이 글은 김영근 교수님의 컴퓨터 구조 강의를 듣고 정리한 내용입니다.
다양한 명령어의 처리 과정
앞서 명령어를 처리할때, 1개의 명령어씩 처리하는 과정에 대해서 다뤘는데 이번 글에서는 다수의 명령어를 동시에 실행하여 보다 효율적으로 연산을 처리하는 Pipeline 구조에 대해서 다뤄볼 것이다.
1️⃣ Sequential vs Pipelining
기존의 Sequential 처리 방식과 Pipelining 처리 방식에 대해서 비교해보자.
빨래 하는 과정을 단계별로 나눠보면, 세탁 → 건조 → 개기 → 보관 4단계로 나눠볼 수 있다.
만약 A/B/C/D 4명의 빨래를 해야한다면? Sequential 처리 방식에서는 A의 빨래를 모두 마친 뒤에 B의 빨래를 시작하기 때문에 시간이 굉장히 오래 걸릴 수 밖에 없다.
하지만 실제로는 A의 세탁이 마치고 건조를 하는 동안, 세탁기에는 작업이 없기 때문에 그 동안 B의 세탁을 할 수 있다. 이렇게 여러 명의 빨래 과정을 각 작업별도 동시에 수행하기 때문에 훨씬 더 효율적으로 빨래를 할 수 있다. 이것이 바로 Pipelining 처리 방식이다.
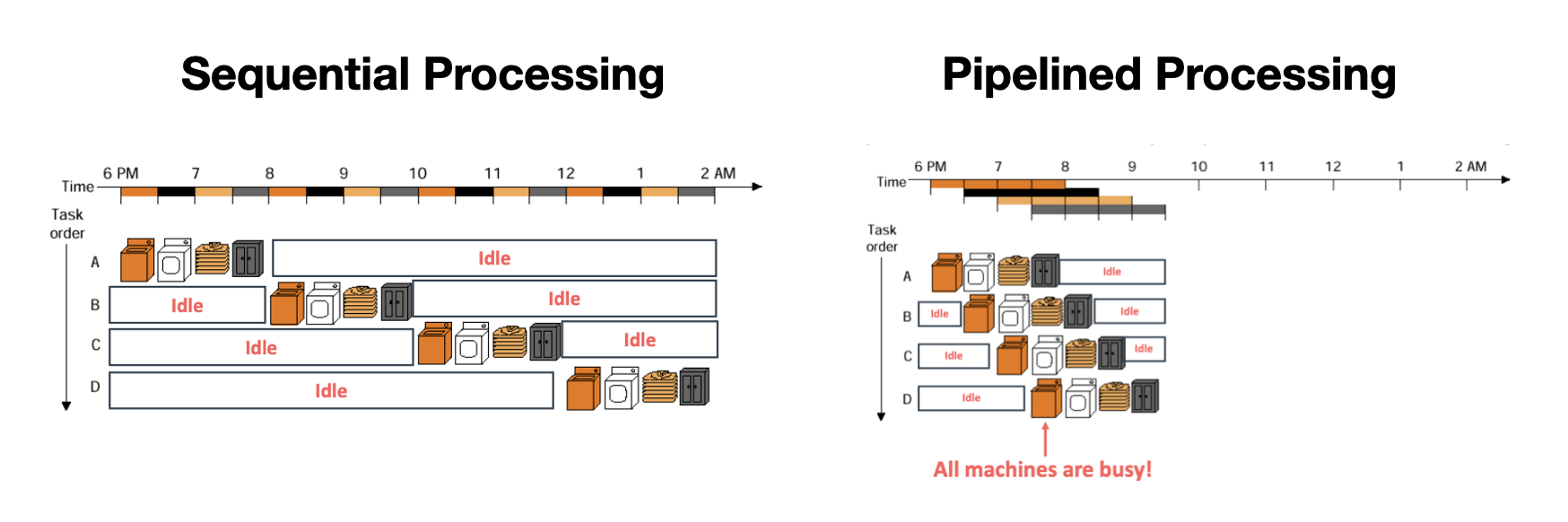
각 처리 방식을 다시 정리해서 설명하자면 아래와 같다.
- Sequential 처리 방식
- 명령어가 하나씩 순서대로 수행된다. (이전 명령어가 끝날 때까지 다음 명령어는 대기 상태)
- 명령어 내부의 연산의 독립적으로 처리되지 않아 자원 낭비가 발생한다.
