
처음부터 비동기 처리가 목적이었기에, 카프카 아키텍처는 물론, 이벤트 기반 아키텍처(이하 EDA)에 대해서도 전혀 생각하지 않았다. 카프카를 하나씩 배워가고 직접 다뤄보면서, 결국 카프카를 사용하기 위한 어떠한 설계 개념이 내게 부재함을 느꼈던 것이다. 그래도 시간만 좀 필요할 뿐, 이 역시 하나씩 알아가면 되는 것이었다.
카프카 토픽 설계
백엔드에서도 도메인 데이터를 가장 먼저 설계하듯이, 우선 설계의 첫 대상은 토픽 메시지였다. 이전 포스팅에서도 이에 대한 내용을 잠시 다뤘는데, 토픽 메시지는 어떠한 이벤트를 목적으로 사용될 것인가를 바탕으로 설계할 수 있었다. 나에게는 그저 '비동기 처리'가 목적이었으니, 이것으로 이벤트의 초점을 맞췄다.
비동기 처리가 목적인 이벤트라면, 엔티티의 데이터 구조를 거의 그대로 가져다 쓰면 된다. 다만 카프카는 관리 복잡성이 높은 시스템이므로, 모든 엔티티를 그대로 토픽으로 만들면 유지관리가 어려워진다. 그래서 Order, OrderItem, Delivery, DeliveryTracking 엔티티가 있다고 한다면, 이 네 개의 엔티티를 모두 토픽으로 만드는 것이 아니라 하나로 합칠 수 있다면 합쳐야 관리 비용을 덜게 된다. 나는 어떠한 서비스에 속하는지에 따라 이벤트를 분류하고, 그 분류된 이벤트 안에 하나의 메시지 형태로 합쳐서 구성했다. 즉, order.topic과 delivery.topic으로 분류하고, order.topic 토픽에는 Order와 OrderItem의 데이터를 함께 갖는 OrderTopicMessage 데이터를 구성하였고, delivery.topic 토픽에는 Delivery와 DeliveryTracking의 데이터를 함께 갖는 DeliveryTopicMessage 데이터를 구성하였다. 이는 토픽 메시지가 JSON 구조로 다뤄질 수 있기에 가능한 것이다. 그리고 JSON 객체는 관계형 데이터와 특성이 다르지만, 그 특성을 살리기 위해 OrderTopicMessage에는 deliveryId를 포함하고, DeliveryTopicMessage에는 orderUuid를 포함함으로써, 애플리케이션에서 해당 메시지 데이터를 엔티티 및 DTO 객체로 변환하여 다룰 수 있도록 했다.
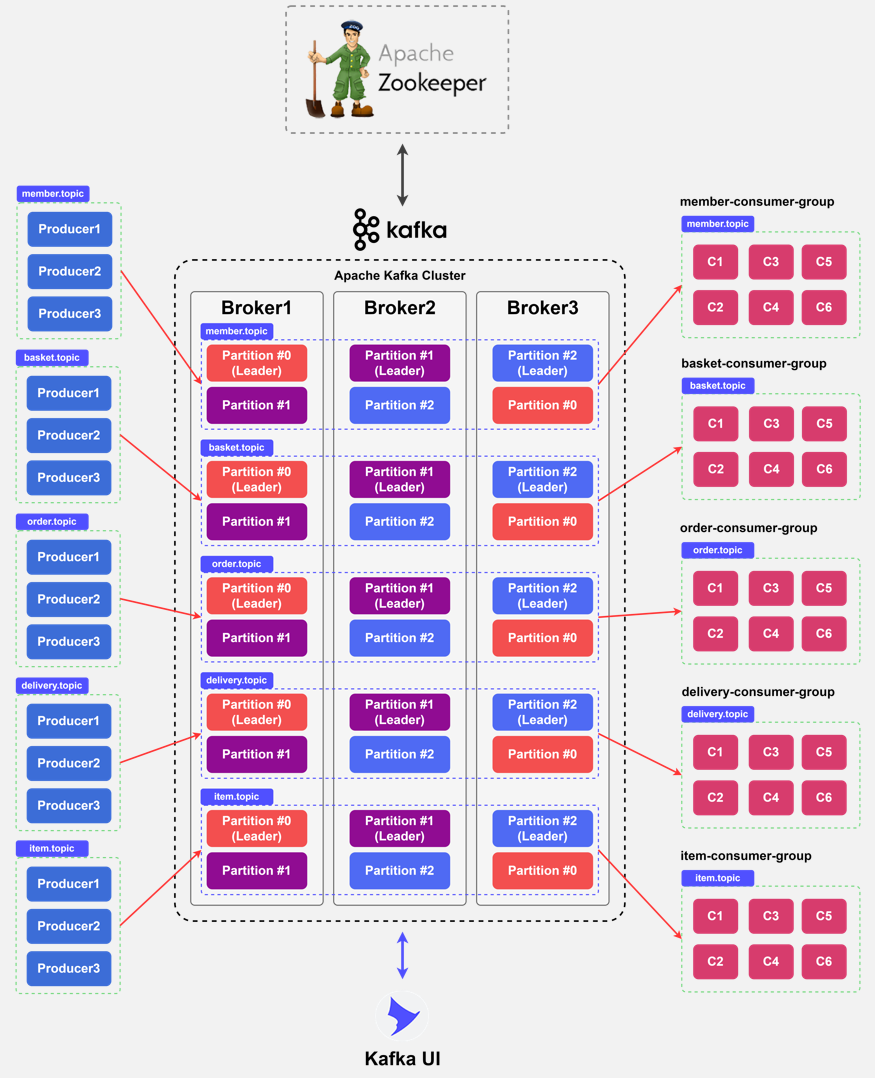
