📌 Notice
Database Operator In Kubernetes study (=DOIK)
데이터베이스 오퍼레이터를 이용하여 쿠버네티스 환경에서 배포/운영하는 내용을 정리한 블로그입니다.
CloudNetaStudy그룹에서 스터디를 진행하고 있습니다.
Gasida님께 다시한번 🙇 감사드립니다.EKS 및 KOPS 관련 스터디 내용은 아래 링크를 통해 확인할 수 있습니다.
[AEWS] AWS EKS 스터디
[PKOS] KOPS를 이용한 AWS에 쿠버네티스 배포
📌 Review
쿠버네티스 스터디를 통해, ECS 환경의 인프라 구성을 EKS로 마이그레이션 하여 서비스를 운영하고 있습니다.
더 나아가 Kafka, Mysql, Redis 등등 컨테이너 환경에서 구동되지만 상태를 저장해야 하는 리소스들을 어떻게 관리할 수 있을지에 대한 기술을 습득하고자 스터디를 시작하였습니다.
 아직도 갈길이 멀다...
아직도 갈길이 멀다...
📌 Summary
-
AWS EKS를 직접 배포하고 사용해보며 동작원리 및 구성요소를 이해합니다.
-
데이터베이스 오퍼레이터를 이해하기 위해 반드시 알아야하는 쿠버네티스 관련 지식을 정리합니다.
📌 Study
이번 스터디는 EKS 환경이 중점이 아닌, 쿠버네티스에서 데이터베이스를 운영하기 위해 필요한 내용을 중점으로 스터디 하였습니다.
👉 Step 01. Amazon EKS 소개
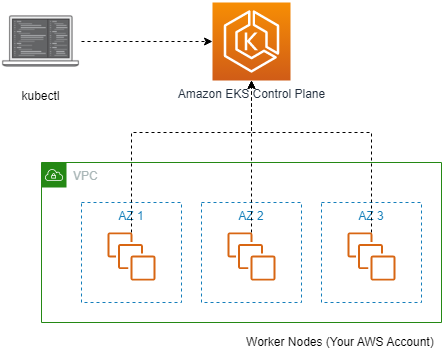
✅ AWS EKS 란?
Amazon EKS 는 Kubernetes를 쉽게 실행할 수 있는 관리형 서비스입니다. Amazon EKS를 사용하시면 AWS 환경에서 Kubernetes 컨트롤 플레인 또는 노드를 직접 설치, 운영 및 유지할 필요가 없습니다.
Amazon EKS는 여러 가용 영역에서 Kubernetes 컨트롤 플레인 인스턴스를 실행하여 고가용성을 보장합니다. 또한, 비정상 컨트롤 플레인 인스턴스를 자동으로 감지하고 교체하며 자동화된 버전 업그레이드 및 패치를 제공합니다.
✅ EKS Control plane
EKS 컨트롤 플레인의 아키텍처 입니다.
AWS EKS는 각각의 클러스터에 대해서 K8s 컨트롤 플레인을 실행합니다.
- Control plane 인프라는 AWS 계정간 공유되지 않습니다.
- 최소 2개의 API 서버 인스턴스와 3개의 ectd 인스턴스로 구성됩니다. 각각의 인스턴스는 다른 3개의 가용영역(AZ)에 배포됩니다.
- etcd란 무엇일까요?
- etcd는 Key-Value 형태로 데이터를 저장하는 스토리지입니다.
- 쿠버네티스에서 ectd를 컨트롤 플레인의 컴포넌트로 채택하여 널리 사용하고 있습니다.

✅ EKS Data plane
쿠버네티스 노드입니다.
각 노드에는 다음 구성요소가 포함됩니다.
- 컨테이너 런타임 – 컨테이너 실행을 담당하는 소프트웨어.
