최근 나타나는 새로운 기술 'Prompt Engineering'을 따라 'LMOps'도 주목받기 시작했습니다. 'LangChain'이란 무엇일까요? 그리고 LangChain을 사용하면 어떤 기능을 할 수 있을까요? 이러한 궁금증을 해결해 줄 글들을 시리즈로 준비했습니다.
LLM & Prompt
- 간단하게 LLM에 대해서 말하자면, prompt 다음에 나올 다음 단어를 유추하는 모델입니다. 1,2,3 다음에 나올 숫자를 4로 예측하는 것과 같습니다. ChatGPT의 경우에는 지시문에 대해서 강화 학습이 더 이루어져서, 사용자 질문에 대해 답을 하는 것처럼 보이게 됩니다.
- Prompt의 구성 요소는 지시, 문맥, 입력 데이터, 출력 지시자로 분류할 수 있습니다. 모든 요소가 다 포함되어야 하는 것은 아니며, 여러 개 있어도 상관없습니다.
- 지시(Instruction)
- 모델에게 특정 작업이나 지시를 제공합니다.
- 예시: "다음 문장을 번역해주세요." - 문맥(Context)
- 응답을 더 효과적이게 만들기 위해 제공되는 배경 정보나 추가적인 문맥을 의미합니다.
- 예시: "이 문장은 18세기 중반의 영국에서 쓰여진 것입니다." - 입력 데이터(Input Data)
- 모델에게 응답을 요청하는 실제 질문이나 데이터입니다.
- 예시: "The sun never sets on the British Empire." - 출력 지시자(Output Indicator)
- 원하는 출력의 형식이나 특징에 대한 지시를 제공합니다.
- 예시: "영-한 번역으로 제공해주세요."
- 지시(Instruction)
- 여기에서 중요한 것은 context나 input_data에 이전 대화 내용을 넣거나 문서 내용을 넣을 수 있다는 것입니다. 또한, output_indicator 통해서 응답을 json, csv 형식으로 받을 수 있으며, URL 형식으로 받아 LLM 모델이 API를 호출하는 것도 가능합니다.
- 정리하자면, Prompt에 모든 종류의 텍스트를 넣을 수 있고, 원하는 방식으로 응답을 받을 수 있다는 것입니다.
LangChain 소개
LangChain은 큰 언어 모델(LLM)을 바탕으로 어플리케이션을 개발하기 위한 프레임워크입니다. 이것을 'LLM Orchestration'이라고도 합니다. LLM은 다양한 텍스트를 이해하는 능력이 뛰어나고, 'Chain'은 여러 서드파티 애플리케이션을 연결하는 인터페이스를 의미합니다. 이 글은 LangChain 공식 문서의 내용을 한글로 정리한 것입니다.
Document QA
- LLM은 Excel, CSV, HTML, JSON, Markdown, PDF, 개발 코드, SQL 등 여러 텍스트를 입력으로 활용할 수 있습니다. 그렇게 입력된 자료를 기반으로 QA 기능을 제공합니다.
