TL;DR
- 기존 문제: IMDb BERT 학습에서 eval_loss가 불규칙하게 보임.
- 원인 재정리: 학습량 문제보다, 작은 batch_size(8)가 큰 grad_norm 분산을 야기.
- 재실험 1 (변수 분리): train:test=1:1 고정, batch_size 8→64만 변경 → eval_loss 안정, grad_norm 분산 축소.
- 재실험 2 (관측 보정): train:test=1:1, batch_size=8 유지, logging_steps=10, eval_steps=20로만 조정 → 초반 loss 감소가 제대로 관측되며 불규칙 패턴 소멸. 즉, 불규칙 원인은 너무 큰 eval_step으로 인한 지표 샘플링 오류.
- 리뷰: 작은 logging/eval steps로 많은 지표 샘플링하되, eval 과다 호출은 주의. grad_norm을 상시 모니터링(분산/소실/폭주 판단)하고, W&B smoothing으로 가독성 확보.
0. Intro
이전에 BERT 모델로 IMDb 영화 리뷰 데이터셋을 학습시켜보았습니다만, 평가 지표 중 eval_loss만 불규칙한 패턴을 보이는 문제가 있었습니다. batch_size와 train/test 비율을 변경해서 재학습시켰더니 eval_loss 패턴이 개선되었지만, 변수 두가지를 동시에 수정해서 테스트한 탓에 정확한 원인을 찾지 못했습니다. 찝찝한 마음에 정확한 원인을 찾아내고자 다시 학습시켜보았습니다.
1. 이전 실험에서의 가설 수정
부끄럽지만, 이전 학습에서는 조금 잘못된 가설 설정이 있었습니다.
가설3: "학습이 덜 되었으니 아직 eval/loss에서 패턴이 보이지 않을 것일 수 있을 듯합니다. batch_size를 높여서 다시 학습시켜 봐야겠습니다."