- kubelet – 컨테이너가 관련 포드 내에서 정상이고 실행 중인지 확인합니다.
- kube-proxy – 팟(Pod)과의 통신을 허용하는 네트워크 규칙을 유지합니다.
EKS의 노드는 세가지 유형으로 분류하여 사용할 수 있습니다.
- EKS 매니지드 노드 그룹
- EKS 클러스터용 노드의 프로비저닝 및 수명 주기 관리를 자동화합니다.
- AWS에서 수명주기를 관리하지만, Amazon EKS 관리형 노드 그룹을 사용하는 데 드는 추가 비용은 없으며 프로비저닝한 AWS 리소스에 대해서만 비용을 지불하면 됩니다.
- 자체 관리형 노드
- Managed 노드 그룹과의 차이는 AWS Outposts 또는 AWS Local Zone에 배포 가능한 그룹 유형입니다.
- AWS FARGATE
- 고객은 별도의 EC2관리할 필요 없이, AWS Fargate 환경에서 제공하는 Micro VM을 이용하여 Pod 별 VM 할당하여 사용할 수 있습니다.
- 기본 커널, CPU 리소스, 메모리 리소스 또는 탄력적 네트워크 인터페이스를 다른 포드와 공유하지 않으므로 컨테이너의 보안을 준수할 수 있습니다.
- Fargate를 사용하면 컨테이너를 실행하기 위해 가상 머신 그룹을 직접 프로비저닝, 구성 또는 확장할 필요가 없습니다.
- 서버 유형을 선택하거나 노드 그룹을 확장할 시기를 결정하거나 클러스터 패킹을 최적화할 필요가 없습니다.

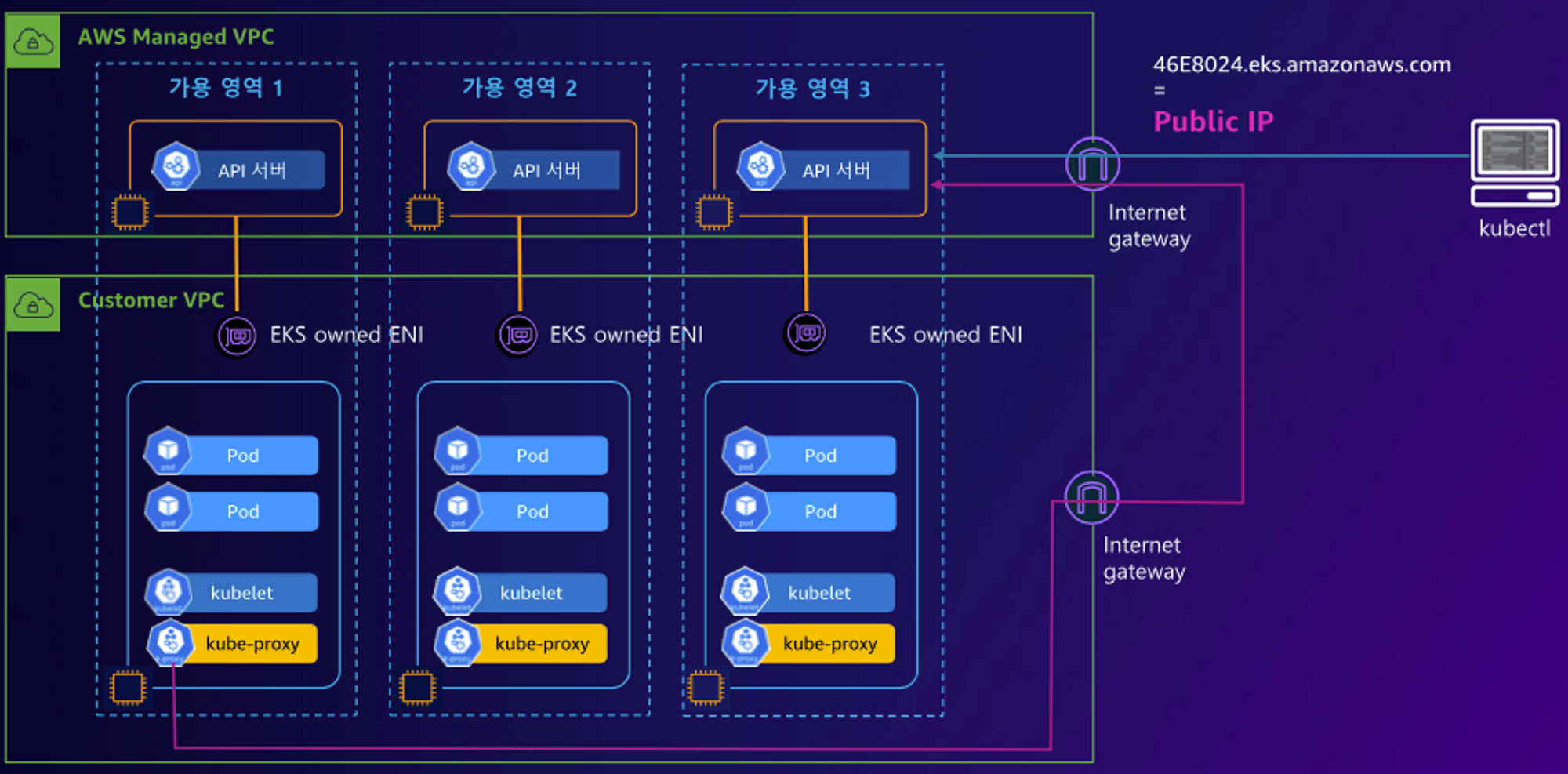
✅ EKS Cluster Endpoint
- Public
Flow
(Start) 제어부
→ (EKS owned ENI) 워커노드 kubelet, 워커노드
→ (퍼블릭 도메인) 제어부, 사용자 kubectl
→ (퍼블릭 도메인) 제어부
✅ EKS Cluster Endpoint
- Public & Private
Flow
(Start) 제어부
→ (EKS owned ENI) 워커노드 kubelet, 워커노드
→ (프라이빗 도메인, EKS owned ENI) 제어부, 사용자 kubectl
→ (퍼블릭 도메인) 제어부
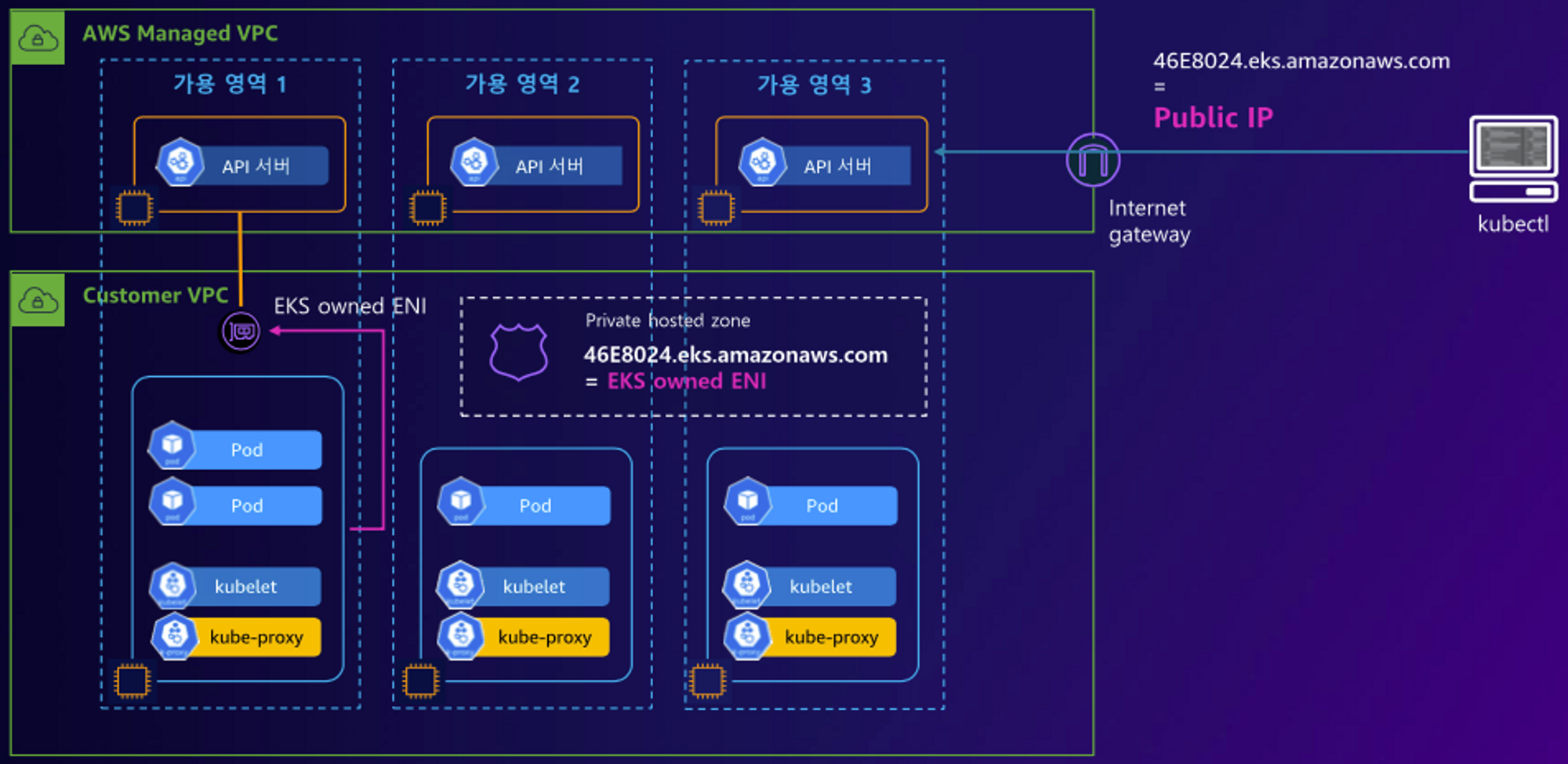
✅ EKS Cluster Endpoint
- Private
Flow
(Start) 제어부
→ (EKS owned ENI) 워커노드 kubelet, 워커노드,사용자 kubectl
→ (프라이빗 도메인, EKS owned ENI) 제어부

👉 Step 02. 쿠버네티스 스토리지
해당 내용은 이전 블로그 내용을 통해 확인할 수 있습니다.
[aews] EKS Storage & Node Manage - 스토리지의 이해
👉 Step 03. 쿠버네티스 네트워크
해당 내용은 이전 블로그 내용을 통해 확인할 수 있습니다.
👉 Step 04. Statefullset & Headless Service
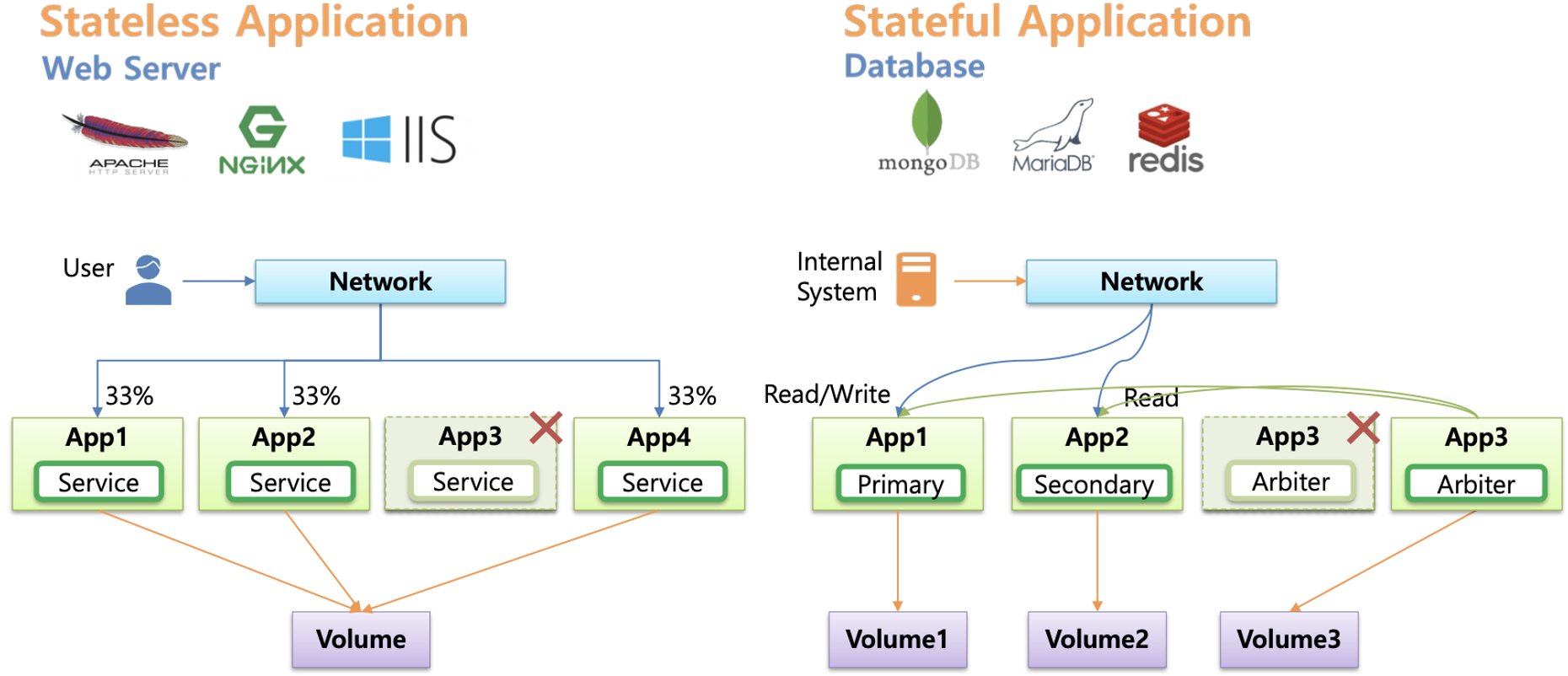
