📌 Notice
Database Operator In Kubernetes study (=DOIK)
데이터베이스 오퍼레이터를 이용하여 쿠버네티스 환경에서 배포/운영하는 내용을 정리한 블로그입니다.
CloudNetaStudy그룹에서 스터디를 진행하고 있습니다.
Gasida님께 다시한번 🙇 감사드립니다.EKS 및 KOPS 관련 스터디 내용은 아래 링크를 통해 확인할 수 있습니다.
[AEWS] AWS EKS 스터디
[PKOS] KOPS를 이용한 AWS에 쿠버네티스 배포

📌 Summary
-
K8s의 Operator를 통해 어플리케이션을 패키징-배포-관리할 수 있습니다.
-
Headless 서비스를 통해 Statefulset의 개별 파드로 직접 접근할 수 있습니다.
-
데이터베이스 오퍼레이터를 이해하기 위해 반드시 알아야하는 쿠버네티스 관련 지식을 정리합니다.
-
Mysql의 일반 복제와 그룹 복제 방법에 대해서 알 수 있습니다.
📌 Study
👉 Step 01. 쿠버네티스 오퍼레이터
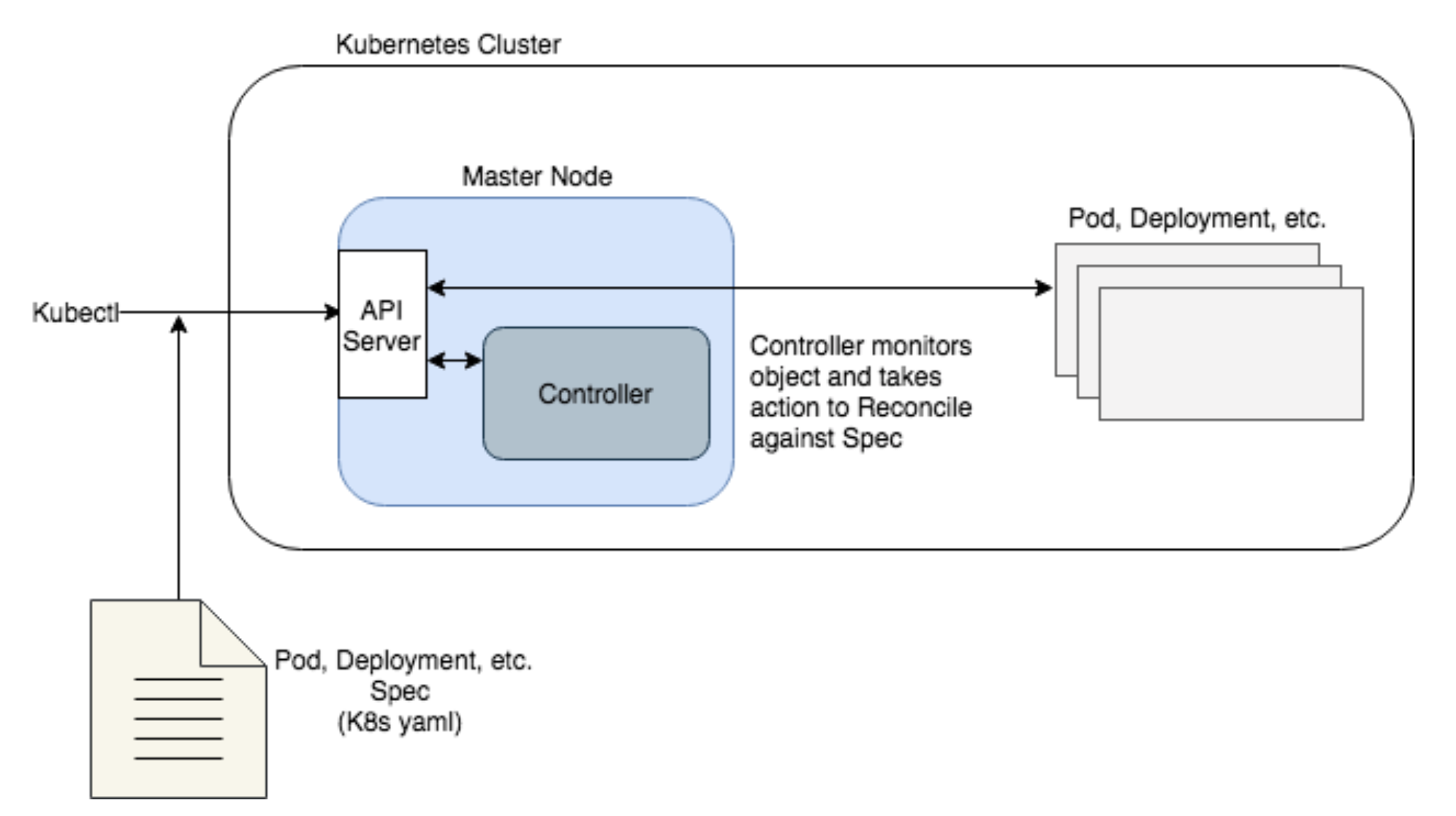
쿠버네티스 동작 흐름
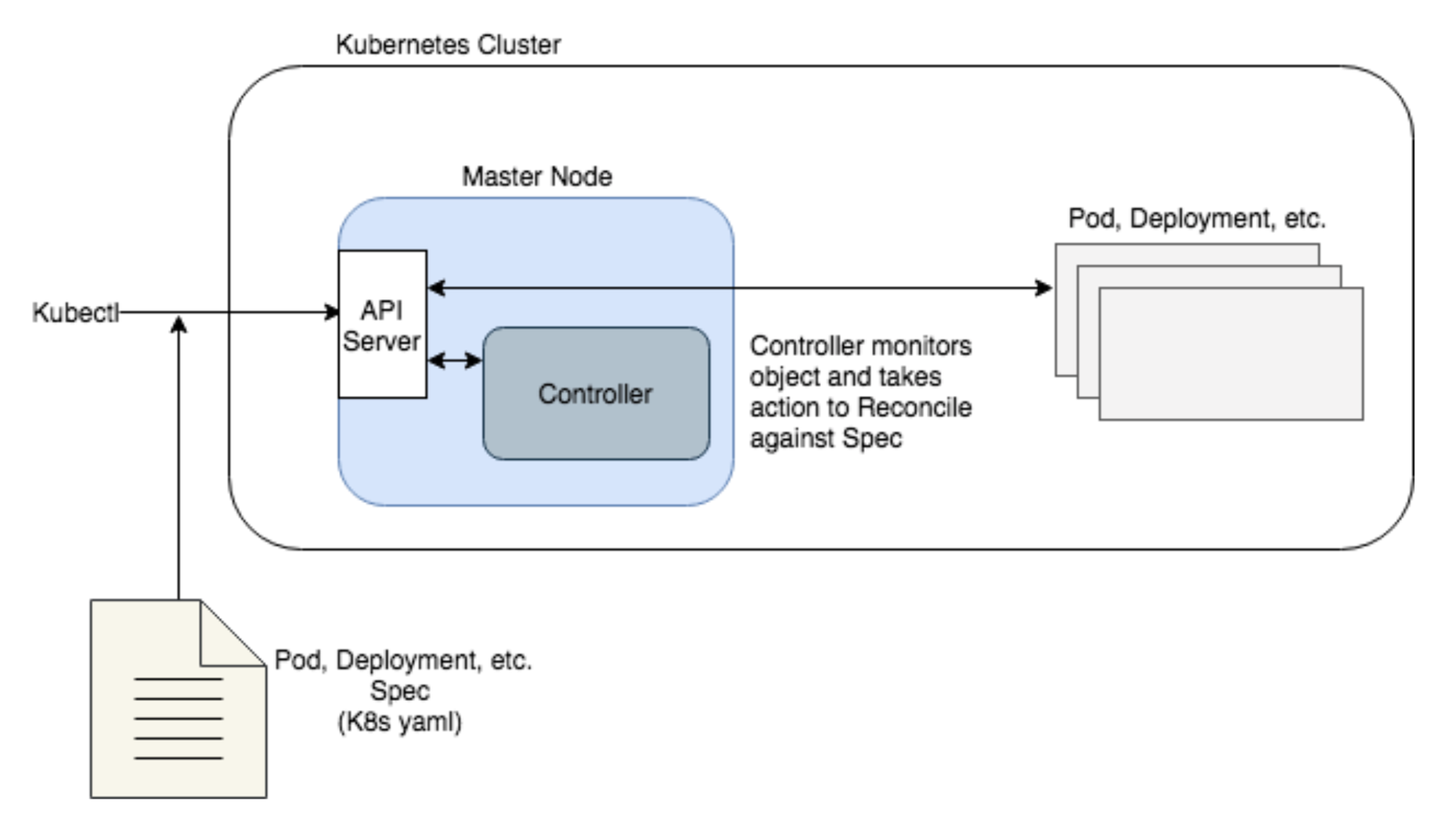
출처 - https://lcom.static.linuxfound.org/sites/lcom/files/kenzan-k8s-1.png
오퍼레이터 동작 흐름
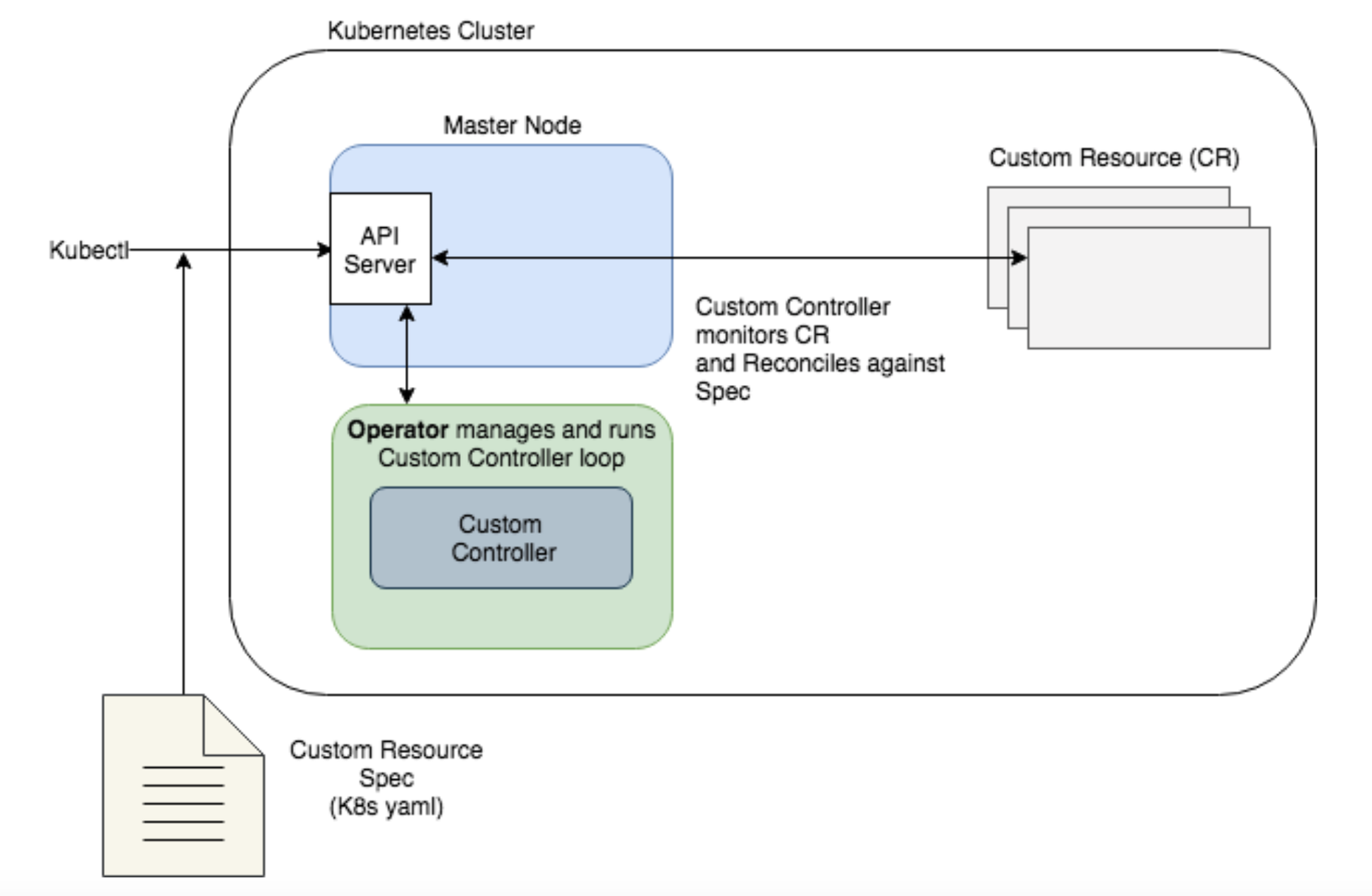
출처 - https://lcom.static.linuxfound.org/sites/lcom/files/kenzan-k8s-2.png
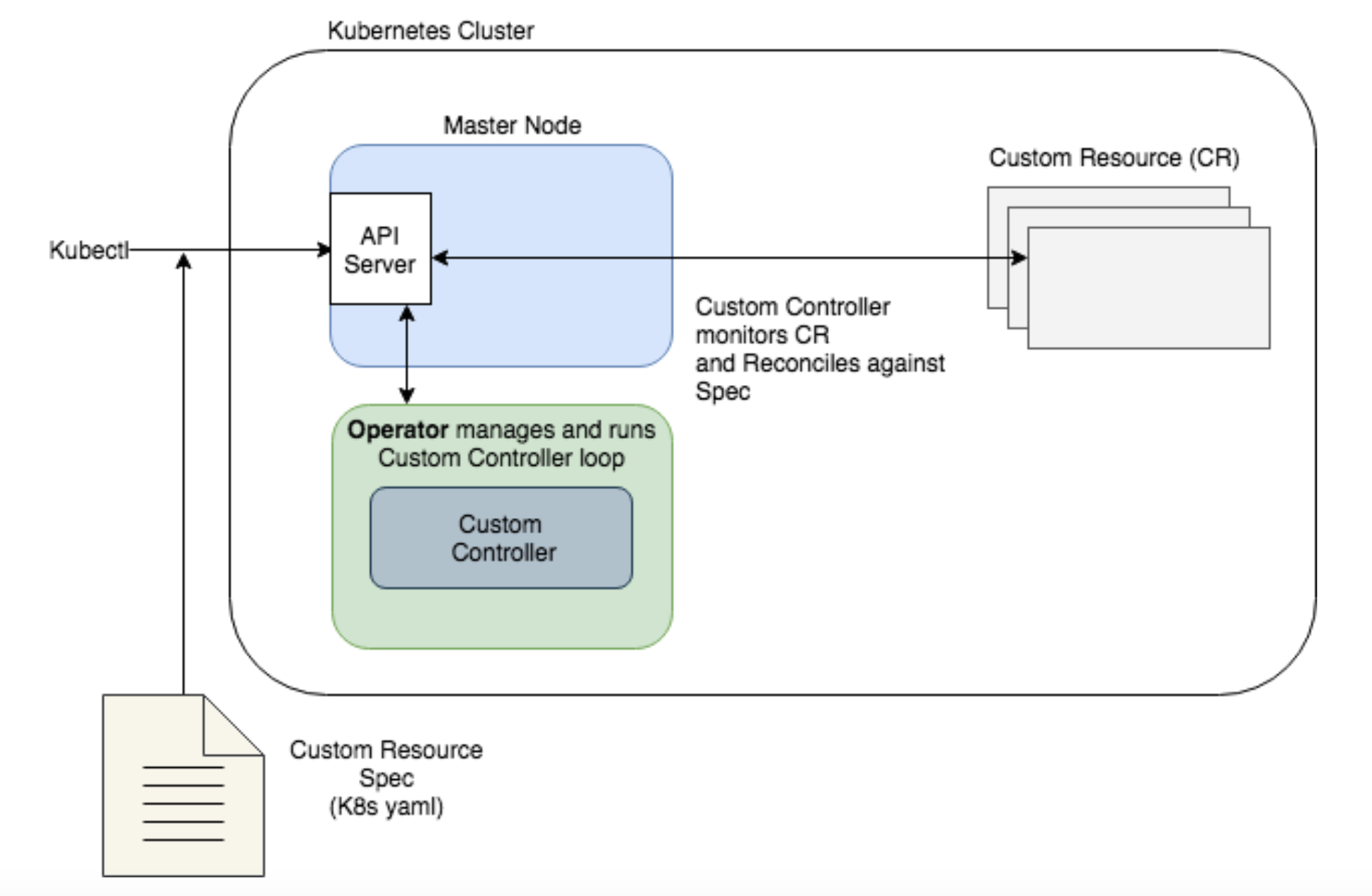
오퍼레이터는 쿠버네티스 추상화를 통해 관리 대상 소프트웨어의 전체 라이프사이클을 자동화, 애플리케이션을 패키징-배포-관리하는 방법론입니다.