나의 카프카 아키텍처에서는 member.topic, basket.topic, order.topic, delivery.topic, item.topic으로 5개의 토픽을 구성하였다. 그리고 이에 대해 각각의 컨슈머 그룹을 구성하였다.
컨슈머와 파티션
나는 각 마이크로서비스를 3개의 인스턴스로 띄웠다. 3개의 인스턴스를 가동시킴으로써 서비스에 대한 요청의 부하 분산이 가능하고, 하나의 인스턴스가 장애 또는 업데이트 중이라고 하더라도 나머지의 다른 인스턴스들을 통해 정상 운영이 가능해진다. 그리고 각 인스턴스에서는 2개의 컨슈머 스레드를 갖도록 설정했다. 그러므로 한 컨슈머 그룹에서는 6개의 컨슈머를 갖게 된다.
하나의 컨슈머 그룹에 대해 컨슈머를 6개씩 배정한 이유는 카프카 서버의 파티션 개수와 맞추기 위함이었다. 내가 구성한 카프카 클러스터는 3개의 카프카 서버를 가지며, 각 브로커는 1개의 주키퍼 서버로부터 관리받는다. 3개의 카프카 서버가 요구되는 최소 권장사항이고, 파티션은 이 3개의 브로커 내에 분산된다. 브로커 수가 최소 3개여야 하는 이유는 다음과 같다. 각 브로커에는 리더 파티션과 팔로워 파티션을 갖게 되는데, 팔로워 파티션은 리더 파티션으로부터 레코드를 복제하는 역할을 수행한다. 브로커 수가 만약 2개라고 한다면, 1개의 브로커가 장애일 경우 남은 1개의 브로커가 복제 기능을 수행하지 못하고 데이터를 유실할 가능성을 안게 되며, 또 카프카 클라이언트의 모든 요청을 소화해야 한다. 그러므로 카프카 브로커는 3개 이상이어야 한다.
카프카의 적절한 기능 수행을 위해서는 1개의 파티션이 동일 컨슈머 그룹 내에서 1개의 컨슈머와 대응되게 해야 한다. 컨슈머 스레드가 파티션 개수보다 많아지면 할당할 파티션 개수가 더는 없으므로 파티션에 할당되지 못한 컨슈머 스레드는 데이터 처리를 하지 않게 되기 때문이다. 그래서 6개의 컨슈머 스레드와 개수가 동일하게 하나의 토픽에 대해 6개의 파티션으로 구성하였다. (카프카 2.4부터는 컨슈머가 팔로워 파티션에서도 데이터를 읽을 수 있지만, 이를 위해서는 별도의 설정이 필요하고, 실제 운영에서는 권장되지는 않는다고 한다.) 5개의 토픽에 파티션 6개의 구성으로 전체적인 카프카 아키텍처는 아래 그림과 같이 구성되었다.