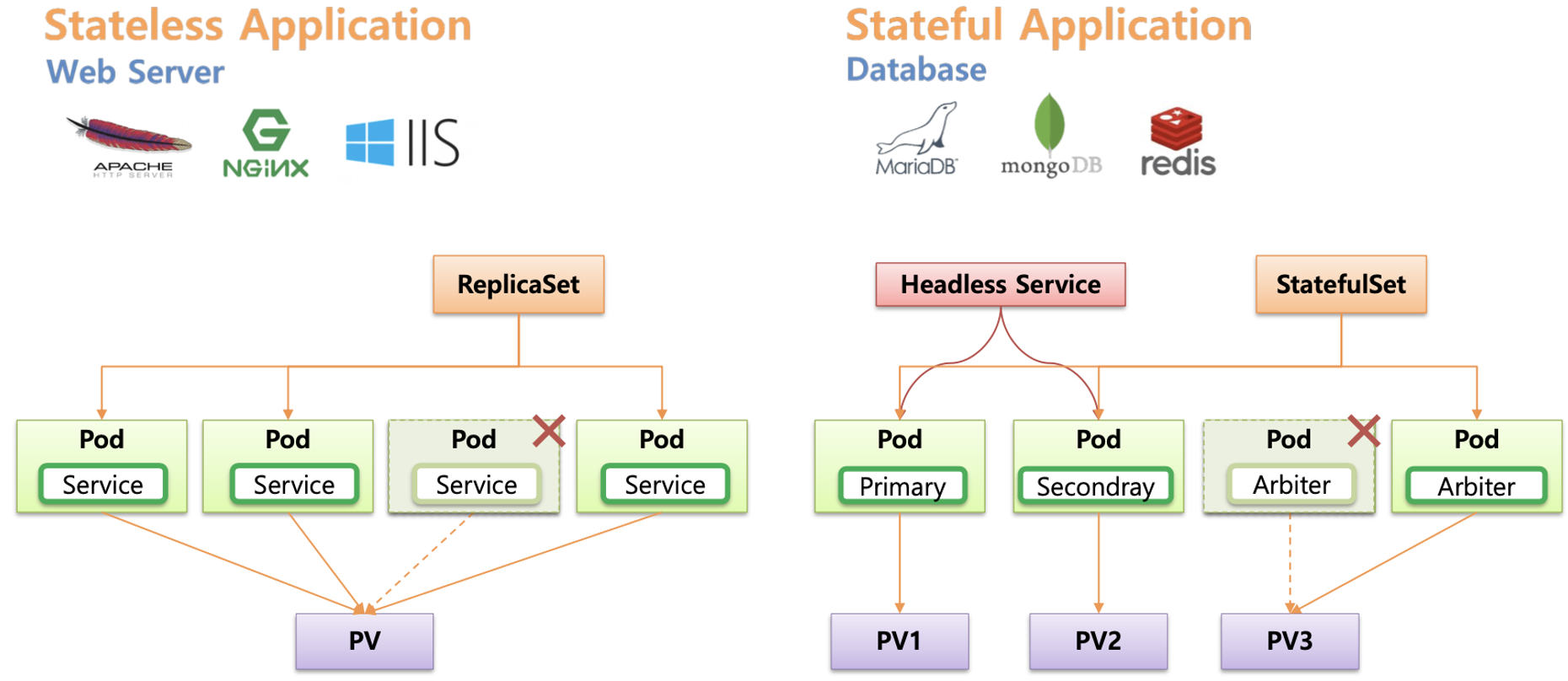
Stateless vs Stateful 비교 및 스테이트풀셋 소개
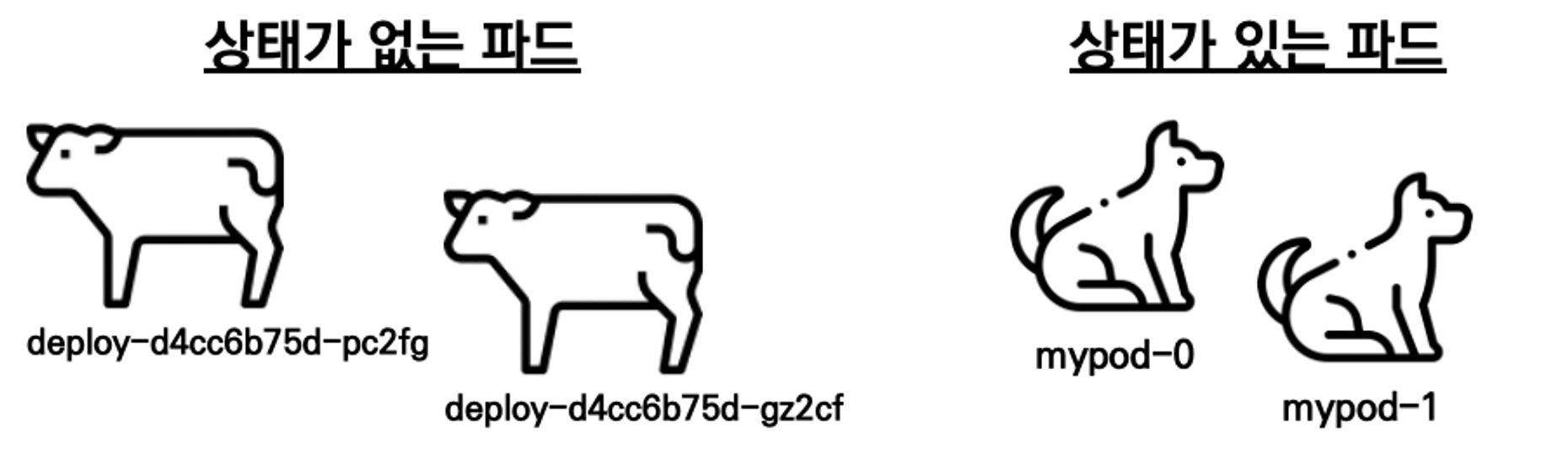
Cattle & Pet
This is one of the cardinal concepts in DevOps is the notion of pets vs cattle for the service model. This was first introduced by Bill Baker on topic of scaling up vs scaling out presentation that was included slide deck titled Scaling SQL Server 2012. It was later introduced popularized by Gavin McCance in CERN Data Centre Evolution presentation.Bill Baker가 SQL Server 2012 확장 이라는 제목의 슬라이드 데크에 포함된 수직 확장 및 확장 프레젠테이션 주제에 대해 처음 소개된 개념으로서, 기존의 마치 애완동물과 같이 개별적으로 꾸준히 관리하는 인프라 환경에서 수많은 가축을 관리하는 컨테이너에 비유하여 설명할 수 있습니다.
쿠버네티스에서 상태가 존재하는 포드를 지칭할 때는 '애완동물'에 비유합니다.
애완동물에는 특별한 이름을 붙여주기 때문에 다른 애완동물과 명확히 구분됩니다.
따라서 사람의 입장에서 애완동물은 대체 불가능한 개체로서, 항상 고유한 식별자를 갖는 것으로 여겨집니다.
이와 같은 이유로 쿠버네티스에서는 상태를 갖는 애플리케이션, 즉 스테이트풀셋을 통해 생성되는 포드를 보통 애완동물에 비유합니다.
상태를 갖는 각 포드는 모두 고유하며, 쉽게 대체될 수 없기 때문입니다.
Stateful 및 Headless 소개 - 김태민님의 기술블로그
상태 저장(Stateful)이 필요한 애플리케이션(파드)의 경우 해당 파드가 문제 시 신규 파드가 생성되고 기존의 PV가 연결됩니다.
스테이트풀셋으로 배포된 파드는 이름 뒤에 순차적인 숫자로 유일하게 구별 가능하며, 파드 별로 PV(PVC)가 생성 및 연동됩니다.
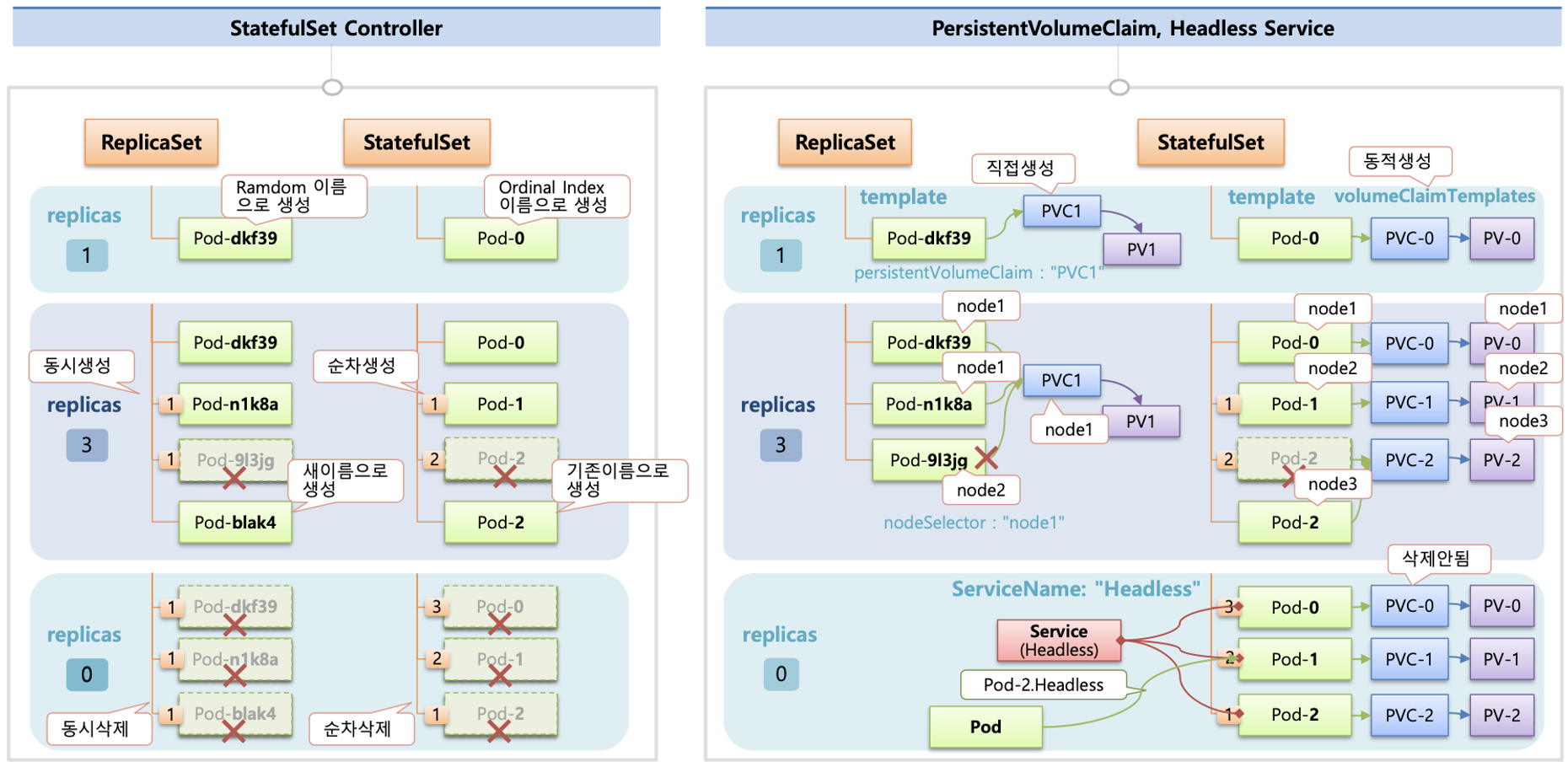
StatefulSet 으로 배포된 파드에 접속하기 위해서는 Headless Service 를 활용합니다.
kubernetes docs - Headless Service?
때때로 로드-밸런싱과 단일 서비스 IP는 필요치 않다. 이 경우, "헤드리스" 서비스라는 것을 만들 수 있는데, 명시적으로 클러스터 IP (.spec.clusterIP)에 "None"을 지정한다.
쿠버네티스의 구현에 묶이지 않고, 헤드리스 서비스를 사용하여 다른 서비스 디스커버리 메커니즘과 인터페이스할 수 있다.