- CRD Custom Resource Definition : 오퍼레이터로 사용할 상태 관리용 객체들의 Spec 을 정의
- CR Custom Resource : CRD의 Spec 를 지키는 객체들의 실제 상태 데이터 조합
- CC Custom Controller : CR의 상태를 기준으로 현재의 상태를 규정한 상태로 처리하기 위한 컨트롤 루프
- 오퍼레이터는 Helm 기능을 포함하며, 배포 업그레이드 운영까지 확장해서 관리
- CRD 구성 및 배포, Custom Controller 연계 및 실행 등을 모두 합쳐 놓은 것 == Operator
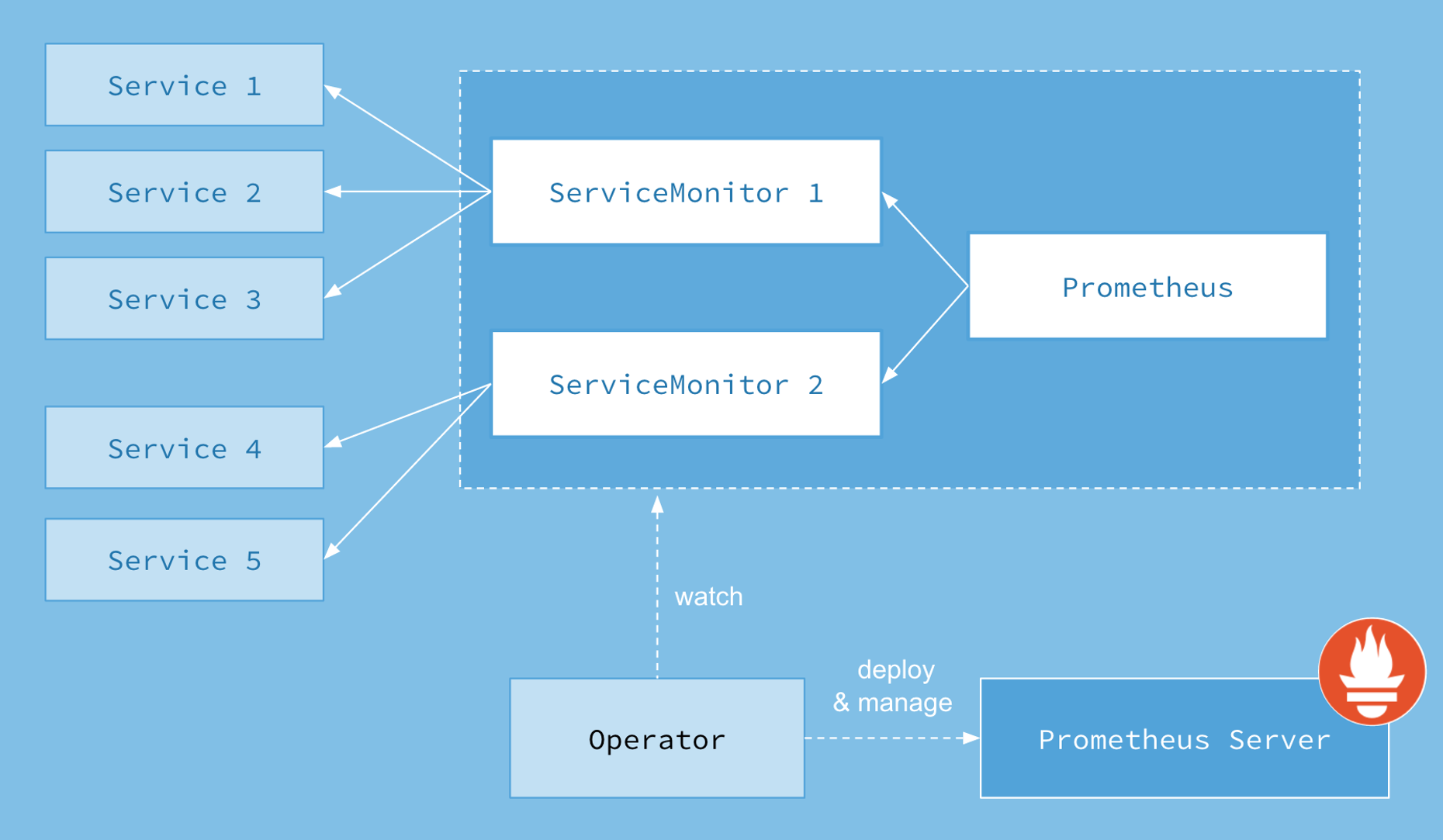
출처 - https://raw.githubusercontent.com/coreos/prometheus-operator/master/Documentation/user-guides/images/architecture.png
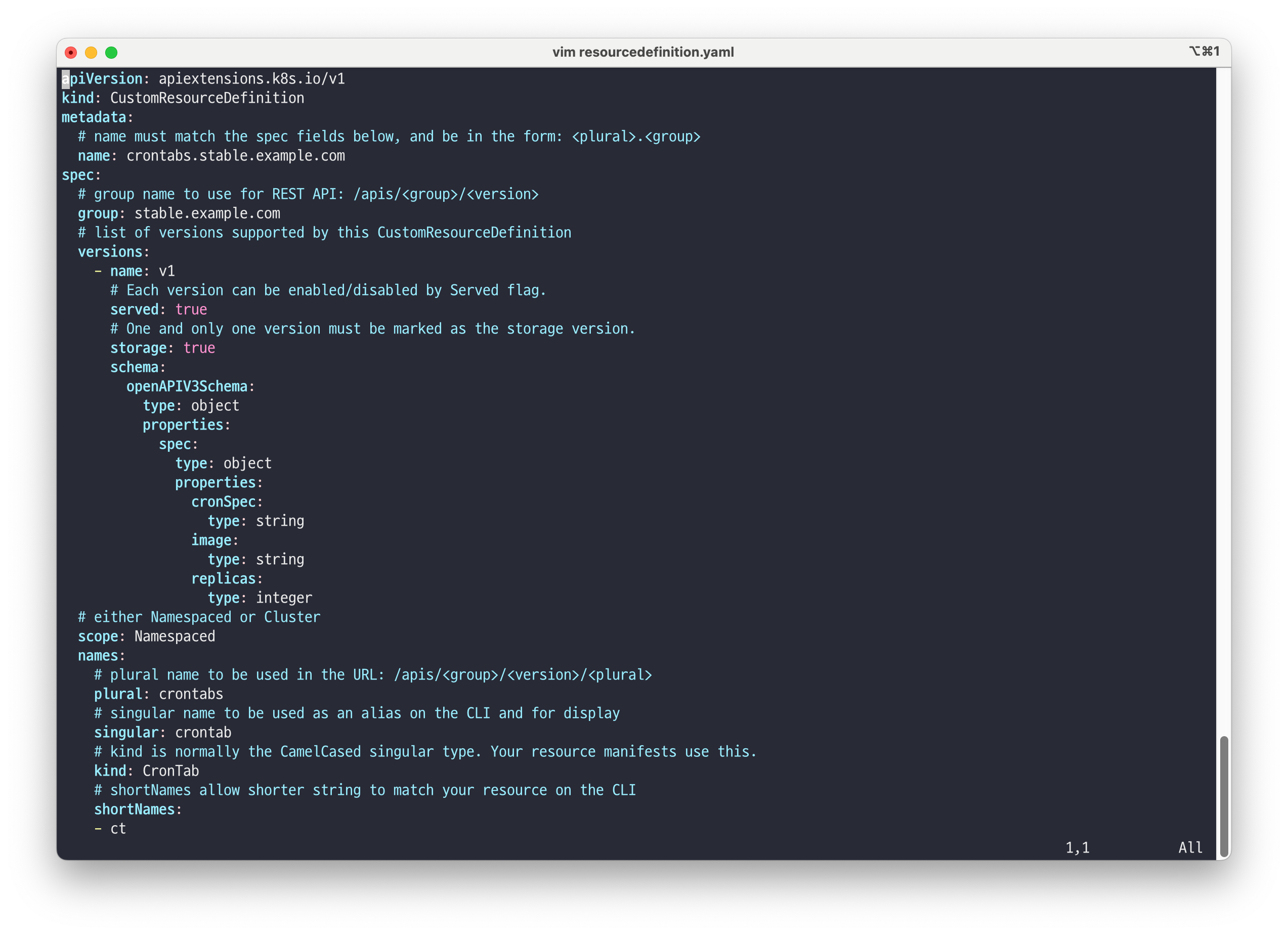
CR & CRD 실습
# CRD 샘플 YAML 파일 확인 curl -s -O https://raw.githubusercontent.com/gasida/DOIK/main/2/resourcedefinition.yaml
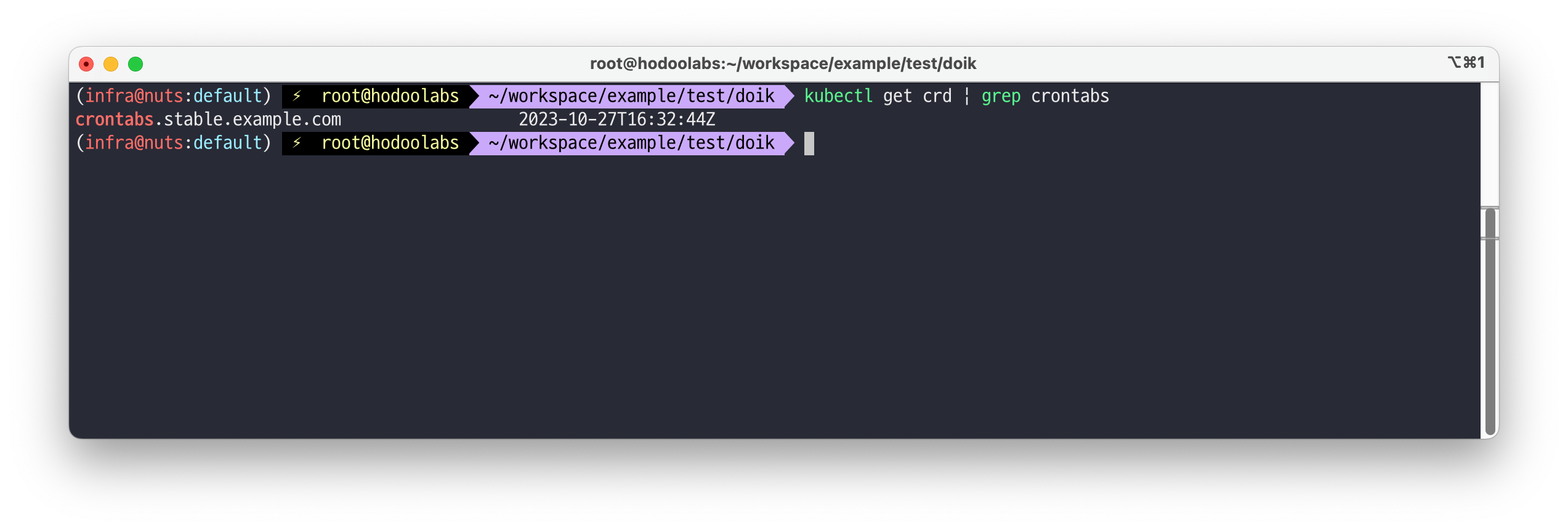
# CRD 생성 kubectl apply -f resourcedefinition.yaml # CRD 생성 확인 kubectl get crd | grep crontabs
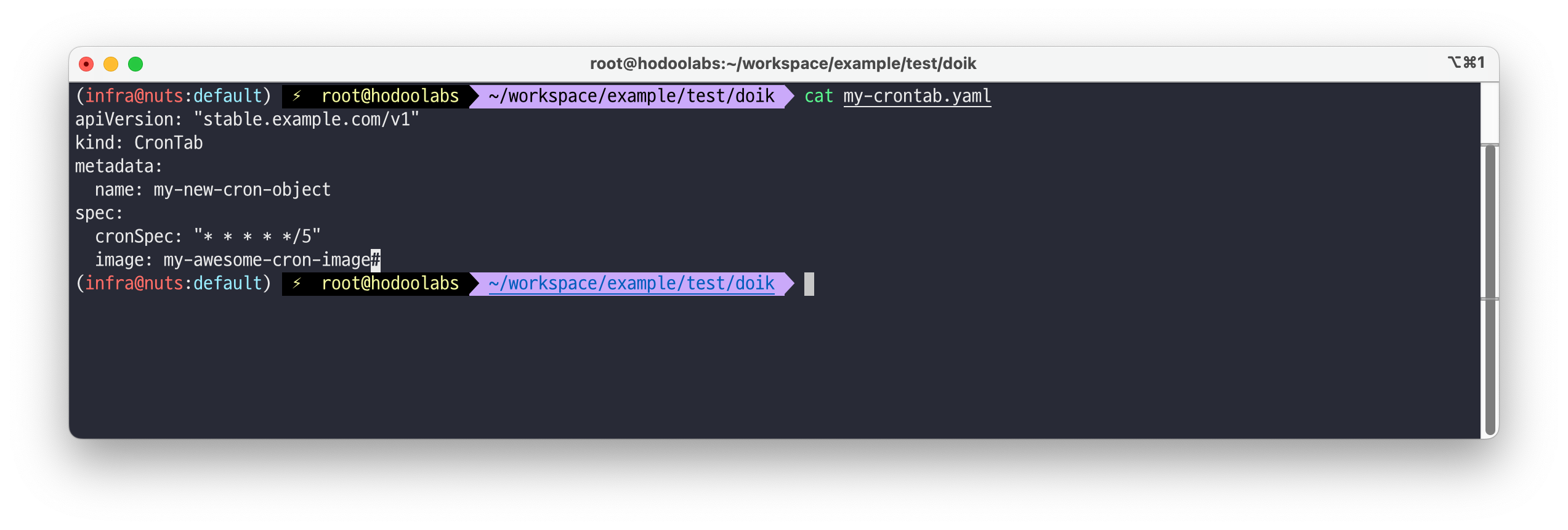
# CR 샘플 YAML 파일 확인 curl -s -O https://raw.githubusercontent.com/gasida/DOIK/main/2/my-crontab.yaml cat my-crontab.yaml | yh
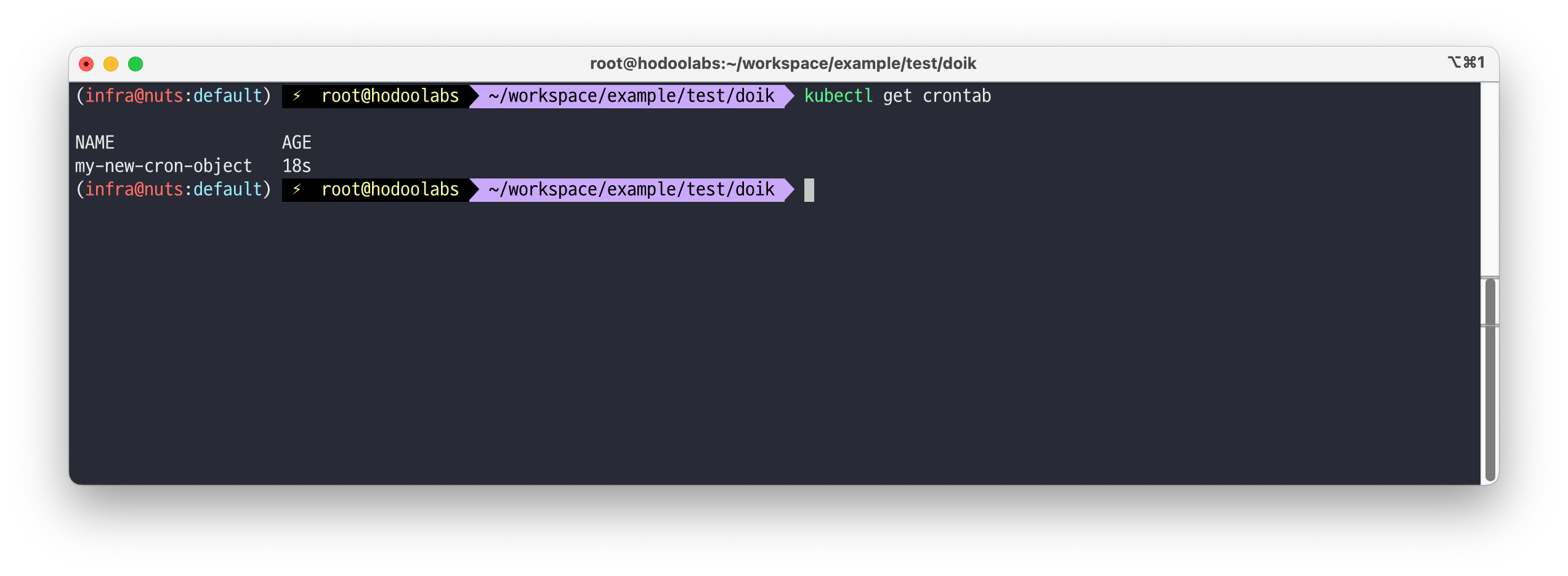
# CR 생성 kubectl apply -f my-crontab.yaml # 생성된 리소스 확인 kubectl get crontab
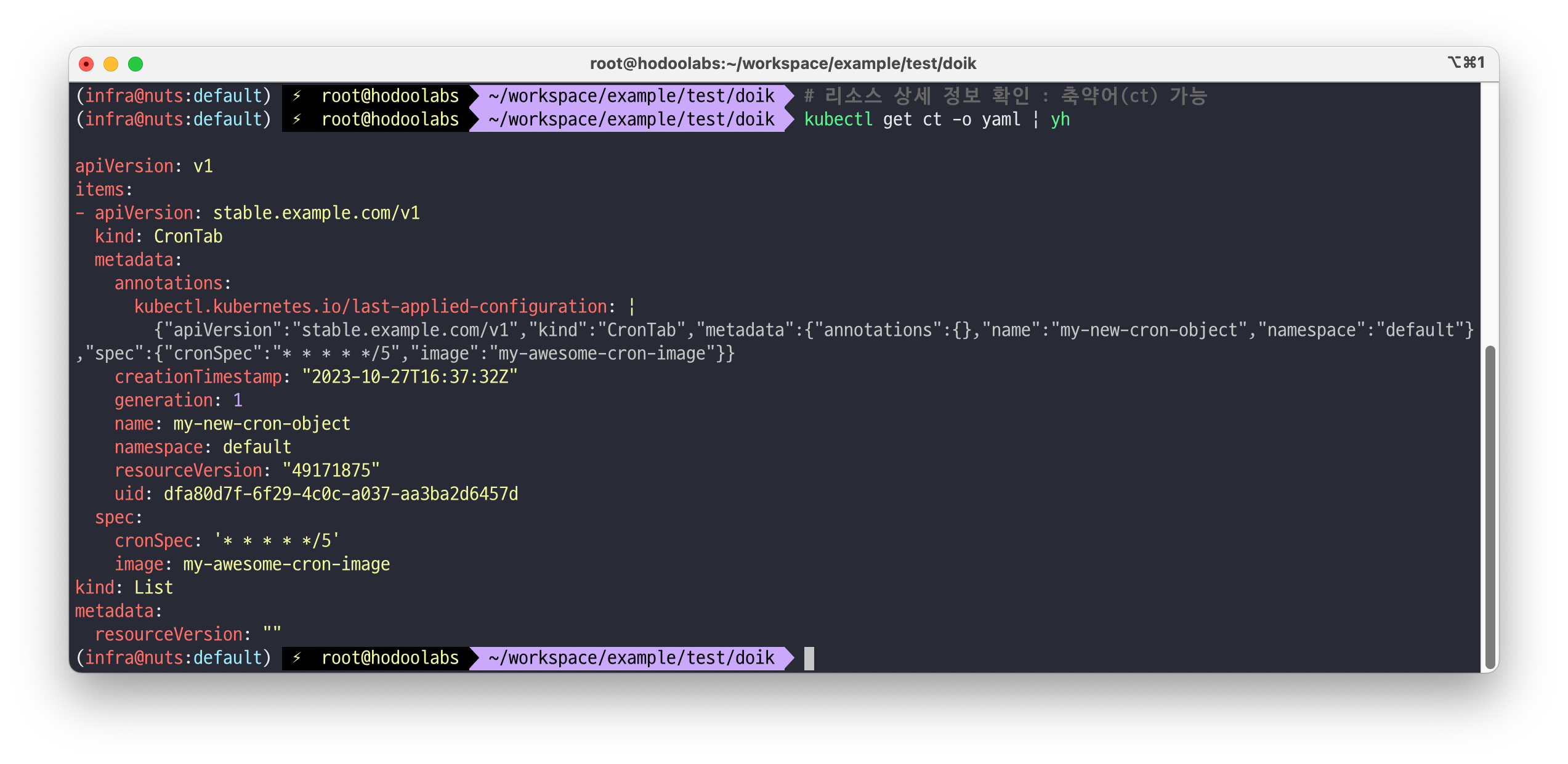
# 리소스 상세 정보 확인 : 축약어(ct) 가능 kubectl get ct -o yaml | yh
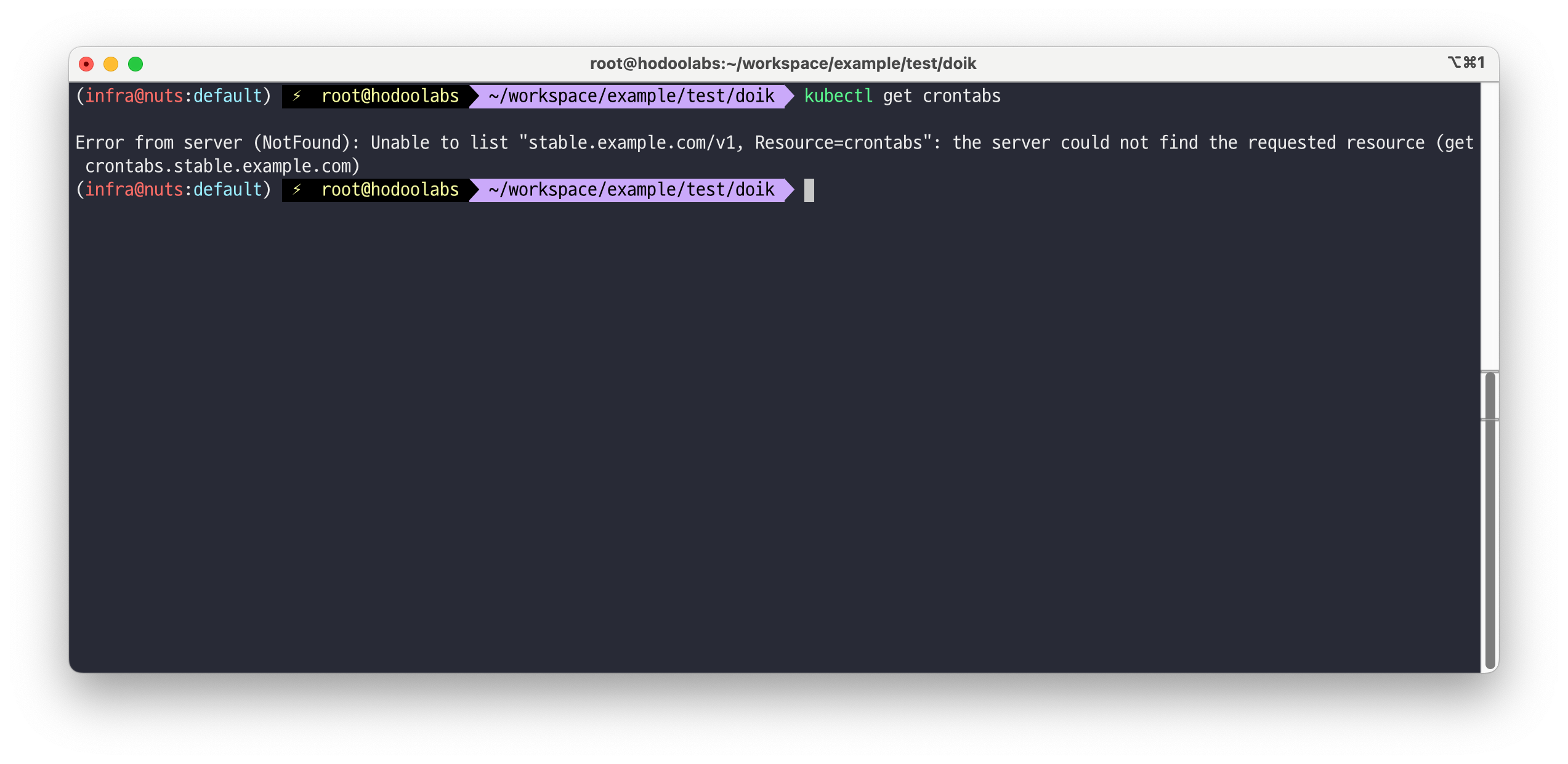