학습량이 문제였다면, epoch를 늘리거나, learning rate를 늘려야했을 겁니다. batch_size을 8→64로 늘렸다면, 학습량 보다는 가중치 업데이트 방향의 분산 정도가 줄어들었을 듯합니다. 가중치 업데이트 방향에 따라 1 step에서의 학습량이 달라졌을 것인데, 이 부분에서는 train/grad_norm 그래프를 봐야겠네요.
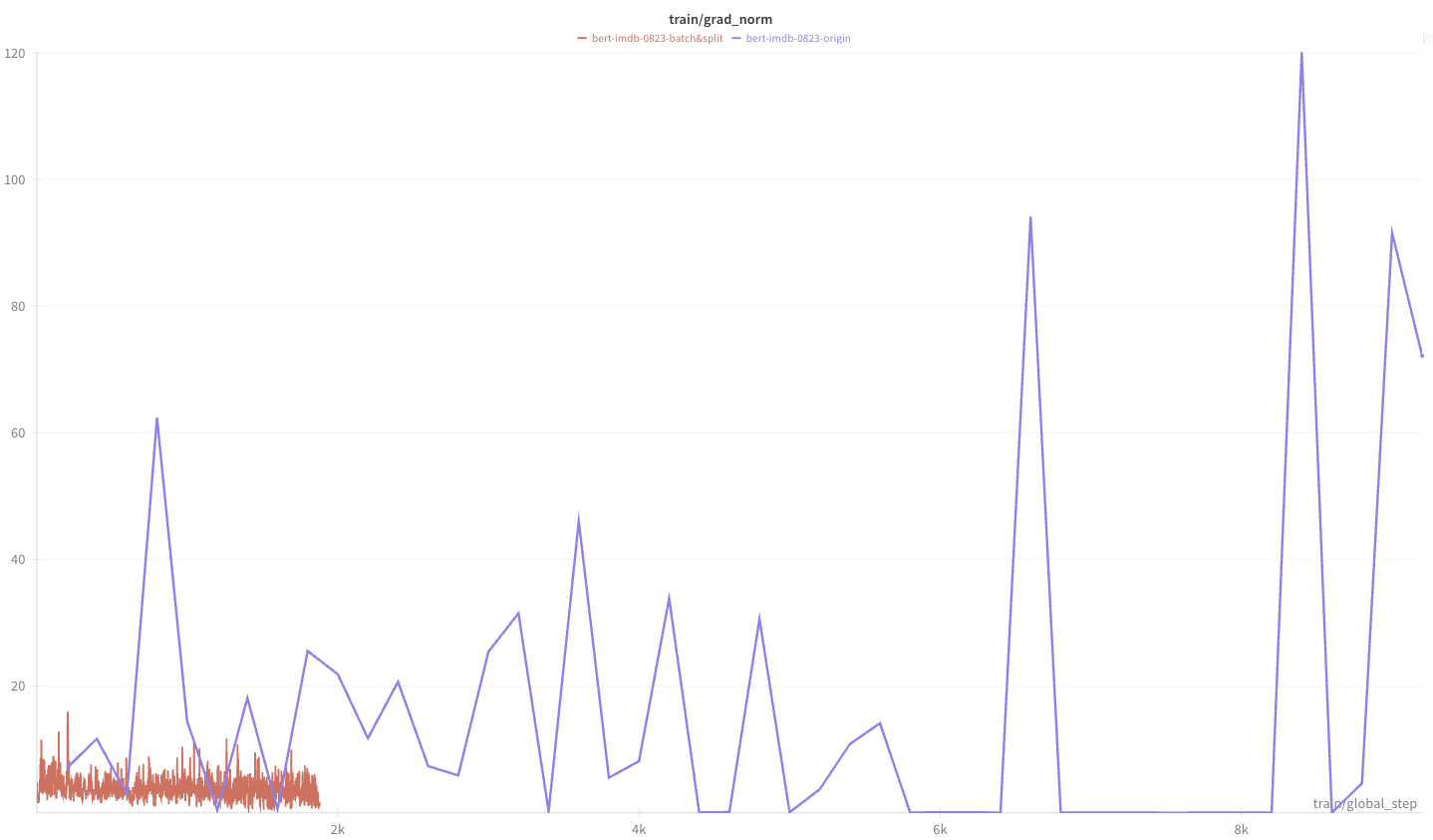
파란색 선은 eval_loss 불규칙 문제가 있었던 train/test=1:1, batch_size=8에서의 train/grad_norm 입니다. 빨간색 선은 train/test=4:1, batch_size=64로 변경했을 때의 train/grad_norm입니다.
step 수는 train/test 비율 차이 및 batch_size 차이 때문에 거의 5배 차이가 나는 것을 볼 수 있습니다. 그리고 가중치 업데이트 기울기의 크기(train/grad_norm)는, batch_size=8일 때 1도 안되는 작은 값에서 120 정도 까지 도달하면서 분산이 매우 큰 것을 볼 수 있습니다. 반면 batch_size=64일 때는 15까지 도달하면서 분산이 작고 가중치 업데이트 크기도 작은 것을 볼 수 있습니다.
가설3을 다시 내리자면... loss가 줄어들면서 가중치 업데이트 분산이 큰 것을 보니, 학습량이 부족하기 보다는 더 많은 데이터셋에 대해 일반화하기 어려운 방향으로 모델 가중치 업데이트가 이뤄지지 않았을까 싶네요. 또한 이상치 분포가 크게 다르지 않다면 train/test 데이터셋 비율 차이가 가중치 업데이트 분산에는 영향을 미칠 가능성은 적을 것 같습니다.
하지만, train/test 데이터셋 비율 차이가 학습량 차이를 만들 수는 있을 듯하네요. 역시 train/test 비율, batch_size 변수를 각각 변경해서 테스트하지 않는 이상 정확한 원인을 알기는 쉽지 않을 듯합니다.
