문제상황
현재 진행중인 프로젝트에서 의약품의 이름을 검색하면 검색어와 유사한 이름을 가진 의약품을 보여주고 원하는 의약품을 선택하면 자세한 정보를 보여주는 요구사항이 있다.
 의약품의 정보를 얻기 위해서 여러 공공데이터를 찾아보았지만 데이터들이 굉장히 불규칙하고 RDB에 저장하기 어려운 구조로 되어있다. 예를 들어서 주의사항과 같은 경우에는 매우 긴 text인데 이 자료가 공공데이터 액셀파일에는 pdf 링크로 입력되어있다. 이렇게 되면 이 서비스에서 의약품 정보를 호출할 때마다 pdf파일을 다운로드 받아서 글자를 크롤링해야하기 때문에 성능적으로 불리하다. 결국 이 불규칙적인 데이터들을 정리해서 우리 서비스에 적합하게 수정해야한다.
의약품의 정보를 얻기 위해서 여러 공공데이터를 찾아보았지만 데이터들이 굉장히 불규칙하고 RDB에 저장하기 어려운 구조로 되어있다. 예를 들어서 주의사항과 같은 경우에는 매우 긴 text인데 이 자료가 공공데이터 액셀파일에는 pdf 링크로 입력되어있다. 이렇게 되면 이 서비스에서 의약품 정보를 호출할 때마다 pdf파일을 다운로드 받아서 글자를 크롤링해야하기 때문에 성능적으로 불리하다. 결국 이 불규칙적인 데이터들을 정리해서 우리 서비스에 적합하게 수정해야한다.
의약품 데이터베이스 구축
테이블 스키마
의약품 안전나라에서 제공하는 의약품 제품허가 상세정보 공공데이터 xlsx 파일을 이용하여 우리 서비스에 적합한 의약품 데이터베이스를 구축할 것이다.
클라이언트에게 제공할 정보들은 다음과 같다.
- 의약품 id (primary key)
- 의약품 code(구별코드)
- 의약품 이름
- 의약품 이미지 링크
- 제약회사
- 성분
- 효능
- 용법
- 주의사항
매번 이 정보가 필요한 것은 아니지만 데이터베이스를 구축할 때 해당 정보들을 저장하면 충분하다. MySql에 테이블을 생성해주자.
create table medicine
(
id int not null auto_increment,
code varchar(12) not null,
name varchar(700) not null,
company varchar(1000),
ingredient varchar(3000),
image varchar(512),
effect longtext,
usages longtext,
precautions longtext,
created_at datetime default current_timestamp,
updated_at datetime default current_timestamp,
primary key (id),
index (code),
index (name)
);이 형태에 맞게 공공데이터 xlsx 파일을 수정해주면된다. 참고로 검색엔진으로서 MySql과 같은 관계형 데이터베이스는 적합하지 않지만 신뢰할 수 있는 데이터 source를 구축할 필요가 있다. 의약품 데이터는 자주 변경되진 않지만 주기적으로 배치 프로그램을 이용하여 검색엔진의 데이터를 업데이트 시켜줄 수도 있다. 이 이야기는 아래에서 다시 설명하고 일단 넘어가겠다.
공공데이터 문제점
일단 1차적으로 불필요한 열을 삭제하고 속성 이름을 테이블에 맞게 수정했다.