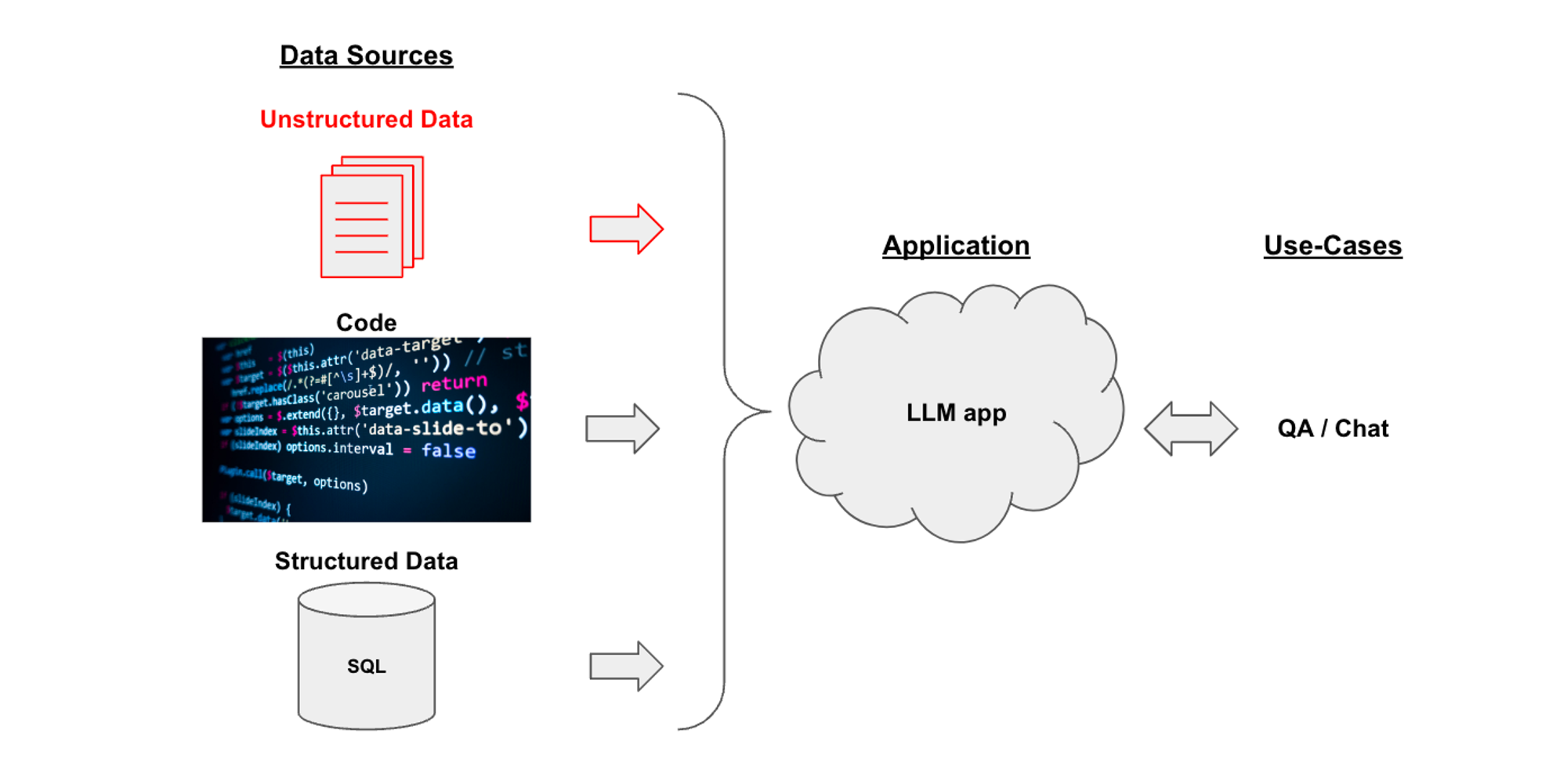
Data Loaders
- LangChain에서는 다양한 형식의 텍스트를 처리할 수 있습니다. 여러 소스의 데이터를 가져오기 위해 LangChain은 다양한 Retriever를 제공하고 있습니다. Retriever 중에는 data loader도 포함되어 있는데, 개인적으로 흥미로운 data loader는 다음과 같습니다:
ArxivLoader, AzureBlobStorageContainerLoader, DataFrameLoader, DatadogLogsLoader, DirectoryLoader, DiscordChatLoader, FigmaFileLoader, GitLoader, GoogleApiYoutubeLoader, YoutubeAudioLoader, PsychicLoader, SeleniumURLLoader, WikipediaLoader, PythonLoader, HuggingFaceDatasetLoader, ChatGPTLoader, BigQueryLoader, GMailLoader, SlackChatLoader, UnstructuredImageLoader, NotionDirectoryLoader, WeatherDataLoader, ...
