📌 Summary
- RDS의 스냅샷에서 특정 데이터를 손쉽게 확인할 수 있습니다.
- Athena 를 이용하여 RDS 인스턴스 복원 과정 없이 데이터를 확인할 수 있습니다.
📌 Architecture
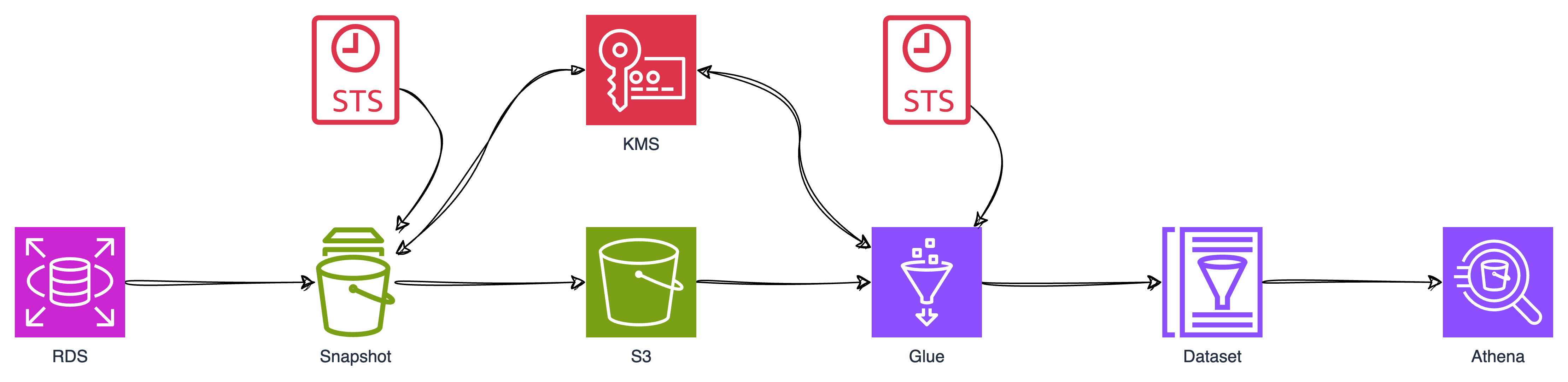
📌 Why RDS to Athena?
기존에는 스냅샷에 있는 데이터를 확인할 때마다 인스턴스를 복원하고 내부에 접속하는 불편한 과정으로 데이터를 확인하였습니다.
이번에는 훨씬 간편하게 RDS 스냅샷에 저장된 데이터를 쿼리하는 방법을 소개하고자 합니다.

본 포스팅에서는 AWS RDS 스냅샷을 가져와 S3 버킷으로 내보내는 과정과, 내보낸 데이터를 쿼리하고 분석하는데에 Athena를 사용하는 방법에 대해 알아보겠습니다. Athena는 서버리스 쿼리 서비스로, SQL을 사용하여 S3에 저장된 데이터를 즉시 분석할 수 있게 해줍니다.
Amazon Athena란 무엇인가요? - docs
Amazon Athena는 표준 SQL을 사용하여 Amazon S3(Amazon Simple Storage Service)에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스입니다. AWS Management Console에서 몇 가지 작업을 수행하면 Athena에서 Amazon S3에 저장된 데이터를 지정하고 표준 SQL을 사용하여 임시 쿼리를 실행하여 몇 초 안에 결과를 얻을 수 있습니다.
📌 Setup
👉 Step 00. KMS 생성
RDS Snapshot을 S3로 보내기 위해서는 고객 관리형 키가 필요합니다.
KMS 서비스에서 고객 관리형 키 항목에서 키 생성을 시작합니다.
- 키 유형 - 대칭
- 키 사용 - 암호화 및 해독
으로 선택하고 다음을 클릭합니다.
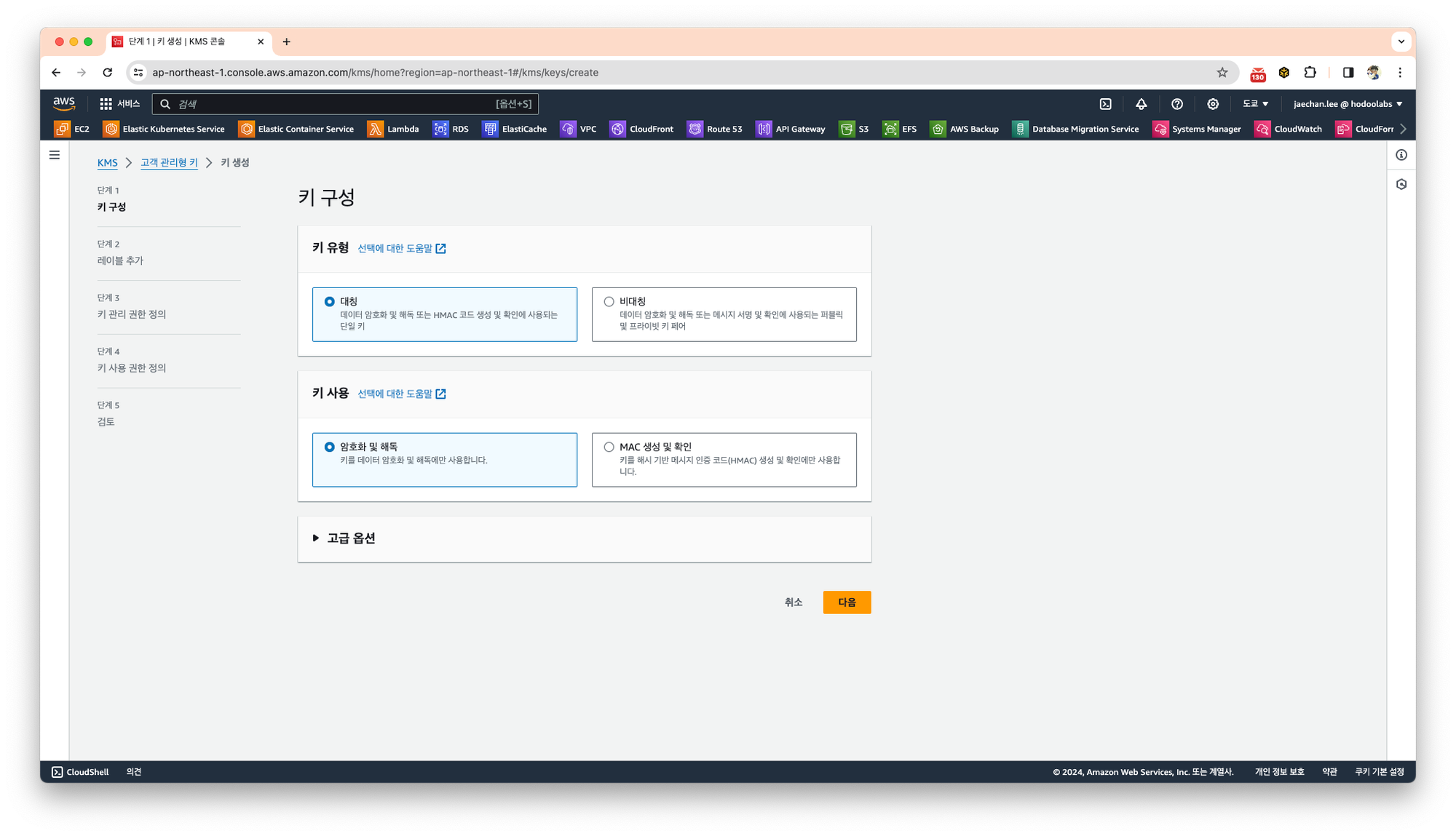
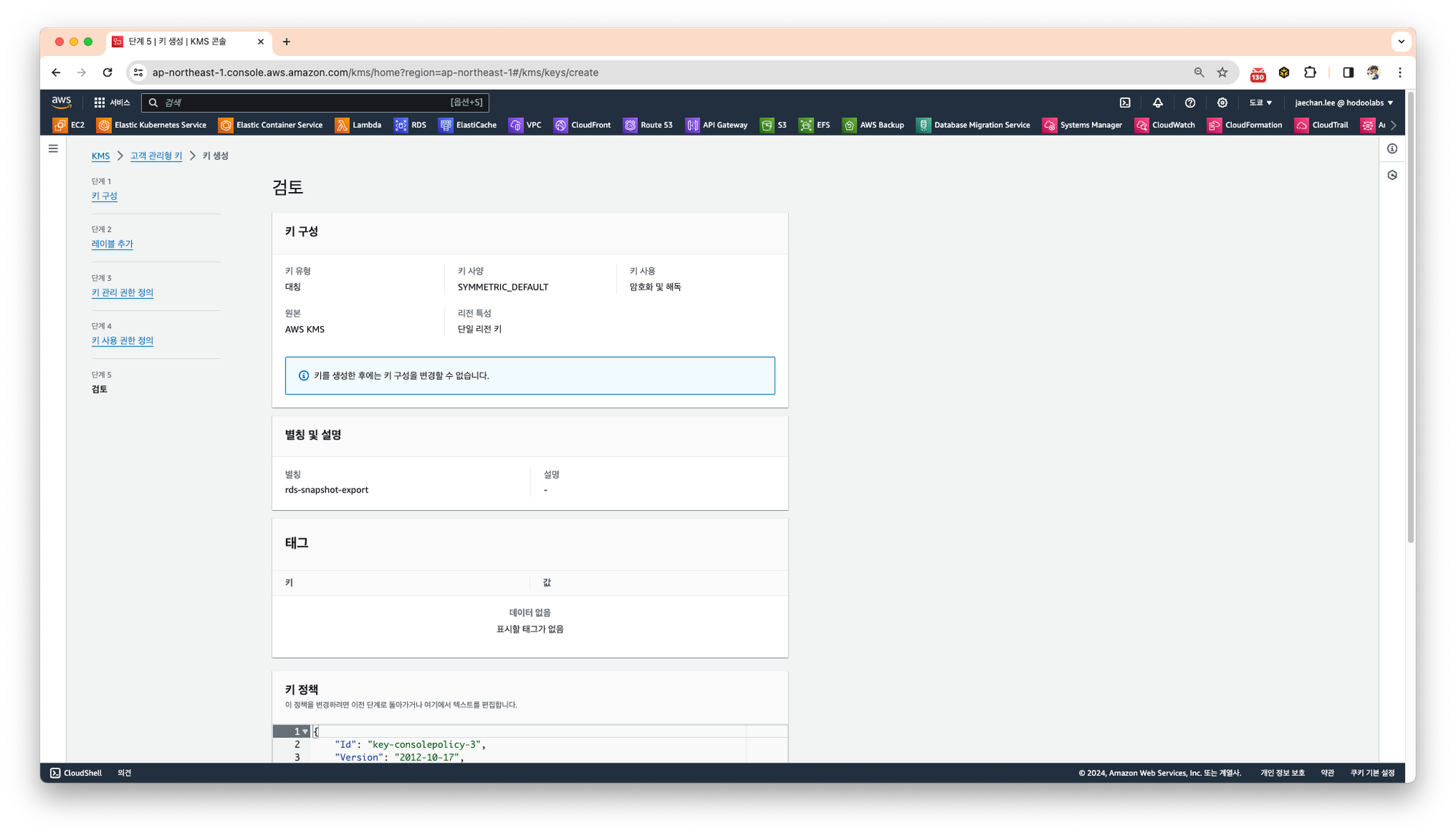
생성될 키에 대한 정보를 입력합니다.