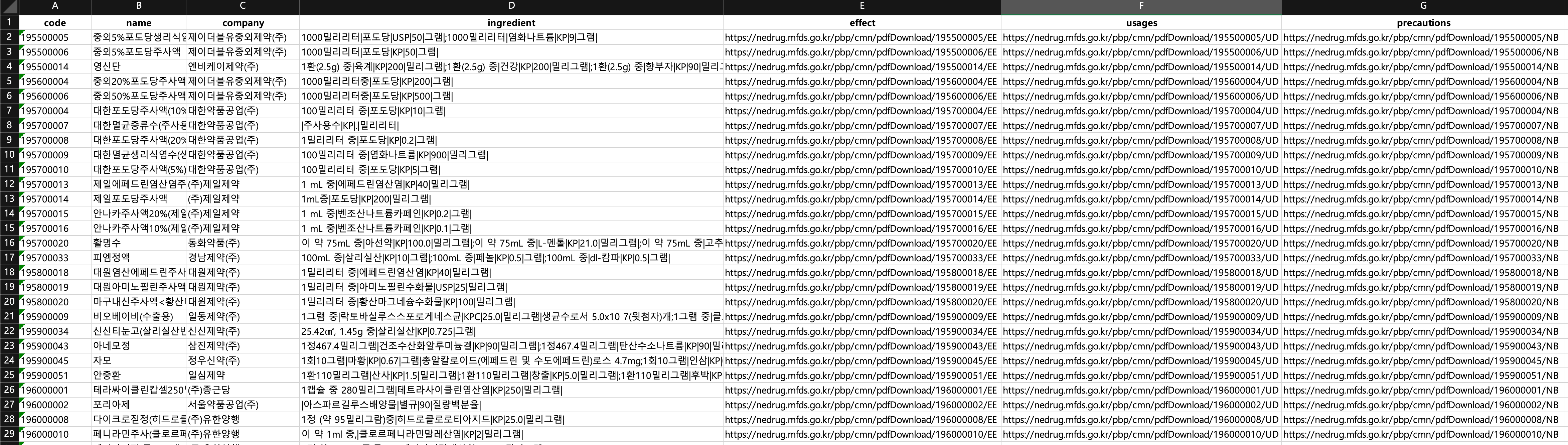
사진을 확대해서 보면 확인할 수 있겠지만 성분에 해당하는 ingredient 셀들의 값이 특이한 문자열로 이루어져있고 특히 effect, usages, precautions 항목들이 pdf 다운로드 링크로 설정되어 있다. 저 pdf 문서를 다운로드 받으면 다음과 같은 문서를 확인할 수 있다.

이런 문서를 3개씩이나 매번 다운로드 받고 크롤링해서 클라이언트에게 보여주는 것은 비효율적이다. 이런 이유로 실제 서비스가 출시되기전에 데이터베이스를 구축하고 단 한번의 요청으로 모든 의약품 정보를 제공하는 것이 훨씬 효율적인 방법일 것이다.
또 성분 ingredinet 값을 보면 규칙성을 확인할 수 있다.
1000밀리리터|포도당|USP|50|그램|;1000밀리리터|염화나트륨|KP|9|그램|두개의 성분이 ;으로 구분되고 용량, 성분명, 단위 등이 |로 구분된다. 우리에게 필요한건 포도당, 염화나트륨과 같은 성분명이므로 적절하게 문자열을 split 해주면 될 것이다.
필자는 약 5만개의 의약품을 담고있는 액셀파일을 수작업으로 수정할 끈기도 없고 컴퓨터공학도로서 이런 수작업은 용납할 수 없다. Python을 이용하여 자동화 하기로 했다.
공공데이터 정제하기
다운로드 문자열 TEXT로 변환
먼저 effect, usages, precautions 내용을 다운로드 받아 보기 좋은 문자열 형태로 저장하고자한다. 의약품 안전나라를 찾아보니 pdf 다운로드 링크를 html 다운로드 링크로 변경할 수 있었다.
이런 형태의 문자열을
https://nedrug.mfds.go.kr/pbp/cmn/pdfDownload/195500005/EE이런식으로 pdfDwonload를 html로 바꿔주면된다.
https://nedrug.mfds.go.kr/pbp/cmn/html/195500005/EE하지만 문자열을 치환하는 것보다는 code값을 이용해서 새로운 html 다운로드 링크 문자열을 생성하는 것이 나아보인다.
https://nedrug.mfds.go.kr/pbp/cmn/html/{code}/EEpandas를 이용하여 xlsx 파일의 링크 관련 문자열들을 수정하고 새로운 xlsx 파일을 생성하자.
import pandas as pd
# xlsx 파일을 읽어서 데이터프레임 생성
df = pd.read_excel('{수정전 xlsx 파일 경로}')
# effect, usages, precautions 열에서 값이 존재하는 행 선택
valid_rows = df[['effect', 'usages', 'precautions']].notna().all(axis=1)
# 선택된 행에 대해 URL 생성
urls = df.loc[valid_rows, 'code'].apply(lambda x: f"https://nedrug.mfds.go.kr/pbp/cmn/html/{x}/EE")
# URL 값을 새로운 열에 추가
df.loc[valid_rows, 'url'] = urls
# 새로운 xlsx 파일로 저장
df.to_excel('{새로운 xlsx 파일 경로}', index=False)여기서 중요한건 링크가 없는 의약품들도 있기 때문에 notna() 설정을 해주어야 정상적으로 결과가 출력된다.