QA Pipeline
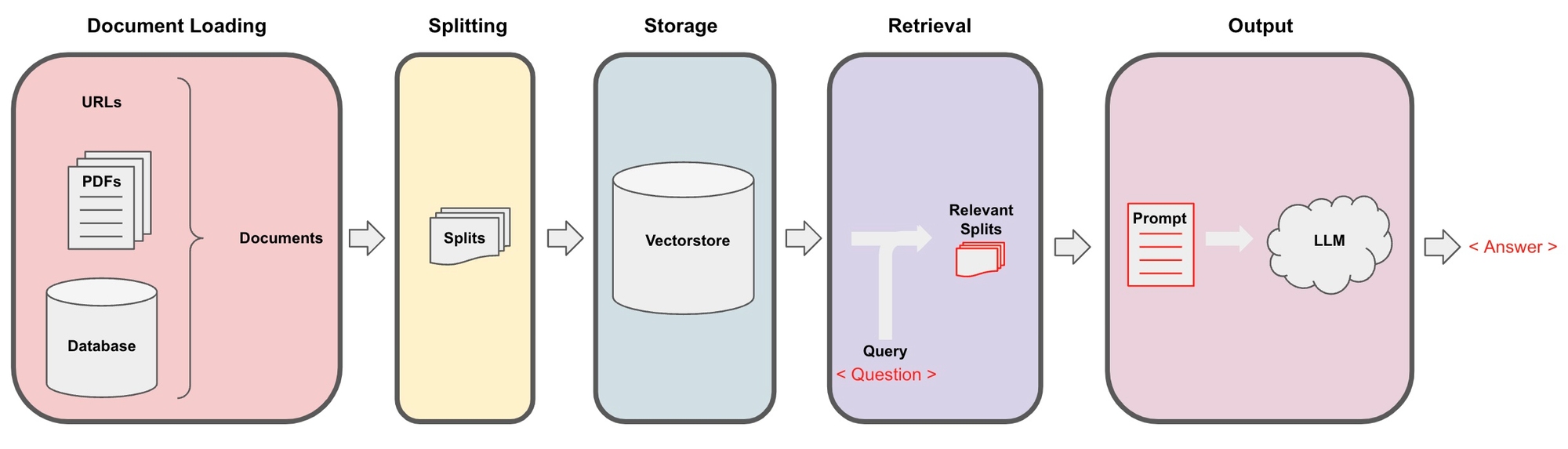
1. 로딩: 먼저 데이터를 로드해야 합니다. 비구조화 데이터는 다양한 소스에서 로드할 수 있습니다.
2. 분할: 텍스트 분할기는 지정된 크기의 분할로 문서를 나눕니다.
3. 저장: 저장소(예: vector store)는 주로 분할된 문서를 저장하는데, 문서를 Embedding해서 저장할 수 있습니다.
- Embedding: 원래의 데이터를 저차원의 연속 vector 공간으로 표현하는 것을 의미합니다. 주로 텍스트, 이미지, 사운드 등의 복잡한 데이터 타입을 고정 길이의 vector로 변환하기 위해 사용됩니다. 임베딩은 데이터의 복잡한 구조와 관계를 보존하면서 정보를 압축하는 방법을 제공합니다.
