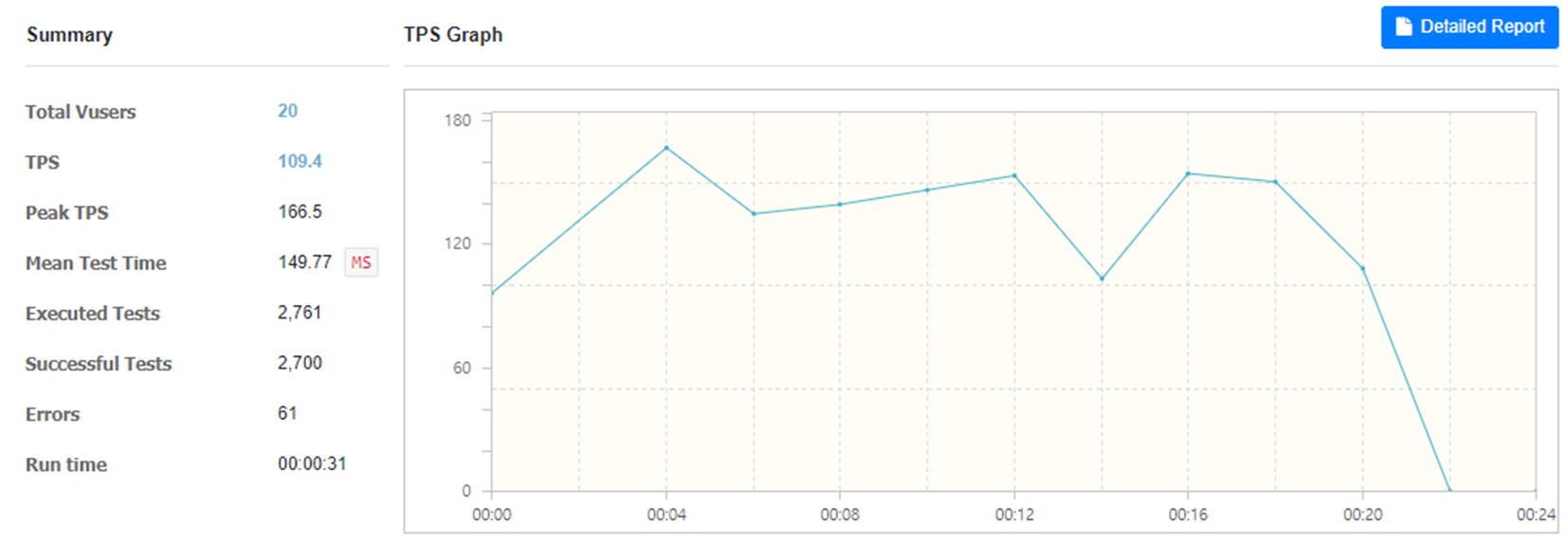
우선 MySQL만 사용한 경우 20명의 가상사용자에 대한 TPS 수치는 109.4이고, 다음으로 MongoDB와 함께 사용한 경우 20명의 가상사용자에 대해서는
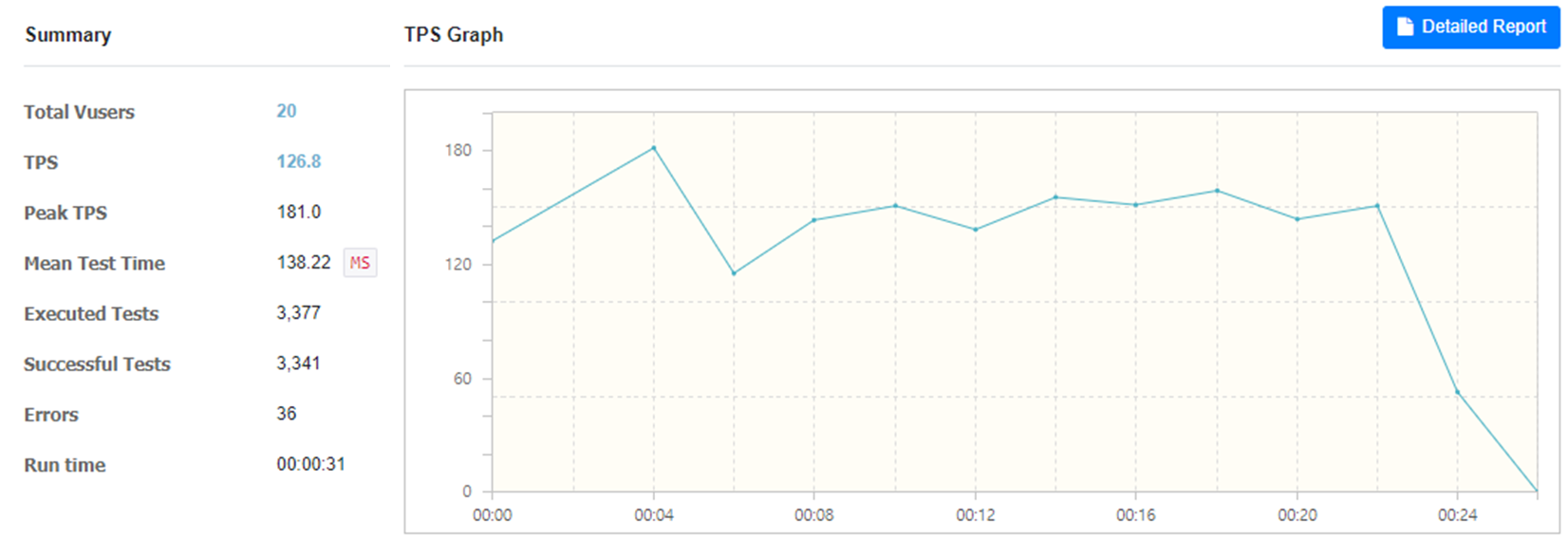
TPS 수치가 126.8이었다. 미미한 차이라고 할 수는 있지만, 성능 향상에 있어서 무의미하지는 않다고 본다.
마무리
카프카를 처음 적용하는 데에 있어서 기능 구현 자체만으로는 어려움이 없을지라도 카프카를 어떻게 설정하고 그 설정에 무엇무엇을 고려해야하는지에 대해서 꽤 깊은 고민을 필요로 했다. 지금은 작은 규모로 카프카를 적용했기에 호수의 더 깊은 곳으로 들어갈 필요까지는 없었지만, 언젠가는 모니터링과 데이터 분석 및 처리, 클라우드 환경에서의 적용까지 해결하는 고수가 되기를 기대하며.
