
이번에는 python crawling의 기초인 urllib.reaquest를 이용해 파일을 다운받고 정보를 저장하는 것을 해보겠습니다.

일단 urllib.request를 사용하기 위해 import를 하고 as를 통해 req로 대체시킵니다.

그리고 다운받을 파일을 저장시킵니다. 저는 naver에서 고양이 사진의 주소를 가져왔으며, html파일인 구글홈페이지 url를 가져왔습니다.

그런다음 다운받을 경로와 파일이름을 설정합니다. 저는 해당 폴더내의 test.jpg와 index.html로 설정하였습니다.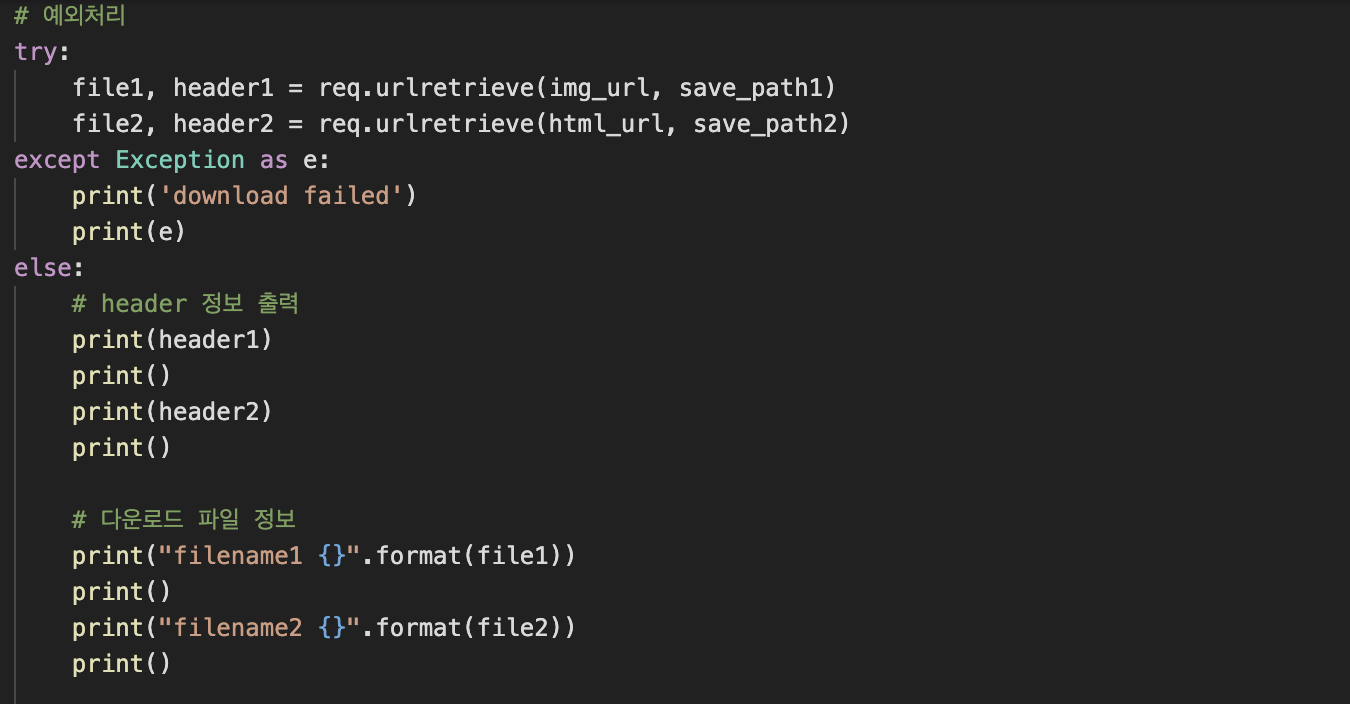
그리고 예외처리를 통해 코드를 구현합니다.
첫번째로, 파일이름(file1,file2)과 헤더정보(header1,header2)를 저장시킵니다.
-> import한 urllib.request내의 urlretrieve를 통해 저장시킵니다.
-> urlretrieve를 통해 파일저장과 파일이름, 헤더정보를 알 수 있습니다.
-> urlretrieve는 uriretrieve(파일 url(위에서 가져온 파일주소), 다운받을경로)형식으로 사용하면 됩니다.
두번째로, 오류발생을 대비하여 except를 구현합니다.
세번째로, 문제없이 코드가 진행되면 else문을 통해 header정보와 file이름을 출력합니다.

백엔드 개발자