TL;DR
- 문제: IMDb 영화 리뷰 데이터셋으로 BERT를 파인튜닝하는 동안 train loss/accuracy, eval accuracy는 괜찮은데 eval loss만 불규칙한 패턴 확인.
- 가설 설정: loss_function 수식에 의해 민감하게 반응, 데이터셋 불균형, 적절하지 않은 학습 하이퍼파라미터.
- 액션: BERT의 loss function 확인, batch_size 8 → 64, train:test 1:1 → 4:1(stratified split).
- 결과: train/eval loss가 각각 0.1/0.18에서 안정적으로 수렴하고 eval accuracy 또한 94%대 유지.
0. Intro
최근에 ML을 다시 공부하면서 Keras 환경에서 IMDb 영화 리뷰 데이터셋으로 RNN 모델 학습시켜 보았습니다. 심화 학습 겸, Transformers 환경에서 BERT 모델로 IMBD 데이터셋 학습시켜 보면서 얻은 생각이나 인사이트를 정리하였습니다.
1. Setting: Base code
Base code는 블로그를 통해 확인할 수 있습니다. 해당 Base code로는 Accuracy를 확인할 수 없으며, 학습 도중 모니터링할 수 없게 되어있습니다. Accuracy 지표 확인 코드와 학습 모니터링을 위한 wandb 코드를 추가하였습니다.
- evaluate, wandb 모듈 설치
!pip install evaluate wandb- Accuracy 평가 함수 설정
import evaluate
import numpy as np
accuracy_metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""
모델 출력(prediction)에서 추론 결과를 얻고, 정답 label과 비교하여 accuracy를 계산합니다.
ref: https://github.com/huggingface/evaluate/tree/main/metrics/accuracy
"""
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return accuracy_metric.compute(predictions=predictions, references=labels)from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