이제 이 html 링크를 다운로드 받고 불필요한 html 태그를 제외한 문자열로 effect, usages, precautions를 수정하는 작업을 진행해보자. 해당 작업은 의약품 1개당 3번의 다운로드가 발생하고 의약품 개수가 약 5만개이므로 약 15만번의 다운로드가 발생한다. 즉 매우 오래 걸리는 작업이므로 중간에 오류가 발생해 데이터가 사라지는 것을 방지하기 위해 100개 단위로 새로운 액셀 파일을 생성하자.
import pandas as pd
from urllib.request import urlretrieve
from bs4 import BeautifulSoup
# 데이터프레임을 나눌 크기를 지정합니다.
chunk_size = 100
# 데이터프레임을 읽어옵니다.
df = pd.read_excel("{xlsx 파일 경로}")
# 데이터프레임을 나누어 처리합니다.
for i in range(0, len(df), chunk_size):
chunk_df = df.iloc[i:i+chunk_size]
for index, row in chunk_df.iterrows():
for column in ["effect", "usages", "precautions"]:
url = row[column]
if url:
html_file = f"{column}_{index}.html"
try:
urlretrieve(url, html_file)
except Exception as e:
print(f"Error downloading {url}: {e}")
continue
with open(html_file, "r", encoding="utf-8") as f:
html = f.read()
soup = BeautifulSoup(html, "html.parser")
# 수정한 부분: "h1" 태그와 "p" 태그를 사용하여 내용을 추출합니다.
content_tag = soup.find("h1")
if content_tag:
content = content_tag.get_text() + "\n"
content_tags = soup.find_all("p", class_="indent0")
for tag in content_tags:
content += " - " + tag.get_text() + "\n"
else:
content = ""
df.loc[index, column] = content
# 처리한 데이터프레임을 엑셀 파일로 저장합니다.
chunk_df.to_excel(f"{데이터 저장할 경로}/최종데이터_{i}.xlsx", index=False)이 작업은 대략 8시간 가량 소요되었다. 결과적으로 수백개의 액셀파일이 저장되었고 이제 이들을 합쳐서 하나의 파일로 만들어야한다.
import pandas as pd
import glob
# 파일 경로와 파일 이름 패턴을 지정합니다.
path = '{데이터 저장된 디렉토리 경로}'
pattern = '최종데이터*.xlsx'
# 모든 파일을 읽어와서 데이터프레임 리스트에 추가합니다.
df_list = []
for filename in glob.glob(f"{path}/{pattern}"):
df_list.append(pd.read_excel(filename))
# 데이터프레임 리스트를 하나로 합칩니다.
merged_df = pd.concat(df_list, ignore_index=True)
# 합쳐진 데이터프레임을 새로운 엑셀 파일로 저장합니다.
merged_df.to_excel(f"{새로운 xlsx 파일 경로}", index=False)성분 문자열 정제하기
이제 성분 ;와|로 구분되어 있는 ingredient 항목을 수정하자.