# 현재는 리소스만 생성한 상태이고, 어떤 동작을 수행해야 하는지 아무런 정보가 없습니다. # 실제 동작을 수행하기 위해서는 Custom Controller 의 도움이 필요합니다. # Operator 패턴이란 Custom Resource + Custom Controller 조합으로 특정 애플리케이션이나 서비스의 생성과 삭제를 관리하는 패턴을 말함 # Operator 패턴을 통해 쿠버네티스 코어 API에 포함되지 않은 애플리케이션을 마치 쿠버네티스 Native 리소스처럼 동작하게끔 만들 수 있음 # CRD 삭제 kubectl delete -f resourcedefinition.yaml # 리소스 정보 확인 시 에러 발생 kubectl get crontabs Error from server (NotFound): Unable to list "stable.example.com/v1, Resource=crontabs": the server could not find the requested resource (get crontabs.stable.example.com)
오퍼레이터 허브 (Capability Levels 성숙도 확인)
데이터베이스 오퍼레이터 종류 - 링크

오퍼레이터 동작 예시 (inlets-operator) 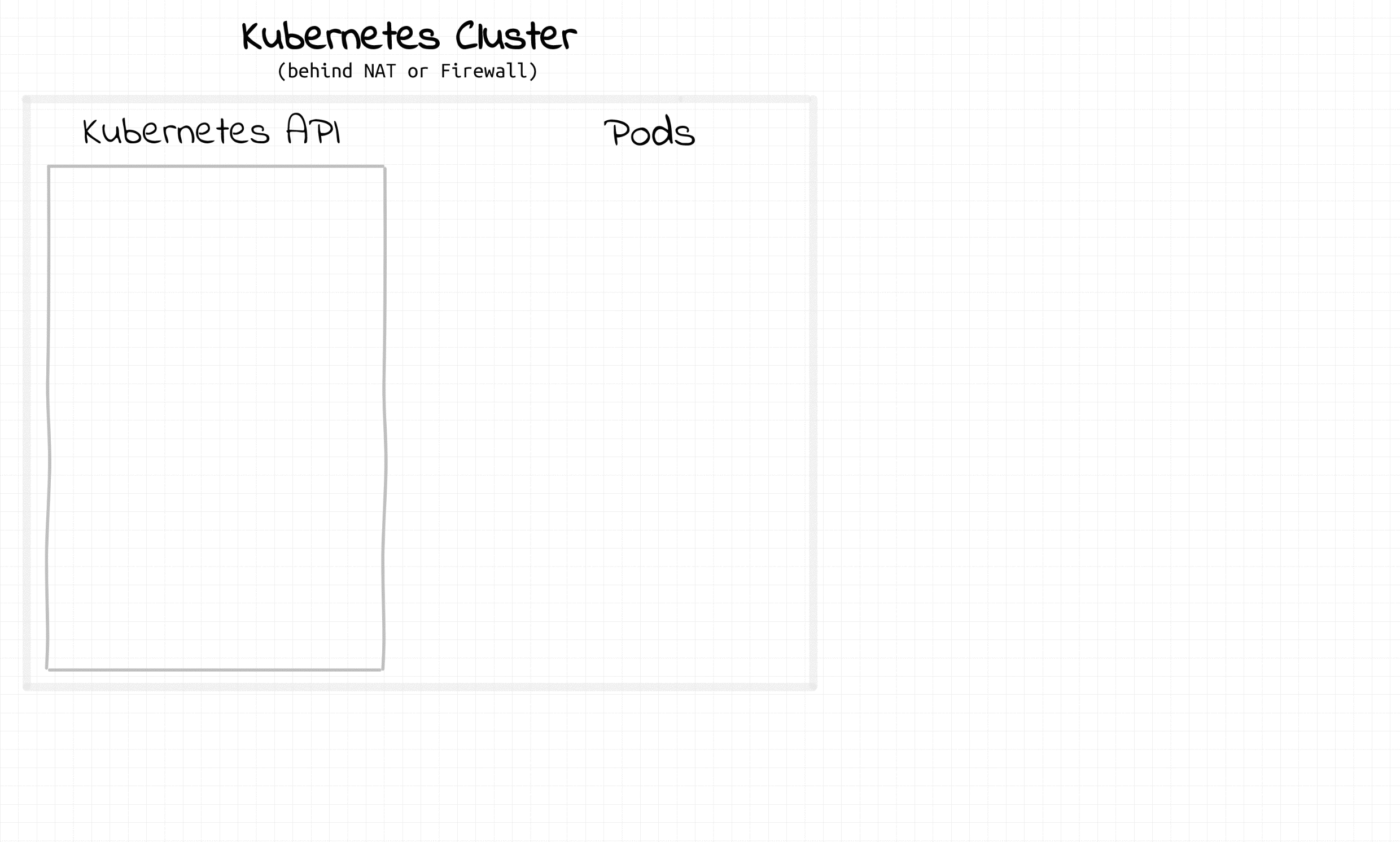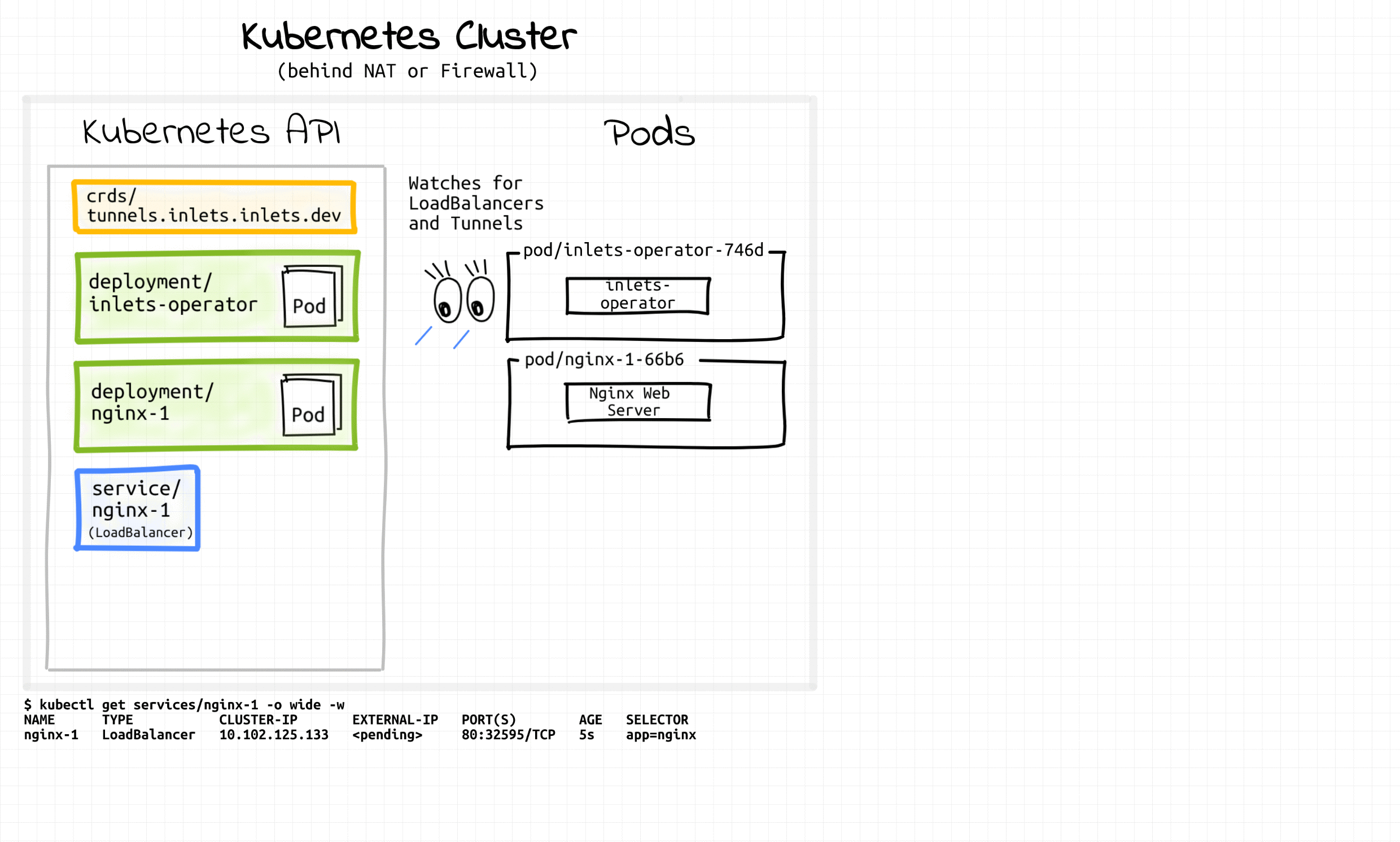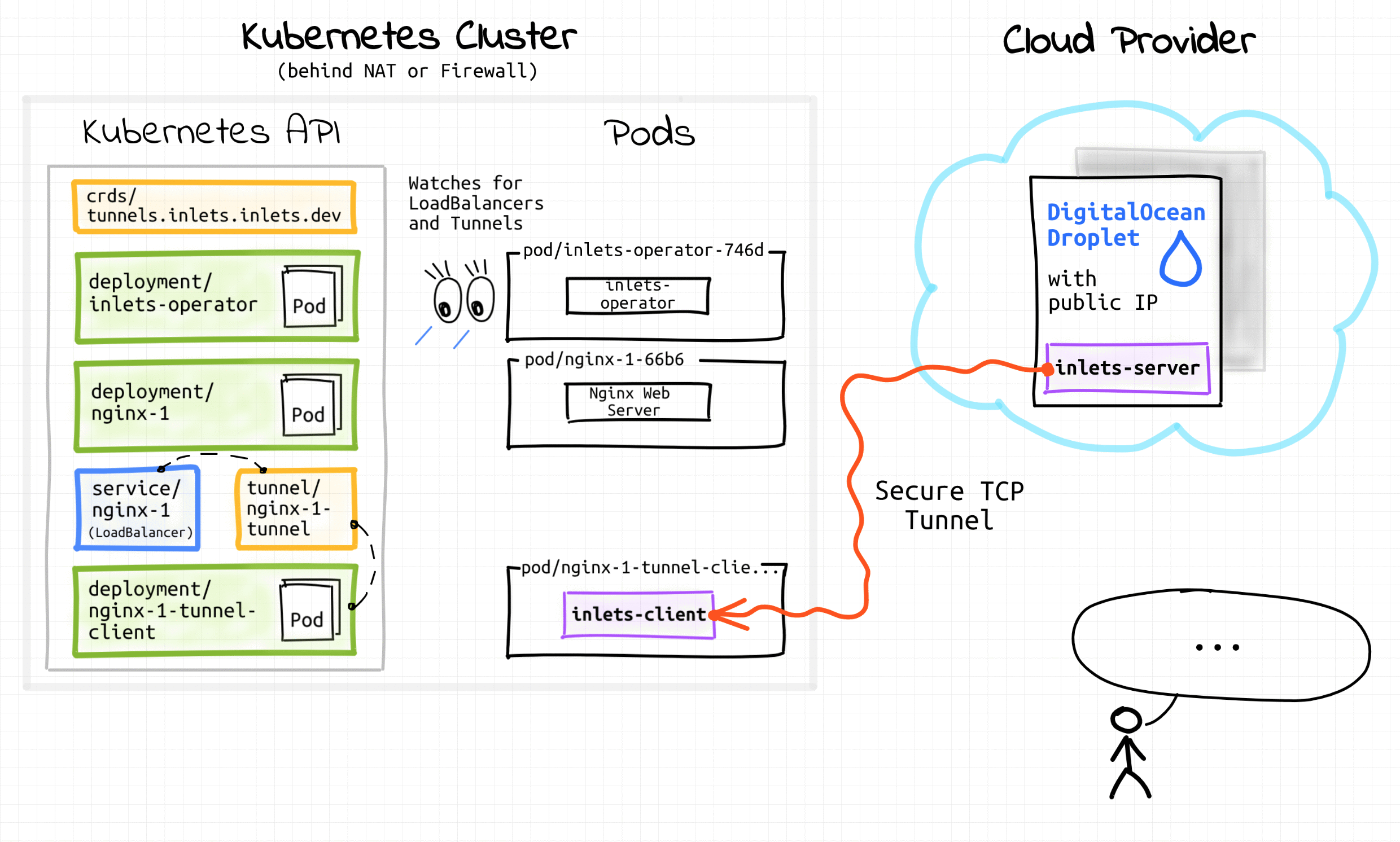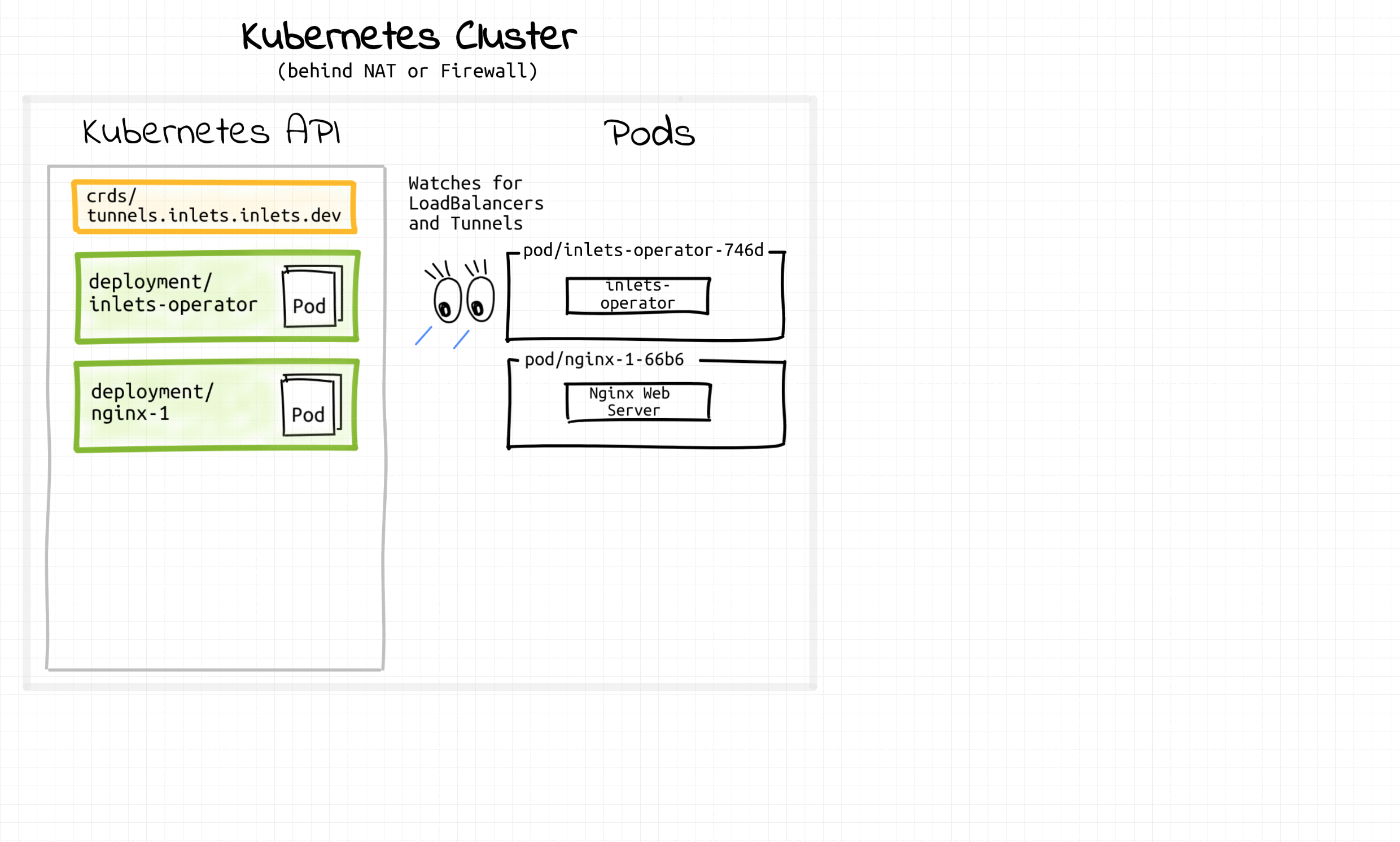
출처 - https://iximiuz.com/en/posts/kubernetes-operator-pattern/
👉 Step 02. InnoDB 클러스터
MySQL 서버 자체적으로 페일오버 Failover 를 처리하는 기능을 제공하지 않으므로 사용자는 장애가 발생했을 때 레플리카 서버가 새로운 소스 서버가 될 수 있도록 일련의 작업들을 수행해야 한다.
즉 레플리카 서버에 설정된 읽기 모드를 해제해야 하며, 스플릿 브레인 Split-Brain 현상을 방지하기 위해 장애가 발생한 소스 서버에서 데이터 변경을 실행하지 못하도록 해야 한다.