- 1개 Cycle의 주기를 설정하는 방법에 따라 2가지 방식이 있다. (Single / Multi Cycle)
- Pipelining 처리 방식
- 명령어 여러 개가 각 연산별로 동시에 수행된다. (1개 연산이 끝나면 다음 명령어의 연산 시작)
- 자원을 효율적으로 활용할 수 있고 처리 속도를 크게 향상시킬 수 있다.
2️⃣ 처리 방식별 성능 비교
아래와 같이 명령어별 Cycle Time이 주어졌을 때,
Sequential 처리 방식(Single / Multi Cycle)과 Pipelining 처리 방식의 성능을 간단히 비교해보자.
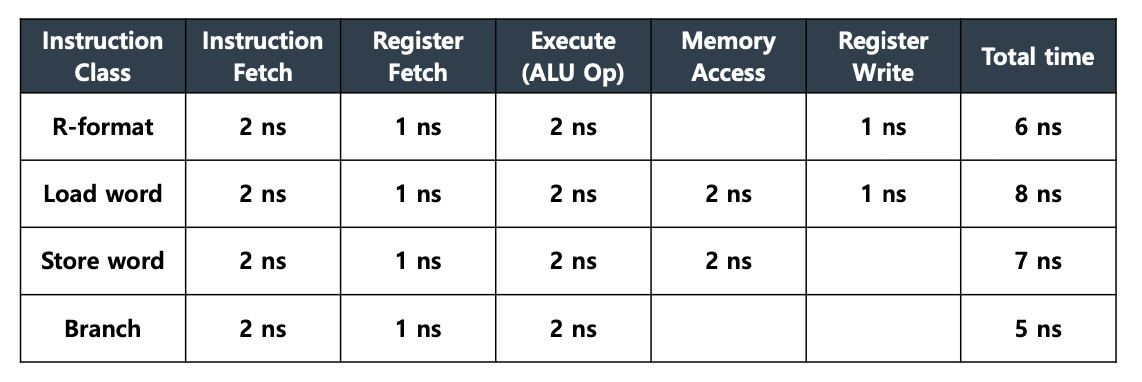
Single Cycle 방식은 1개 Clock이 (최장)Load 명령어 기준으로, 모든 명령어의 실행 시간은 8ns 이다.
Multi Cycle 방식은 1개 Clock Time은 2ns 이며 명령어별로 실행 시간이 다르다.
최소 실행 시간은 6ns(Branch) 이며, 최대 실행 시간은 10ns(Load)이다.
Pipelining 방식에서는, 명령어가 갖는 평균 Cycle은 4개이고 4개를 병렬로 수행할 수 있기 때문에,
Multi Cycle 방식 대비 약 4배 빠르다고 추정할 수 있다.
Pipelining
Pipelining 방식은 각 명령어를 연산별로 나누어, 각 연산을 독립적으로 동시에 수행시킨다.
그럼 세부적으로 어떤 과정을 통해서 연산을 독립적으로 수행시킬 수 있는건지 살펴보자.
1️⃣ Pipelining 단계
아래와 같이 일반적으로 명령어를 5개의 연산(작업)으로 구분할 수 있다.
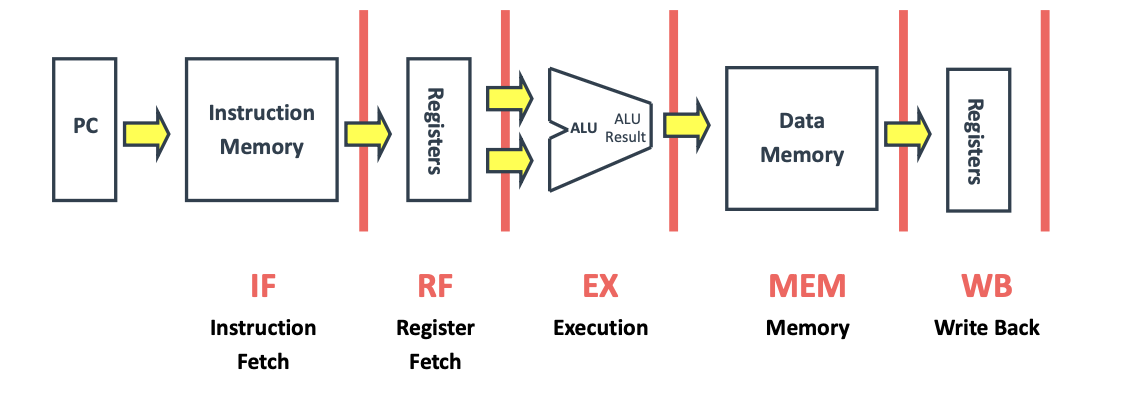
명령어별로 5개의 연산을 모두 사용하는 경우도 있고, 아닌 경우도 있지만
우선 5개의 연산을 사용하는 Load 명령어가 여러 차례 실행된다고 가정해보자.