import pandas as pd
# 알약빅데이터_수정_ingredient.xlsx 파일을 DataFrame으로 불러오기
df = pd.read_excel('/Users/jameskim/downloads/알약빅데이터_수정_ingredient.xlsx')
# NaN 값을 공백 문자열로 대체하기
df['ingredient'].fillna('', inplace=True)
# ingredient 열에서 ';'로 구분된 각 재료 정보 중 2번째 문자열들만 추출하여 리스트에 저장하기
new_ingredients = []
for ingr in df['ingredient']:
ingr_list = ingr.split(';') # ';'로 구분된 각 재료 정보를 분리하여 리스트에 저장
new_ingredient_list = []
for elem in ingr_list:
if '|' in elem:
new_ingredient_list.append(elem.split('|')[1])
new_ingredient = '|'.join(new_ingredient_list) # '|'로 구분된 각 속성 정보에서 2번째 값을 추출하여 '|'로 구분하여 하나의 문자열로 저장
new_ingredients.append(new_ingredient)
# 추출한 정보를 기존 DataFrame에 추가하기
df['ingredient'] = new_ingredients
# 수정된 DataFrame을 새 Excel 파일로 저장하기
df.to_excel('/Users/jameskim/downloads/알약빅데이터_수정_ingredient_new.xlsx', index=False)이 과정을 거치면 다음과 유사한 상태로 저장이 될 것이다. 필자는 effect, usages, precautions 내용을 클라이언트에 출력할 때 더 잘보이는 형태로 바꾸기 위해서 약간의 처리과정을 거쳐서 좀 다를 수 있다. 앞에 공백 2개를 추가하여 줄을 맞추고 불필요한 제목들을 지웠다. 협업 과정에서 클라이언트 개발자분께서 차라리 html 코드로 제공하는 편이 나을 수 있다고 하셨는데 이는 요구사항에 따라 적절하게 조절하면된다.

image 주소로 변환하기
여기서 문제는 image가 없다. 불행하게도 이미지는 다른 공공데이터 파일에 저장되어 있었다. code 값을 기준으로 두 xlsx 파일을 merge(join과 유사한 개념) 해주면된다.
그런데 아주 큰 문제가 발생했다. image 링크가 이미지 주소 링크가 아닌 이미지 다운로드 링크였다. 이렇게도 작업을 할 수 있겠지만 클라이언트 개발자 입장에서는 번거롭고 다운로드를 매 요청마다 진행해야 하므로 이미지 주소 링크로 변경해야한다.

해당 이미지를 모두 다운로드 받아 Naver Cloud Platform의 ObjectStorage에 저장하고 이미지 링크를 생성하는 방법을 떠올렸다. 여기에서 중요한건 이미지 파일 이름은 code와 연관지어서 설정하는 것이다. ObjectStorage는 AWS의 S3와 유사한 파일 저장소이고 동일하게 S3 client를 사용할 수 있다.

NCP에서 yacsa라는 버킷을 생성해주었고 이제 이곳에 이미지 파일을 저장할 것이다. 이 때 주의할 점은 파일을 전체 공개 해주어야한다는 점이다. 불편하게도 NCP object storage는 한번에 파일 권한을 수정할 수 없어 업로드 할 때 설정해주어야 하고 이 또한 사이트에서 직접 처리할 순 없고 S3 client를 이용하여 코드로 작업해주어한다.
먼저 image 값들을 통해 이미지를 한 디렉토리에 모두 다운로드 하자
import pandas as pd
import requests
import os
df = pd.read_excel("{이미지 다운로드 링크가 저장된 xlsx 파일 경로}")
for idx, row in df.iterrows():
code = row['code']
image = row['image']
if image != '':
response = requests.get(image)
with open(f'{이미지 저장 디렉토리 경로}/img_{code}.jpg', 'wb') as f:
f.write(response.content)
if idx % 500 == 0:
print(f"{idx} rows processed")다운로드가 잘 진행되는지 500개마다 print로 로그를 남기도록 처리했다. 이미지는 img_{code}.jpg 이름으로 저장되어 code와 매핑시킬 수 있다.