헤드리스 서비스의 경우, 클러스터 IP가 할당되지 않고, kube-proxy가 이러한 서비스를 처리하지 않으며, 플랫폼에 의해 로드 밸런싱 또는 프록시를 하지 않는다. DNS가 자동으로 구성되는 방법은 서비스에 셀렉터가 정의되어 있는지 여부에 달려있다.
Headless Service 의 경우에는 <파드이름>.<서비스이름>... 으로 DNS 쿼리 할 수 있습니다.
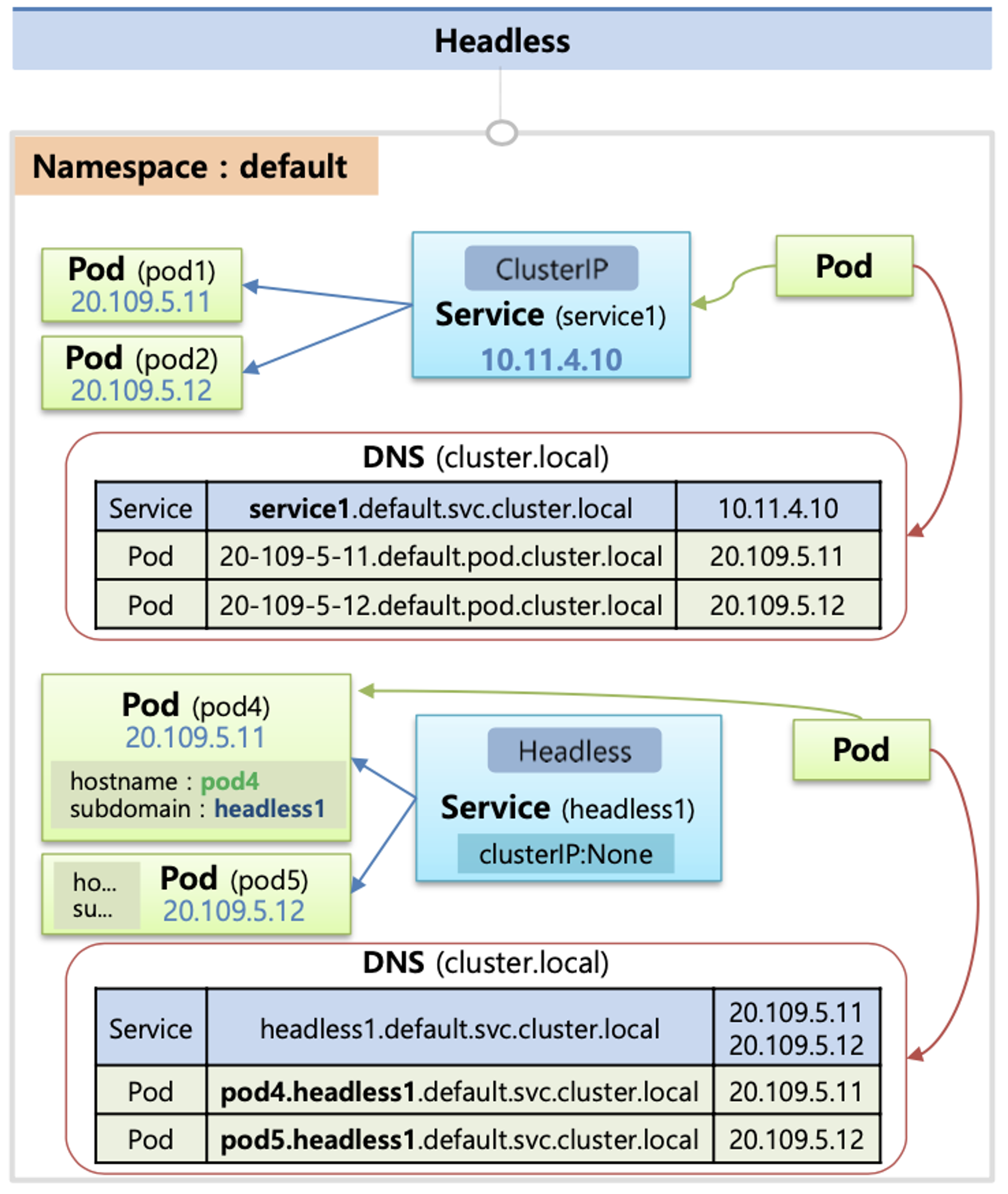
헤드리스 서비스 조건
- 서비스의 spec.type 이 ClusterIP 일 것
- 서비스의 spec.clusterIP 가 None 일 것
- 스테이트풀렛 + 헤드리스 서비스 사용으로 스테이트풀렛으로 생성된 파드명으로 이름 해석 시 추가 조건
- 서비스의 metadata.name 이 스테이트풀셋의 spec.serviceName 과 같을 것
- 헤드리스 서비스의 이름은 SRV 레코드로 쓰이기 때문에 헤드리스 서비스의 이름을 통해 포드에 접근할 수 있는 IP를 반환할 수 있다 - SRV 레코드
- SRV(Service record)는 DNS(Domain Name System)에서 서비스의 위치(호스트네임 과 포트번호)를 저장하기 위해서 사용하는 레코드
📍 실습
스테이트풀셋 & 헤드리스서비스 실습
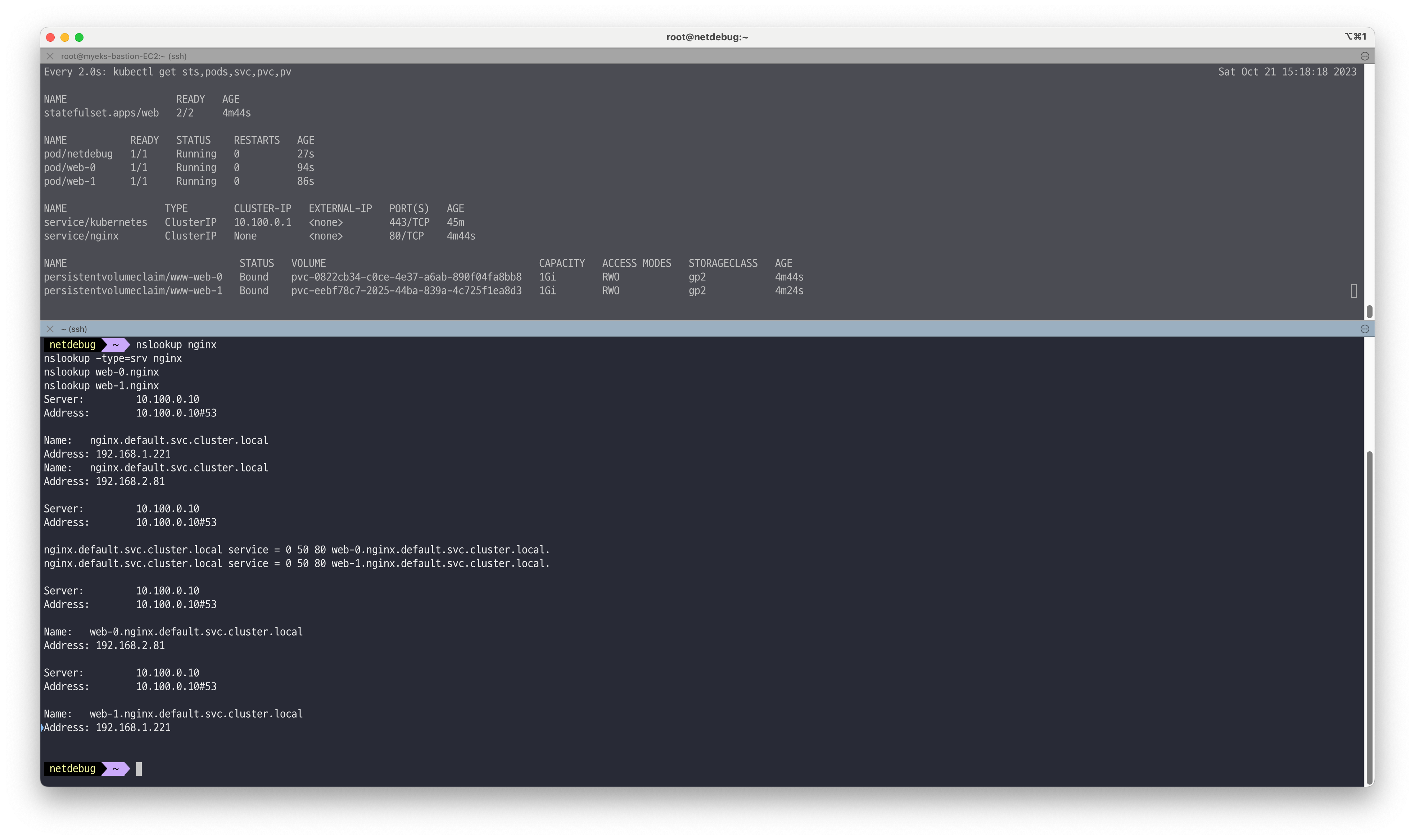
# 모니터링 watch -d 'kubectl get sts,pods,svc,pvc,pv' # 스테이트풀셋 & 헤드리스서비스 배포 curl -s -O https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/application/web/web.yaml cat web.yaml | yh kubectl apply -f web.yaml && kubectl get pods -w -l app=nginx # 파드 hostname 확인 for i in 0 1; do kubectl exec "web-$i" -- sh -c 'hostname'; done kubectl df-pv # netshoot 이미지로 netdebug 파드에 zsh 실행 kubectl run -it --rm netdebug --image=nicolaka/netshoot --restart=Never -- zsh -------------------- nslookup nginx nslookup -type=srv nginx nslookup web-0.nginx nslookup web-1.nginx exit --------------------
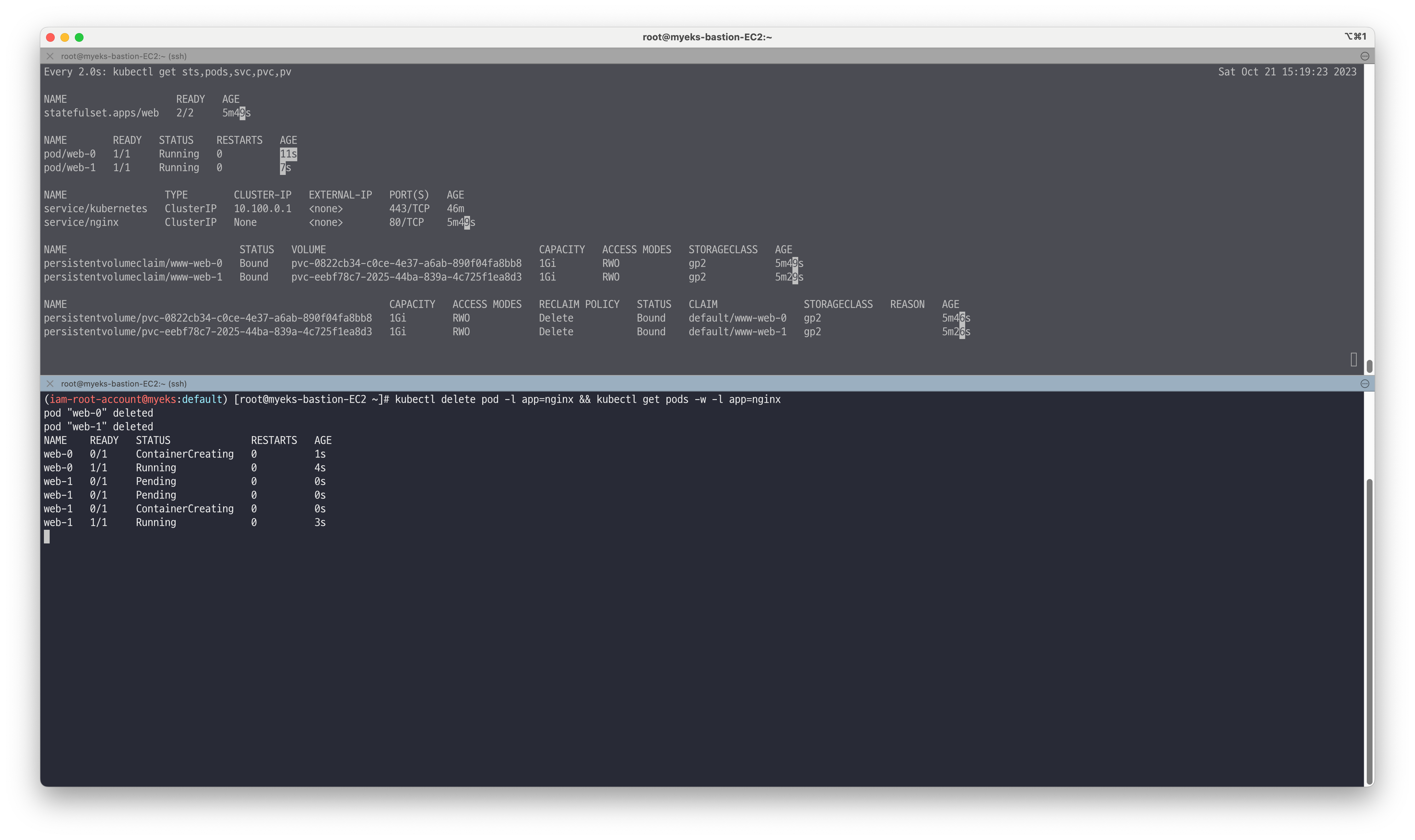