2. batch_size만 변경하여 다시 학습
먼저 train/test=1:1로 기존 base 코드 그대로 유지하고, batch_size=8→64만 적용시켜 다시 학습시켜보았습니다. (logging_step은 1은 그래프가 너무 촘촘해서 10으로 설정하였습니다)
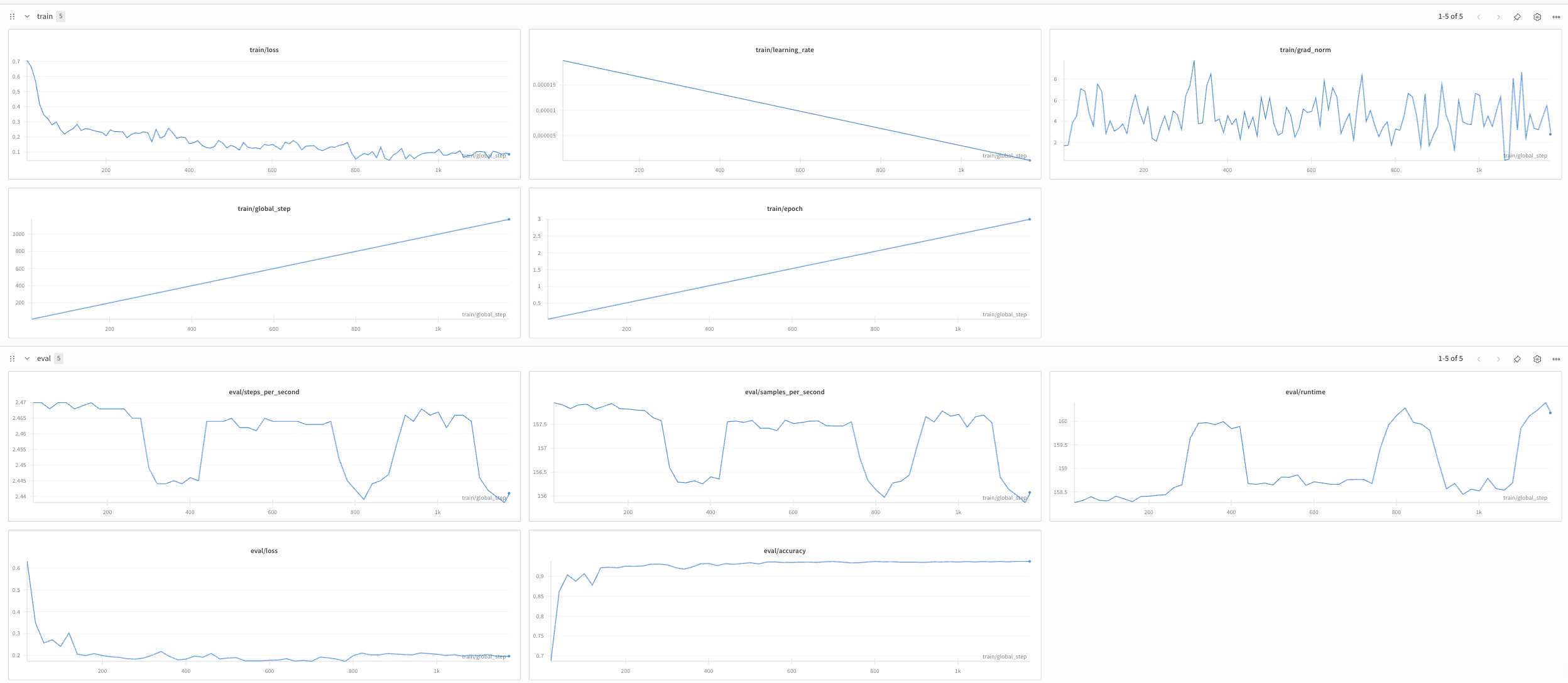
train/grad_norm은 0.28에서 9.74 까지 적용되었고, 이전 실험 보다는 가장 작은 분산을 보였습니다.
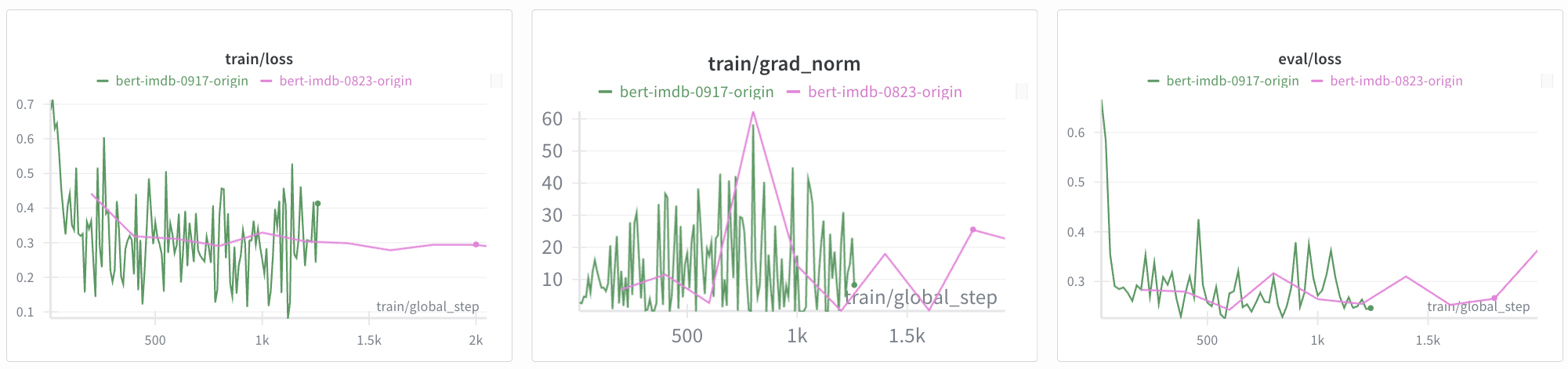
train/loss와 eval/loss는 떨어지다가 수렴하고, eval/accuracy는 상승하다가 수렴하는 것을 볼 수 있습니다.