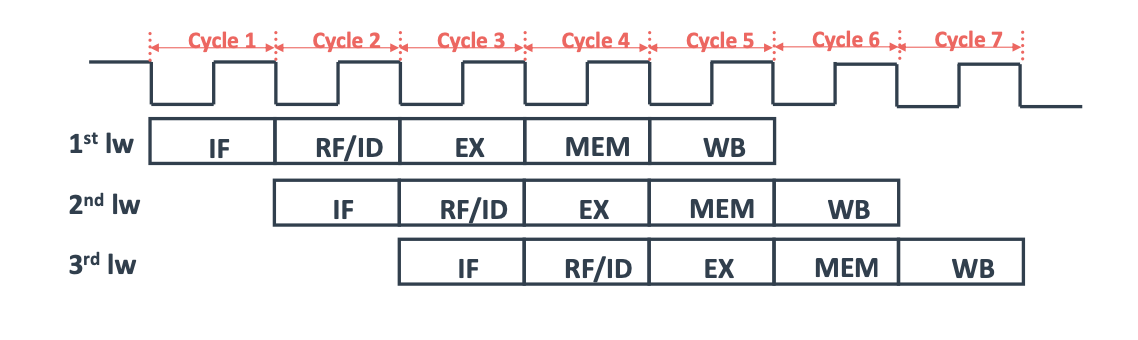
그럼 위의 그림과 같이 1번째 Cycle에서는 1번째 명령어의 IF 연산이 수행되고,
그 다음 Cycle에서는 1번째 명령어의 RF 연산, 2번째 명령어의 IF 연산이 수행되는 방식이다.
Pipelining 방식은 이러한 과정을 통해서 명령어를 동시에 여러개 수행할 수 있다.
2️⃣ Pipelining 방식과 장단점
Pipelining 방식은 이렇게 하드웨어 자원을 효율적으로 사용하고 성능을 향상시킨다는 장점을 가진다.
그런데 Pipelining 방식에는 장점만 있지는 않다.
여러 개의 명령어를 동시에 실행시키는 만큼 하드웨어의 구조도 복잡해질뿐더러,
명령어 간에 자원 및 데이터를 공유하기 때문에 여기에서 발생되는 문제점도 존재한다.
이러한 문제점을 Hazard라고 하고, 주요 Hazard 유형들에 대해 아래에서 다뤄보고자 한다.
Hazard
1️⃣ Hazard란?
Hazard는 명령어의 병렬 처리 과정 중에 다음 명령어가 즉시 실행되지 않는 경우를 말한다.
Hazard가 발생하는 원인에 따라 구조적/데이터/제어 3가지 유형으로 나눌 수 있는데,
각각의 Hazard의 원인과 해결 방안에 대해서 다뤄보고자 한다.
2️⃣ Structural Hazard
구조적(Structural) Hazard는 주로 하드웨어 자원 점유가 충돌될 때 발생하는 유형으로, 명령어가 완전히 병렬 처리 되지 않을 때 빈번하게 발생된다. 예를 들어, 아래 그림과 같이 CPI가 다른 명령어들을 병렬 처리 하는 과정에서, 2개의 명령어가 동일한 자원에 대해 WB 연산을 수행하게 되며 Hazard가 발생될 수 있다.
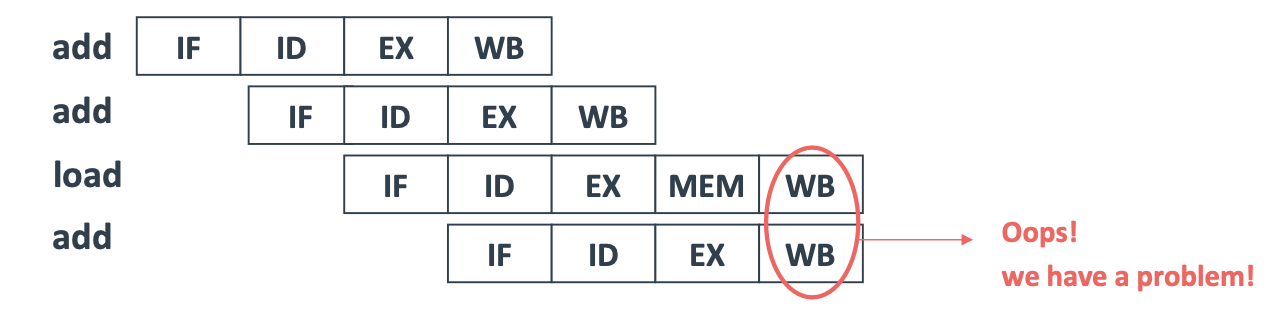
1) 해결 방안
이러한 경우 해결 방안으로는 크게 2가지가 있다.