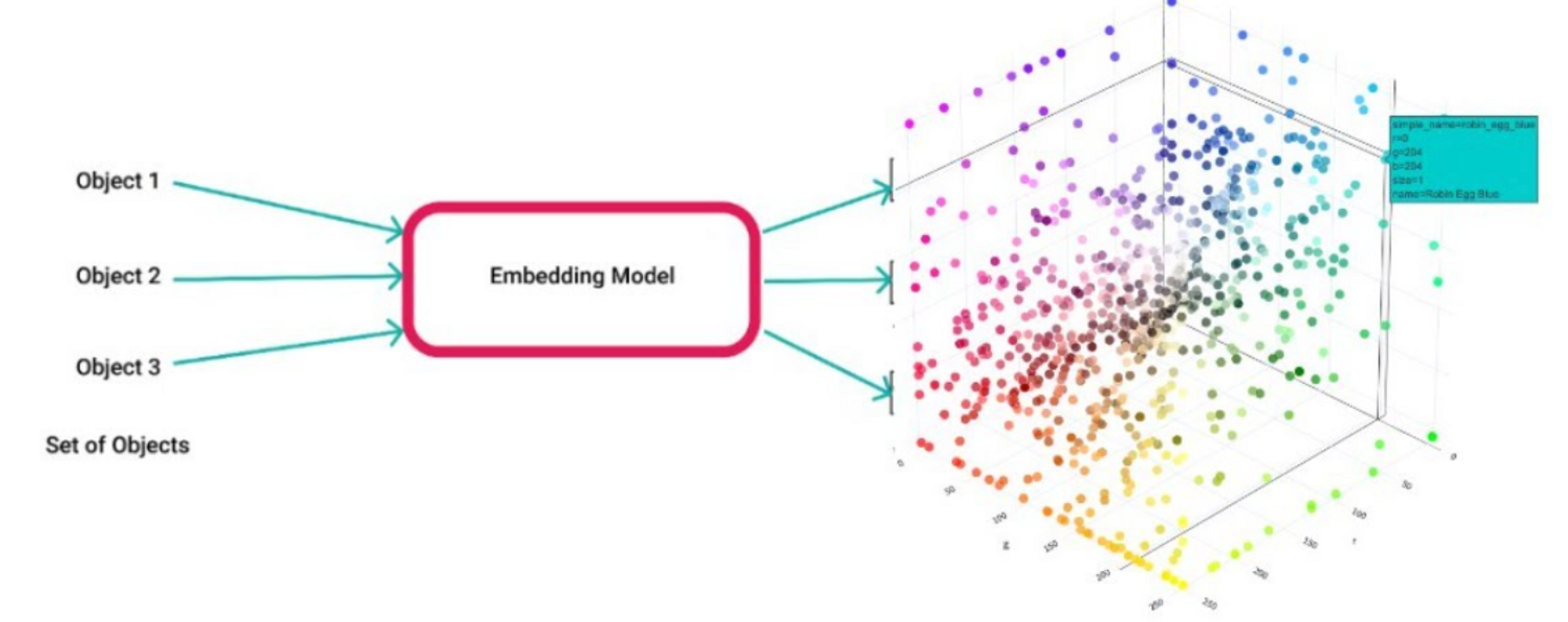
-
검색: 앱은 저장소에서 분할된 문서를 검색합니다. Embedding된 vector가 있을 경우, vector 정보와 함께 검색합니다.
- 알고리즘: 쿼리 임베딩 → 분할 문서와 vector 거리값 계산하여 유사도 측정 → 쿼리 벡터와 가까운 거리값을 갖는 분할 문서 return
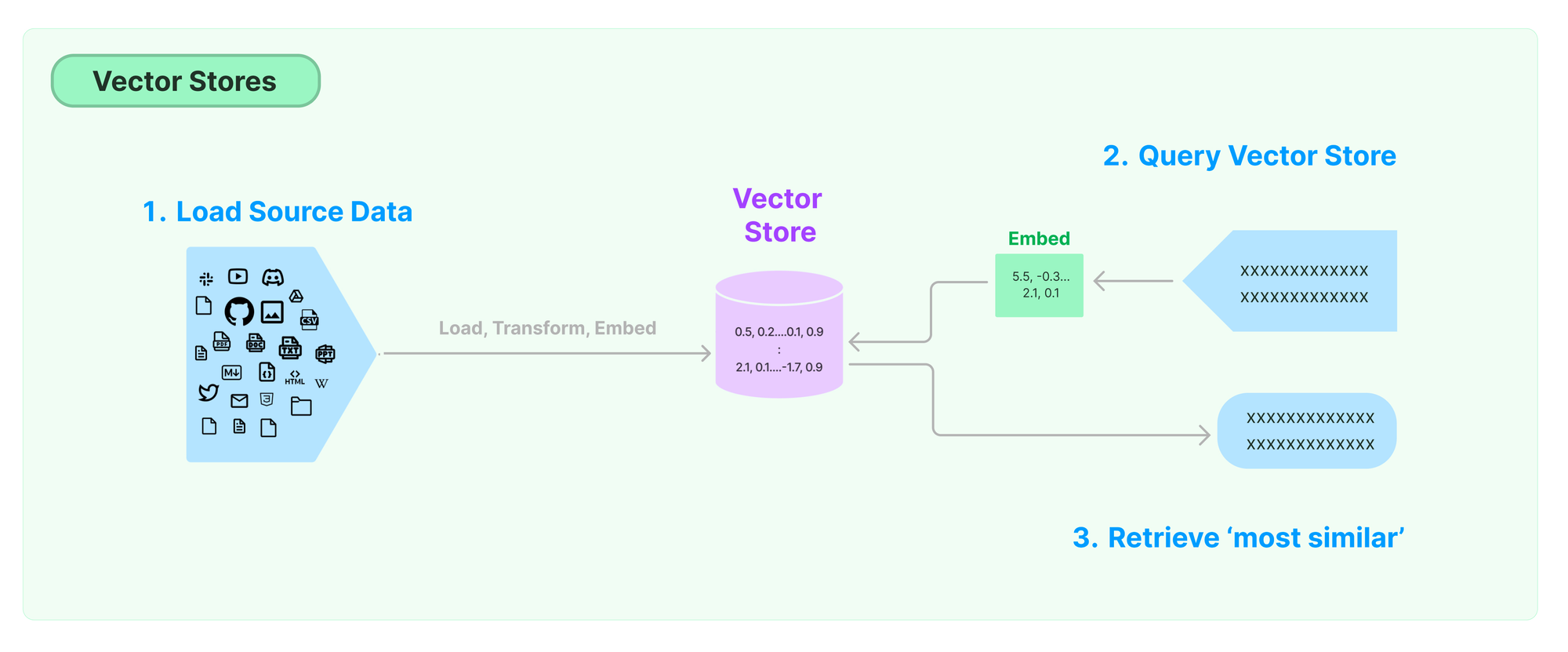
- 알고리즘: 쿼리 임베딩 → 분할 문서와 vector 거리값 계산하여 유사도 측정 → 쿼리 벡터와 가까운 거리값을 갖는 분할 문서 return
-
생성: LLM은 질문 + 검색된 데이터를 포함한 프롬프트를 사용하여 답변을 생성합니다.
- 실제 프롬프트 템플릿:
"""Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.{context}Question: {question}Helpful Answer:"""- context = 검색된 데이터
- question = 질문 query
- 실제 프롬프트 템플릿:
-
대화 (확장): QA 체인에 메모리를 추가하여 다중 턴 대화를 진행합니다.
- 예를 들어, chain 중 qa_chain의 'refine'타입은 다음과 같이 동작합니다. 이와 같은 방식은 퀄리티 있는 응답을 얻을 수 있지만, 그만큼 응답을 얻는 데에 많은 시간이 소요되며, 토큰 또한 많이 사용하게 됩니다.
1. 쿼리와 함께 문서 하나를 context에 넣고 응답을 얻습니다.
2. 그리고 쿼리와 함께 다음 문서를 context로 넣되, 중간 응답(Intermediate answer)로 이전 응답을 함께 넣습니다.
3. 중간 응답은 다음 문서와 쿼리를 참고하여 정제(Refine)됩니다.
4. 이와 같은 방식을 문서 수 만큼 반복합니다.