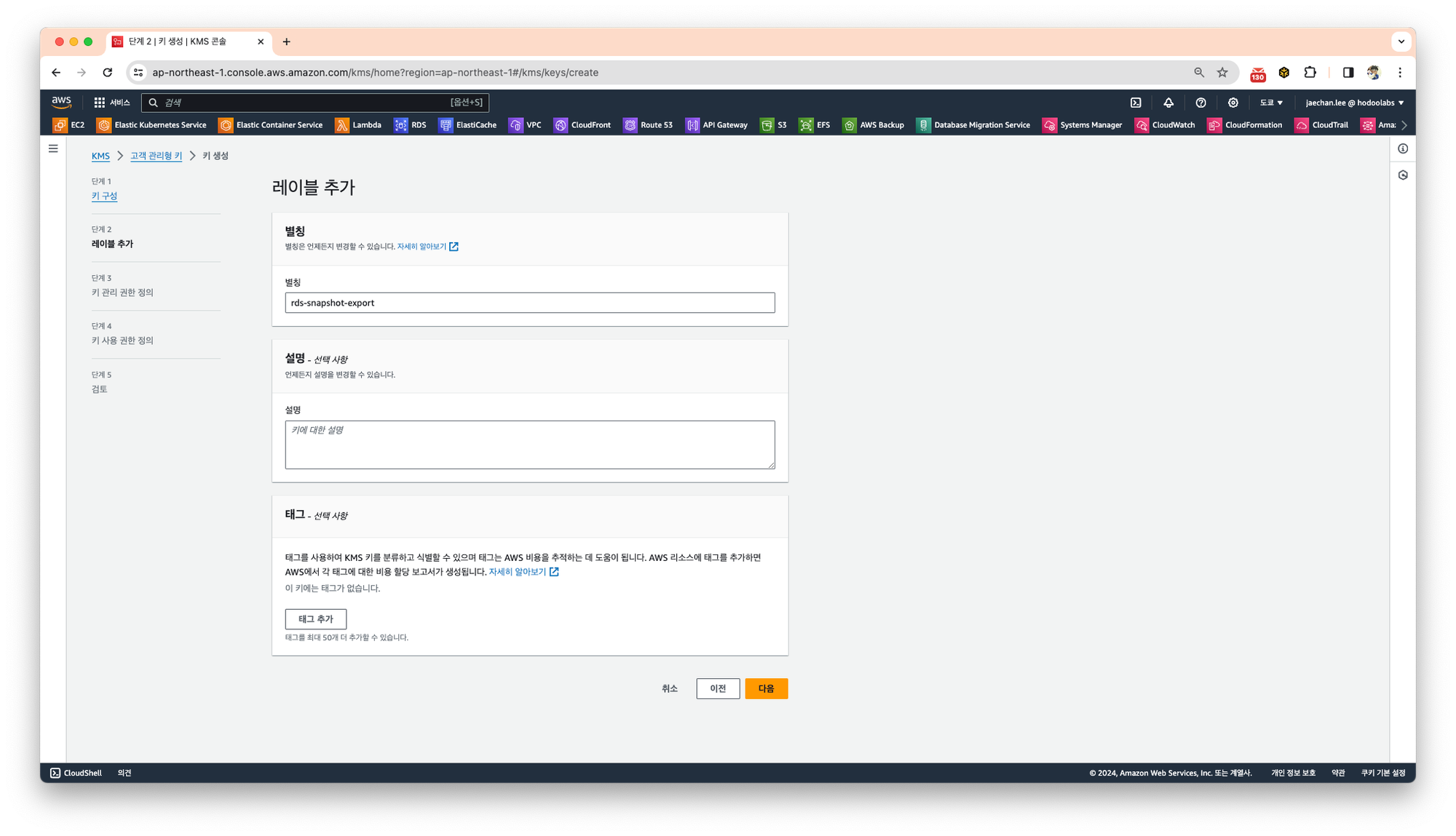
키 관리를 위한 권한을 정의합니다.
별도로 선택하지 않고 다음을 클릭합니다.
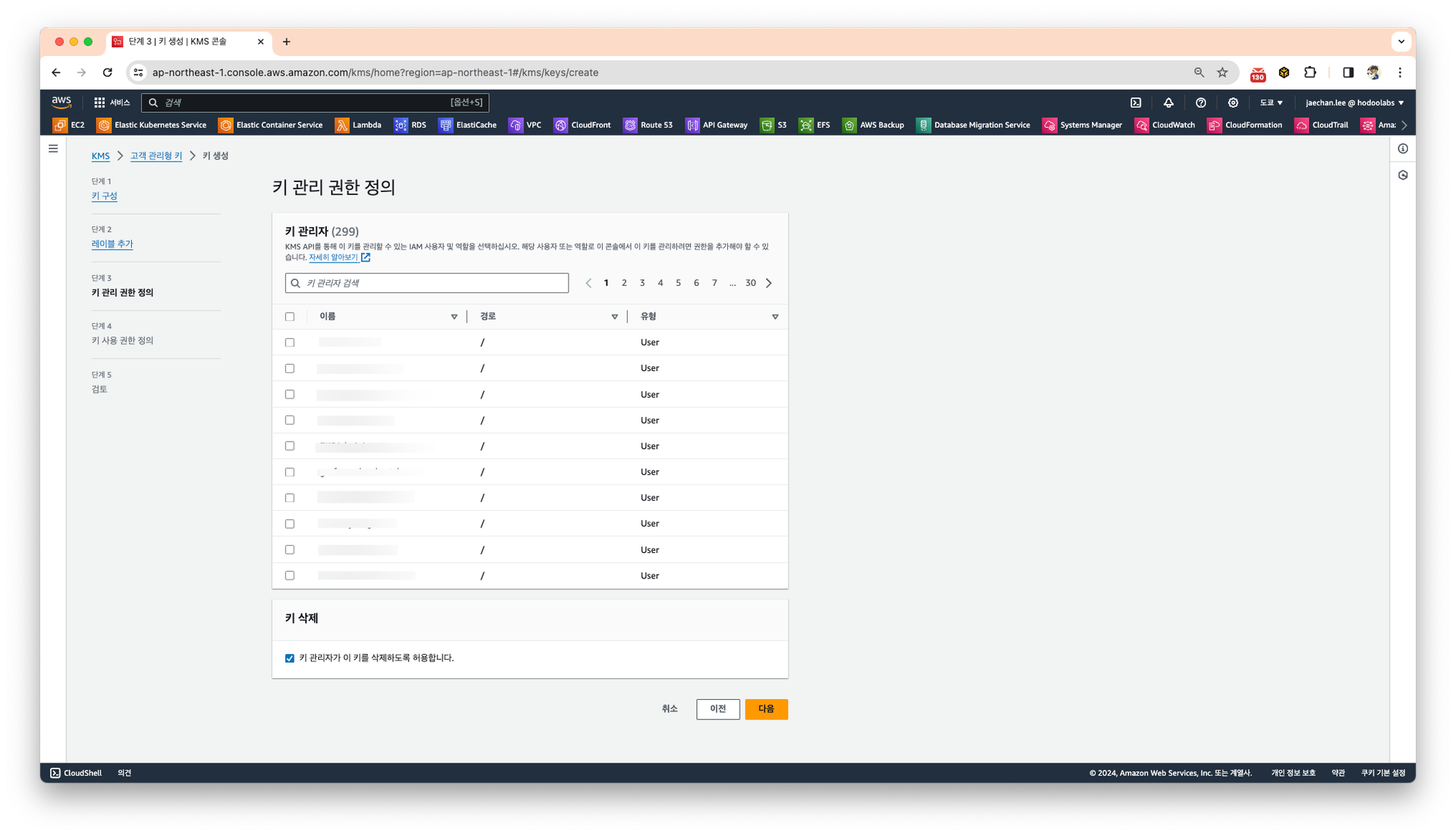
키 사용 권한을 정의합니다.
이 과정에서도 별도의 사용자를 선택하지 않겠습니다. 다음을 선택합니다.
설정이 완료되었다면 검토를 완료하고 키를 생성합니다.
👉 Step 01. RDS Snapshot export S3
✅ IAM
Snapshot에서 사용할 서비스 역할 생성하기
DB 스냅샷 데이터를 Amazon S3로 내보내는 작업에 Amazon S3 버킷에 대한 쓰기-액세스 권한이 필요합니다.
역할을 생성하는 방법에는 두가지가 있습니다.
AWS IAM에 익숙하지 않다면 콘솔에서 새 역할 생성 기능을 사용하여 자동으로 생성된 역할을 바로 사용해도 무방합니다.
콘솔에서 역할 생성
IAM 역할 탭에서 새 역할을 손쉽게 생성할 수 있습니다.