eval_strategy='steps', # batch 스텝에 따른 eval 전략 사용
eval_steps=200, # 200번 스탭 마다 eval 실행
save_steps=200,
logging_steps=200, # 200번 스탭 마다 wandb에 logging 전달
load_best_model_at_end = True,
metric_for_best_model='accuracy', # 최종 모델 선택에 사용할 지표
report_to='wandb', # wandb로 report 하도록
run_name='bert-imdb' # wandb run 이름 설정
)- Trainer에 compute_metreics 적용 및 학습
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
compute_metrics=compute_metrics, # Accuracy 평가 함수를 적용합니다.
)
trainer.train()2. 학습 했더니 Eval Loss가 이상하다?
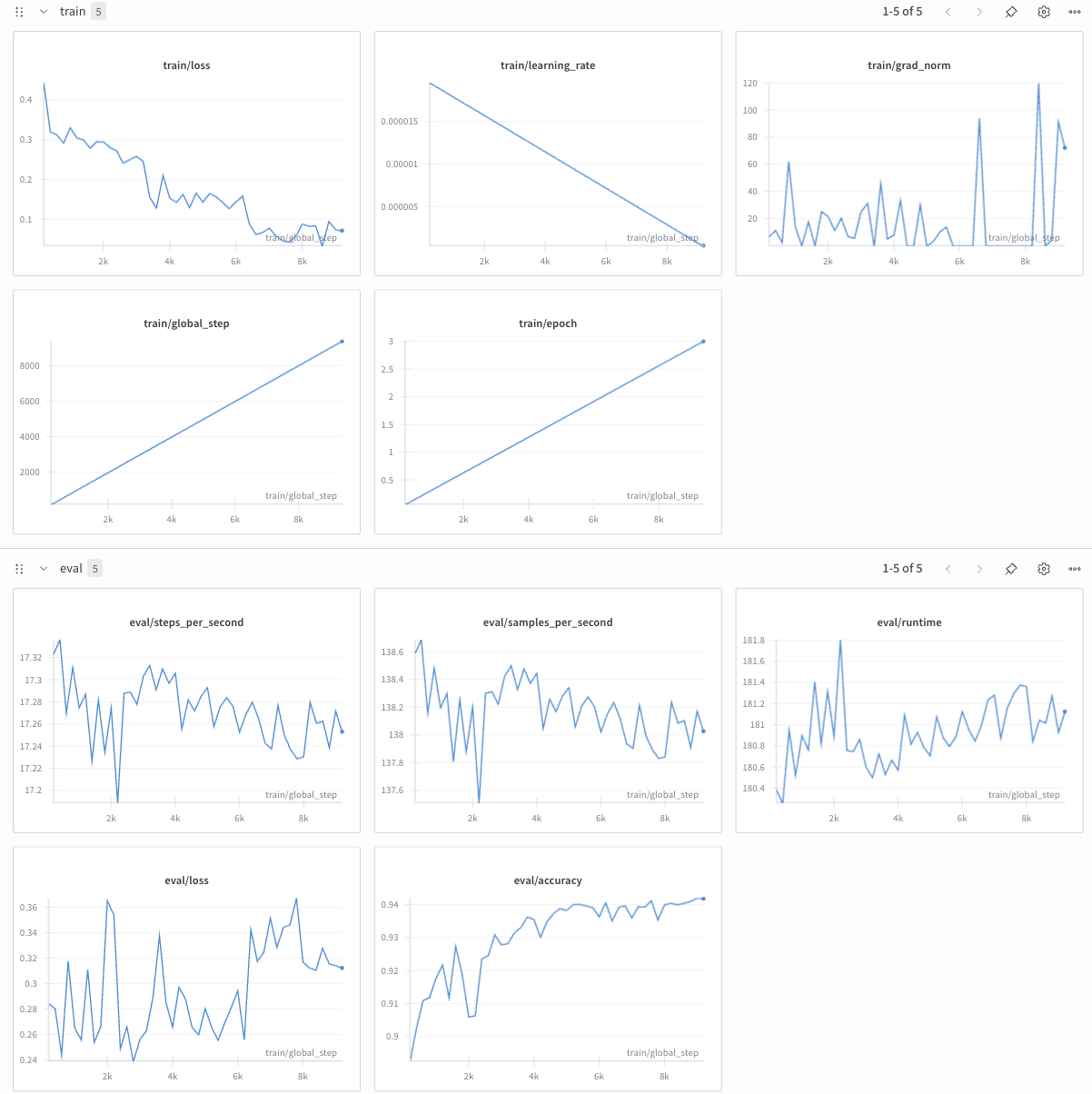
Wandb 접속해서 학습 결과를 모니터링 했더니 위와 같은 그래프를 확인할 수 있었습니다. train/loss는 잘 떨어지고 있고, eval/accuracy는 증가하다가 수렴하고 있네요. 근데 eval/accuracy와 다르게 eval/loss는 불규칙한 패턴을 보이고 있습니다. 왜 이런 패턴을 보이는 걸까요...?
이에 몇가지 가설을 세워봤습니다만...
가설 1: eval/accuracy는 잘 나온 것에 비해 eval/loss가 불규칙한 이유는, loss_func의 log 때문일까?
GPT에 해당 그래프 사진을 던져놓고 분석을 요구했더니, loss_func의 log 때문에 민감하게 반응한 것일 수 있다고 하네요. 그럼 BERT 모델에서 loss_func으로 어떤 걸 사용하는지 뜯어봐야겠습니다.
model.loss_function 확인해서 transformers 코드를 분석해보니, pytorch에서 제공하는 cross_entropy를 함수를 사용하는 것을 확인할 수 있었습니다.