import boto3
import os
service_name = 's3'
endpoint_url = 'https://kr.object.ncloudstorage.com'
region_name = 'kr-standard'
access_key = '{ACCESS_KEY}'
secret_key = '{SECRET_KEY}'
if __name__ == "__main__":
s3 = boto3.client(service_name, endpoint_url=endpoint_url, aws_access_key_id=access_key,
aws_secret_access_key=secret_key)
bucket_name = '{Object Storage 버킷 이름}'
# create folder
object_name = 'medicine-image/'
s3.put_object(Bucket=bucket_name, Key=object_name, ACL='public-read')
dir_path = '{이미지가 저장된 디렉토리 경로}'
# 폴더 내 모든 파일 업로드
file_count = 0
for file_name in os.listdir(dir_path):
file_path = os.path.join(dir_path, file_name)
with open(file_path, 'rb') as f:
s3.upload_fileobj(f, bucket_name, os.path.join(object_name, file_name),
ExtraArgs={'ACL': 'public-read', 'ContentType': 'image/jpeg'})
file_count += 1
if file_count % 100 == 0:
print(f'{file_count} 개 파일 업로드 완료')
print(f'전체 {file_count} 개 파일 업로드 완료')ACCESS_KEY와 SECRET_KEY는 마이페이지 -> 계정관리 -> 인증키 관리에서 설정할 수 있다. 여기서 중요한 것은 ACL은 public-read로 설정해야한다는 것이다. 그래야 이 서비스를 사용하는 누구나 이미지에 접근할 수 있다.
이 작업들을 마무리하면 정상적으로 이미지가 업로드 됨을 확인할 수 있고 이미지 주소도 확인할 수 있다.
이제 xlsx 파일의 image를 이미지 주소로 변경해주면 된다.
import pandas as pd
# xlsx 파일 읽어오기
df = pd.read_excel("{수정 전 xlsx 파일}")
# image 열의 값 변경
df['image'] = df.apply(lambda row: f"{NCP 버킷 주소}/img_{row['code']}.jpg", axis=1)
# 변경된 DataFrame을 새로운 xlsx 파일로 저장
df.to_excel("{새로운 xlsx 파일 경로}", index=False)드디어 이미지 다운로드 링크로 저장된 xlsx 파일이 생성되었다. 이제 이전에 image 값이 존재하지 않던 xlsx 파일과 image 다운로드링크로 방금 수정한 xlsx 파일을 merge 해주면된다. 이 때 주의해야될 점은 두 파일을 merge 할 때 image가 존재하지 않는 파일이 있는데 이 때는 이전에 버킷에 업로드한 notfound 이미지 경로를 지정해주면된다. RDB의 Left Join을 생각하면 이해하기 쉬울 것이다.
import pandas as pd
# 첫 번째 엑셀 파일을 읽어서 데이터프레임으로 변환합니다.
df1 = pd.read_excel('{첫번째 xlsx 파일 경로}')
# 두 번째 엑셀 파일을 읽어서 데이터프레임으로 변환합니다.
df2 = pd.read_excel('{두번째 xlsx 파일 경로}')
# 첫 번째 데이터프레임과 두 번째 데이터프레임을 합칩니다.
merged_df = pd.merge(df1, df2[['code', 'image']], on='code', how='left')
# 두 번째 데이터프레임에 존재하지 않는 코드는 "NOTOUND 이미지 주소로"로 지정합니다.
merged_df.loc[merged_df['image'].isna(), 'image'] = '{NOTFOUND 이미지 경로}'
# 합쳐진 데이터프레임을 새로운 엑셀 파일로 저장합니다.
merged_df.to_excel('{합친 파일 경로}', index=False)최종적으로 우리 서비스에 필요한 의약품 xlsx 파일을 만들었다. 이제 이 xlsx 파일에 있는 의약품 정보들을 MySql로 insert 해주면 된다.