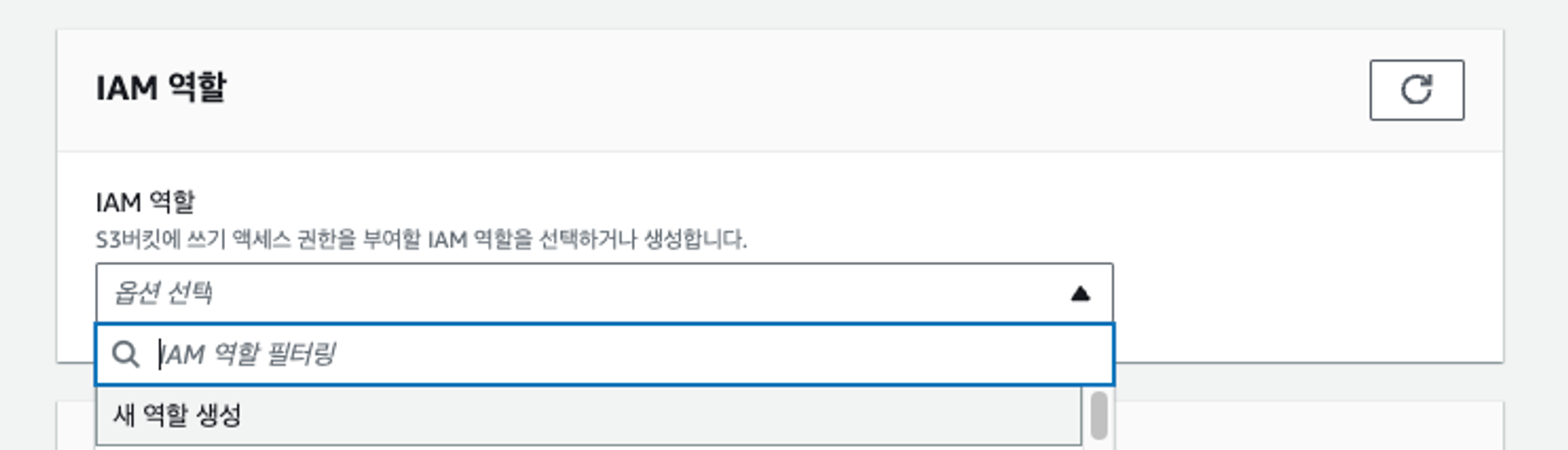
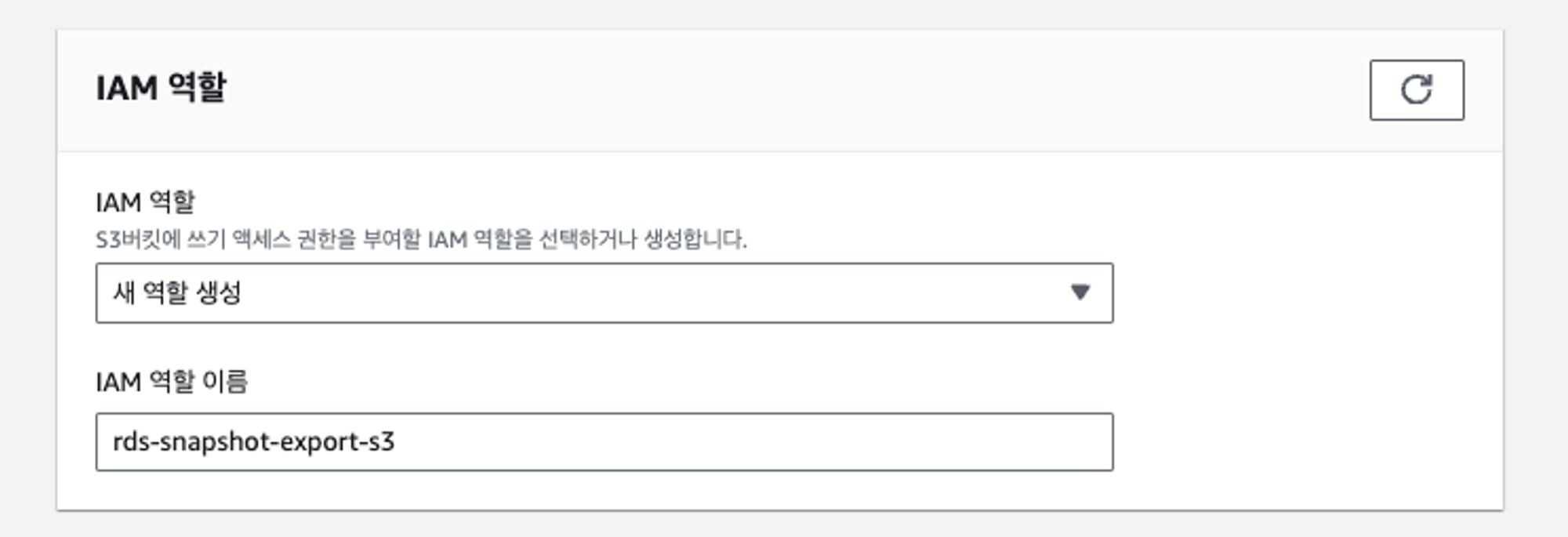
관리자가 역할을 직접 생성
IAM을 직접 생성하는 과정을 설명합니다.
S3에 접근할 수 있는 권한이 필요합니다.
IAM 정책을 생성합니다.
정책에서 Amazon RDS에서 S3 버킷으로의 파일 전송을 허용하려면 다음과 같은 필수 작업을 포함시킵니다.
s3:PutObject*s3:GetObject*s3:ListBuckets3:DeleteObject*s3:GetBucketLocation
정책에 다음 리소스를 포함하여 버킷에 있는 S3 버킷과 객체를 식별합니다. 다음 리소스 목록은 Amazon S3에 액세스하기 위한 Amazon 리소스 이름(ARN) 형식을 보여 줍니다.
arn:aws:s3:::*your-s3-bucket*arn:aws:s3:::*your-s3-bucket*/*
aws iam create-policy --policy-name ExportPolicy --policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ExportPolicy",
"Effect": "Allow",
"Action": [
"s3:PutObject*",
"s3:ListBucket",
"s3:GetObject*",
"s3:DeleteObject*",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::your-s3-bucket",
"arn:aws:s3:::your-s3-bucket/*"
]
}
]
}'Amazon RDS가 사용자 대신 이 IAM 역할을 수임하여 Amazon S3 버킷에 액세스할 수 있도록 IAM 역할을 생성합니다.
AWS CLI 명령을 사용해 rds-snapshot-export-s3이라는 역할을 생성합니다.
aws iam create-role --role-name rds-snapshot-export-s3 --assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'생성한 IAM 역할에 생성한 IAM 정책을 연결합니다.
aws iam attach-role-policy --policy-arn your-policy-arn --role-name rds-snapshot-export-s3Amazon RDS에서 스냅샷 탭에서 복원하고자 하는 스냅샷을 선택하고 Amazon S3로 내보내기를 선택합니다.
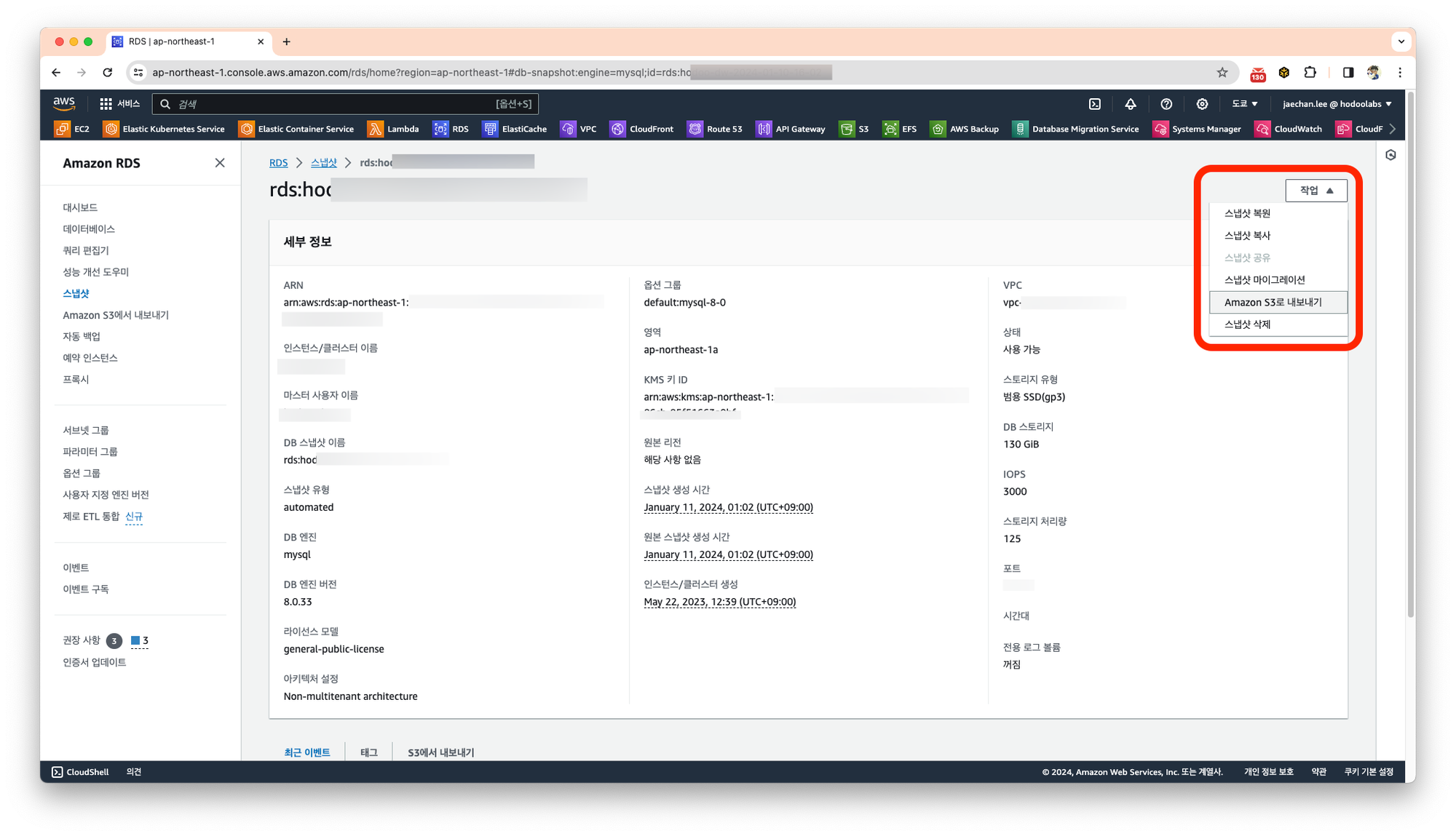
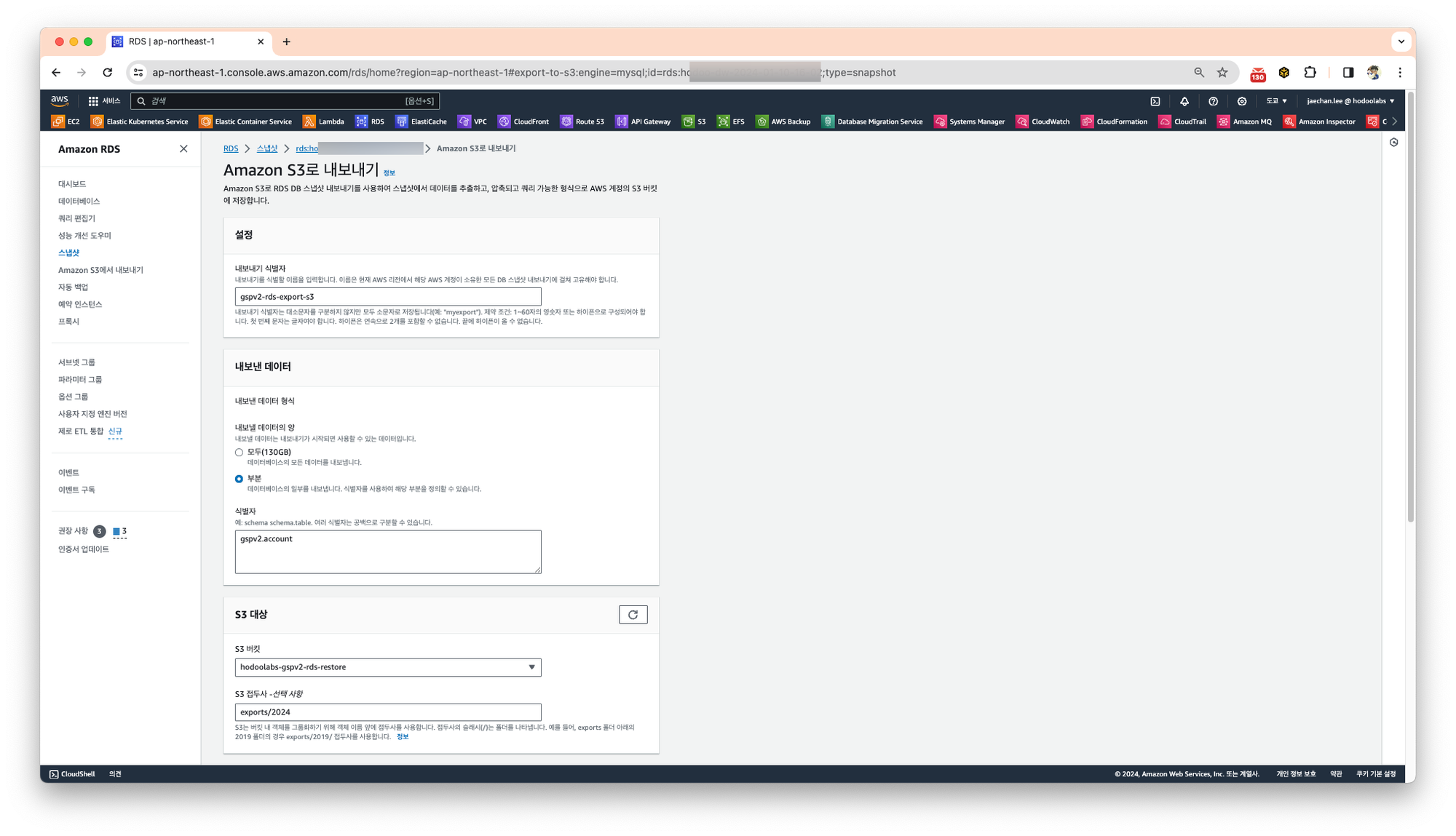
Amazon S3로 내보내기 항목에서 내보내기를 위한 식별자를 입력하고, 내보내고자 하는 데이터를 선택합니다.