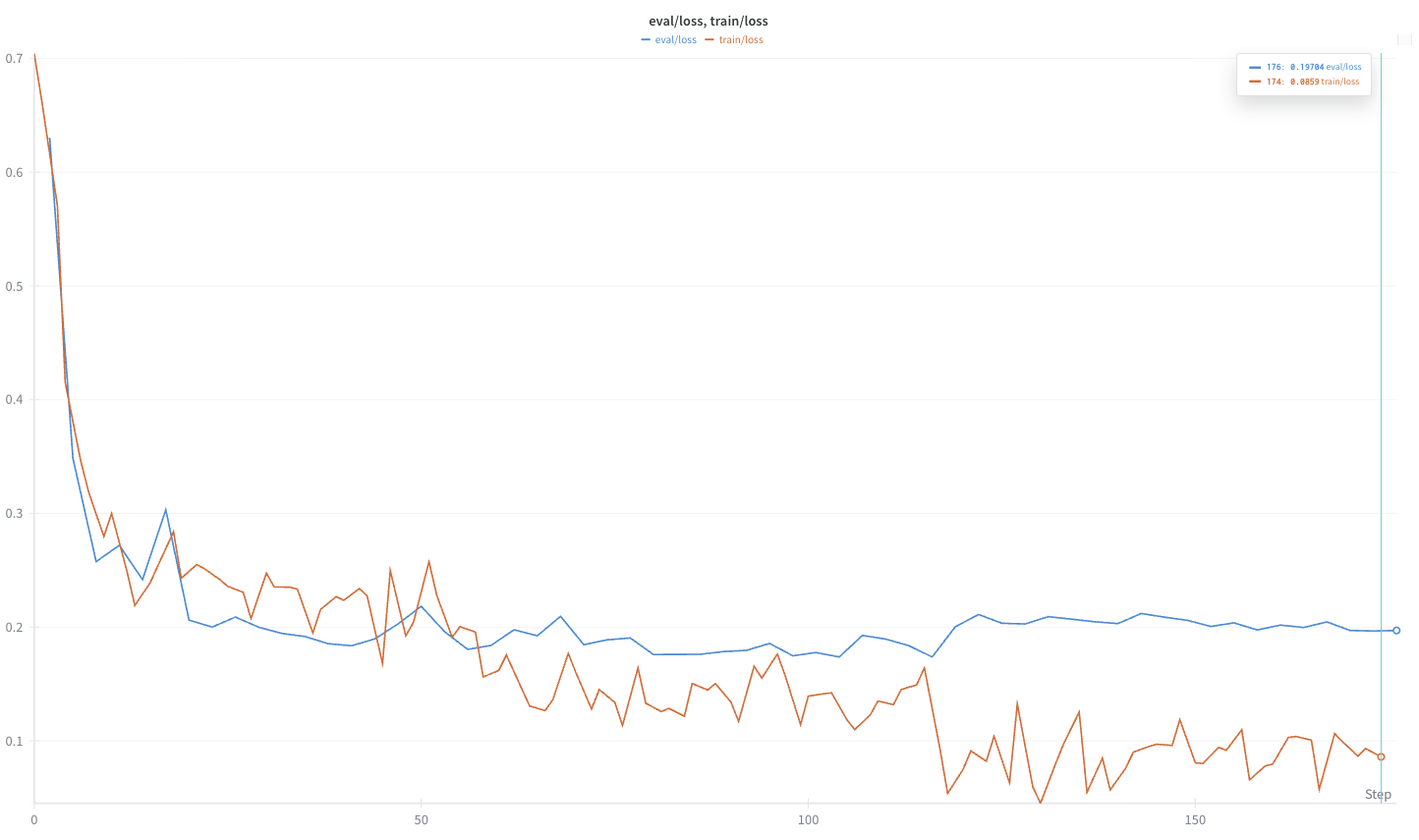
loss 그래프를 곂쳐서 다시 보게 되면, eval/loss는 수렴하고 있지만, train/loss는 계속 줄어드는 것으로 보아 과적합 과정에 있는 게 아닐까 싶습니다.