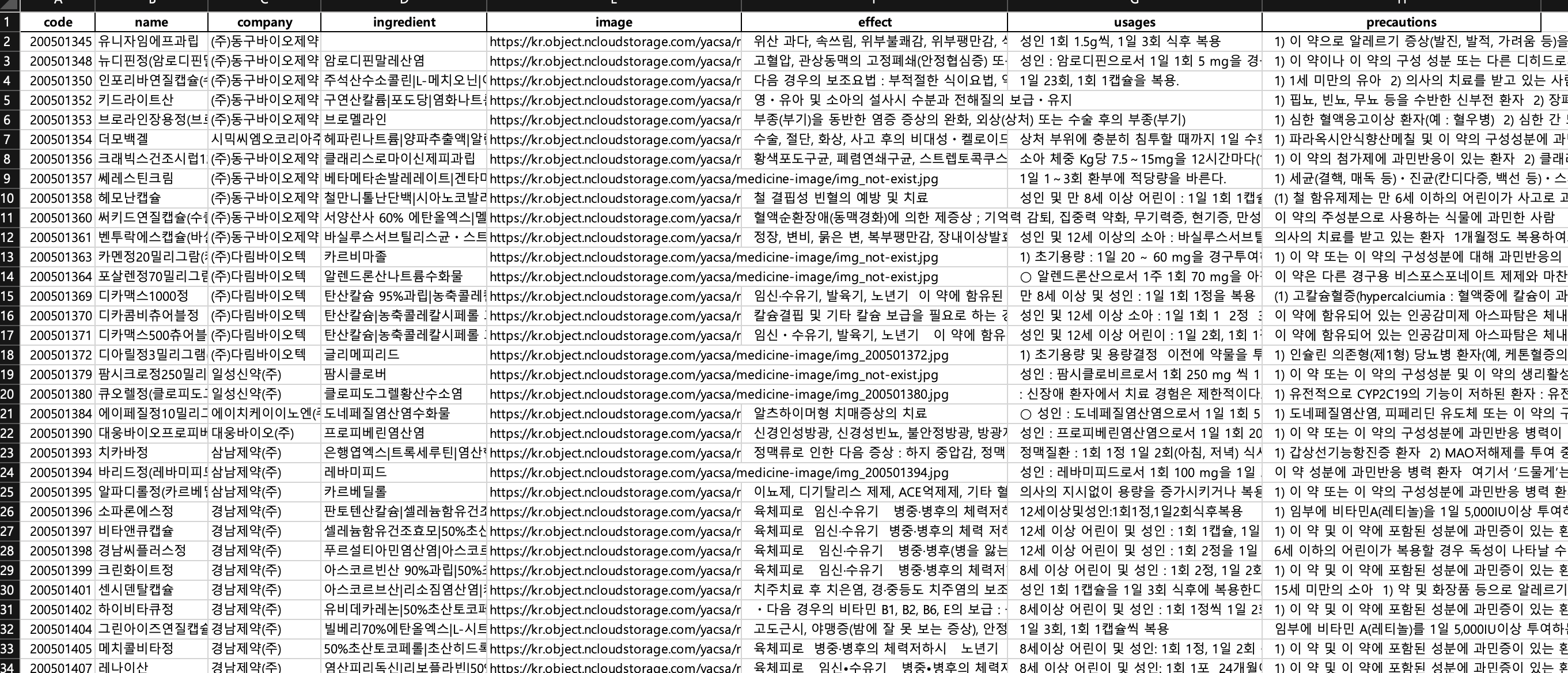
mysql에 insert 하기
다음과 같이 mysql.connector를 이요하여 xlsx 파일의 데이터를 insert 쿼리로 만들어 execute 해주면된다.
import pandas as pd
import mysql.connector
# MySQL 서버에 연결
cnx = mysql.connector.connect(user='{user}', password='{password}',
host='{host 주소}', database='{database}')
# 읽어올 CSV 파일 경로 지정
csv_file_path = "/Users/jameskim/downloads/최종DB.csv"
# CSV 파일 읽어오기
df = pd.read_csv(csv_file_path)
df.fillna('', inplace=True)
# MySQL 테이블에 데이터프레임의 내용 삽입
cursor = cnx.cursor()
for index, row in df.iterrows():
cursor.execute(
"INSERT INTO medicine (code, name, company, ingredient, effect, usages, precautions, image)"
" VALUES (%s, %s, %s, %s, %s, %s, %s, %s)",
(row['code'], row['name'], row['company'], row['ingredient'], row['effect'], row['usages'],
row['precautions'], row['image'])
)
cnx.commit()
# 연결 종료
cursor.close()
cnx.close()최종적으로 MySql에 의약품 데이터베이스를 구축하였다.
