0. Intro
이전 시간에 Spark에 대해서 알아보았고, Spark의 데이터 구조로 RDD, Dataframe, Dataset이 있다는 것을 배웠다. 각각은 어떤 형태로 되어 있으며 어떻게 조작하는 것일까?
1. RDD란?
-
RDD의 의미 Resillient Distributed Data를 해석하자면 다음과 같다.
- Resillient: RAM 내부에서 손실이 일어나게 되면, 파티션을 재연산하여 복구할 수 있다.
- Distributed: 데이터가 분산되어 저장된다.
- Data: 정보
-
Read Only로 불변의 특성을 갖는다. 연산 하면서 수많은 RDD가 생성되고, 생성되는 순서가 Lineage라고 한다.
-
RDD Lineage는 DAG(Directed Acyclic Graph, 노드 간의 순환이 없고 일정한 방향성을 갖는다) 형태를 가진다. 그렇기에 노드 간에 순서와 의존성이 생긴다.
-
Fault-tolerant: 작업 중 장애나 고장이 발생해도 예비 부품이나 절차가 즉시 그 역할을 대체 수행함으로써 서비스의 중단이 없게 하는 특성이다. RDD는 DAG형태로 메모리 정보가 손실될 경우, 그래프를 복기하여 다시 계산하고 자동으로 복구하는 Fault-tolerant 특성을 갖는다.
-
Lazy Evaluation(느긋한 연산): 이는 즉시 실행하지 않는 것을 의미한다. Action(수행) 연산자를 만나기 전까지 Transformation(변환) 연산자가 아무리 쌓여도 처리하지 않습니다. 바로 action을 취하지 않고, transformation 끼리의 연계를 파악해 실행 계획의 최적화가 가능진다.
-
Lazy Evaluation 특징은 MapReduce와 대조적인 것으로, Spark는 최적화된 실행 계획 덕분에, MapReduce를 사용하는 것보다 클러스터에 걸리는 부하가 적다. 간단한 operation들에 대한 성능적 이슈를 고려하지 않아도 된다는 장점을 가지고 있다.
-
Transformation 연산자는 새로운 RDD를 생성하는 동작이다. 즉, RDD를 반환한다. Transformation 연산자 종류로는 다음과 같다.
이름 용도 map() RDD 각 요소에 함수를 적용하고 결과 RDD를 반환한다. (ex. rdd.map(x: x+2)) filter() 조건에 통과한 값만 반환한다. distinct() RDD의 중복된 값을 제거하고 고유값만을 반환한다. union() 두 RDD 데이터를 병합한다. intersection() 두 RDD의 공통된 값만을 반환한다. -
Action 연산자는 기록된 모든 작업을 실제로 수행하는 연산자입니다. 연산자 종류는 다음과 같다.
이름 용도 collect() RDD의 모든 데이터를 반환한다. count() RDD 값 개수를 반환한다. top(n) 상위 값 n개를 반환한다. takeOrdered(n)(ordering) ordering 기준으로 값 n개를 반환한다. reduce(func) RDD의 값들을 모두 병렬로 연산하여 한 개의 값으로 병합한다. persist() 결과를 유지시켜 RDD를 재사용할 수 있다. -
사용 케이스에 따라 cache, persist, checkpointing을 이용한 RDD 재사용을 통해 퍼포먼스를 향상시킬 수도 있다. 이는 읽고 쓰는 비용이 높아지고, 메모리 공간을 사용함으로써 메모리 공간 관리가 필요해진다는 단점이 존재한다.
-
LRU Caching: Spark의 executor가 메모리 부족을 겪을 때, 뺄 파티션을 결정하기 위해 LRU(Least Recently Used) caching 방식을 사용하여 사용한 지 가장 오래된 데이터를 뺀다.
2. Dataframe이란?
- Dataframe은 Spark v1.3에 도입된 데이터 구조로, RDB의 Table이나 Pandas의 Dataframe과 같은, 행과 열로 구성된 데이터 구조다.
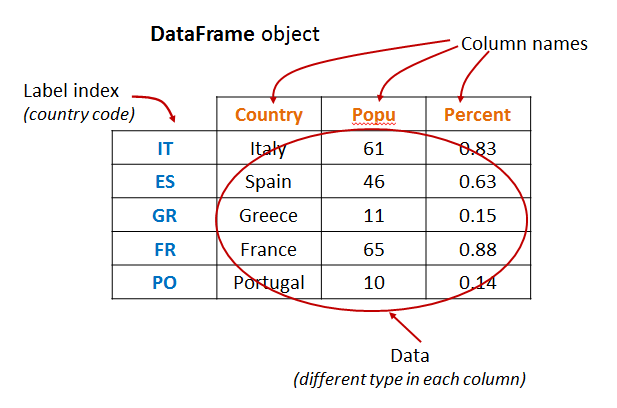
- 등장배경: RDD의 성능 이슈
- 스키마가 없고, 구조화 데이터와 비구조화 데이터를 함께 저장하여 효율성이 저하된다.
- 메모리 공간 관리가 안 될 경우, 제대로 동작이 되지 않는다.
- I/O 직렬화(Serialization, JAVA에서 바이트코드로 패키징하는 작업)와 Garbage Collection(자동 메모리 해제 및 공간 확보)을 사용하기 때문에 메모리 오버헤드를 증가시킨다.
- Dataframe의 특징
- 정형 데이터 구조를 가지고 있어, SparkSQL을 이용한 SQL 쿼리를 통해 쉽게 데이터를 다룰 수 있다. (structured vs unstructured data)
- JVM의 off-heap 메모리 영역(on-heap의 반대 개념으로, GC가 설정되어 있지 않아 어플리케이션에서의 메모리 관리가 필요하다)을 사용하기 때문에 GC(Garbage Collection) 및 직렬화 오버헤드가 감소된다.
* Spark 2.0 이후로 DataFrame API는 Datasets API와 통합되게 된다.
3. Dataset이란?
udemy 강의에서는 dataset 데이터 구조를 깊게 알려주지 않는다...
- dataframe보다 포괄적인 구조이며, JVM 객체의 직렬화(encoder가 그 역할을 한다)와 관련하여 Python보다는 Scala와 Java에 최적화되어 사용할 수 있다고 한다.
- 앞서 설명한 것처럼, DataFrame API와 통합되었다.
참고:
