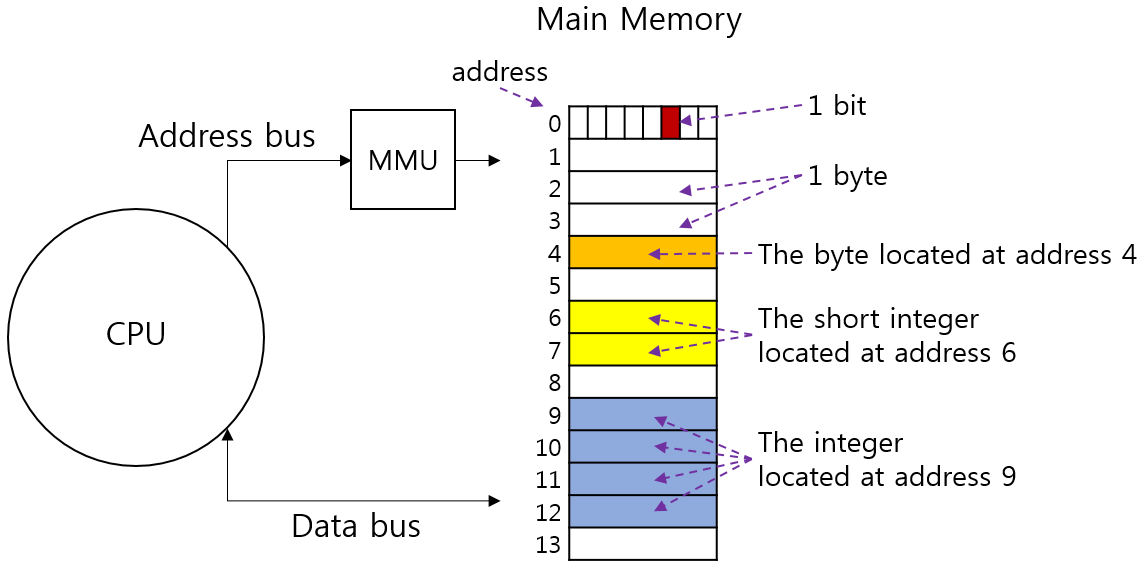
메모리의 구조는 1Byte 크기로 나뉘며, 1 Byte로 나뉜 각 영역은 메모리 주소로 구분하는데 0번지 부터 시작한다.
CPU는 메모리에 있는 내용을 가져오거나, 작업 결과를 메모리에 저장하기 위해 메모리 주소 레지스터(MAR) 을 사용한다.
폰노이만 컴퓨터 구조에서 메모리는 유일한 작업 공간이고 모든 프로그램은 메모리에 올라와야 실행이 가능하다.
오늘날의 시분할 시스템에서는 운영체제를 포함한 모든 응용 프로그램이 메모리에 올라와 실행되기 때문에 메모리 관리가 매우 복잡하다.
복잡한 메모리 관리는 메모리 관리 시스템(Memory Management System, MMS)에서 담당한다.
메모리 관리의 이중성
프로세스 입장에서는 메모리를 독차지 하려하고,
메모리 관리자 입장에서는 되도록 관리를 효율적으로 하고 싶어하는 것을 말한다.
프로세스 입장에서의 작업의 편리함과 관리자 입장에서 관리의 편리함이 충돌을 일으키는 것이다.
메모리 관리자(MMU)의 역할

메모리 관리는 메모리 관리자가 담당한다.
메모리 관리자는 정확히 말해 메모리 관리 유닛(Memory Management Unit, MMU) 라는 하드웨어인데 일반적으로 메모리 관리자라고 일컫는다.
메모리 관리자는 다음의 작업을 한다.
-
가져오기
프로세스와 데이터를 메모리로 가져오는 작업
-
배치
가져온 프로세스와 데이터를 메모리의 어떤 부분에 올려놓을지 결정하는 작업
배치 작업 전에 메모리를 어떤 크기로 자를 것인지가 매우 중요
-
재배치
새로운 프로세스를 가져와야 하는데 메모리가 꽉 찼다면 메모리에 있는 프로세스를 하드디스크로 옮겨 놓아야, 새로운 프로세스를 메모리에 가져올 수 있다.
메모리는 관리자는 위의 작업시 정책을 수립하여, 그 정책에 따라 메모리를 관리한다.
-
가져오기 정책
프로세스가 필요로 하는 데이터를 언제 메모리를 가져올지 결정하는 정책
-
배치 정책
가져온 프로세스를 메모리의 어떤 위치에 올려 놓을 지 결정하는 정책
메모리를 같은 크기로 자르는 것을 페이징
메모리를 프로세스의 크기에 맞게 자르는 것을 세그먼테이션 이라고 한다.