모든 데이터를 추출할수 있고, 원하는 내용만 선택할 수 있습니다.
원하는 내용은
Schema.table 과 같이 .(dot)과 스페이스 구분자로 지정합니다.
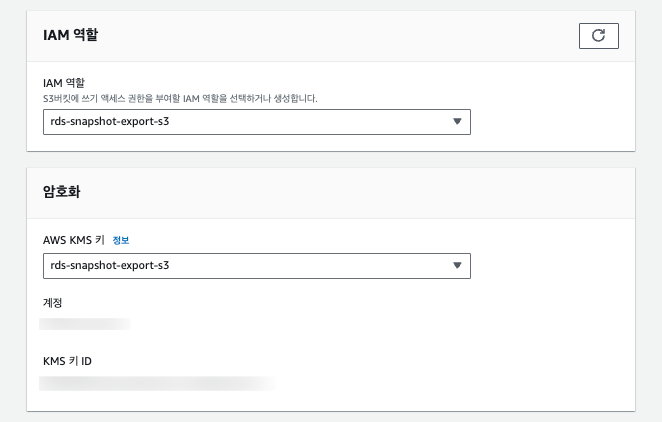
위에서 생성한 IAM 역할 및 AWS KMS 키를 입력하고 내보내기를 실행합니다.
👉 Step 02. Glue Crawler
AWS Glue Crawler는 AWS Glue 서비스의 핵심 구성 요소 중 하나로, 다양한 데이터 스토어에서 데이터를 자동으로 검색하고 메타데이터를 생성합니다. 이를 통해 데이터를 AWS Glue의 카탈로그에 등록하고 분석 및 쿼리에 활용할 수 있습니다.
데이터베이스를 생성합니다.
AWS Glue Data Catalog의 데이터베이스는 AWS Glue 서비스에서 데이터 스키마와 메타데이터 정보를 유지하고 저장하는 역할을 담당합니다.
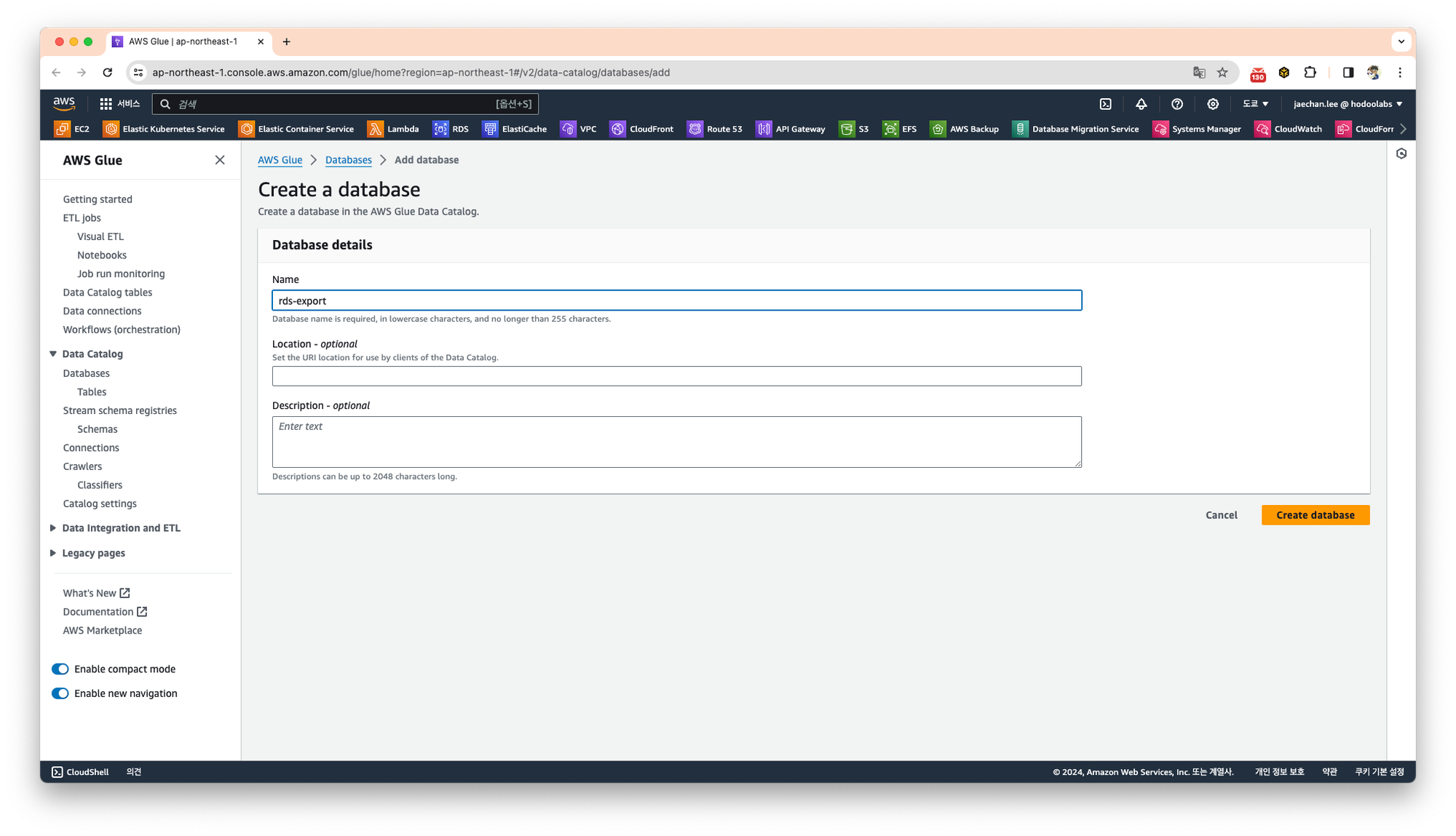
이 과정에서 중요한 점은 데이터 크롤링을 위한 크롤러 생성을 반드시 Data Catalog/Tables 항목에서 Add Tables using crawler 를 사용해서 생성합니다.

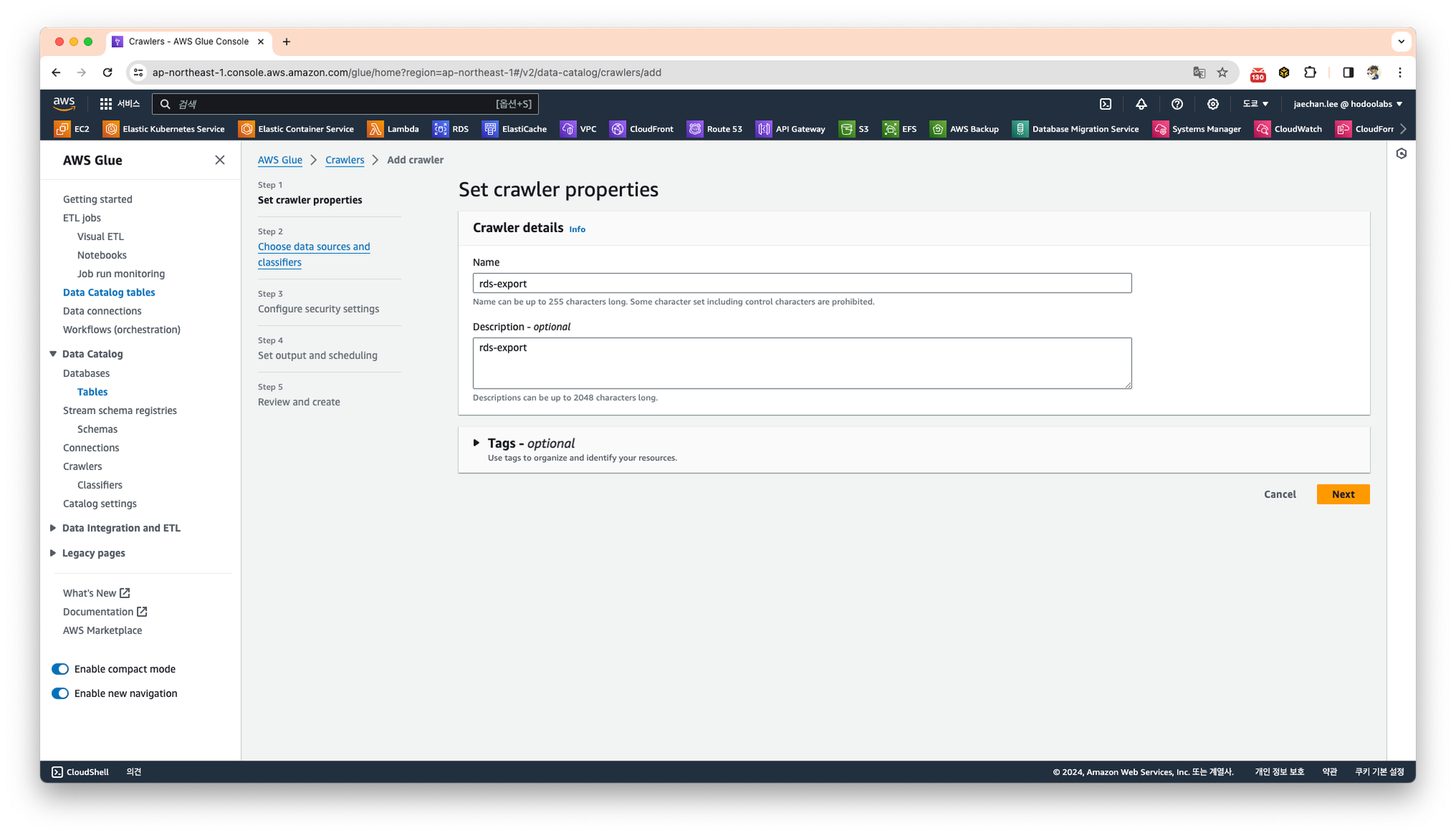
크롤러에 대한 이름과 설명을 작성합니다.