Application Level CDC
그렇다면 카프카를 통해 어떻게 비동기 처리를 적용하였을까? 비동기 처리를 적용할 부분은 애플리케이션에서 DB에 접근하는 시점이니까, 결국 DB write, DB read를 수행하는 구간에서 카프카 프로듀싱과 컨슈밍이 동작할 수 있게 하면 된다.
데이터 정합성
그런데 비동기 처리 적용 과정에 있어서 데이터 정합성 이슈에 대해서도 고민이 필요했다. 이를 위해 CDC를 적용해야 한다. 물론 인프라 레벨이 아닌 애플리케이션 레벨에서는 CDC를 dual-write 방식으로 수행하다보니 데이터 정합성이 깨질 가능성이 있지만, 그럼에도 애플리케이션 레벨에서의 최선일 것이다. 그리고 여기서 write는 데이터가 DB 테이블과 카프카 메시지로 분리되어 저장함으로써 이루어지는데, read는 데이터를 DB로부터 읽어오게 되는지, 아니면 기존 DB는 백업용으로만 사용하고 카프카 메시지로부터 컨슘해서 읽어오게 되는지 고민이었다. 왜냐하면 현재 애플리케이션 서버를 다중 인스턴스로 돌릴 예정이다보니, DB에서 데이터를 read하는 여러 요청 중에는 특정 id의 레코드를 읽는 동시에 변경이 일어날 수 있기 때문이다. 이 때에는 서버 인스턴스 A와 서버 인스턴스 B가 동시에 읽는다고 할 때 서로 다른 값을 읽게 될 수 있다. 그렇다면 DB read보다 카프카 메시지 컨슘이 더 높은 신뢰성을 가지므로, 모든 데이터의 read 작업은 DB가 아닌 카프카 컨슘을 통해서만 처리하도록 해야한다.
그런데 컨슈밍은 애플리케이션에서 시점을 정해서 할 수 있는 게 아니라, 컨슈머가 알아서 동작하는 구조이다보니 데이터를 읽는 작업이 기존 DB에서 읽는 게 아니라면 정해진 루트가 없다. 컨슈머가 읽어온 데이터를 어딘가에 담아둘 곳이 필요한데, 나는 그 저장소로 JSON 객체 타입으로 저장이 가능하고 결과적 일관성을 제공하는 MongoDB를 사용하기로 했다.
아래 그림은 각 마이크로서비스에서 쓰기와 읽기 작업에 대해 write 및 이벤트를 발행하고 컨슈밍 및 read를 수행하는 과정을 나타냈다.