① Stall 사용
아래 그림과 같이 CPI가 다른 명령어에 아무 작업도 하지 않는 Cycle을 삽입하여 Hazard를 방지할 수 있는데, 이때 삽입하는 Cycle을 Stall이라고 말한다. Stall을 사용하는 방법은 구조가 간단하지만 Cycle 1개를 불필요하게 낭비한다는 단점이 존재한다.
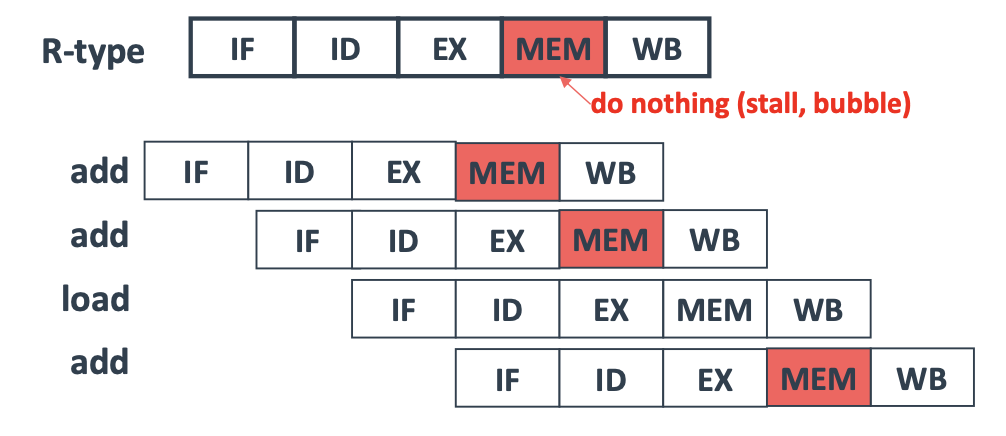
② 하드웨어 개선
충돌이 발생하는 하드웨어 자원을 추가하거나, 중복 쓰기 작업과 같은 연산을 허용시키는 방안이 있는데 현실적으로 접근하기 쉬운 방안은 아니기 때문에 길게 다루지 않겠다.
3️⃣ Data Hazard
2번째 Hazard 유형으로는, 데이터(Data) Hazard가 있다.
데이터 Hazard는 데이터 종속성으로 인해 발생하는 Hazard로, 다음 실행될 명령어가 이전 명령어의 결과를 필요로 하나, 이전 명령어가 결과를 생성하기 전에 다음 명령어가 해당 결과에 접근하는 경우 발생한다.
1) 유형
다음 명령어가 이전 명령어의 결과에 접근하는 유형에는 4가지가 있으며,
WAW, WAR의 경우 일반적인 파이프라인에서 발생 가능성이 낮고, RAR의 경우 발생되도 문제가 되지 않고, 실제 문제 되는 유형은 RAW 라고 할 수 있다.
- RAW(Read After Write) : 이전 명령어가 데이터를 쓰기 전에 다음 명령어가 읽는 경우
- WAW(Write After Write) : 다음 명령어가 이전 명령어의 결과를 덮어 쓰는 경우
- WAR(Write After Read) : 다음 명령어가 이전 명령어보다 먼저 데이터를 변경하는 경우
- RAR(Read After Read) : 다음 명령어가 이전 명령어보다 먼저 읽는 경우
2) 해결 방안
① Stall 사용
구조적 Hazard와 동일하게 Stall을 사용하여 Data Hazard 또한 방지할 수 있다.
아래의 경우 Stall 3개를 사용해야 Data Hazard를 방지할 수 있는 것을 알 수 있다.

② Change Clock Cycle
1개 Clock을 2개 시점으로 나누어서 해결하는 방안도 있는데,
아래 그림과 같이 1개 Clock 내에서 1번째 시점에서는 Register 쓰기 작업이 수행되고 2번째 시점에서는 Register 읽기 작업을 수행함으로써 Stall을 2개만 사용하고도 Data Hazard를 방지할 수 있다.