# 파드 삭제 실행 후 재실행 시 생성 순서 확인 kubectl delete pod -l app=nginx && kubectl get pods -w -l app=nginx # 파드 hostname 확인 for i in 0 1; do kubectl exec web-$i -- sh -c 'hostname'; done # netshoot 이미지로 netdebug 파드에 zsh 실행 kubectl run -it --rm netdebug --image=nicolaka/netshoot --restart=Never -- zsh -------------------- nslookup nginx nslookup -type=srv nginx nslookup web-0.nginx nslookup web-1.nginx exit --------------------
# PVC 확인 kubectl get pvc -l app=nginx NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE www-web-0 Bound pvc-464030d6-f732-406f-aac4-dc35add63b2b 1Gi RWO local-path 7m6s www-web-1 Bound pvc-04c73836-e842-4abd-b19e-870c16b2b51c 1Gi RWO local-path 6m59s # 웹 서버 index.html 에 hostname 추가 후 웹 접속 해서 확인 # 웹 서버 파드는 볼륨 마운트 정보 : Mounts: /usr/share/nginx/html from www (rw) - PersistentVolumeClaim for i in 0 1; do kubectl exec "web-$i" -- sh -c 'echo "$(hostname)-pv-test" > /usr/share/nginx/html/index.html'; done for i in 0 1; do kubectl exec -i -t "web-$i" -- curl http://localhost/; done

# 파드 증가 kubectl scale sts web --replicas=5 && kubectl get pods -w -l app=nginx
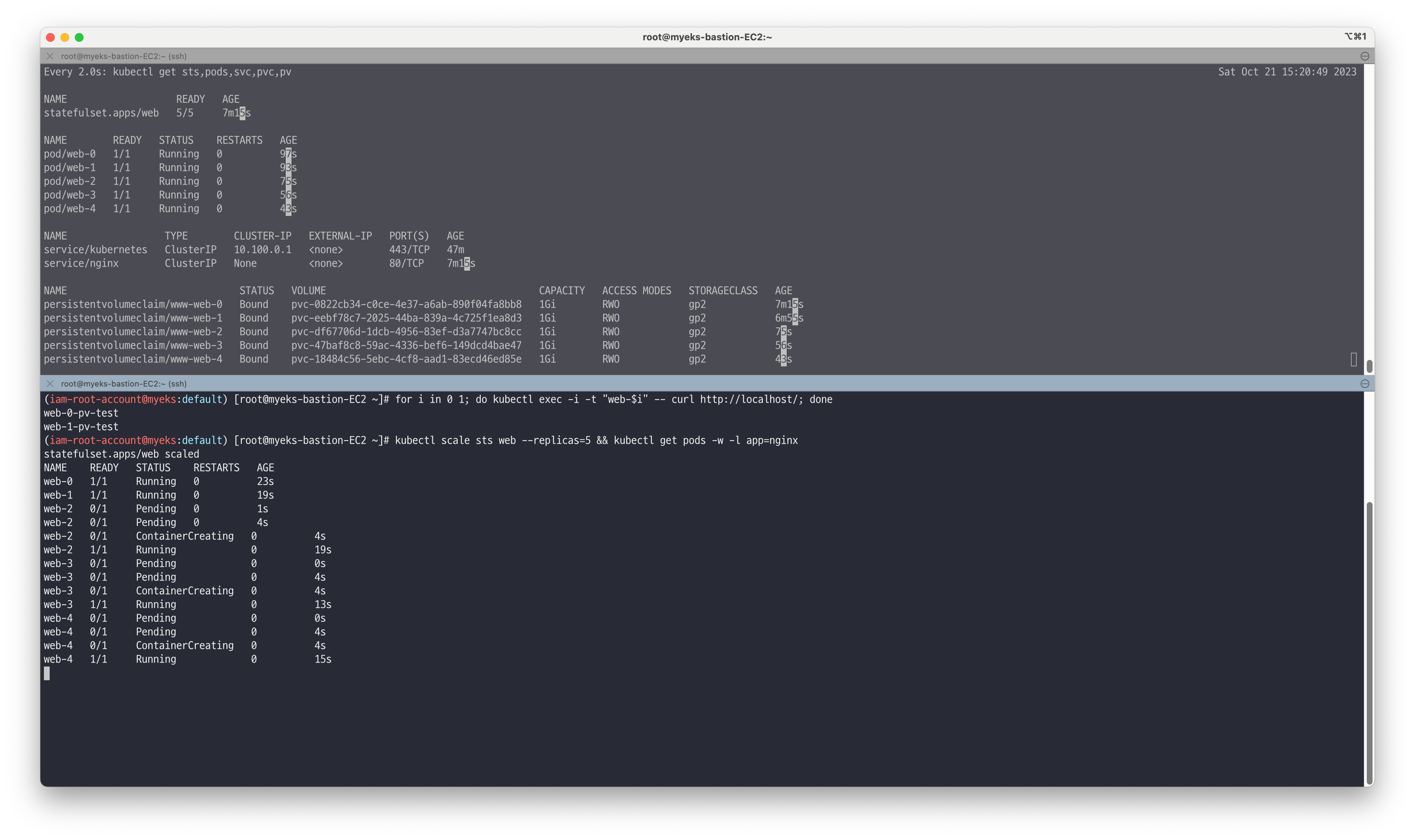
# 파드 감소 kubectl patch sts web -p '{"spec":{"replicas":3}}' && kubectl get pods -w -l app=nginx

✅ Assignment
⚡ Run a Replicated Stateful Application : MySQL
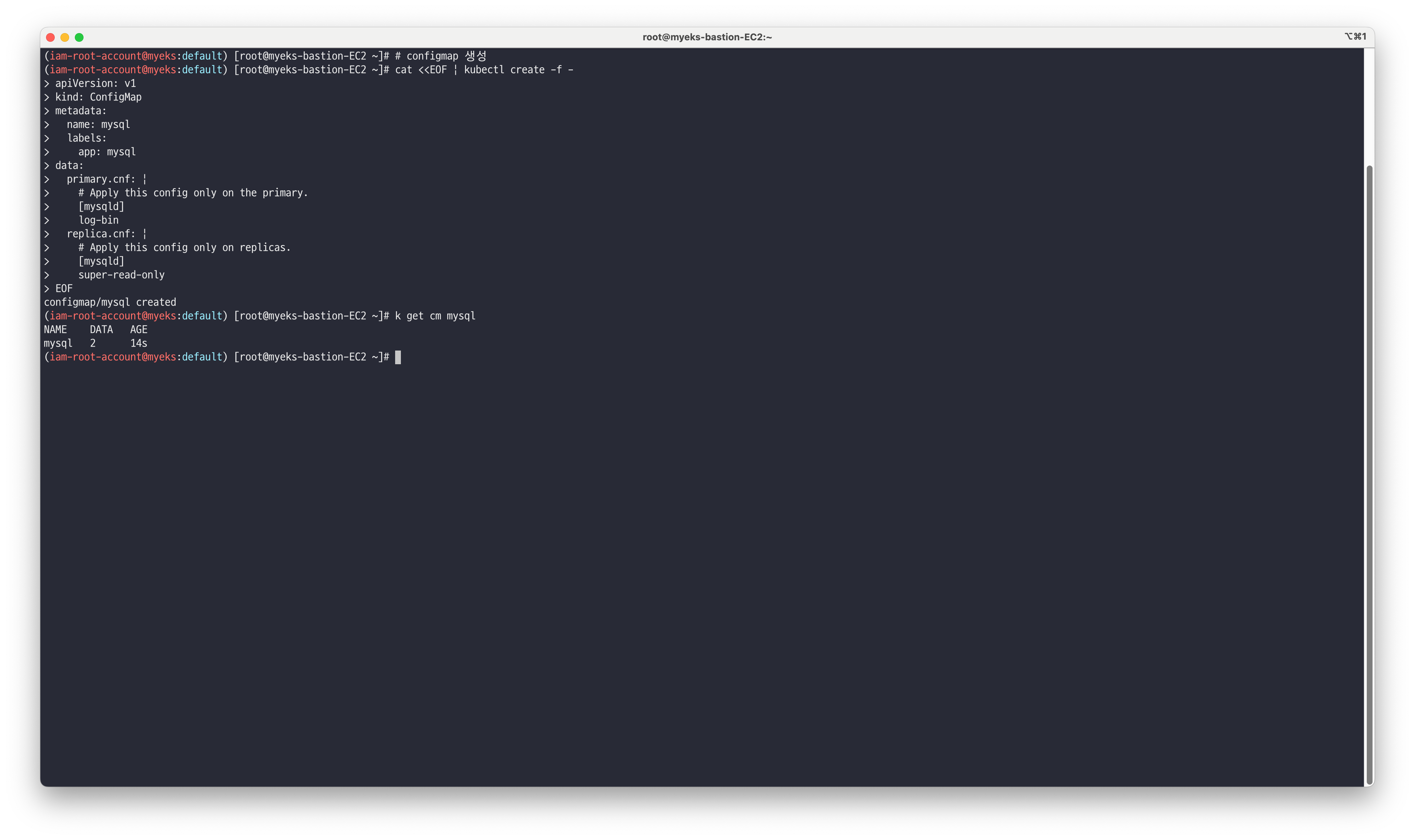
mysql을 배포하기 전 기본 설정값을 적용하기 위해 ConfigMap 리소스를 생성합니다.