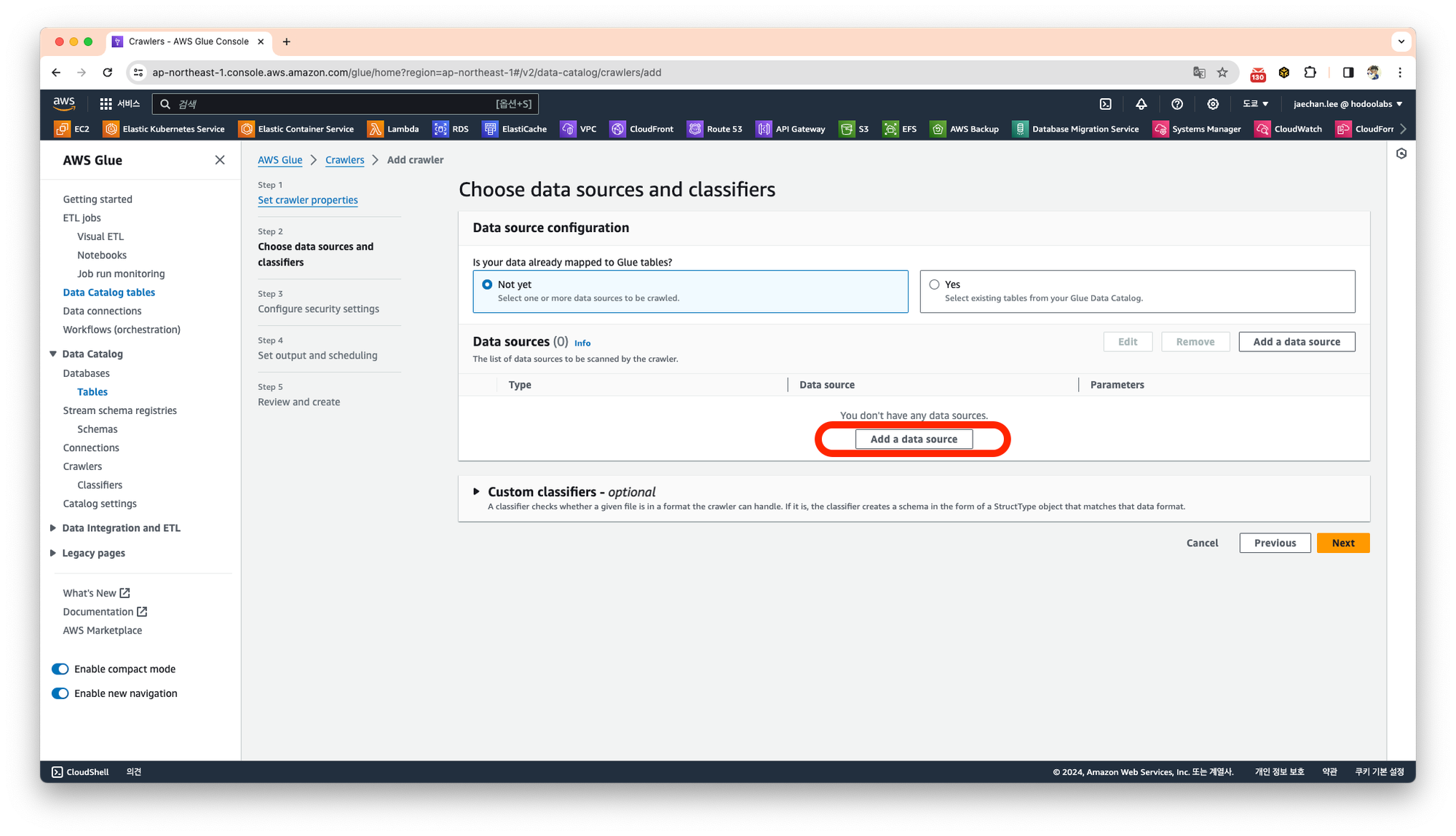
Add a data source 탭을 눌러 데이터소스를 설정합니다.
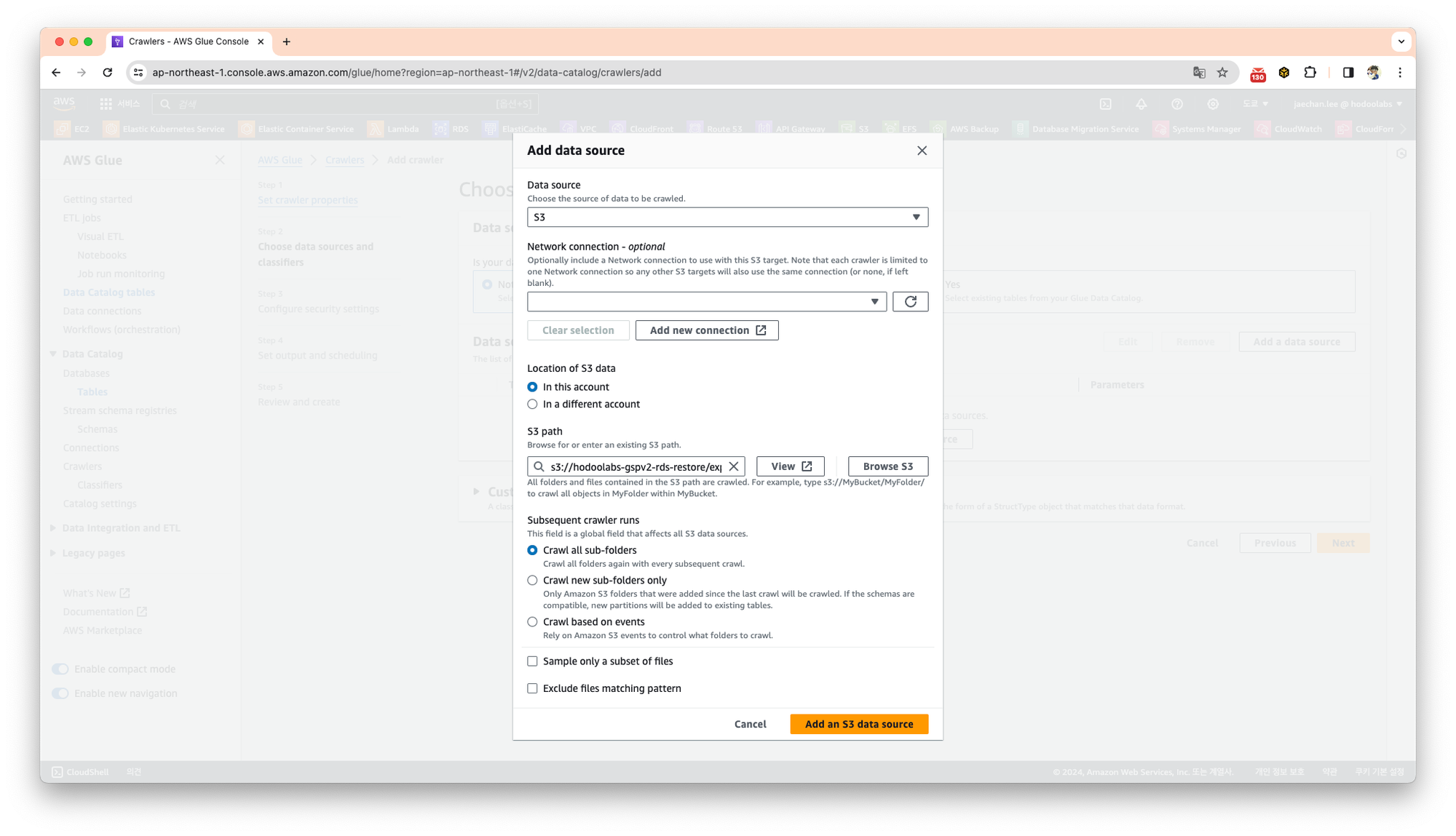
- Data Source - s3
- S3 Path - 스냅샷이 저장된 S3의 경로를 입력합니다.
✅ IAM
Glue Crawler에서 사용할 서비스 역할을 생성합니다.
콘솔에서 역할 생성
크롤러 생성과정에서 Create new IAM role 탭으로 역할을 생성합니다.