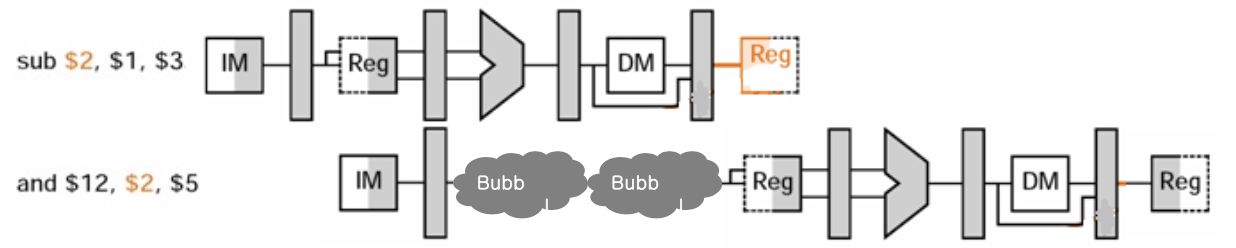
③ Forward(or Bypassing)
Forward 방식은 위의 2개보다 구현은 조금 더 복잡하지만, Stall을 확연히 줄일 수 있는 방안이다.
아래 그림과 같이, 명령어의 결과(데이터)가 생성되는 시점부터 즉시 다음 명령어에 전달 되게끔 하는 방식이다. 다만 다음 명령어가 데이터를 활용할 수 있도록 Data Path가 추가되어야 하기 때문에 구현 측면에서 조금 더 복잡하지만 보다 효율적으로 명령어를 처리할 수 있다.
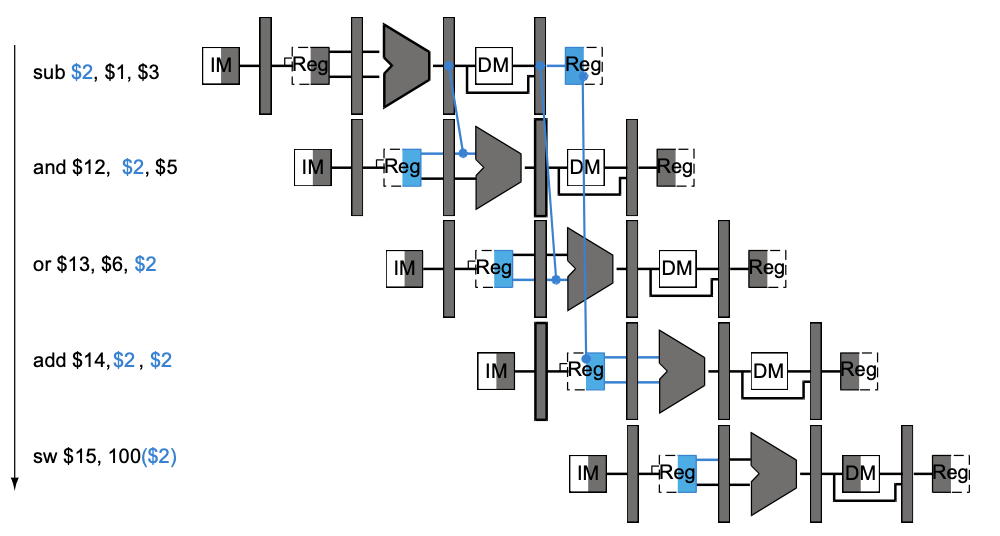
④ Software(Compiler) 제한
위의 3가지 방식은 하드웨어 관점에서의 개선 위주였다면, 소프트웨어 관점에서의 해결 방안도 존재한다.
컴파일러에서 동일한 데이터를 사용하는 명령어들을 재배치하거나 해당 명령어들 사이에 비연산 명령어를 추가하여 별도의 Stall 등을 사용하지 않고도 Data Hazard를 방지할 수 있다.
다만 모든 케이스에 이를 적용하기는 어렵다.
4️⃣ Control Hazard
Control Hazard는 주로 분기 명령어와 같이 다음 실행될 명령어가 이전 분기 명령어에 의해
결정되는 제어 의존성 때문에 발생된다.
1) 해결 방안
① Stall 사용
Control Hazard도 동일하게, 분기 명령어의 결과가 나오기 전까지 다음 명령어의 실행을 지연 시킴으로써 Hazard를 방지할 수 있다.