Member Service
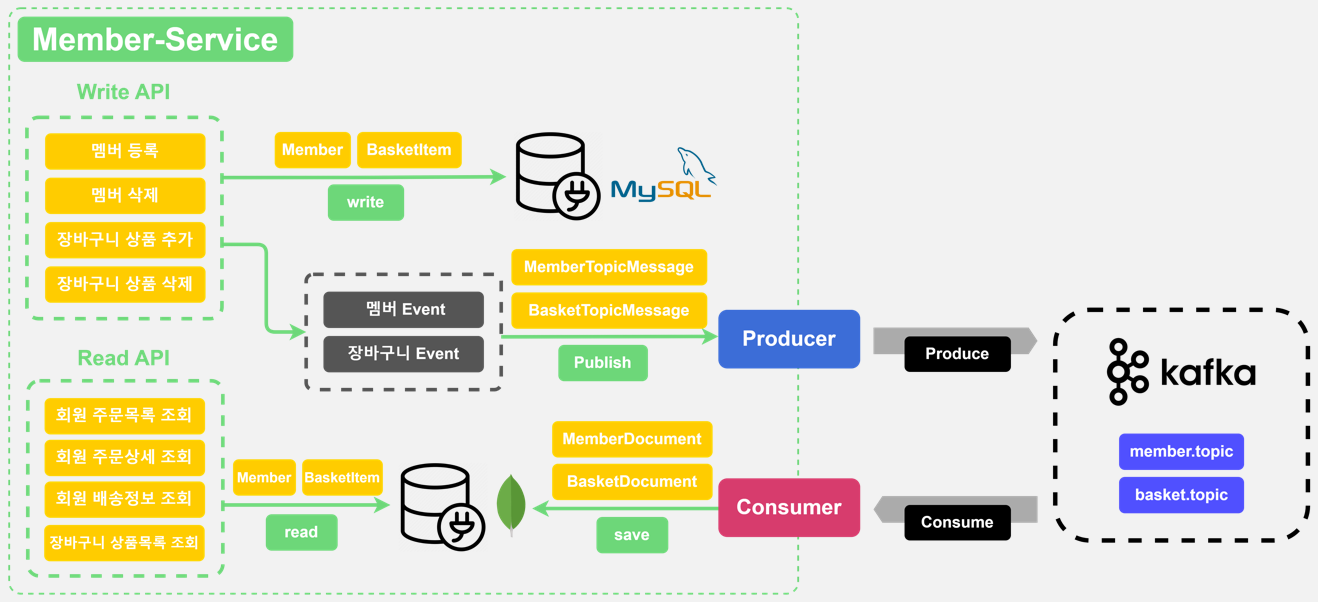
멤버서비스에서는 Member, Basket, BasketItem 엔티티를 다루고 있고, dual-write로 기존 DB 저장과 카프카 프로듀싱을 하게 되는데, 카프카 토픽 메시지인 MemberTopicMessage, BasketTopicMessage로 이 엔티티들을 담을 수 있게 구성하였으며, MemberEvent와 BasketEvent 이벤트를 통해 카프카로 발행된다. 발행된 토픽 메시지는 카프카에서 member.topic, basket.topic 토픽 파티션에 저장되도록 처리하고 컨슈머가 해당 토픽의 레코드를 읽어온다. 그리고 이렇게 읽은 레코드를 MemberDocument, BasketDocument 객체로 변환하여 MongoDB로 저장한다. 그러면 이 애플리케이션에서 데이터를 읽는 작업은 MongoDB를 통해 읽으면 된다.
Order Service
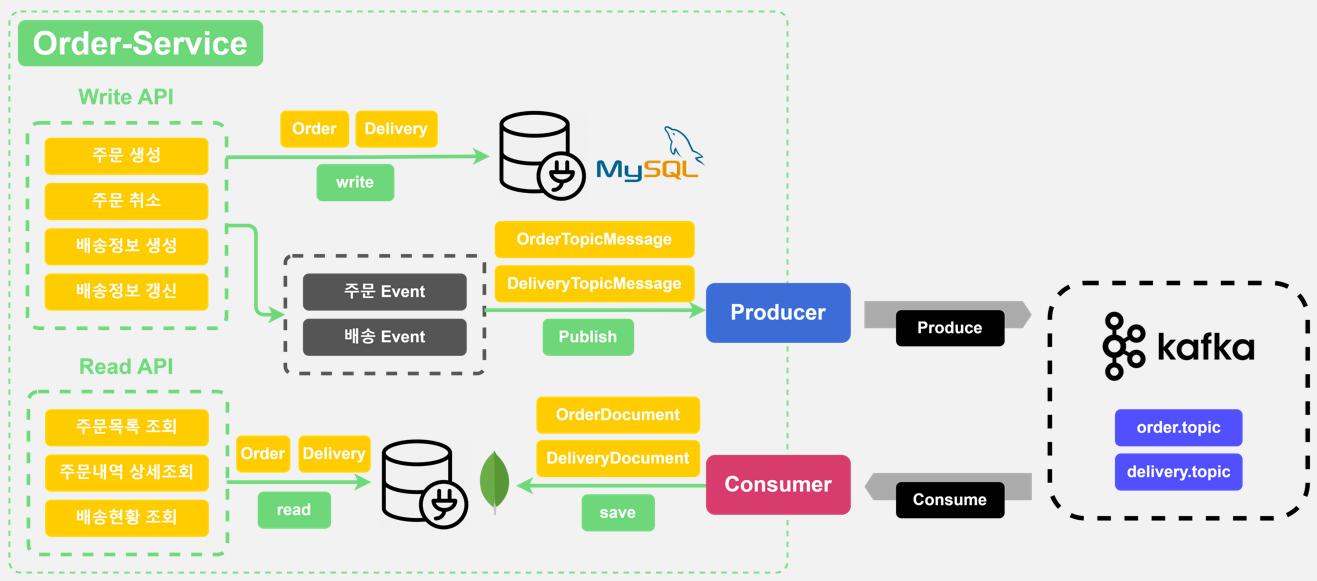
오더서비스에서도 위 멤버서비스와 동일한 메커니즘을 갖게 된다. Order, OrderItem, Delivery, DeliveryTracking 엔티티를 기존 DB 저장과 카프카 프로듀싱을 하게 되는데, 이 엔티티들을 카프카 토픽 메시지인 OrderTopicMessage, DeliveryTopicMessage로 담아서 처리한다. 이 토픽 메시지 데이터는 OrderEvent와 DeliveryEvent 이벤트를 통해 카프카로 발행되며, 발행된 토픽 메시지는 카프카에서 order.topic, delivery.topic 토픽 파티션에 저장되도록 처리하고 컨슈머가 해당 토픽의 레코드를 읽어온다. 그리고 이렇게 읽은 레코드를 OrderDocument, DeliveryDocument 객체로 변환하여 MongoDB로 저장한다. 그러면 이 애플리케이션에서도 데이터를 MongoDB를 통해 읽으면 된다.