# configmap 생성 cat <<EOF | kubectl create -f - apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: primary.cnf: | # Apply this config only on the primary. [mysqld] log-bin replica.cnf: | # Apply this config only on replicas. [mysqld] super-read-only EOF
Mysql을 사용하기 위하여 서비스 리소스를 생성합니다.
# Service 생성 kubectl apply -f https://k8s.io/examples/application/mysql/mysql-services.yaml # Service 생성 확인 : mysql(헤드리스서비스) 과 mysql-read 두개 서비스 생성됨 kubectl get svc -l app=mysql NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE mysql ClusterIP None <none> 3306/TCP 50m mysql-read ClusterIP 10.200.1.167 <none> 3306/TCP 50m # Statefulset 생성 kubectl apply -f https://k8s.io/examples/application/mysql/mysql-statefulset.yaml # Statefulset 생성 확인 : 파드에 4개의 컨테이너로 구성 - 초기화컨테이너(init-mysql, clone-mysql), 컨테이너(mysql), 사이드카컨테이너(xtrabackup) kubectl get -f https://k8s.io/examples/application/mysql/mysql-statefulset.yaml kubectl get pod -l app=mysql -owide
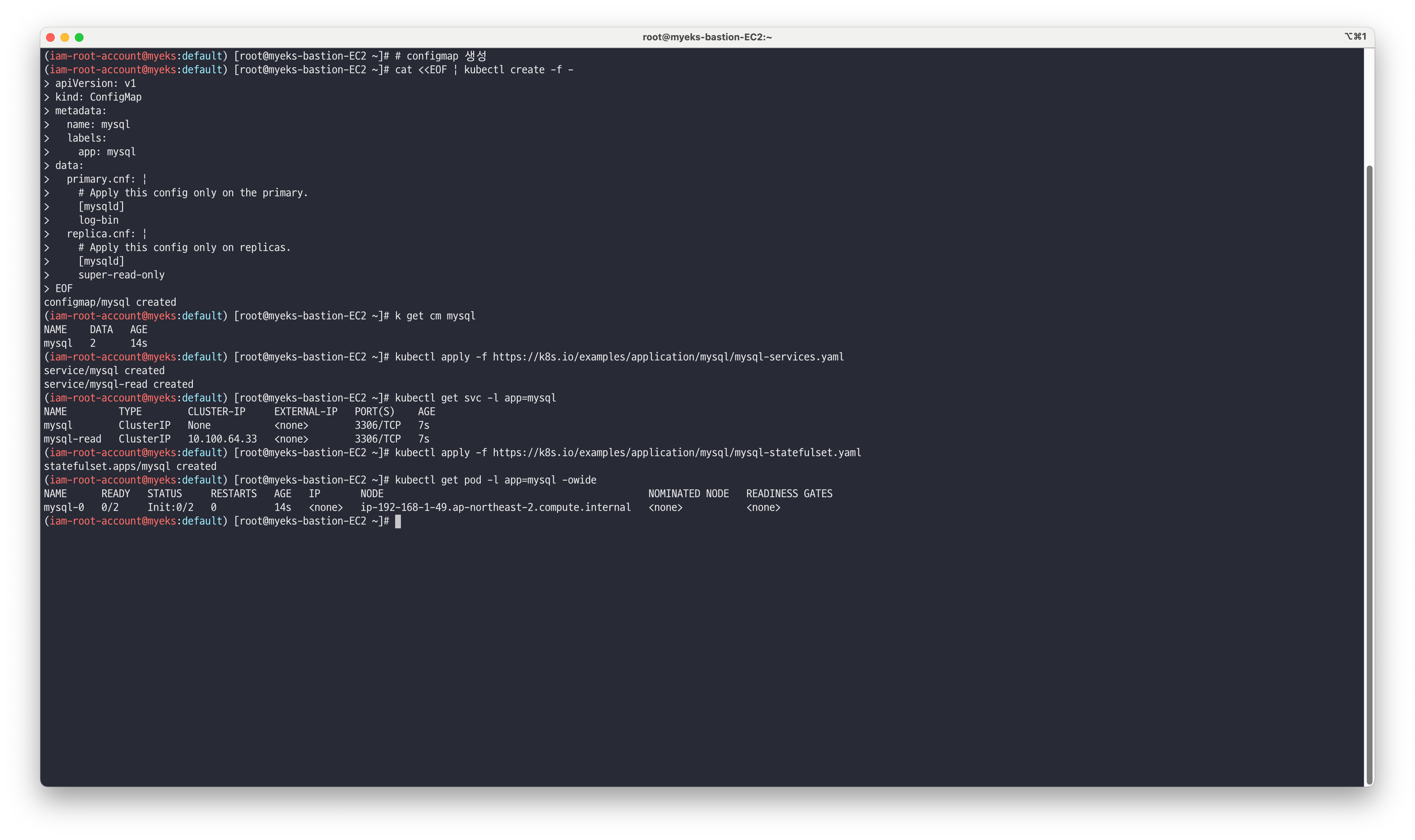
Mysql Client 파드를 이용해서
StatefulSet으로 배포되어있는 Mysql Serve에 쿼리를 실행합니다.# 데이터베이스 생성 및 데이터 INSERT kubectl run mysql-client --image=mysql:5.7 -i --rm --restart=Never --\ mysql -h mysql-0.mysql <<EOF CREATE DATABASE test; CREATE TABLE test.messages (message VARCHAR(250)); INSERT INTO test.messages VALUES ('hello doik study'); EOF # 데이터베이스 쿼리 확인 kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\ mysql -h mysql-read -e "SELECT * FROM test.messages" +---------+ | message | +---------+ | hello | +---------+ # mysql-read 서비스로 쿼리 시 mysql 파드들로 분산 쿼리 확인 kubectl run mysql-client-loop --image=mysql:5.7 -i -t --rm --restart=Never --\ bash -ic "while sleep 1; do mysql -h mysql-read -e 'SELECT @@server_id,NOW()'; done" +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 102 | 2022-05-26 18:38:45 | +-------------+---------------------+ +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 101 | 2022-05-26 18:38:47 | +-------------+---------------------+ +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 100 | 2022-05-26 18:38:48 | +-------------+---------------------+ CTRL+C 로 중지
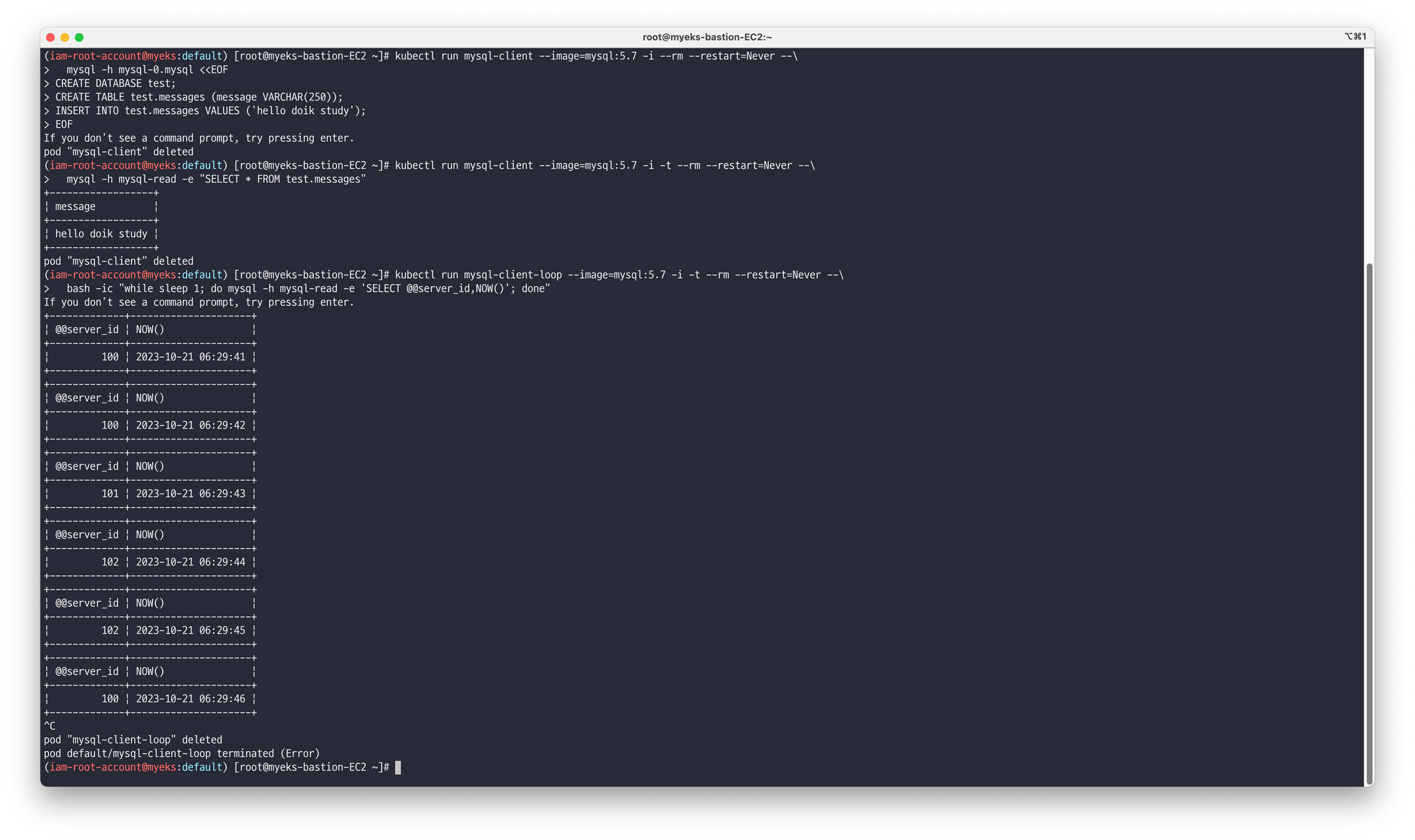
Mysql Server 파드를 Scale-out 하여 5개로 증설하고, 새로 생성된 임의의 파드에서 위에서 적용한 데이터가 조회되는지 확인합니다.