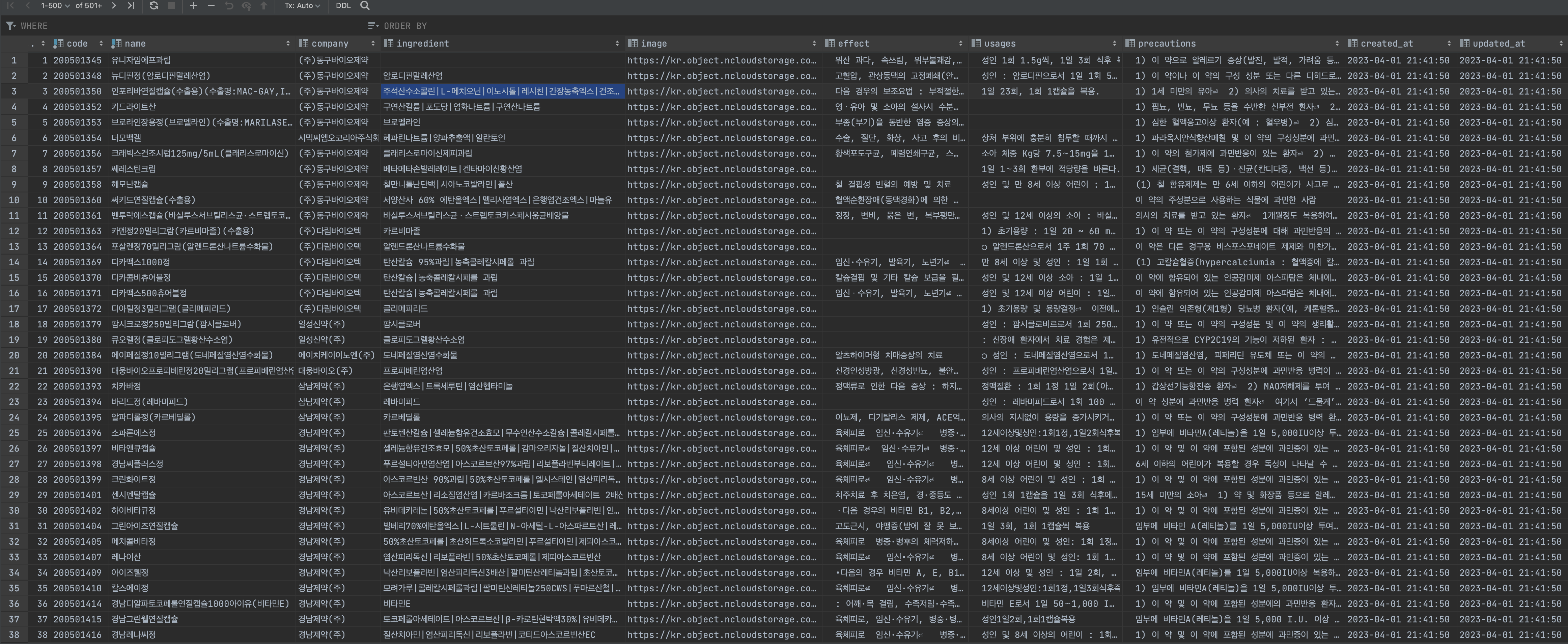
이제 이 정보를 이용하여 의약품 정보를 조회할 수 있고 우리가 구축한 데이터를 이용하여 검색엔진을 만들 수 있다. 해당 내용은 다음 포스팅에서 다루겠다.

안녕하세요, 마침 같은 문제로 고민하고 있었는데 좋은 포스트 작성해주셔서 감사합니다 :)
혹시 한가지 질문 남겨도 될까요?
html로 변환하는 것까지는 했는데 안에 내용을 크롤링하는 과정에서 500 오류가 나 봤더니 해당 링크로 접속이 안 되는 것 같더라구요.. html 형식으로 파일이 열리지 않아 안에 내용을 가지고 올 수 없는 문제인 것 같습니다. 의약품 안전나라에 문의를 남겨볼 계획이지만, 가능하시다면 정제한 파일을 메일로 받아볼 수 있을까요?? 말씀하신대로 의약품 관련 데이터셋이 너무 불규칙해 가공, 정제하는 과정이 어렵네요ㅜㅜ.. 부탁드리겠습니다!!