페이징과 세그먼테이션의 장단점을 파악하여, 메모리를 효율적으로 관리할 수 있도록 정책을 만드는 것
-
재배치 정책
메모리가 꽉 찼을 때 메모리 내에 있는 어떤 프로세스를 내보낼지 결정하는 정책
메모리 주소
32bit CPU와 64bit CPU의 차이
CPU의 비트는 한 번에 다룰 수 있는 데이터의 최대 크기를 의미한다. (32는 32bit, 64는 64bit)
CPU 내부 부품은 모두 이 비트를 기준으로 제작이 되는데
레지스터 크기, 산술 논리 연산장치 또한 데이터를 전송하는 각종 버스의 크기 (대역폭) 도 여기에 따른다.
32bit CPU인 경우, 메모리 주소를 지정하는 메모리 주소 레지스터의 크기가 32bit 이므로 표현할 수 있는 메모리 주소의 범위가 2의 32승 이므로 주소 하나당 1Byte 이므로 약 4GB 이다.
그래서 32bit CPU 컴퓨터는 메모리를 최대 4GB까지 사용할 수 있다.
메모리 오버레이
과거에는 작은 메모리로 메모리 요구가 큰 프로그램을 어떻게 작동시켰을까?
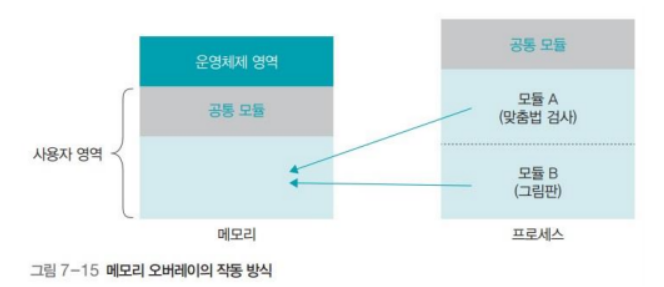
프로그램의 크기가 실제 메모리보다 클 때, 전체 프로그램을 메모리에 가져오는 대신 적당한 크기로 잘라서 가져오는 기법을 메모리 오버레이(memory overlay)라고 한다.
프로그램을 몇 개의 모듈로 나누고, 필요할 때마다 모듈을 메모리에 가져와 사용한다.
필요한 중요한 모듈만 올려놓고 나머지는 필요할 때마다 메모리에 가져와 사용하는 것이다.
프로그램 전체를 메모리에 올려놓고, 실행하는 것보다 속도가 느리지만 메모리가 프로그램보다 작을 때도 실행 할 수 있어 유용하다.
어떤 모듈을 가져오거나 내보낼지는 CPU 레지스터 중 하나인 프로그램 카운터(PC)가 결정한다.
해앞으로 실행할 명령어의 위치를 가리키는데 해당 모듈이 메모리에 없으면,
메모리 관리자에게 요청하여 메모리로 가져오게 한다.
스왑
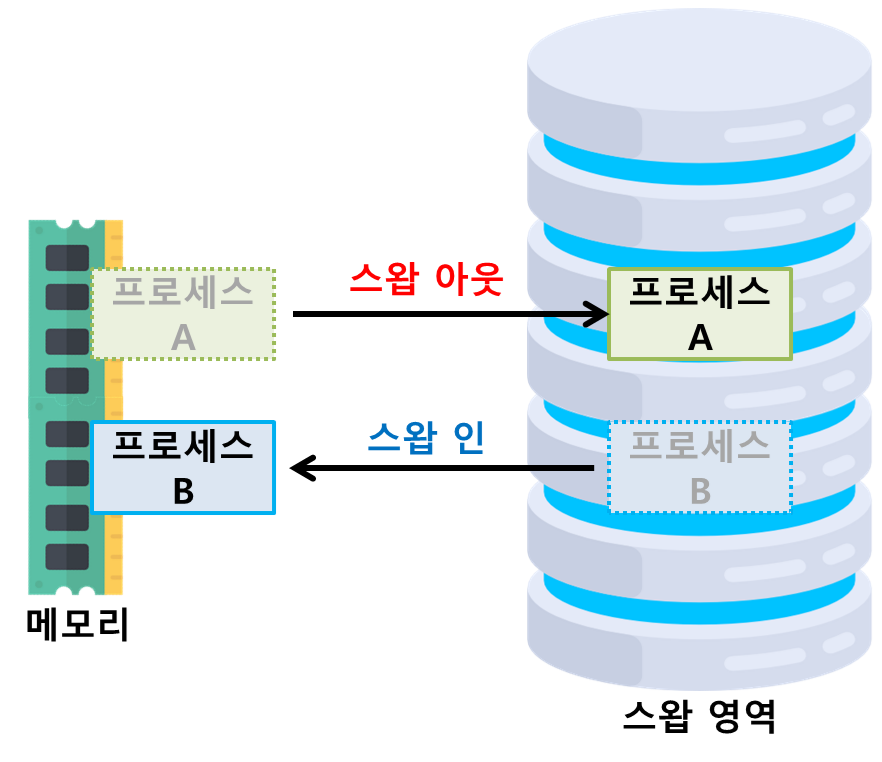
메모리 오버레이를 이용하면 메모리보다 큰 프로그램을 실행할 수 있지만 문제가 있다.