일단 eval/loss의 불균형 패턴은 없는 듯합니다. train/test 데이터셋 비율은 그대로 하고 batch_size만 변경했기 때문에, 가설3 설정한 것처럼 낮은 batch_size로 인한 가중치 업데이트 분산이 원인이라는 게 조금 더 확실해졌습니다.
하지만... 여기까지 테스트를 하고 보니, steps 20 내에서 train, eval loss 둘 다 급격하게 줄어드는 것을 보고 한 가지 놓치고 있었다는 게 생각이 들었습니다. 이전에는 logging_steps를 200으로 설정했었는데, 200 steps 전에 loss는 이미 줄어든 상태가 아니였을까 하는 생각이 들었습니다. 그렇다면 기존 base 코드에서 logging_steps=20, eval_steps=10으로만 조정하고 다시 테스트 해봐야겠습니다.
3. base 코드로 다시 학습...
다시 base 코드 그대로 train/test=1:1, batch_size=8로 설정하고, 아래처럼 logging_steps, eval_steps만 변경해서 학습시켜 보았습니다.
training_args = TrainingArguments(
output_dir='./results',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
eval_strategy='steps',
eval_steps=20,
save_steps=20,
logging_steps=10,
load_best_model_at_end = True,
metric_for_best_model='accuracy',
report_to='wandb',
run_name=WANDB_RUN_NAME
)(Colab에서의 GPU 사용량을 다 쓰고 T4로 학습시켰더니 12시간 런타임 제한시간 넘어가면서, 학습이 끊겼습니다. 그래도 200 steps 이상 진행되었으니, 학습 앞부분에서 loss 감소하는지 확인하기엔 문제 없겠네요.)

train,eval loss는 모두 줄어드면서 수렴하는 것을 볼 수 있습니다. eval/accuracy는 상승하면서 수렴합니다. train/grad_norm은 58까지 올라가면서 어느 정도 분산을 확인할 수 있습니다.
이전과 다르게 eval/loss에서 불규칙한 패턴은 보이지 않습니다. train/grad_norm은 맨 처음 base 코드 실행했을 때의 크기 150 보다는 크지 않는 듯합니다만, 학습 steps가 작아서 아직 그만큼의 높은 분산이 확인되지 않았을 듯합니다.
더 정확하게 확인하기 위해 이전 base 코드에서의 학습 그래프와 곂쳐서 비교해보도록 하겠습니다.
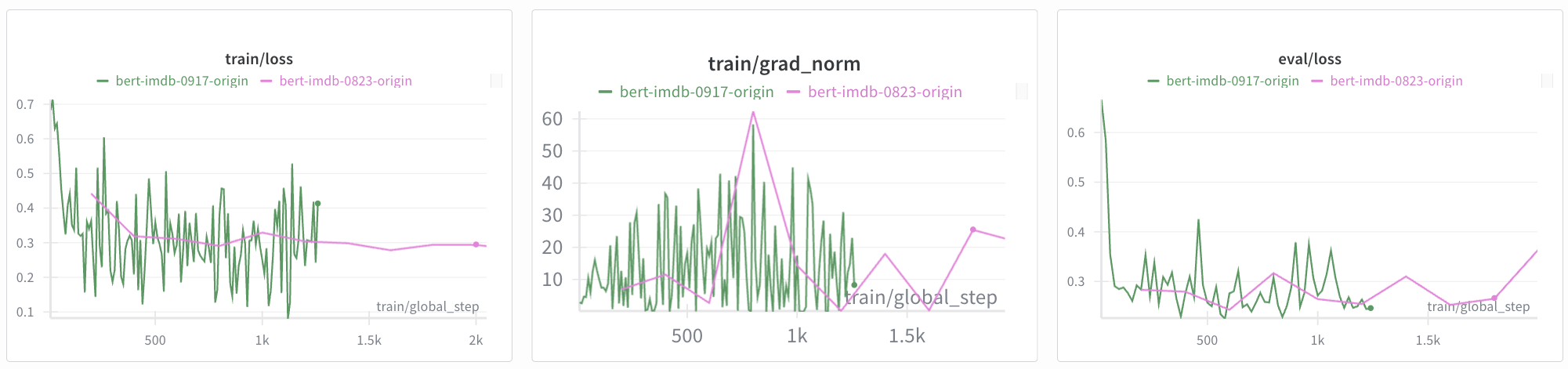
분홍색 선은 eval/loss 불규칙한 패턴 확인했을 때의 logging_steps=200, eval_steps=200으로 설정된 학습 그래프입니다. 빨간색 선은 logging_steps=20, eval_steps=10으로 설정한 학습 그래프입니다.