그리고 애플리케이션 서버는 새로운 소스 서버를 바라보도록 커넥션 설정을 변경해야 한다.
이러한 작업들은 모두 수동으로 처리할 수 밖에 없으며 완료되기까지 적지 않은 시간이 소요된다.
MySQL 5.7.17 버전에서 빌트인 형태의 HA 솔루션인 InnnDB 클러스터가 도입되면서 사용자는 좀 더 편리하게 고가용성을 실현할 수 있게 됐다.
InnoDB 클러스터 아키텍처
그룹 복제 Group Replication
소스 서버의 데이터를 레플리카 서버로 동기화하는 기본적인 복제 역할뿐만 아니라 복제에 참여하는 MySQL 서버들에 대한 자동화된 멤버쉽 관리 (그룹에 새로운 멤버의 추가 및 제거 등) 역할을 담당한다.MySQL 라우터
애플리케이션 서버와 MySQL 서버 사이에서 동작하는 미들웨어 프로그램으로 애플리케이션이 실행한 쿼리를 적절한 MySQL 서버로 전달하는 프락시 Proxy 역할을 한다.MySQL 셸
기존 MySQL 클라이언트보다 좀 더 확장된 기능을 가진 새로운 클라이언트 프로그램으로, 기본적인 SQL문 실행뿐만 아니라 자바스크립트 및 파이썬 기반의 스크립트 작성 기능과 MySQL 서버에 대한 클러스터 구성 등의 어드민 작업을 할 수 있게 하는 API AdminAPI 를 제공한다.
InnoDB 클러스터
- InnoDB 클러스터에서 데이터가 저장되는 MySQL 서버들은 그룹 복제 형태로 복제가 구성되며, 각 서버는 읽기/쓰기가 모두 가능한 프라이머리 Primary 혹은 읽기만 가능한 세컨더리 Secondary 중 하나의 역할로 동작하게 된다. 여기서 프라이머리는 기존 MySQL 복제에서는 소스 서버라 할 수 있으며, 세컨더리는 레플리카 서버라고 할 수 있다.
- 그룹 복제에 설정된 모드에 따라 복제 그룹 내에서 프라이머리는 하나만 존재할 수 도 있고 여러 대가 존재할 수도 있다. 그룹 복제에서는 InnoDB 스토리지 엔진만 사용될 수 있는데, 이것이 “InnoDB” 클러스터라고 명명된 이유라 할 수 있다.
- 또한 그룹 복제를 구성할 때 고가용성을 위해 MySQL 서버를 최소 3대 이상으로 구성해야 하는데, 이는 3대로 구성했을 때부터 MySQL 서버 한 대에 장애가 발생하더라도 복제 그룹이 정상적으로 동작하기 때문이다.
MySQL 라우터
- 클라이언트는 MySQL 서버로 직접 접근해서 쿼리를 실행하는 것이 아니라 MySQL 라우터에 연결해서 쿼리를 실행한다.