Item Service
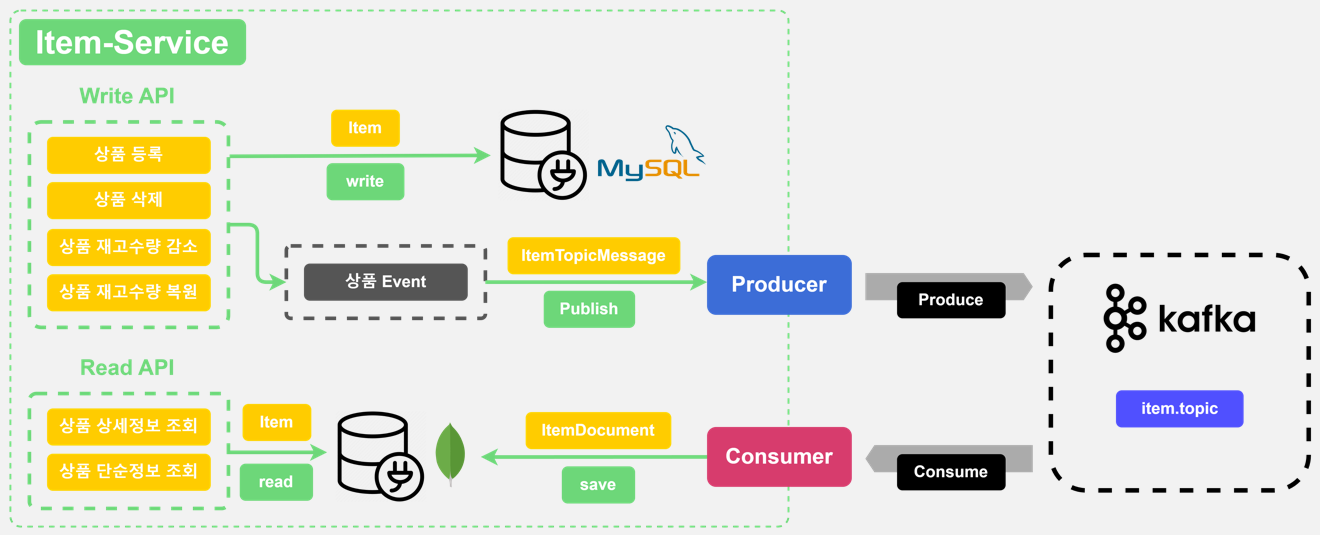
아이템서비스도 위와 동일한 메커니즘으로 구성된다.
마무리
지금까지 내가 정리해본 작은 규모의 카프카 아키텍처였다. 카프카 클라이언트의 설정들에 대해서는 이전 포스팅에서 다뤘으므로 더 언급하지 않는다. 비동기 처리를 위한 이벤트가 아니라, 비동기 통신이었다면 서비스간 통신을 대체하는 보다 복잡도가 높은 메커니즘에 도전해볼 수 있었겠지만, 지금으로서는 꽤 큰 도전을 완수했기에 만족스럽다. 그렇다고 여기서 멈추면 안되겠지. 시간을 두고 하나씩 도전해보면 된다.