# transformers.loss.loss_utils.py
import torch.nn as nn
def fixed_cross_entropy(
source: torch.Tensor,
target: torch.Tensor,
num_items_in_batch: Optional[torch.Tensor] = None,
ignore_index: int = -100,
**kwargs,
) -> torch.Tensor:
...
loss = nn.functional.cross_entropy(source, target, ignore_index=ignore_index, reduction=reduction)
...
return loss
def ForSequenceClassificationLoss(labels: torch.Tensor, pooled_logits: torch.Tensor, config, **kwargs) -> torch.Tensor:
...
if config.problem_type == "single_label_classification":
return fixed_cross_entropy(pooled_logits.view(-1, num_labels), labels.view(-1), **kwargs)
...pytorch의 CrossEntropy 문서를 확인하니 알고 있던 것처럼 log가 씌어진 형태라는 것을 확인할 수 있었습니다.
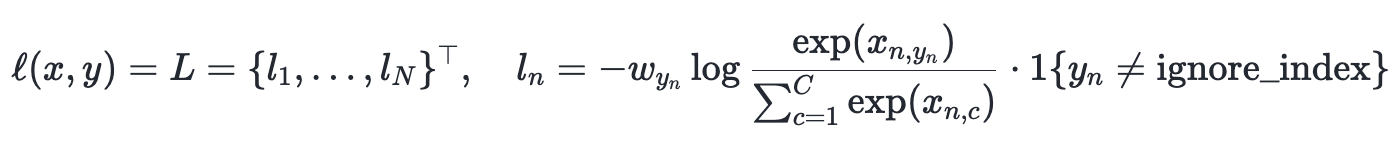
그렇다면 GPT가 말한 것처럼 CrossEntropy에 log가 있으니 작은 모델 출력값에도 loss는 크게 흔들릴 수 있을 듯합니다. 그에 비해 accuracy는 출력 차이 정도와 상관없이 큰 logit 값에 해당하는 class를 적용하기 때문에 loss와 accuracy가 차이가 나는 것일 수 있겠네요.
eval/accuracy에 비해 eval/loss가 불규칙한 이유는 어느 정도 납득이 가능해졌습니다. 하지만 아직 train/loss에 비해 eval/loss가 불규칙한 것은 해결하지 못했습니다.
가설 2: 데이터셋에 문제가 있어서 train/loss에 비해 eval/loss가 불규칙한 것일까?
train/test 데이터셋 불균형이 있기 때문에 이렇게 나타난 게 아닐까요? train/test 데이터셋 각각 25000개씩인데, 테스트 데이터셋 크기도 크고 테스트 데이터셋에 엣지 데이터 때문에 eval/loss만 불규칙하게 나타난 게 아닐까 싶네요.
데이터셋을 모두 열어서 확인할 수 없으니, text 길이나 label 분포만이라도 확인해봐야겠습니다.
>>> train_text_len = pd.Series([len(text) for text in dataset['train']['text']])
>>> test_text_len = pd.Series([len(text) for text in dataset['test']['text']])
>>> train_text_len.describe(), test_text_len.describe()
(count 25000.00000
mean 1325.06964
std 1003.13367
min 52.00000
25% 702.00000
50% 979.00000
75% 1614.00000
max 13704.00000
dtype: float64,
count 25000.00000
mean 1293.79240
std 975.90776
min 32.00000
25% 696.00000
50% 962.00000
75% 1572.00000
max 12988.00000
dtype: float64)pandas.Series.describe()로 확인해보니 text 길이에 대한 분포도 거의 비슷한 듯합니다.
>>> train_label_unique = np.unique(dataset['train']['label'], return_counts=True)
>>> test_label_unique = np.unique(dataset['test']['label'], return_counts=True)
>>> train_label_unique, test_label_unique
((array([0, 1]), array([12500, 12500])),
(array([0, 1]), array([12500, 12500])))라벨 분포도 train/test 둘 다 1:1로 같네요.
그래도 여전히 내용을 알 수 없기에 엣지 데이터가 있을 수 있다는 가능성은 버릴 수 없을 듯합니다. 만약 test에 엣지 데이터가 있다면, test 데이터셋 비율을 줄이고 train 데이터셋 크기를 늘려서, train 데이터셋에 더 다양한 데이터가 포함되도록 할 수 있을 듯하네요. train:test=4:1 비율로 다시 나눠서 다시 학습시켜 봐야겠습니다.