- MySQL 라우터는 InnoDB 클러스터로 구성된 MySQL 서버들에 대한 메타데이터 정보를 지니며, 이를 바탕으로 클라이언트로부터 실행된 쿼리를 클러스터 내 적절한 MySQL 서버로 전달한다.
- 따라서 클라이언트는 현재 InnoDB 클러스터가 어떤 서버로 구성돼 있는지 알고 있을 필요가 없으며, 커넥션 정보에는 MySQL 라우터 서버만 설정해두면 된다.
MySQL 셸
- MySQL 셸은 사용자가 손쉽게 InnoDB 클러스터를 생성하고 관리할 수 있도록 API 를 제공하며, 그외에서 InnoDB 클러스터의 상태를 확인하거나 MySQL 서버의 설정을 변경하는 것과 같은 여러 가지 기능들을 제공한다. MySQL 셸에서 InnoDB 클러스터와 관련된 작업들을 진행할 때는 InnoDB 클러스터 내 MySQL 서버에 직접 연결해 작업해야 하며, 단순히 쿼리를 실행하는 경우에는 MySQL 라우터로 연결해서 처리할 수도 있다.
장애 시 동작
- InnoDB 클러스터에서는 MySQL 서버에 장애가 발생하면 그룹 복제가 먼저 이를 감지해서 자동으로 해당 서버를 복제 그룹에서 제외시키며, MySQL 라우터는 이러한 복제 토폴로지 변경을 인지하고 자신이 가진 메타데이터를 갱신해서 클라이언트로부터 실행된 쿼리가 현재 복제 그룹에서 정상적으로 동작하는 MySQL 서버로만 전달될 수 있도록 한다.
- 즉 기존에는 전부 수동으로 장애 복구 처리를 해야 했던 부분들이 InnoDB 클러스터에서는 모두 자동으로 처리되며, 클라이언트에서도 MySQL에 대한 커넥션 설정 변경 등과 같은 부수적인 작업을 수행할 필요 없이 기존에 설정된 그대로 쿼리를 실행하면 된다.
MySQL 라우터 :
애플리케이션 서버와 MySQL 서버 사이에서 동작하는 미들웨어로 애플리케이션이 실행한 쿼리를 적절한 MySQL 서버로 전달하는 프락시 Proxy 역할 - 링크
- 주요 기능 : InnoDB 클러스터의 MySQL 구성 변경 자동 감지, 쿼리 부하 분산, 자동 페일오버
- MySQL 라우터는 클러스터 내 MySQL 서버들에 대한 정보를 메모리에 캐시하고 있으며, 주기적으로 이 정보를 갱신한다. 서버 구성 변경 시 자동 감지 및 변경 반영.
- MySQL 라우터 여러 MySQL 서버로 부하 분산 수행 가능. 부하 분산 방식 지정 가능.