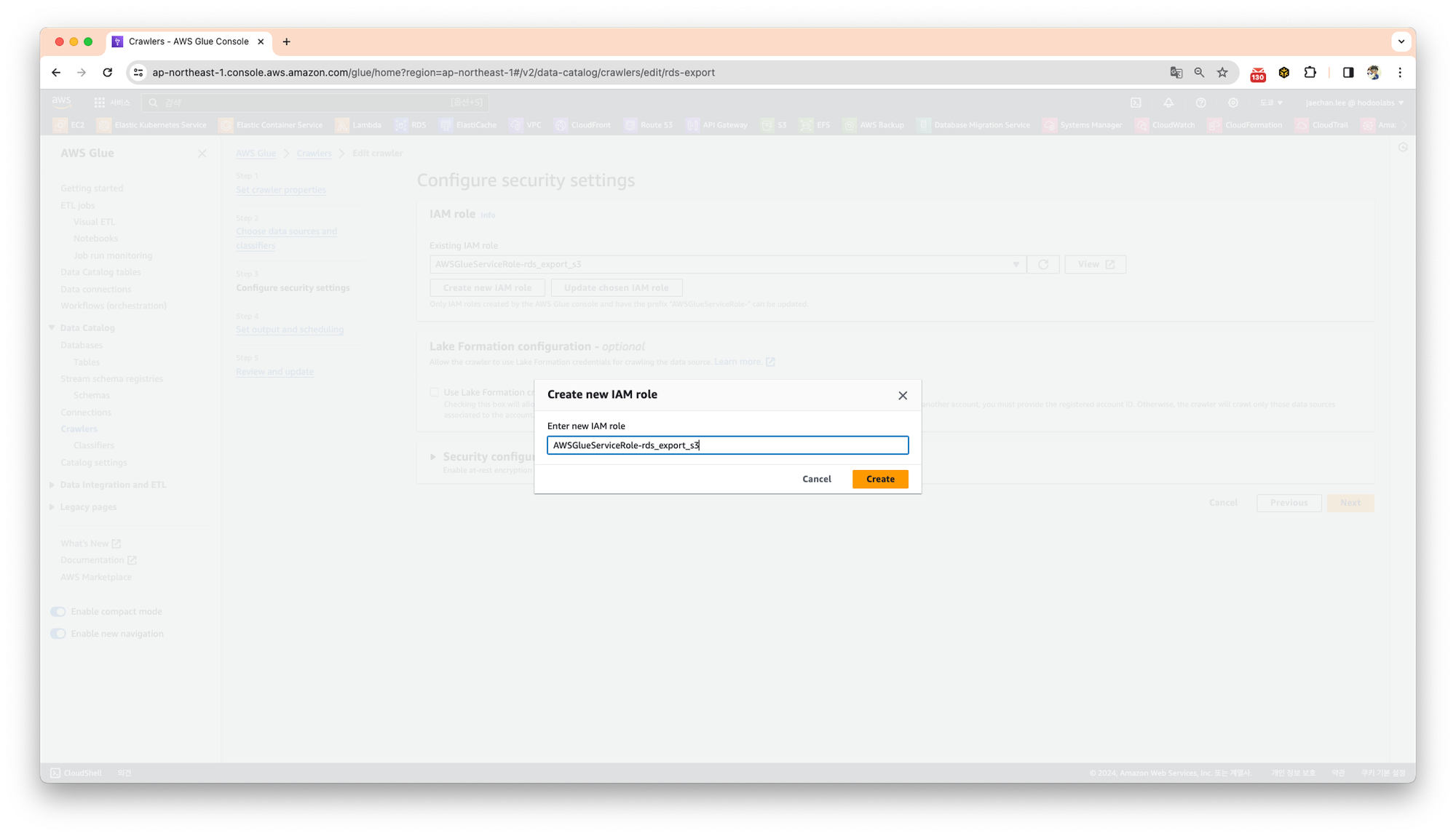

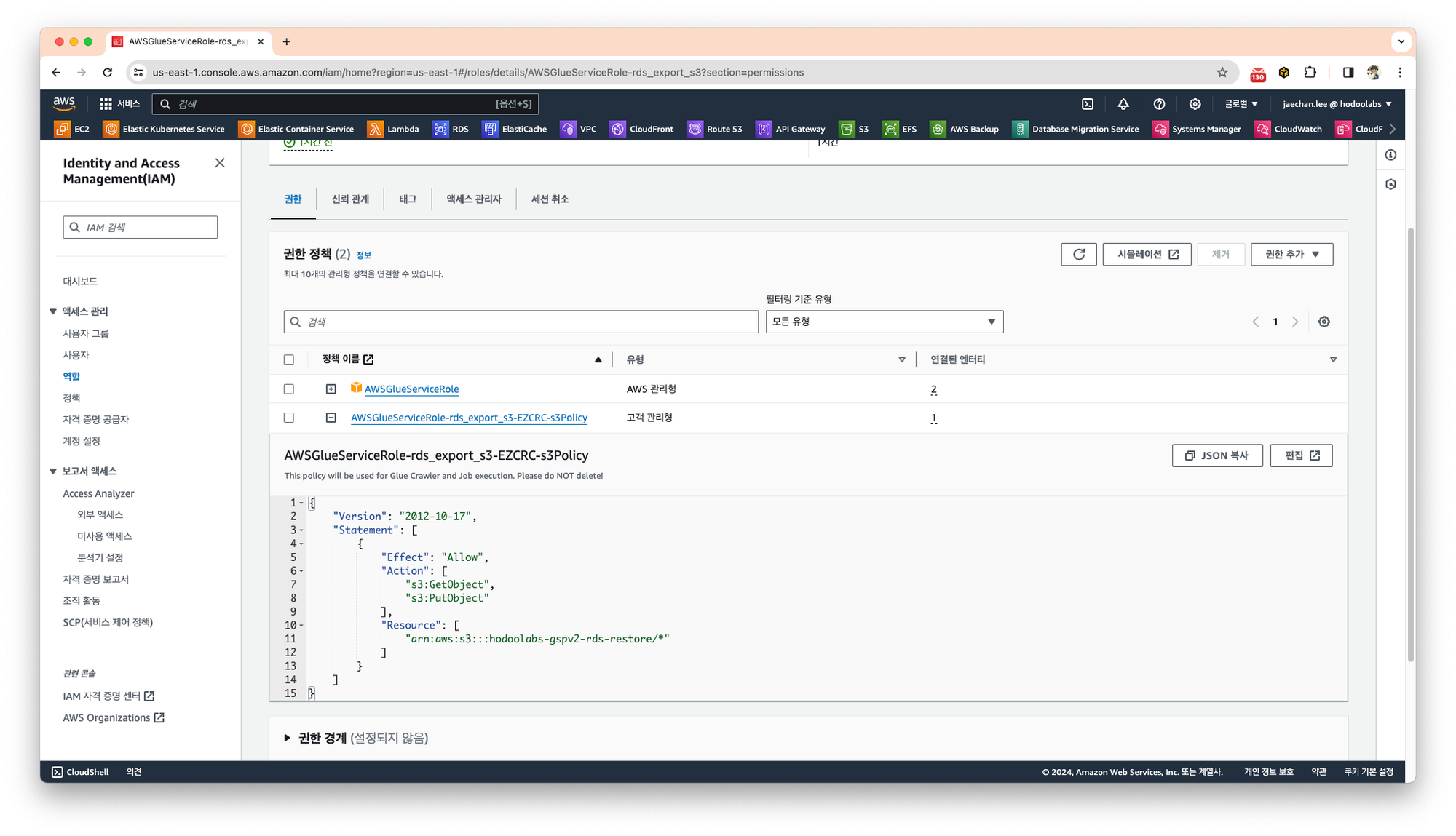
생성된 IAM의 권한은
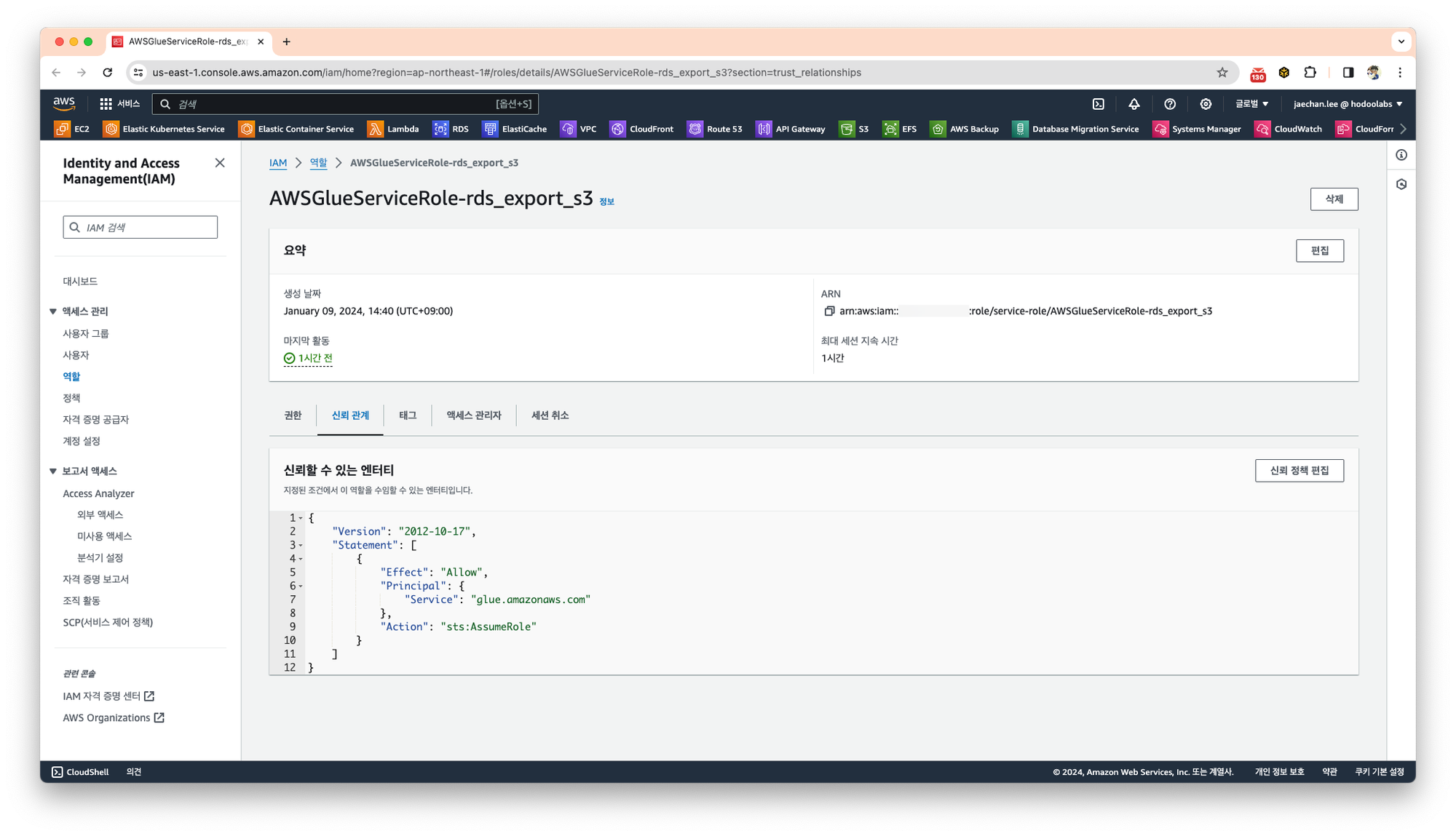
S3에 접근하기 위한 권한과 glue와의 신뢰관계로 설정되어 생성되는것을 확인할 수 있습니다.
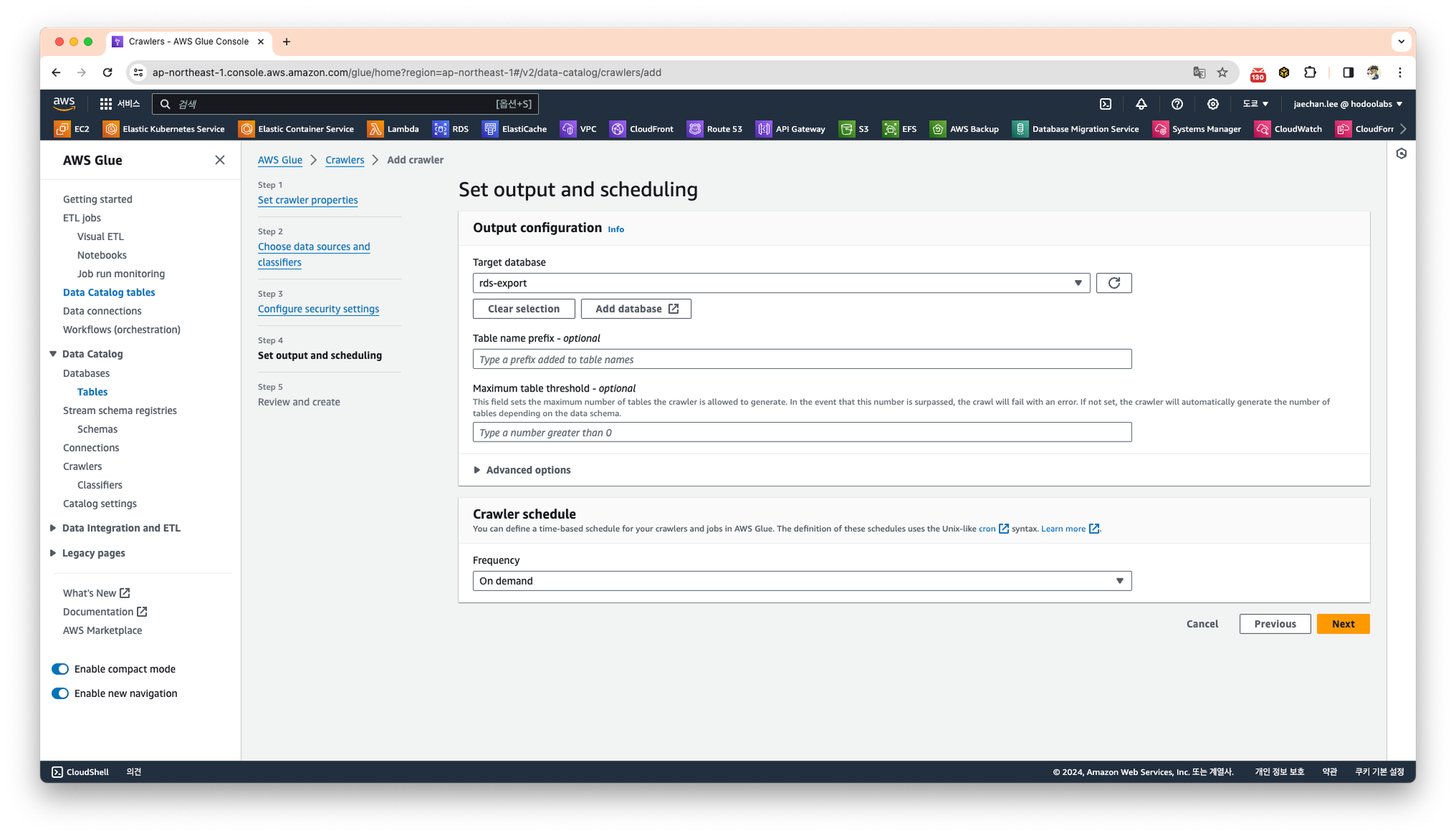
크롤링이 완료된 내용을 출력하고, 스케쥴링 하기위한 설정 입니다.