프로그램을 모듈로 나누었을 때, 메모리에 올라가있지 않은 모듈은 어디에 보관해야 할까?
다시 사용할지도 모르고 아직 작업이 끝나지 않았기 때문에 이를 보조 저장장치에(하드디스크) 보관해야 한다.
이처럼 메모리가 모자라서 쫓겨난 프로세스는 저장장치의 특별한 공간에 모아두는데
이러한 영역을 스왑 영역(swap area)라고 한다.
스왑 영역에서 메모리로 데이터를 가져오는 작업을 스왑인
메모리에서 스왑 영역으로 데이터를 보내는 작업을 스왑아웃
이라고 한다.
스왑 영역도 메모리 관리자가 관리한다. 원래 하드디스크 같은 저장장치는 저장장치 관리자가 관리하지만,
스왑 영역은 메모리에서 쫓겨났다가 다시 돌아가는 데이터가 머무는 곳이기 때문에
저장장치는 장소만 빌려주고, 메모리 관리자가 관리하는것이다.
사용자의 실제 메모리의 크기와 스왑 영역의 크기를 합쳐서 전체 메모리로 인식하고 사용할 수 있다.
물론 메모리 크기 > 메모리 + 스왑영역 크기 인 상태에서 메모리 단일 크기가 큰 쪽이 속도는 더 빠르지만
실제 메모리 크기에 상관없이 큰 프로그램을 실행할 수 있는 것이다.
메모리 분할 방식
메모리를 어떤 크기로 나눌 것인가는 메모리 배치 정책에 해당하는데 2가지 방법이 있다.
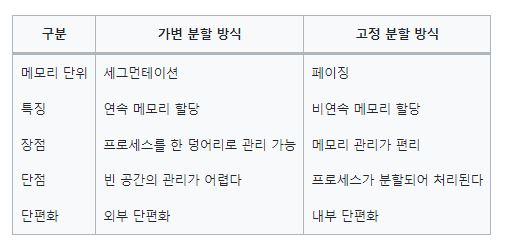
- 가변 분할 방식 : 프로세스의 크기에 따라 메모리를 나누는 것, 세그먼테이션 기법
- 하나의 프로세스를 연속 공간에 배치한다. (연속 메모리 할당)
- 메모리 관리가 복잡하다.
- 외부 단편화가 발생한다. (메모리 여유 공간이 프로세스 크기 보다 작아 프로세스가 주소 할당 못받음)
- 고정 분할 방식 : 프로세스의 크기와 상관 없이, 메모리를 같은 크기로 나누는 것, 페이징 기법
- 메모리를 일정한 크기로 나누어 관리해 메모리 관리가 수월하다.
- 내부 단편화가 발생한다. (프로세스 크기가 메모리 고정 크기보다 작아서, 메모리에 공간이 남는 것)
현대 운영체제에서 메모리 관리는 기본적으로 고정 분할 방식을 사용하면서
일부분은 가변 분할 방식을 혼합하고 있다.
참조한 책 및 사이트
쉽게 배우는 운영체제
https://velog.io/@chappi/OS%EB%8A%94-%ED%95%A0%EA%BB%80%EB%8D%B0-%ED%95%B5%EC%8B%AC%EB%A7%8C-%ED%95%A9%EB%8B%88%EB%8B%A4.-13%ED%8E%B8-%EA%B0%80%EB%B3%80-%EB%B6%84%ED%95%A0-%EB%A9%94%EB%AA%A8%EB%A6%AC%EC%99%80-%EA%B3%A0%EC%A0%95-%EB%B6%84%ED%95%A0-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EB%8B%A8%ED%8E%B8%ED%99%94