👉 Step 03. MySQL Operator for Kubernetes
📚 소개
MySQL Operator for Kubernetes : 쿠버네티스 클러스터로 MySQL InnoDB Cluster 관리, MySQL 8.0.29 버전과 함께 GA 됨 - 링크
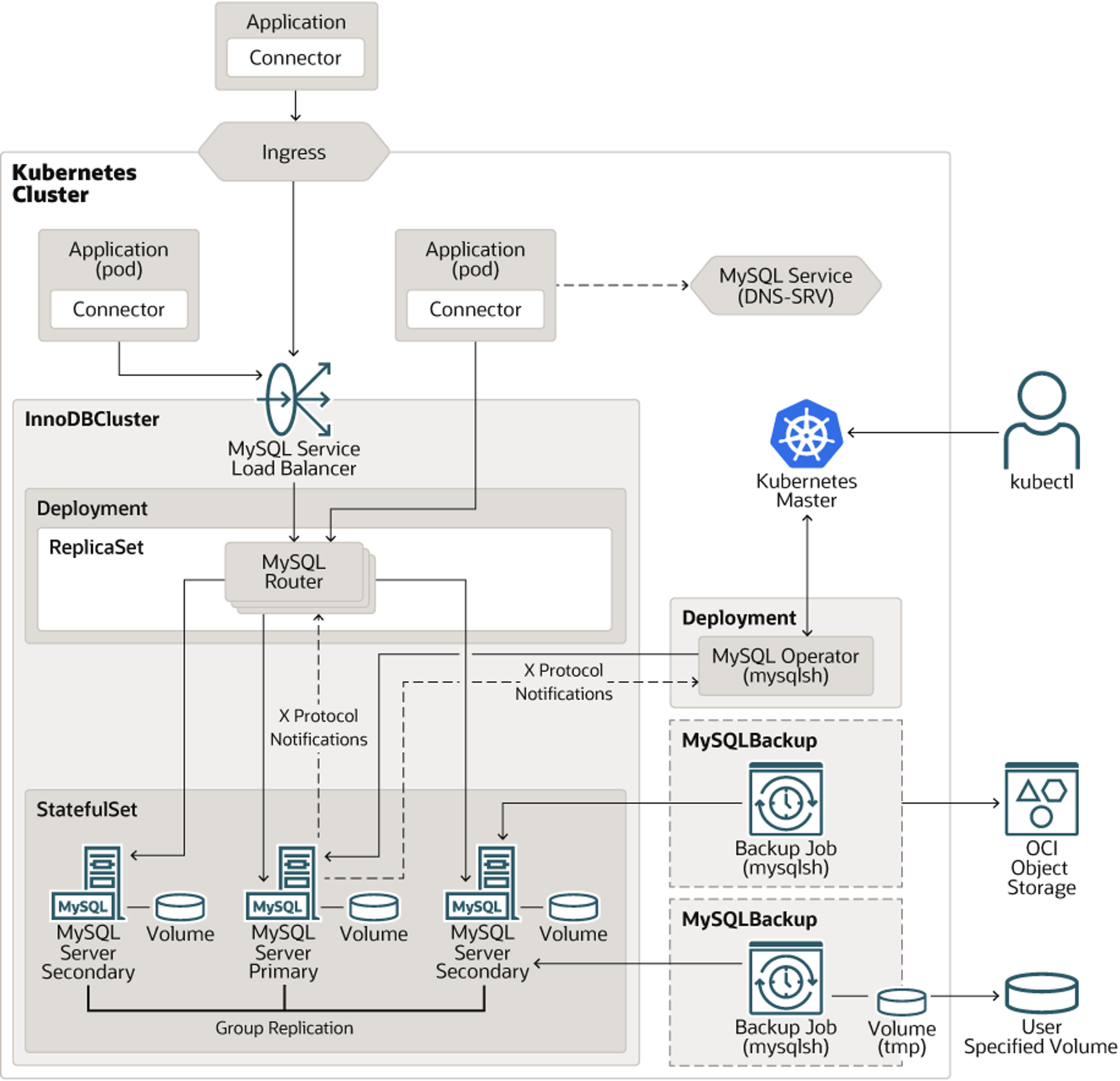
출처 - https://dev.mysql.com/doc/mysql-operator/en/mysql-operator-introduction.html
MySQL Operator for Kubernets : 1개 이상의 MySQL InnoDB Cluster 관리
MySQL InnoDB Cluster : 쿠버네티스 API 서버를 통해서 관련 리소스 배포
- 스테이트풀셋 : MySQL Server instances - MySQL 서버
- 디플로이먼트 : MySQL Routers - Proxy 역할로 애플리케이션의 쿼리를 서버에 전달, RW/RO
- 서비스 : MySQL Router, 개별 MySQL 서버로 접속 주소 생성 (Headless 서비스, SRV 레코드)
- MySQL Shell : MySQL Router 와 MySQL Server 에 툴 포함, MySQL 클라이언트 보다 좀 더 확장 기능 제공, 클러스터 관리 가능(AdminAPI)
- 그외 : 컨피그맵(MySQL Server 설정) , 시크릿(시스템 등 암호들)
📚 설치
MySQL Operator 설치
with Helm - [Docs] [Chart] [CR] [Release] [Release2]# Repo 추가 helm repo add mysql-operator https://mysql.github.io/mysql-operator/ helm repo update # 실험 버전 설치 : 차트 버전(--version 2.1.0), 애플리케이션 버전(8.1.0-2.1.4) # 안정 버전 설치 : 차트 버전(--version 2.0.11), 애플리케이션 버전(8.0.34-2.0.11) # 23.10.28 기준 차트 버전 2.1.0이 설치가 되지 않아 2.0.12로 설치하였습니다. helm install mysql-operator mysql-operator/mysql-operator --namespace mysql-operator --create-namespace --version 2.0.12 helm get manifest mysql-operator -n mysql-operator # 설치 확인 kubectl get deploy,pod -n mysql-operator # CRD 확인 kubectl get crd | egrep 'mysql|zalando' clusterkopfpeerings.zalando.org 2023-10-16T13:30:46Z innodbclusters.mysql.oracle.com 2023-10-16T13:30:46Z kopfpeerings.zalando.org 2023-10-16T13:30:46Z mysqlbackups.mysql.oracle.com 2023-10-16T13:30:46Z ## (참고) CRD 상세 정보 확인 kubectl describe crd innodbclusters.mysql.oracle.com ...(생략)... # (참고) 삭제 helm uninstall mysql-operator -n mysql-operator && kubectl delete ns mysql-operator
MySQL InnoDB Cluster 설치 with Helm - [Docs] [Chart]
# (참고) Helm Chart Default Values 확인 helm show values mysql-operator/mysql-innodbcluster ...(생략)... # 파라미터 파일 생성 cat <<EOT> mycnf-values.yaml credentials: root: password: sakila serverConfig: mycnf: | [mysqld] max_connections=300 default_authentication_plugin=mysql_native_password tls: useSelfSigned: true EOT # 차트 설치(기본값) : root 사용자(root), 호스트(%), 서버인스턴스(파드 3개), 라우터인스턴스(파드 1개), serverVersion(8.1.0) # root 사용자 암호(sakila), tls.useSelfSigned(사용), 네임스페이스 생성 및 적용(mysql-cluster) helm install mycluster mysql-operator/mysql-innodbcluster --namespace mysql-cluster --version 2.0.12 -f mycnf-values.yaml --create-namespace helm get values mycluster -n mysql-cluster helm get manifest mycluster -n mysql-cluster # (옵션) 모니터링 << pv 는 왜 mysql-cluster 네임스페이스내에서 안 보일까요? watch kubectl get innodbcluster,sts,pod,pvc,svc -n mysql-cluster # 설치 확인 kubectl get innodbcluster,sts,pod,pvc,svc,pdb,all -n mysql-cluster kubectl df-pv kubectl resource-capacity ## MySQL InnoDB Cluster 구성요소 확인 kubectl get InnoDBCluster -n mysql-cluster NAME STATUS ONLINE INSTANCES ROUTERS AGE mycluster ONLINE 3 3 1 6m20s
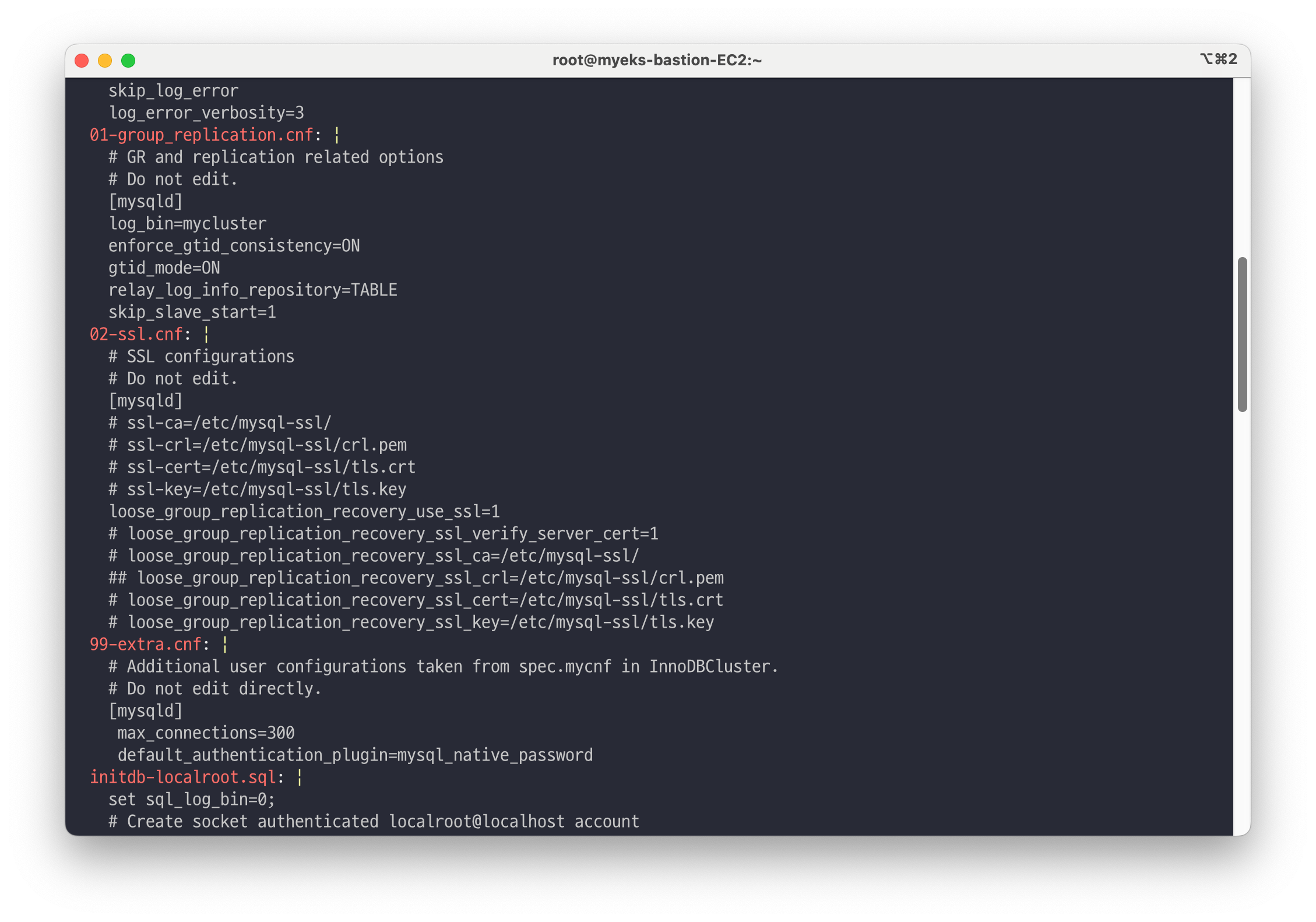
## 이벤트 확인 kubectl describe innodbcluster -n mysql-cluster | grep Events: -A30 ...(생략)... ## MySQL InnoDB Cluster 초기 설정 확인 kubectl get configmap -n mysql-cluster mycluster-initconf -o json | jq -r '.data["my.cnf.in"]' kubectl get configmap -n mysql-cluster mycluster-initconf -o yaml | yh kubectl describe configmap -n mysql-cluster mycluster-initconf ...(생략)... 01-group_replication.cnf: ---- # GR and replication related options # Do not edit. [mysqld] log_bin=mycluster enforce_gtid_consistency=ON gtid_mode=ON # 그룹 복제 모드 사용을 위해서 GTID 활성화 relay_log_info_repository=TABLE # 복제 메타데이터는 데이터 일관성을 위해 릴레이로그를 파일이 아닌 테이블에 저장 skip_slave_start=1 ...(생략)... 99-extra.cnf: ---- # Additional user configurations taken from spec.mycnf in InnoDBCluster. # Do not edit directly. [mysqld] max_connections=300 # max_connections default 기본값은 151 default_authentication_plugin=mysql_native_password ...(생략)...