② Branch Prediction
Branch Prediction은, 분기 결과를 예측하여 다음 명령어를 실행시킴으로써 잘못된 명령어의 실행을 줄이는 방안이다. 분기 결과 예측의 경우 이전 분기 명령어의 결과를 활용하여 다음 분기 결과를 예측하는 Dynamic Branch Prediction(1-bit / 2-bit)이 있다.
비교적 간단해 보이지만 2-bit Predicition의 경우 90% 이상의 정확도를 보여 실제로도 많이 활용되고 있다.
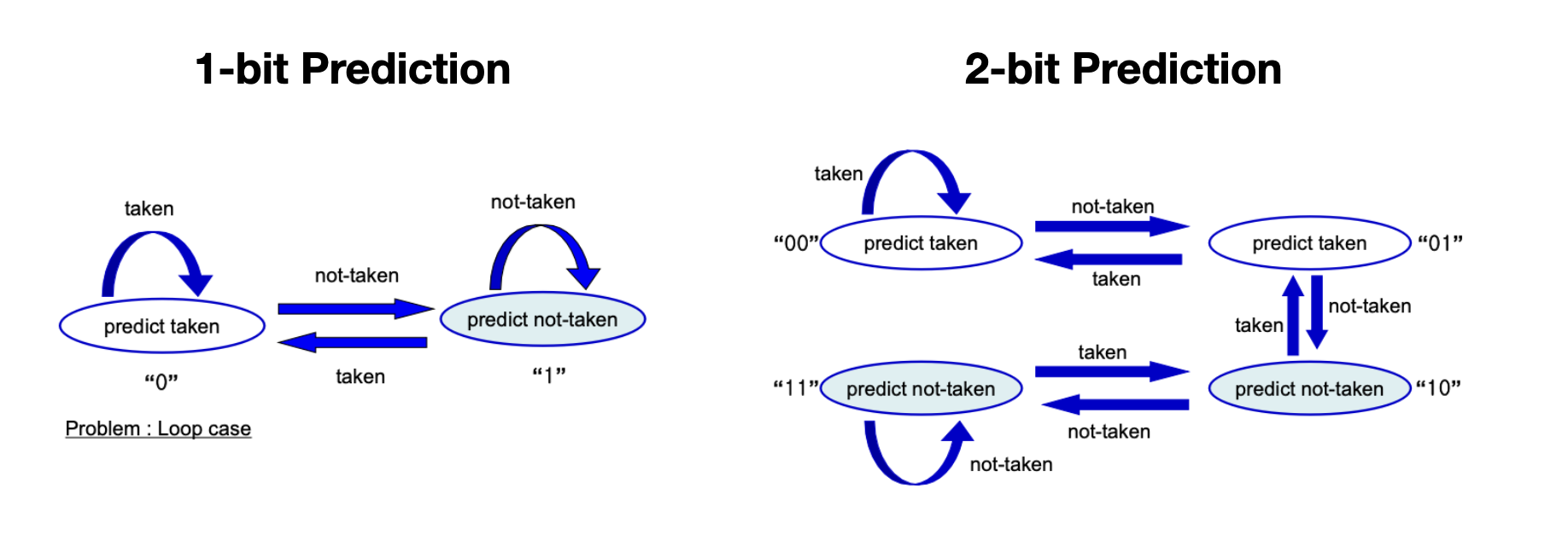
③ Delayed Decision
이는 분기 결과에 의존하지 않는 명령어를 분기 명령어 뒤에 실행시켜 Control Hazard 를 방지하면서 낭비되는 Cycle을 줄이는 방안이 있다.
파이프라인 구조의 발전
수퍼파이프라이닝 / 수퍼스칼라 / VLIW
- 명령어 수준 병렬성(ILP: Instruction Level Parallelism)
- 수퍼파이프라이닝(superpipelining): 깊은 파이프라인으로 클록 주파수 향상
- 수퍼스칼라(superscalar): 한 사이클에 여러 명령어 처리 가능
- VLIW(Very Long Instruction Word): 여러 연산을 하나의 명령어로 처리
- 동적 스케줄링(Dynamic Scheduling)
- 명령어 처리 순서를 동적으로 관리하여 효율성 향상
- 분기 예측 기법
- 동적 분기 예측(dynamic branch prediction)
- 1-bit, 2-bit 예측기를 이용해 정확성 향상
파이프라이닝은 명령어 처리 효율을 높이기 위한 핵심 기술로, 하드웨어와 소프트웨어적 해결책을 통해 다양한 해저드를 극복하여 성능을 극대화합니다.