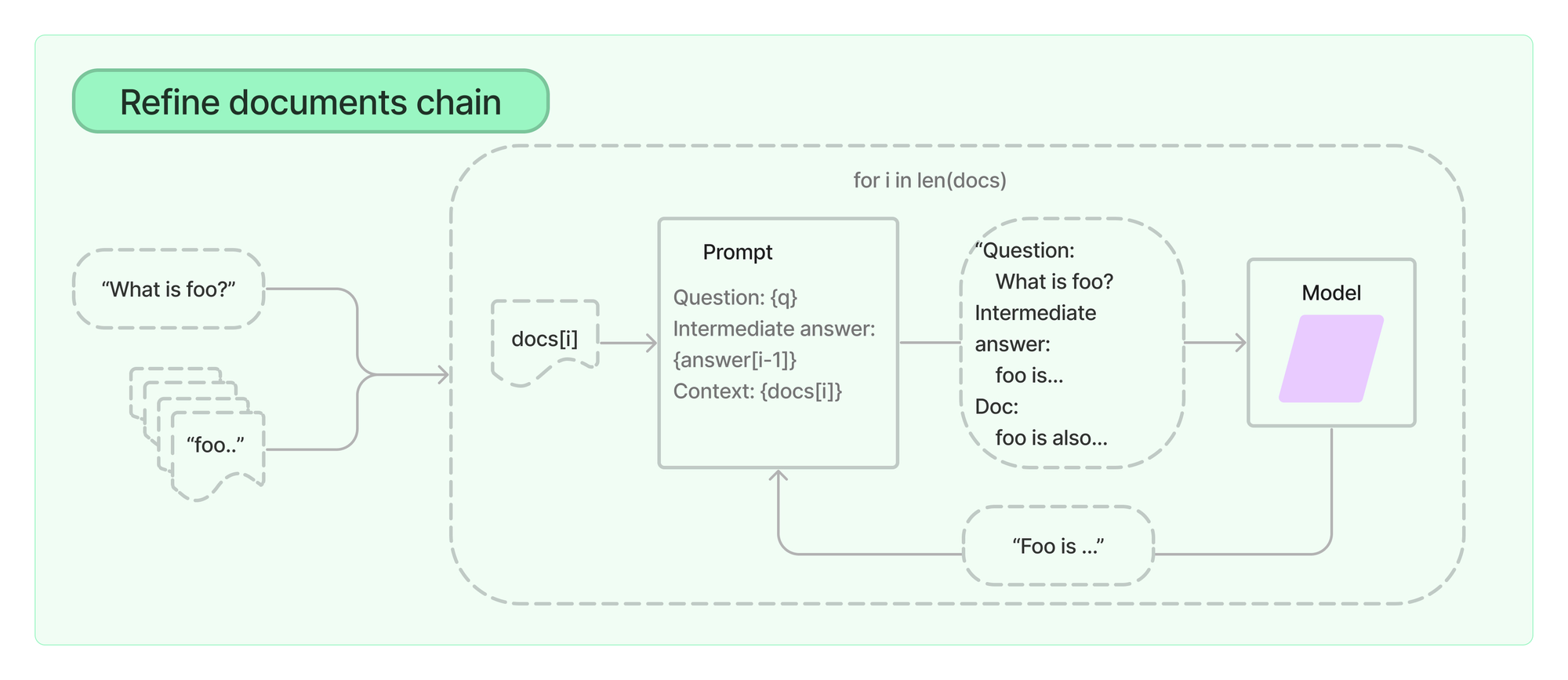
- 예를 들어, chain 중 qa_chain의 'refine'타입은 다음과 같이 동작합니다. 이와 같은 방식은 퀄리티 있는 응답을 얻을 수 있지만, 그만큼 응답을 얻는 데에 많은 시간이 소요되며, 토큰 또한 많이 사용하게 됩니다.
Sample Code
- 외부 데이터 가져오기
from langchain.document_loaders.pdf import PyPDFLoader
pdf_url = '/some/path/of/pdf_file.pdf'
loader = PyPDFLoader(pdf_url)
data = loader.load()- 데이터 분리
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 800, chunk_overlap = 100)
all_splits = text_splitter.split_documents(data)- 벡터 스토어 저장
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())- 쿼리 및 데이터 검색
question = "apple에 대해서 설명해줘"
docs = vectorstore.similarity_search(question)
docs
# [Document(
# page_content='there is something red, \n...',
# metadata={'page': 7, 'source': '/some/path/of/pdf_file.pdf'}
# ), ... ]- 쿼리 응답
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
response = qa_chain({"query": question})