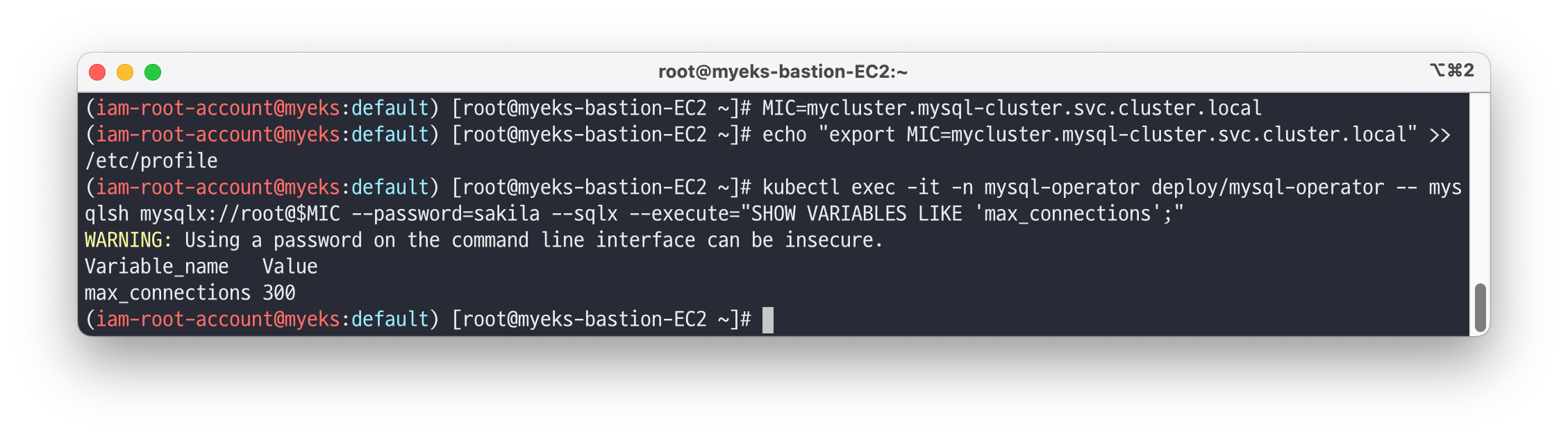
## 서버인스턴스 확인(스테이트풀셋) : 3개의 노드에 각각 파드 생성 확인, 사이드카 컨테이너 배포 kubectl get sts -n mysql-cluster; echo; kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=database -owide ## 프로브 확인(Readiness, Liveness, Startup) kubectl describe pod -n mysql-cluster mycluster-0 | egrep 'Liveness|Readiness:|Startup' ## 서버인스턴스가 사용하는 PV(PVC) 확인 : AWS EBS 볼륨 확인해보기 kubectl get sc kubectl df-pv kubectl get pvc,pv -n mysql-cluster ## 서버인스턴스 각각 접속을 위한 헤드리스 Headless 서비스 확인 kubectl describe svc -n mysql-cluster mycluster-instances ...(생략)... kubectl get svc,ep -n mysql-cluster mycluster-instances NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE mycluster-instances ClusterIP None <none> 3306/TCP,33060/TCP,33061/TCP 19m ## 라우터인스턴스(디플로이먼트) 확인 : 1대의 파드 생성 확인 kubectl get deploy -n mysql-cluster;kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=router ## 라우터인스턴스 접속을 위한 서비스(ClusterIP) 확인 kubectl get svc,ep -n mysql-cluster mycluster # max_connections 설정 값 확인 : MySQL 라우터를 통한 MySQL 파드 접속 >> Helm 차트 설치 시 파라미터러 기본값(151 -> 300)을 변경함 MIC=mycluster.mysql-cluster.svc.cluster.local echo "export MIC=mycluster.mysql-cluster.svc.cluster.local" >> /etc/profile kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MIC --password=sakila --sqlx --execute="SHOW VARIABLES LIKE 'max_connections';"
# (참고) 삭제 helm uninstall mycluster -n mysql-cluster && kubectl delete ns mysql-cluster

📚 MySQL 서버 접속
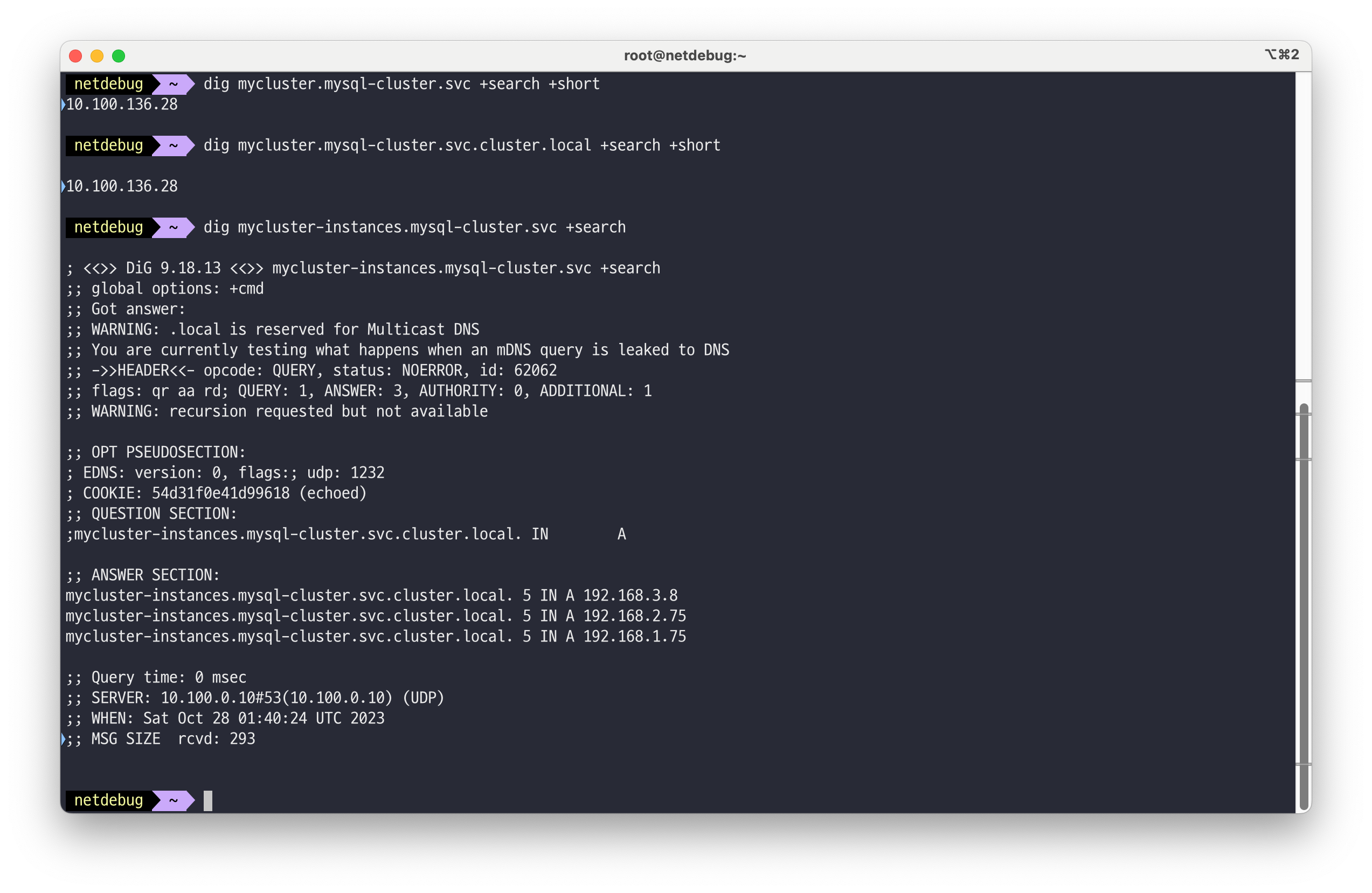
Headless 서비스 주소로 개별 MySQL 서버(파드)로 직접 접속
# MySQL 라우터 접속을 위한 서비스 정보 확인 : 실습 환경은 Cluster-IP Type kubectl get svc -n mysql-cluster mycluster # MySQL 서버(파드) 접속을 위한 서비스 정보 확인 : Headless 서비스 kubectl get svc -n mysql-cluster mycluster-instances kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=database -owide # netshoot 파드에 zsh 접속해서 DNS 쿼리 수행 kubectl run -it --rm netdebug --image=nicolaka/netshoot --restart=Never -- zsh ------- # dig 툴로 도메인 질의 : <서비스명>.<네임스페이스>.svc 혹은 <서비스명>.<네임스페이스>.svc.cluster.local # 아래 도메인 주소로 접근 시 MySQL 라우터를 통해서 MySQL 서버(파드)로 접속됨 dig mycluster.mysql-cluster.svc +search +short dig mycluster.mysql-cluster.svc.cluster.local +search +short # Headless 서비스 주소로 개별 MySQL 서버(파드)로 직접 접속을 위한 DNS 쿼리 dig mycluster-instances.mysql-cluster.svc +search dig mycluster-instances.mysql-cluster.svc.cluster.local +short # MySQL 서버(파드)마다 고유한 SRV 레코드가 있고, 해당 도메인 주소로 접속 시 MySQL 라우터를 경유하지 않고 지정된 MySQL 서버(파드)로 접속됨 dig mycluster-instances.mysql-cluster.svc.cluster.local SRV ..(생략)... ;; ADDITIONAL SECTION: mycluster-2.mycluster-instances.mysql-cluster.svc.cluster.local. 30 IN A 172.16.1.11 mycluster-0.mycluster-instances.mysql-cluster.svc.cluster.local. 30 IN A 172.16.3.14 mycluster-1.mycluster-instances.mysql-cluster.svc.cluster.local. 30 IN A 172.16.2.12 # zsh 빠져나오기 exit -------
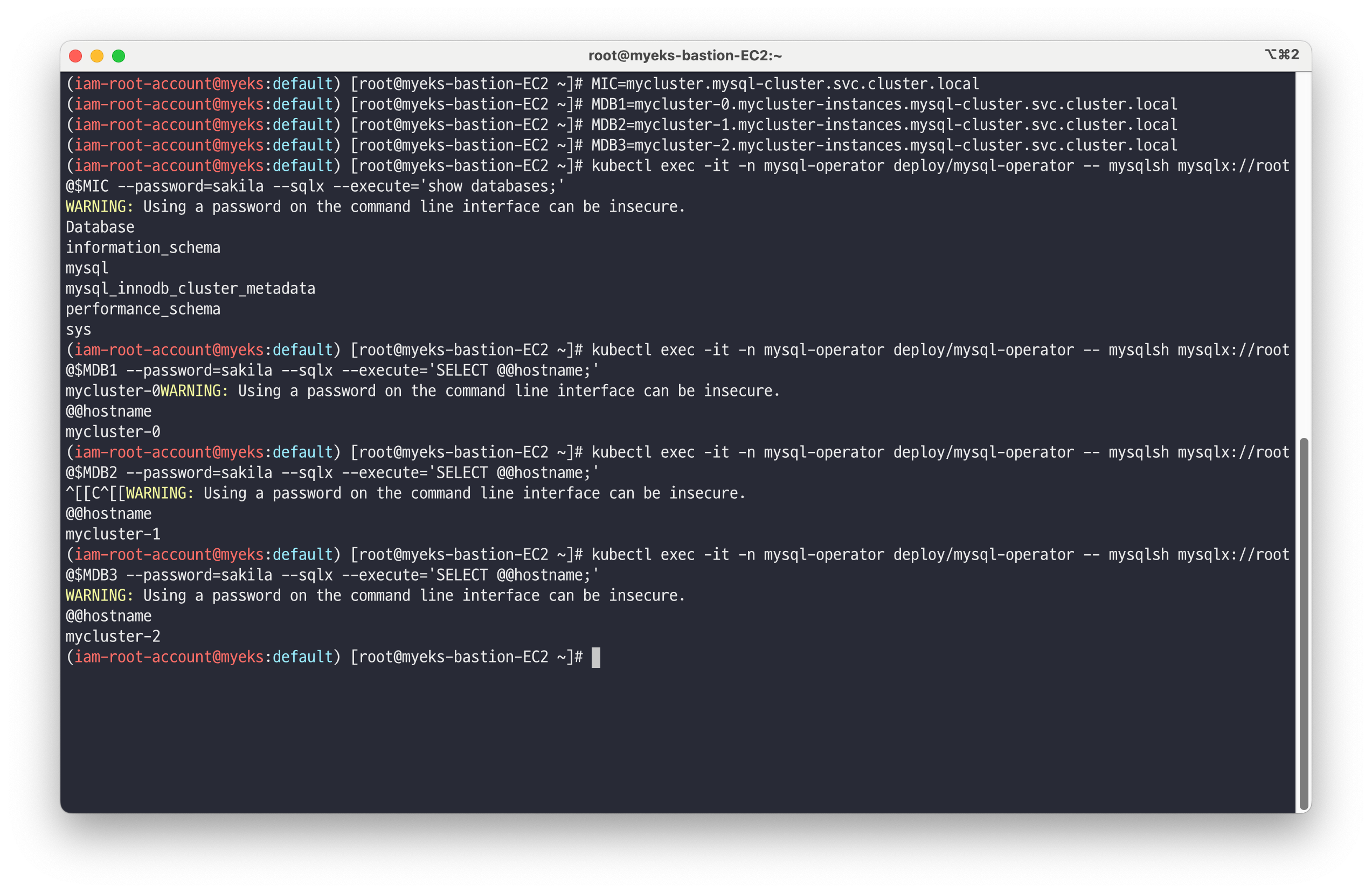
# 접속 주소 변수 지정 MIC=mycluster.mysql-cluster.svc.cluster.local MDB1=mycluster-0.mycluster-instances.mysql-cluster.svc.cluster.local MDB2=mycluster-1.mycluster-instances.mysql-cluster.svc.cluster.local MDB3=mycluster-2.mycluster-instances.mysql-cluster.svc.cluster.local # MySQL 라우터를 통한 MySQL 파드 접속 #kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MIC --password=sakila kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MIC --password=sakila --sqlx --execute='show databases;' ...(생략)... kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MIC --password=sakila --sqlx --execute="SHOW VARIABLES LIKE 'max_connections';" *Variable_name Value max_connections 151* # 개별 MySQL 파드 접속 : 헤드리스 서비스 kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MDB1 --password=sakila --sqlx --execute='SELECT @@hostname;' *mycluster-0* kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MDB2 --password=sakila --sqlx --execute='SELECT @@hostname;' *mycluster-1* kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MDB3 --password=sakila --sqlx --execute='SELECT @@hostname;' *mycluster-2*
다수의 MySQL 클라이언트 파드를 통해 MySQL 라우터 시 부하분산 확인