가설 3: 아니면 학습 하이퍼파라미터를 잘못 적용해서 train/loss에 비해 eval/loss가 불규칙한 것일까?
batch_size가 8로 작다보니, loss 최솟값을 잘못 찾고 학습이 진행되지 않는 게 아닐까요? 그렇다고 하기엔 train/loss를 보면 줄어들면서 모델 가중치가 잘 업데이트 되고 있는 듯합니다. 하지만 train/loss가 아직 수렴하지 않은 걸 보니, 학습이 덜 된 게 아닐까요? 학습이 덜 되었으니 아직 eval/loss에서 패턴이 보이지 않을 것일 수 있을 듯합니다. batch_size를 높여서 다시 학습시켜 봐야겠습니다.
3. 모델 재학습
가설2와 가설3에서의 조건을 따로 설정하고 학습하면 좋겠지만... 학습 하는 데에 3시간이 걸리기 때문에 아쉽지만 한꺼번에 설정하여 학습하도록 했습니다.
코드 설정1: train/test 데이터셋 비율 변경
데이터셋을 불러온 후, 아래의 코드를 추가합니다. datasets.concatenate_datasets() 이용해 train/test 데이터셋을 합친 후, train_test_split()을 통해 데이터셋을 train:test=4:1로 다시 나눴습니다. label 불균형이 생기지 않도록 stratify 옵션을 적용합니다.
from datasets import concatenate_datasets
merged_dataset = concatenate_datasets([dataset['train'], dataset['test']])
dataset = merged_dataset.train_test_split(
test_size=0.2,
seed=42,
shuffle=True,
stratify_by_column='label'
)코드 설정2: 학습 하이퍼파라미터 재설정
인터넷을 조금 찾아보니 보통 GPU 환경에서 batch_size를 32, 64, 128, 256까지 설정한다고 하네요. 하지만, Colab A100 환경에서 batch_size 128로 설정하니 GPU memory 부족 에러가 뜨네요. batch_size는 64가 한계인 듯합니다. TrainingArguments에서 batch_size를 64로 수정합니다.
logging_steps=1, eval_steps=20으로 설정하긴 했습니다만, 조급한 마음도 있고, train/loss에 다른 패턴이 보이지 않을까 싶어 설정했습니다. 패턴을 관찰하는 데에 큰 영향은 없을 듯합니다만, 좀 더 정확한 비교를 위해 그대로 뒀으면 하는 아쉬움이 있네요
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
learning_rate=2e-5,
per_device_train_batch_size=64, # train batch_size를 변경합니다.
per_device_eval_batch_size=64, # eval batch_size를 변경합니다.
...
logging_steps=1, # batch 스탭 마다 wandb log를 보내도록 합니다.
...