# mysql 파드 스케일링 : 5개로 증가 kubectl scale statefulset mysql --replicas=5 && kubectl get pods -l app=mysql --watch # 파드 증가 확인 kubectl get pod -l app=mysql NAME READY STATUS RESTARTS AGE mysql-0 2/2 Running 0 57m mysql-1 2/2 Running 0 56m mysql-2 2/2 Running 0 5m8s mysql-3 2/2 Running 0 81s mysql-4 2/2 Running 0 56s
# 증가된 mysql-3 파드로 쿼리 확인 kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never -- mysql -h mysql-3.mysql -e "SELECT * FROM test.messages" +---------+ | message | +---------+ | hello | +---------+ # mysql-read 서비스로 쿼리 시 mysql 파드들로 분산 쿼리 확인 kubectl run mysql-client-loop --image=mysql:5.7 -i -t --rm --restart=Never --\ bash -ic "while sleep 1; do mysql -h mysql-read -e 'SELECT @@server_id,NOW()'; done" +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 104 | 2022-05-26 19:01:19 | +-------------+---------------------+ +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 102 | 2022-05-26 19:01:20 | +-------------+---------------------+ +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 103 | 2022-05-26 19:01:21 | +-------------+---------------------+ CTRL+C 로 중지


⚡ EKS Cluster를 관리형노드그룹을 Spot 인스턴스로 배포해보기
기존 노드그룹 콘솔에서 현재 생성된 노드 그룹을 확인합니다.
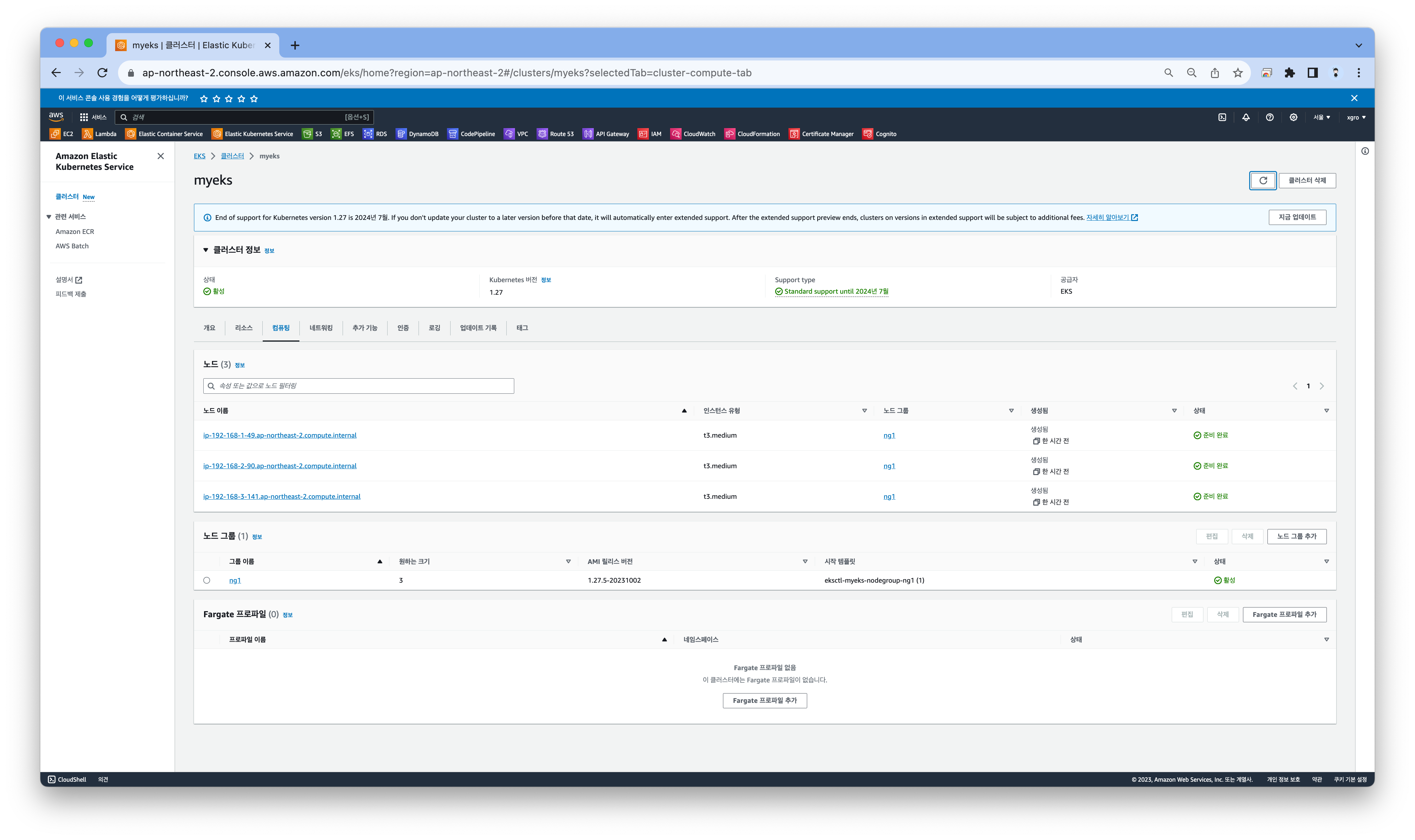
❗ 주의!
서브넷에 따라 이용 가능한 instance-types이 다르므로 노드 그룹 생성시 서브넷에서 지원하는 유형을 파악합니다.