초기 가중치 설정이 달라서인지, 같은 steps에서 미묘한 차이들이 확인됩니다. train/grad_norm에서는 고점에서의 크기가 거의 같습니다. 대체적으로 빨간색 그래프는 분홍색 그래프를 따라가는 듯 합니다. 특히 불규칙 패턴이 관찰되었던 eval/loss에서는 분홍색 선 시작 전에 빨간색 선에서 이미 loss 감소가 크게 일어나는 것을 볼 수 있습니다.
logging_steps, eval_steps가 너무 높아서, 특정 패턴을 못 잡게 되고 eval/loss 그래프가 불규칙하게 보였던 것이 확실해졌네요!
4. Review
다시 모델을 학습해보면서, batch_size가 학습에 어떤 영향을 주는 지 더 자세하게 살펴볼 수 있었습니다. 그래프를 조작해보면서 wandb 환경에도 조금 더 익숙해질 수 있었습니다. 이전엔 grad_norm을 그냥 지나쳤었는데, 기울기(가중치 업데이트 방향) 분산 크기나 소실(vanishing), 폭주(exploding) 여부를 판단하는 데 좋은 참고가 되는 듯합니다.
무엇보다... 학습 그래프에서 자세한 결과를 확인하기 위해서 logging_steps, eval_steps는 작은 게 좋은 듯합니다. 하지만 eval_steps는 너무 작으면 eval 횟수가 늘어나면서 총 학습 시간이 늘어나니 너무 작아서는 안 될 듯합니다. wandb chart 내에서 logging_steps/eval_steps를 바꾸거나 sampling 기능은 없는 듯하지만, line chart에서 smoothing 설정 통해서 너무 빽빽한 선 그래프도 어느 정도 펼쳐서 볼 수 있어서 좋네요.
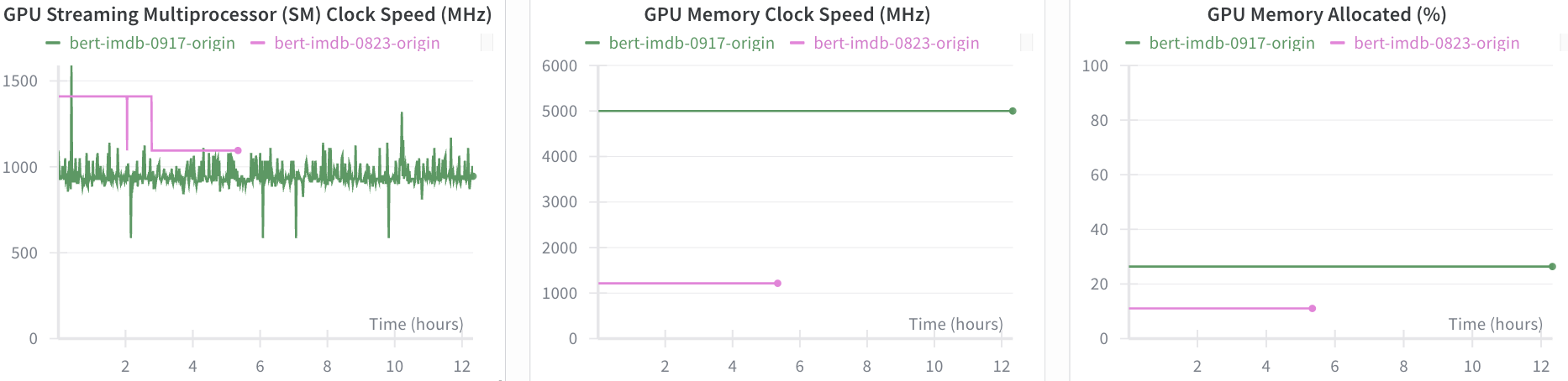
같은 Colab GPU지만, T4와 A100 환경에서 eval/steps_per_second는 각각 4.553, 17.233이었습니다. 같은 batch_size지만, 약 3.78배 더 빠르네요! GPU SM Clock Speed 차이 때문에 이렇게 나온 게 아닐까 싶습니다. (train에서 가중치 업데이트 과정이 있으니 train/steps_per_second도 같이 보면 좋을 듯합니다만, T4에서는 학습이 끊기는 바람에 해당 지표가 안 나온 듯하네요 ㅠ)