)모델 재학습 결과
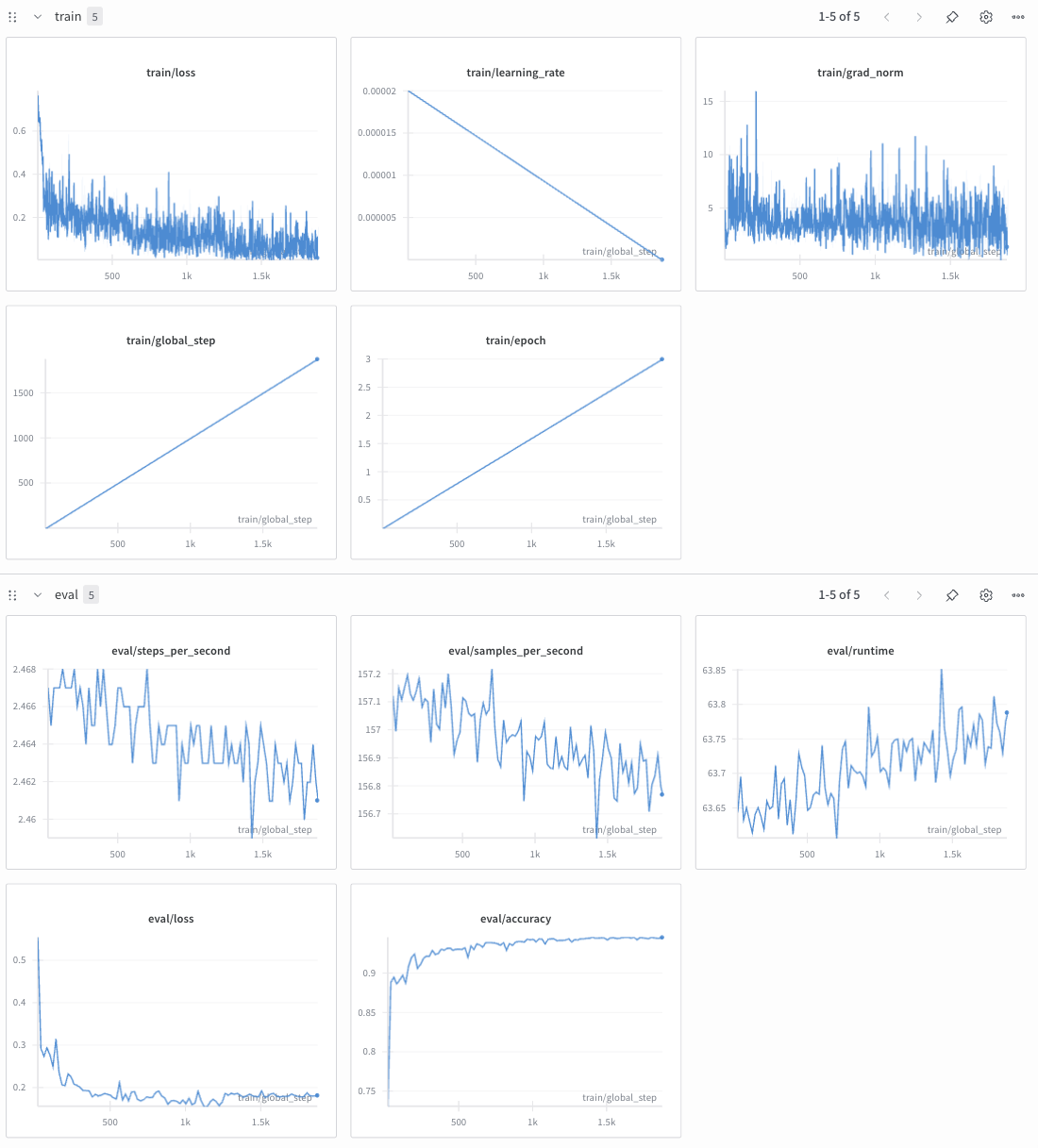
train/loss, eval/loss는 낮아지다 수렴하고, eval/accuracy 또한 상승하다가 수렴하는 것을 확인할 수 있습니다. (역시 logging_steps=1로 했더니 그래프가 산만하네요 ㅋㅋ)
train/eval loss가 모두 수렴하는 걸 보니 모델이 잘 학습되었을 확률이 클 듯합니다.
4. Review
이전에는 OpenAI 환경에서만 모델을 학습해보고, Transformers를 사용해보지 못해 스스로 아쉬운 점이 있었습니다. 처음으로 Transformers 환경에서 모델 학습을 진행해보면서, Transformers에 익숙해질 수 있었습니다.
코드를 뜯다보니, BERT에서 loss function으로 CrossEntropy를 쓰고 있다는 것을 알았고, 추가적으로 gpt-oss에서도 CrossEntropy을 사용하고 있는 것을 확인할 수 있었습니다. 조금이지만 LLM 모델을 옅볼 수 있었던 기회가 됐습니다.
단순히 Transformers 사용해보려고 했던 건데, 계속 파헤치다보니 꽤 많은 인사이트를 얻을 수 있었네요.