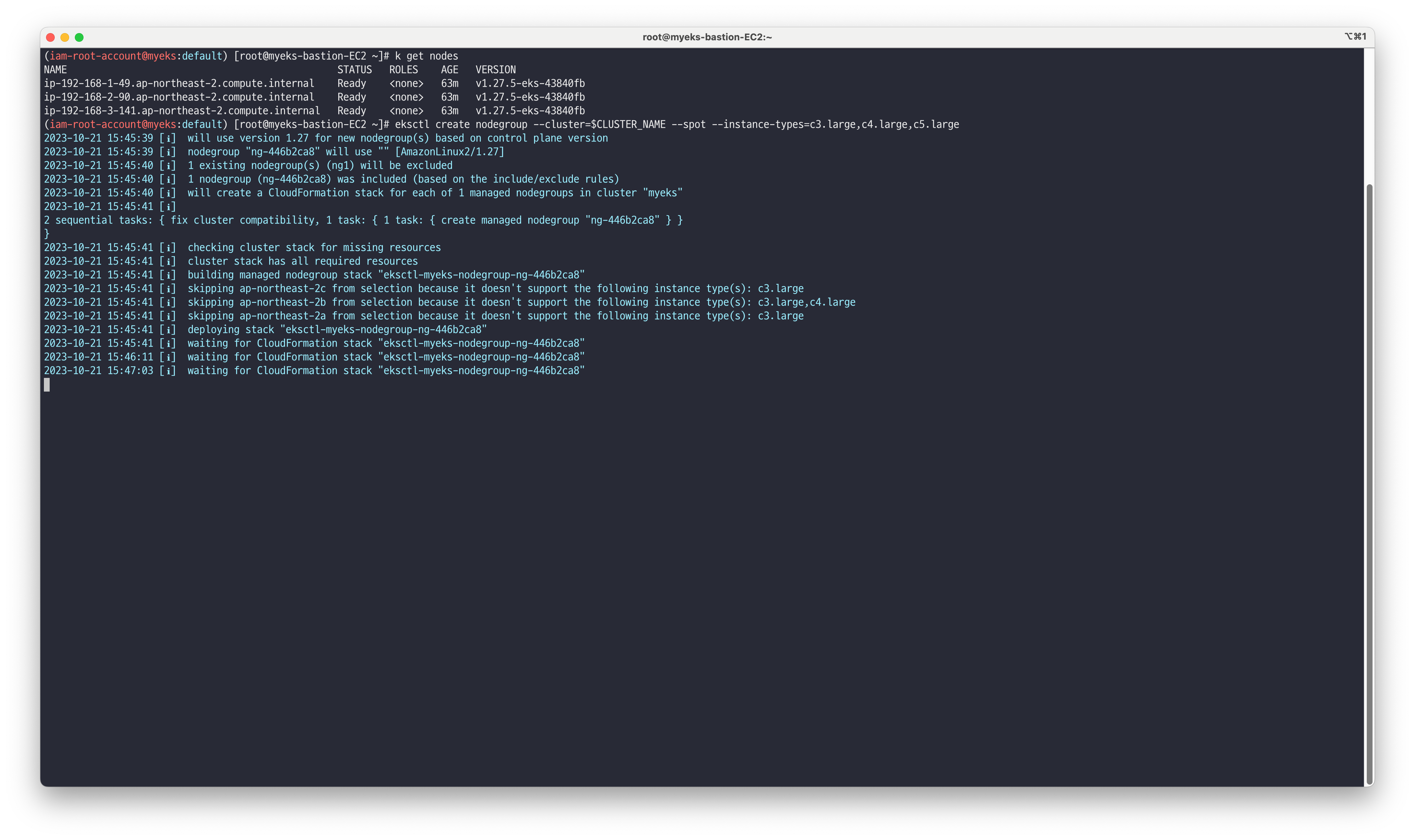
EKSCTL을 이용하여 스팟 인스턴스 노드그룹 생성합니다.
# EKSCTL을 이용하여 스팟 인스턴스 노드그룹 생성 eksctl create nodegroup --cluster=$CLUSTER_NAME --spot --instance-types=t3.small,t3.medium,t3.large
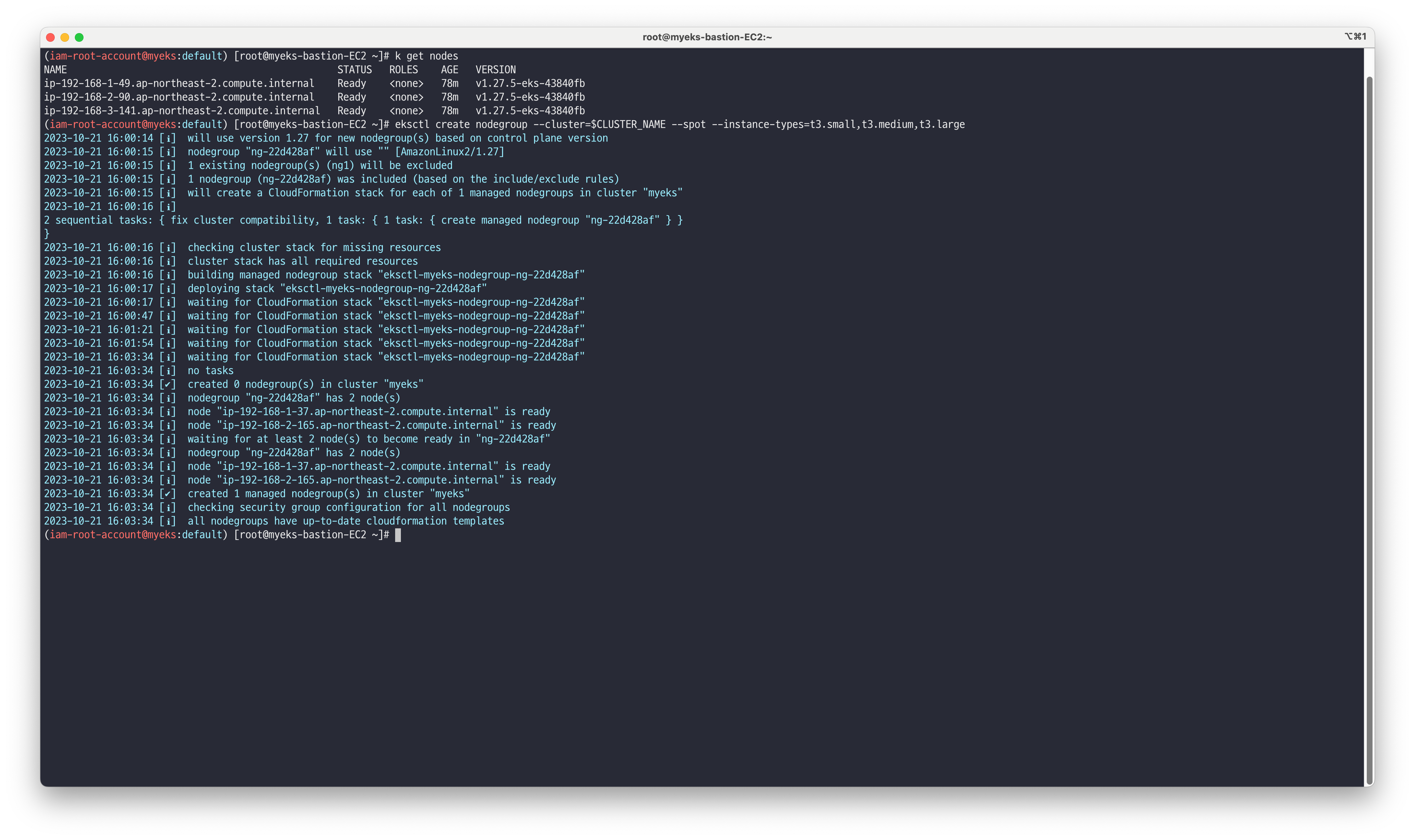
스팟 인스턴스 유형으로 생성된 노드그룹 확인합니다
kubectl describe nodes | grep -A1 -B5 eks.amazonaws.com/capacityType
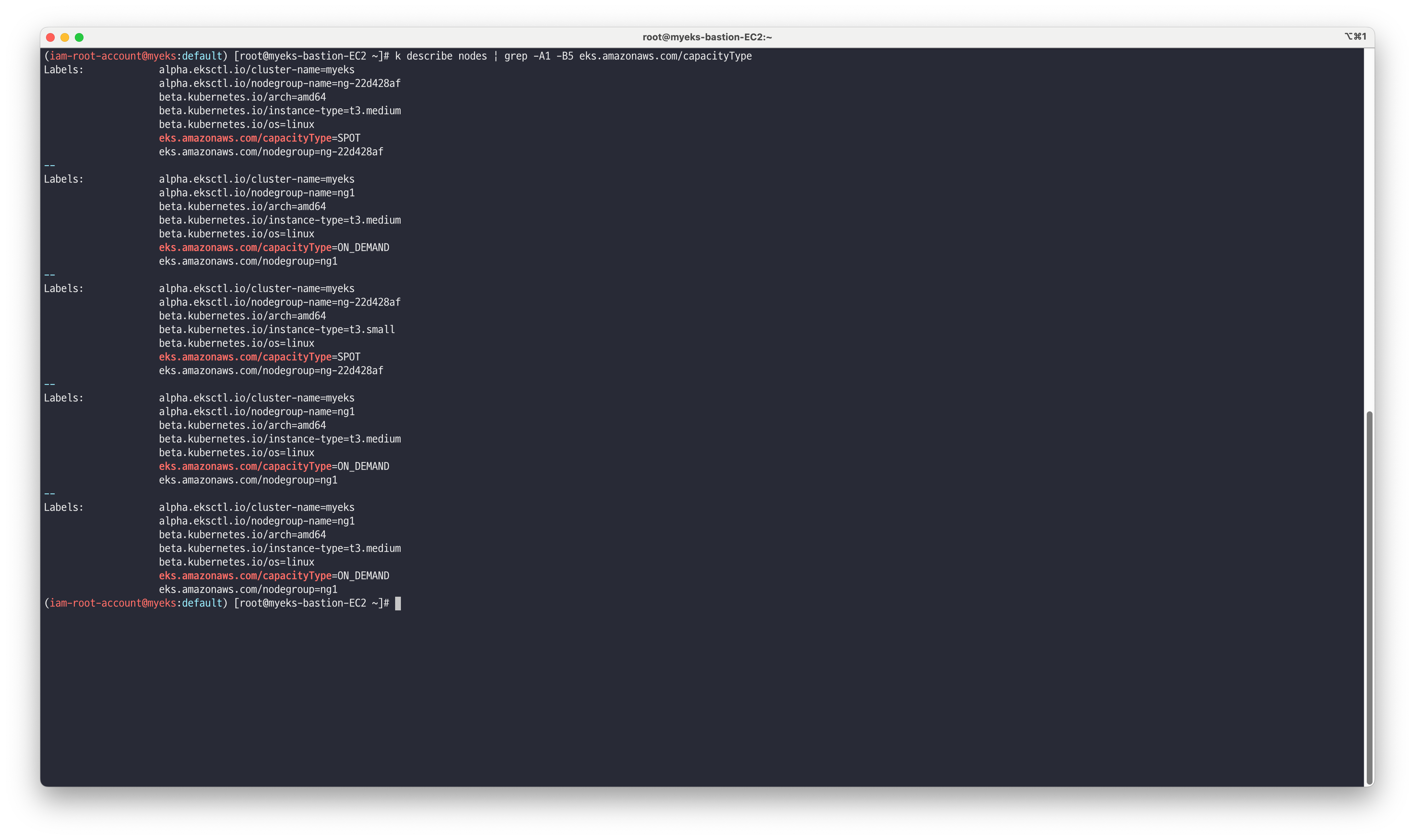
콘솔에서도 새로 생성된 노드 그룹을 확인할 수 있습니다.

📌 Reference