스케쥴링은 수동으로 트리거 할 예정이므로 On-demand를 선택하고 Next를 클릭합니다.
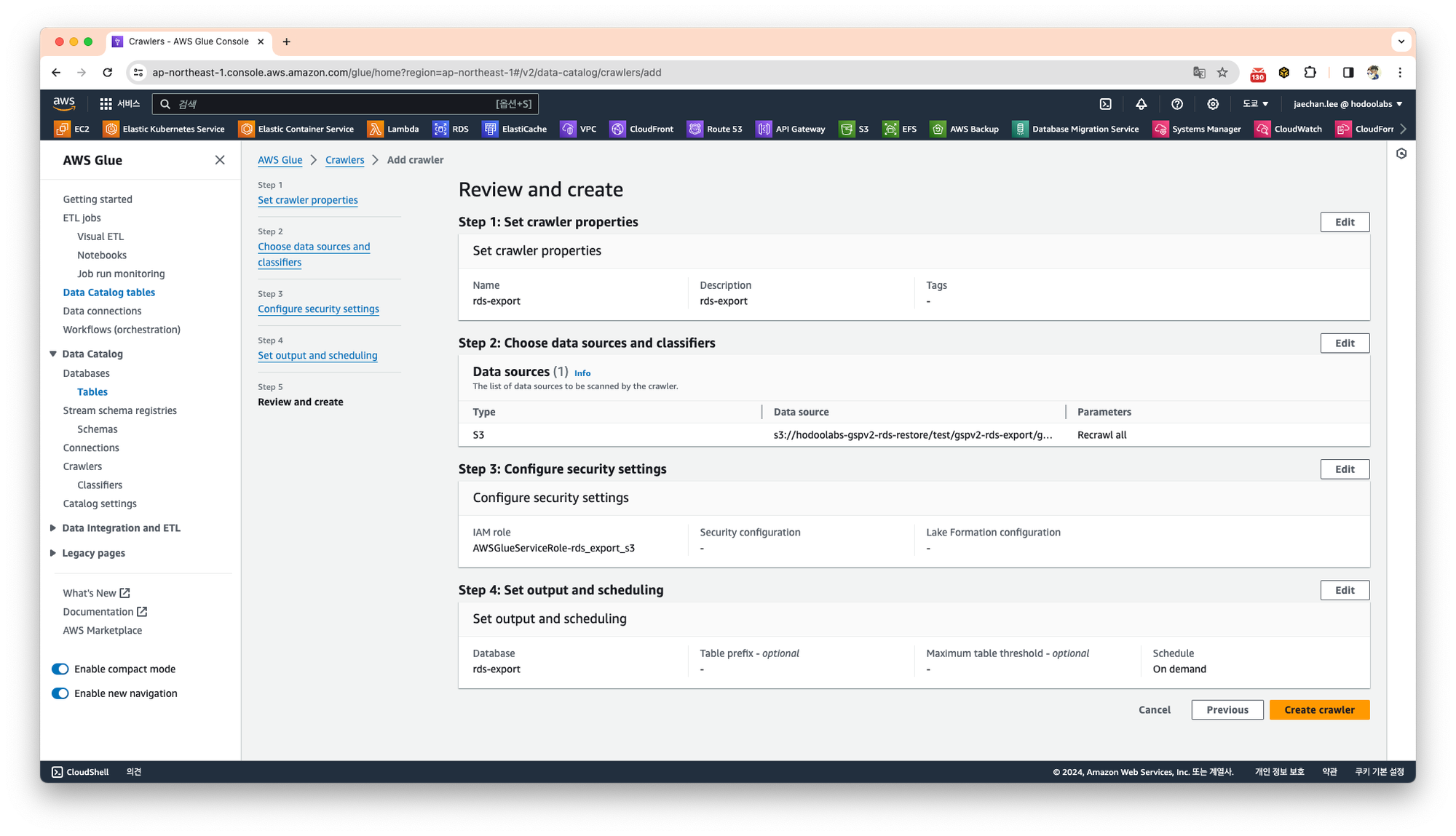
최종적으로 설정값을 확인한 후 Create crawler를 선택하여 크롤러를 생성합니다.
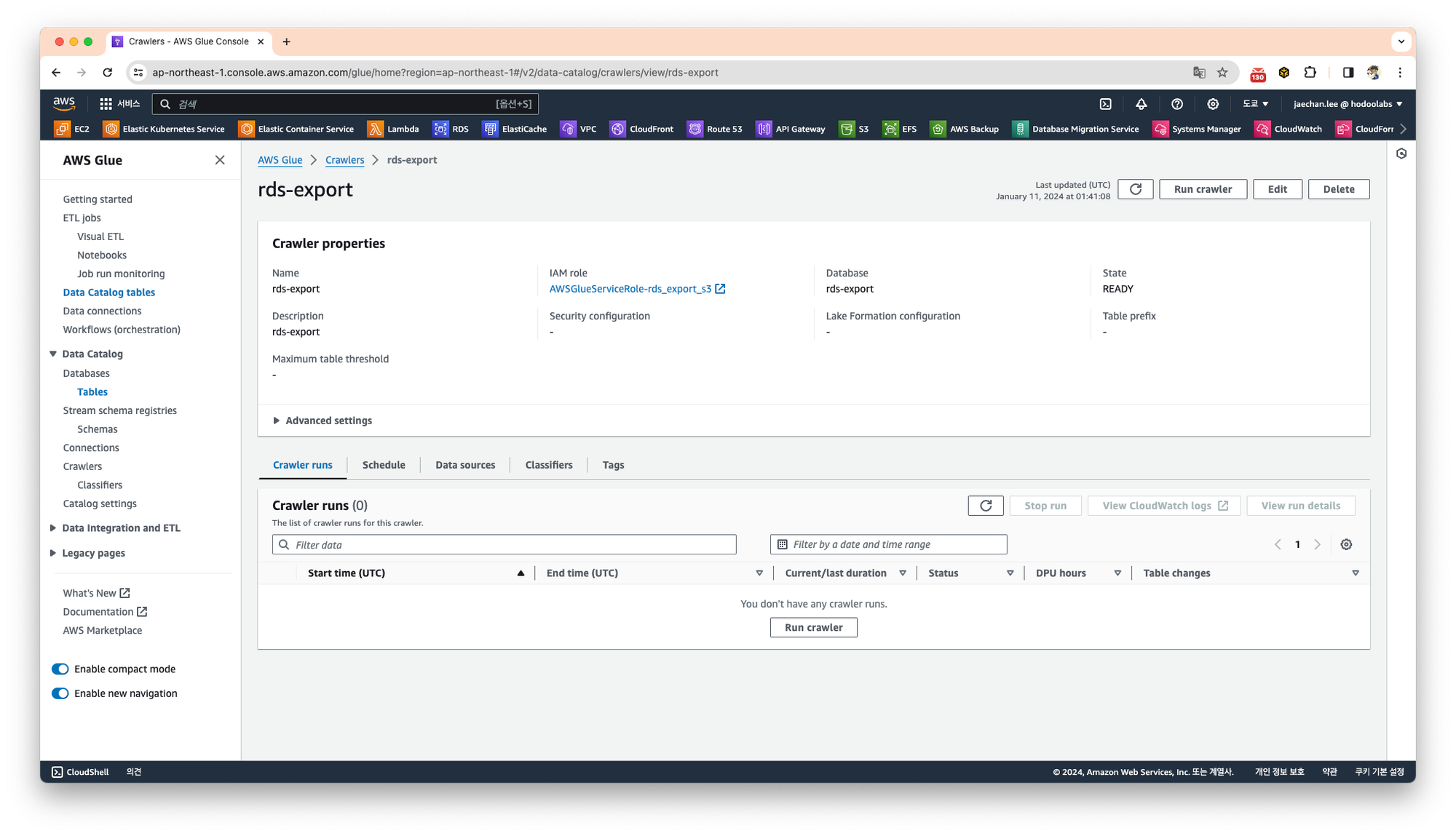
크롤러가 정상적으로 생성되었다면, Run crawler를 클릭하여 크롤링을 시작합니다.
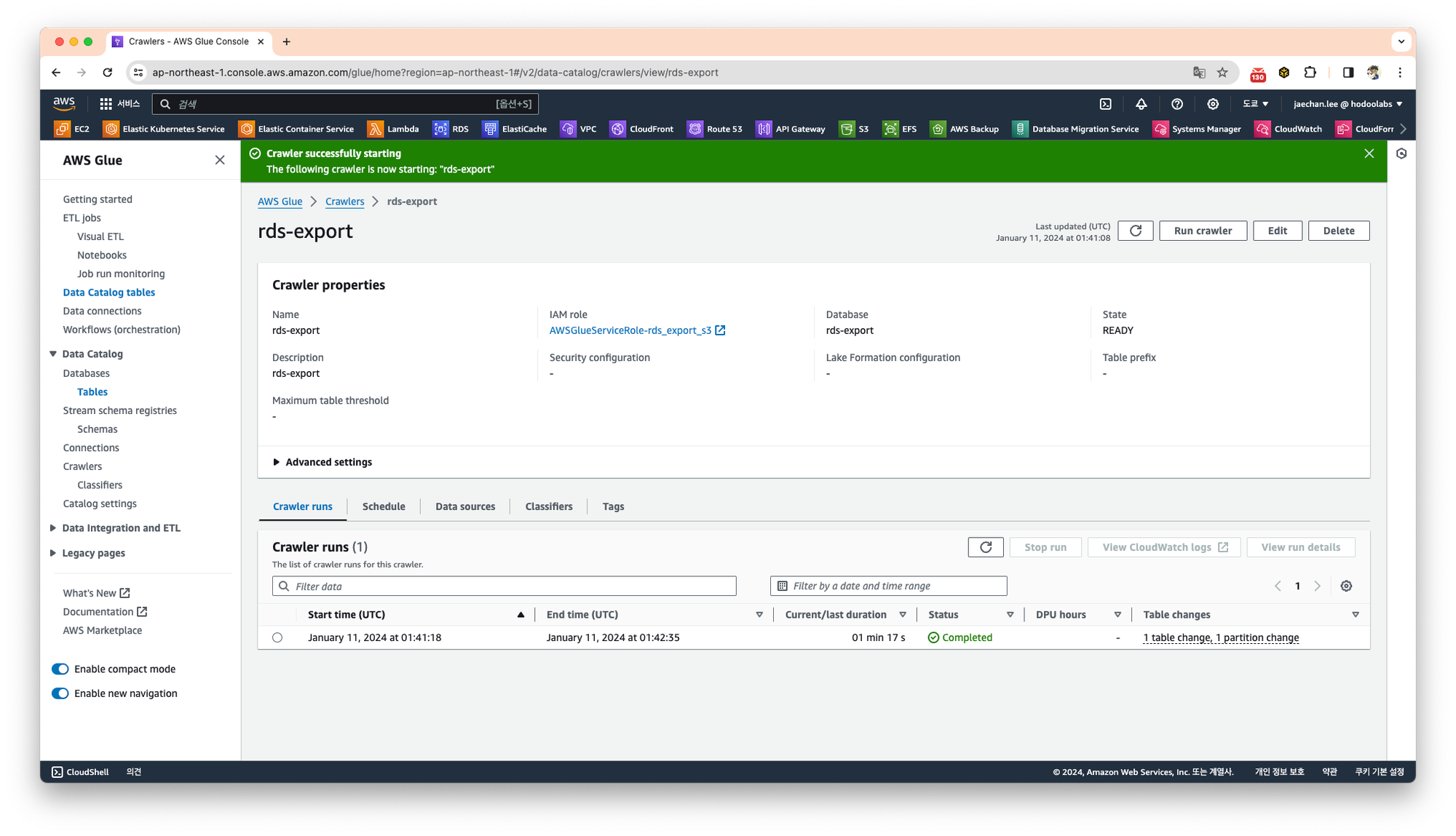
크롤링이 완료되면 아래와 같이 Table Changes에서 테이블이 자동으로 생성되는것을 확인할 수 있습니다.
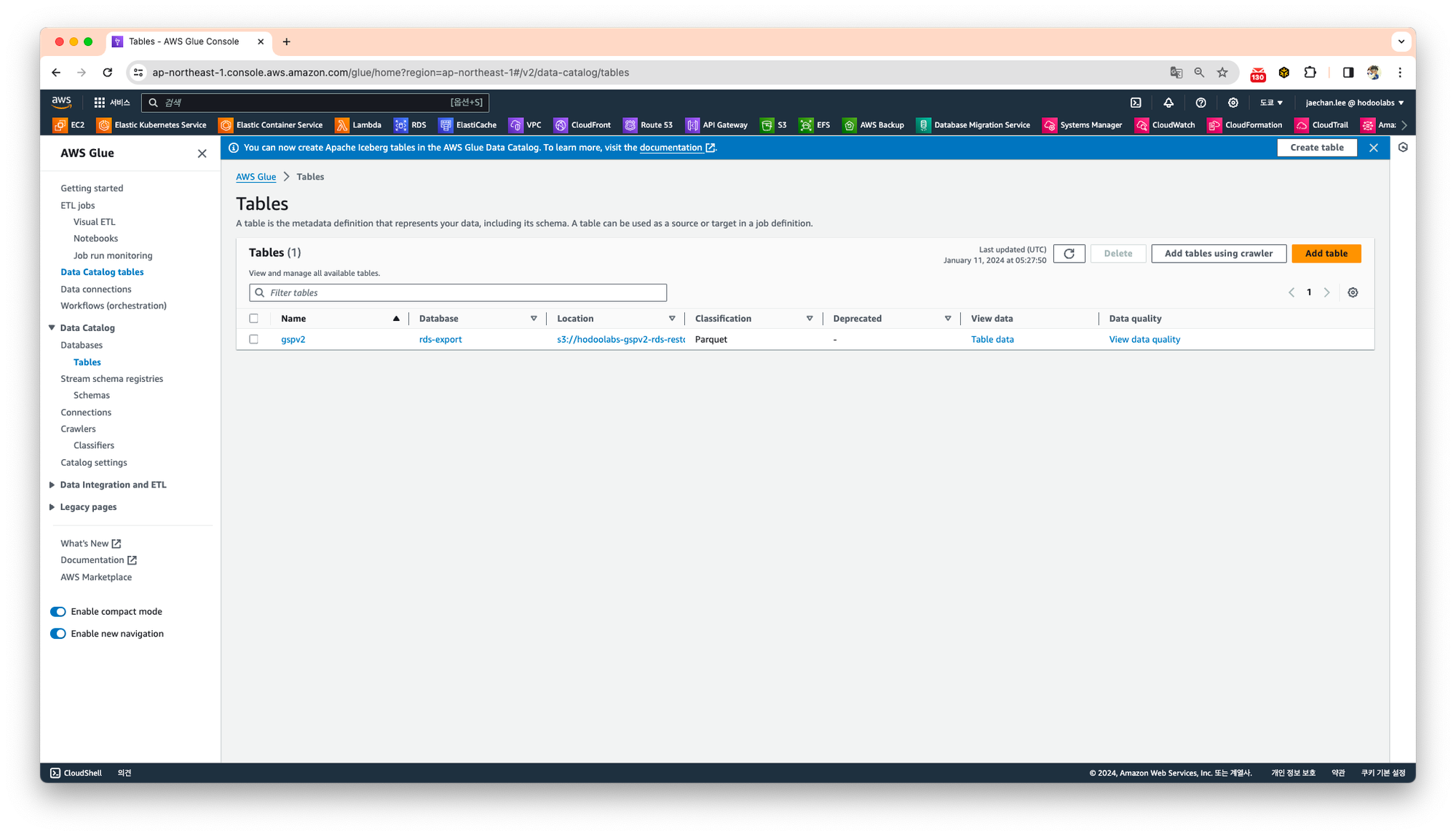
👉 Step 03. AWS Athena 데이터 확인
Tables 항목에서 생성된 테이블을 확인합니다.
View data의 탭을 이용하여 Athena로 바로 이동할 수 있습니다.
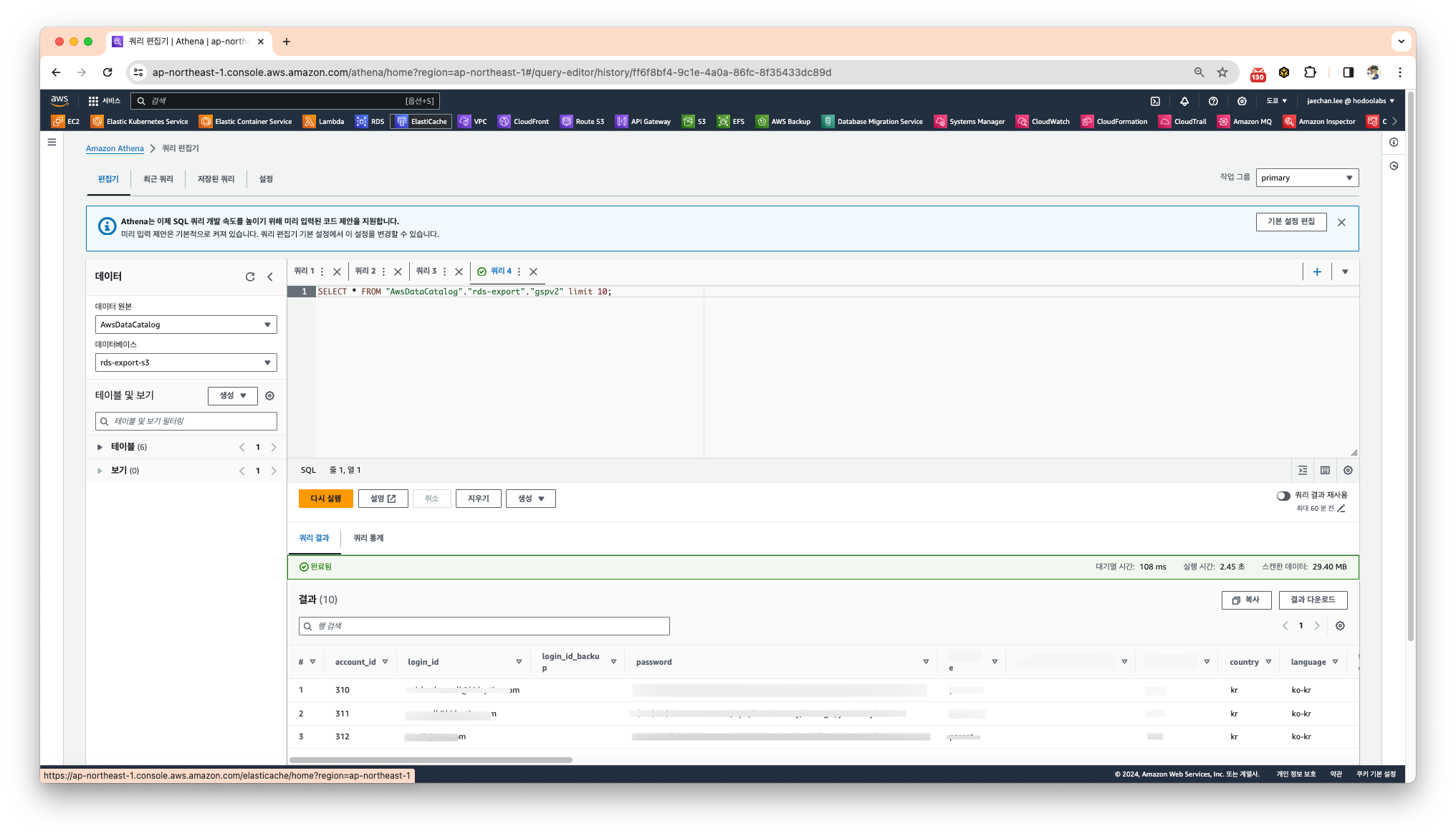
Proceed 를 통해 Athena로 이동하면 테이블 내용을 확인하기 위한 기본 쿼리가 세팅됩니다.
실행을 이용하여 결과 탭에 데이터가 출력되는것을 확인할 수 있습니다.
📌 Conclusion
이 블로그를 통해 AWS RDS 스냅샷을 S3로 내보내고 Athena로 데이터를 확인하는 과정에 대해 알아보았습니다. 기존의 불편한 인스턴스 복원 및 내부 접속 과정 없이, 클라우드의 강력한 서비스들을 활용하여 데이터를 효율적으로 관리하고 분석하는 방법을 소개했습니다.
불필요한 번거로움 없이 데이터를 쿼리하고 분석할 수 있는 새로운 경험을 얻을수 있었습니다. Amazon RDS, S3, Athena와 같은 서비스들은 뛰어난 편의성을 제공하는것 같습니다.
이번 글을 읽어주셔서 감사합니다. 더 궁금한 사항이나 추가적인 정보가 필요하시다면, 언제든지 댓글로 남겨주시면 감사하겠습니다.
🔗 Reference