# mysql 클라이언트 파드 YAML 내용 확인 curl -s https://raw.githubusercontent.com/gasida/DOIK/main/2/myclient-new.yaml -o myclient.yaml cat myclient.yaml | yh # myclient 파드 1대 배포 : envsubst 활용 PODNAME=myclient1 envsubst < myclient.yaml | kubectl apply -f - # myclient 파드 추가로 2대 배포 for ((i=2; i<=3; i++)); do PODNAME=myclient$i envsubst < myclient.yaml | kubectl apply -f - ; done # myclient 파드들 확인 kubectl get pod -l app=myclient # 파드1에서 mysql 라우터 서비스로 접속 확인 : TCP 3306 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SHOW DATABASES;" kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME,@@SERVER_ID;" kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME,host from information_schema.processlist WHERE ID=connection_id();" # 파드1에서 mysql 라우터 서비스로 접속 확인 : TCP 6446 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6446 -e "SELECT @@HOSTNAME,@@SERVER_ID;" # 파드1에서 mysql 라우터 서비스로 접속 확인 : TCP 6447 >> 3초 간격으로 확인! kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "SELECT @@HOSTNAME,@@SERVER_ID;" 3초 간격 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "SELECT @@HOSTNAME,@@SERVER_ID;" # 파드들에서 mysql 라우터 서비스로 접속 확인 : MySQL 라우터정책이 first-available 라서 무조건 멤버 (프라이머리) 첫번쨰로 전달, host 에는 라우터의 IP가 찍힌다. for ((i=1; i<=3; i++)); do kubectl exec -it myclient$i -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "select @@hostname, @@read_only, @@super_read_only";echo; done for ((i=1; i<=3; i++)); do kubectl exec -it myclient$i -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME,host from information_schema.processlist WHERE ID=connection_id();";echo; done for ((i=1; i<=3; i++)); do kubectl exec -it myclient$i -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME;USE employees;SELECT * FROM employees LIMIT $i;";echo; done # 파드들에서 mysql 라우터 서비스로 접속 확인 : TCP 6447 접속 시 round-robin-with-fallback 정책에 의해서 2대에 라운드 로빈(부하분산) 접속됨 for ((i=1; i<=3; i++)); do kubectl exec -it myclient$i -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "SELECT @@HOSTNAME,host from information_schema.processlist WHERE ID=connection_id();";echo; done for ((i=1; i<=3; i++)); do kubectl exec -it myclient$i -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "SELECT @@HOSTNAME;USE employees;SELECT * FROM employees LIMIT $i;";echo; done for ((i=1; i<=3; i++)); do kubectl exec -it myclient$i -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "select @@hostname, @@read_only, @@super_read_only";echo; done

반복적으로 데이터 INSERT 및 MySQL 서버에 복제 확인
세컨더리파드에 INSERT 시도
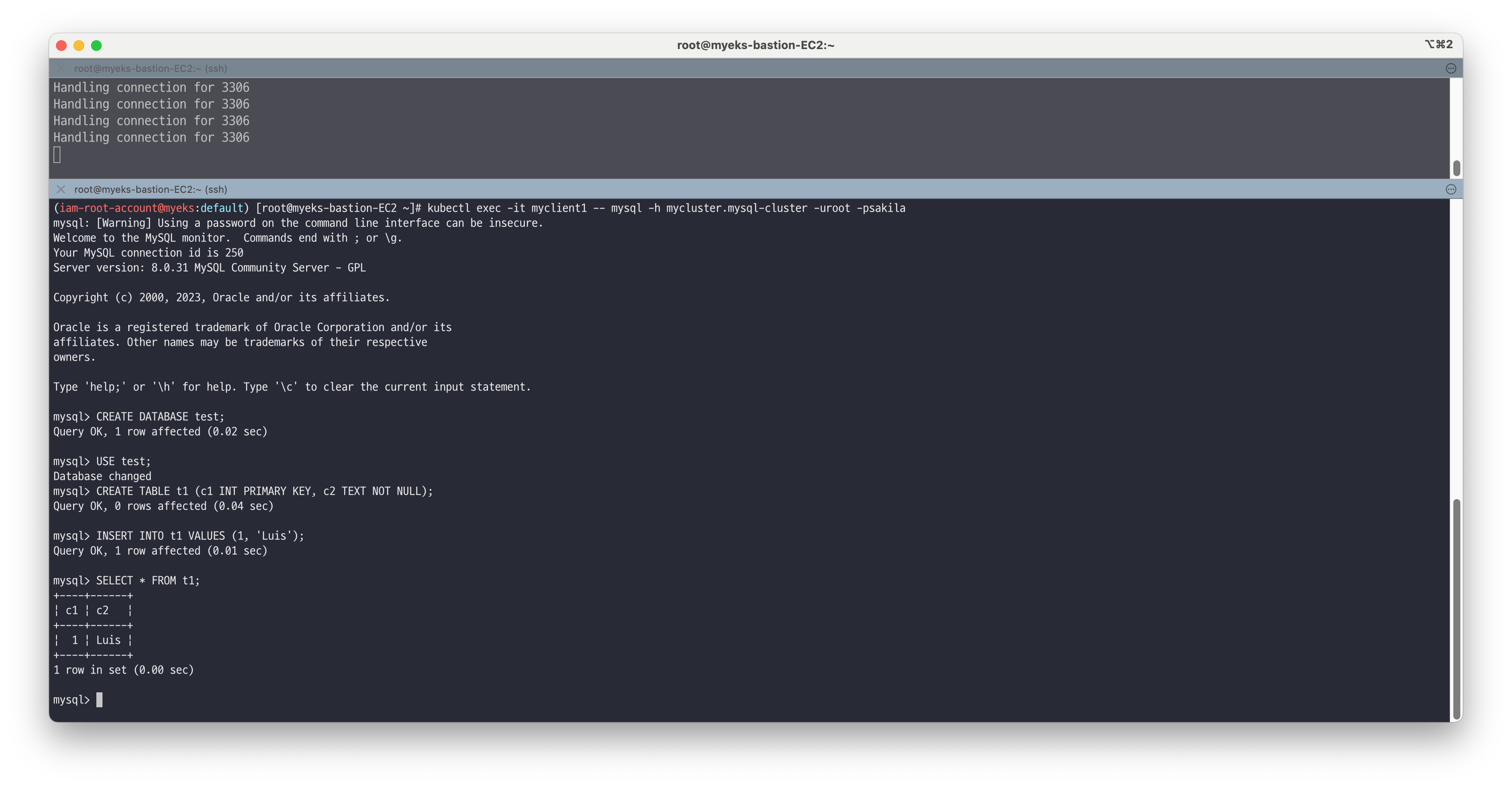
# 파드1에서 mysql 라우터 서비스로 접속 확인 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -------------------- # 간단한 데이터베이스 생성 CREATE DATABASE test; USE test; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL); INSERT INTO t1 VALUES (1, 'Luis'); SELECT * FROM t1; exit --------------------
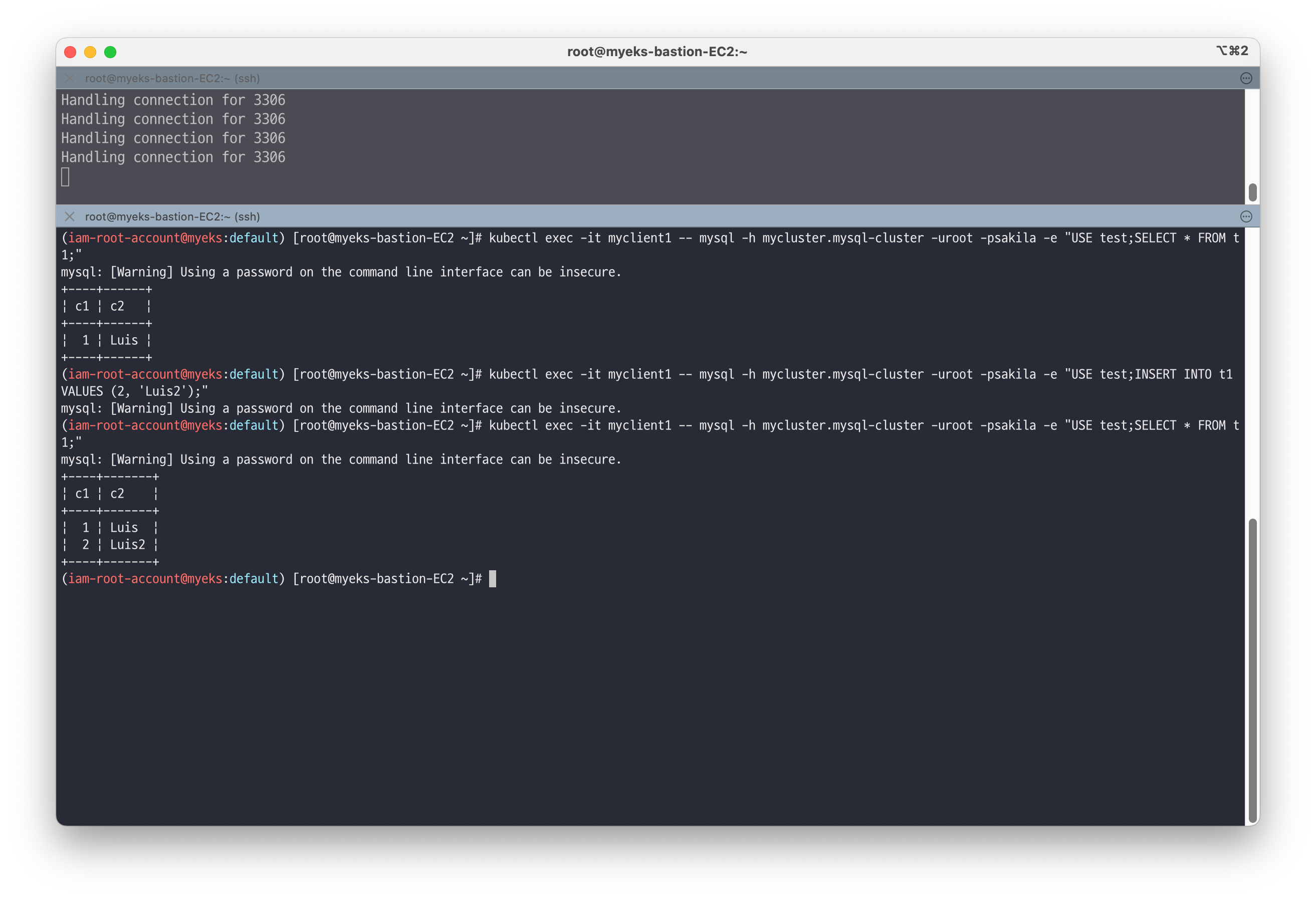
# 조회 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "USE test;SELECT * FROM t1;" # 추가 후 조회 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "USE test;INSERT INTO t1 VALUES (2, 'Luis2');" kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "USE test;SELECT * FROM t1;"
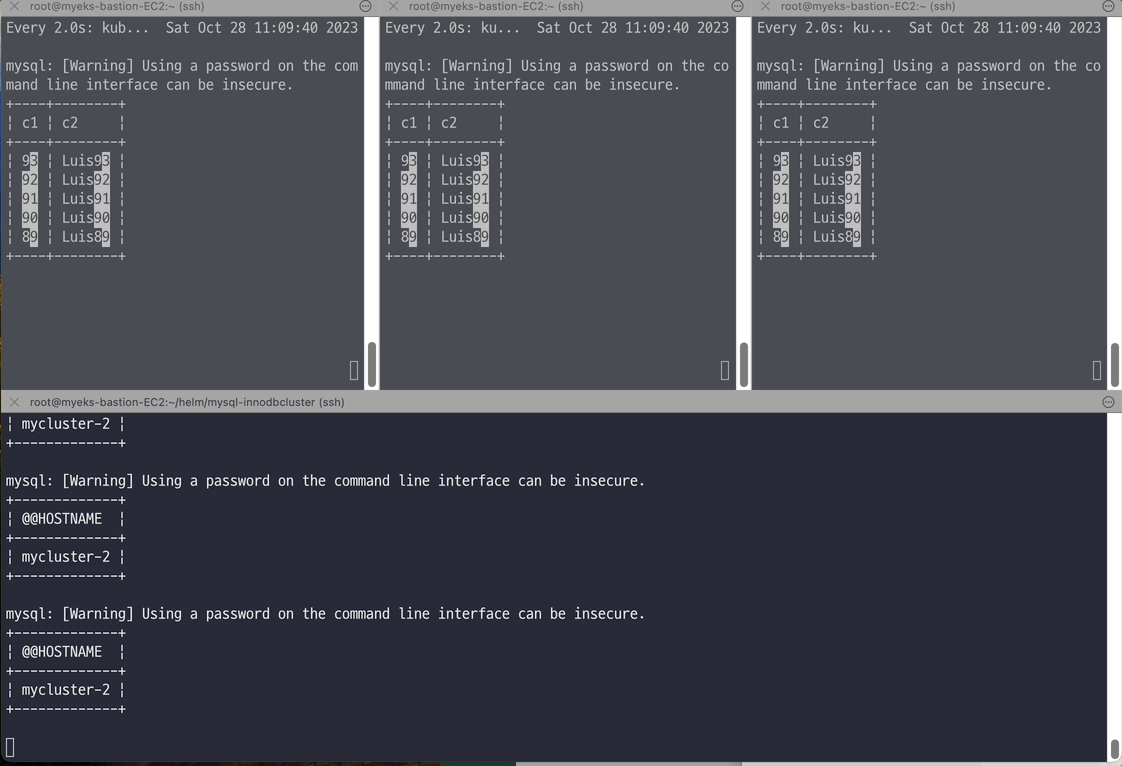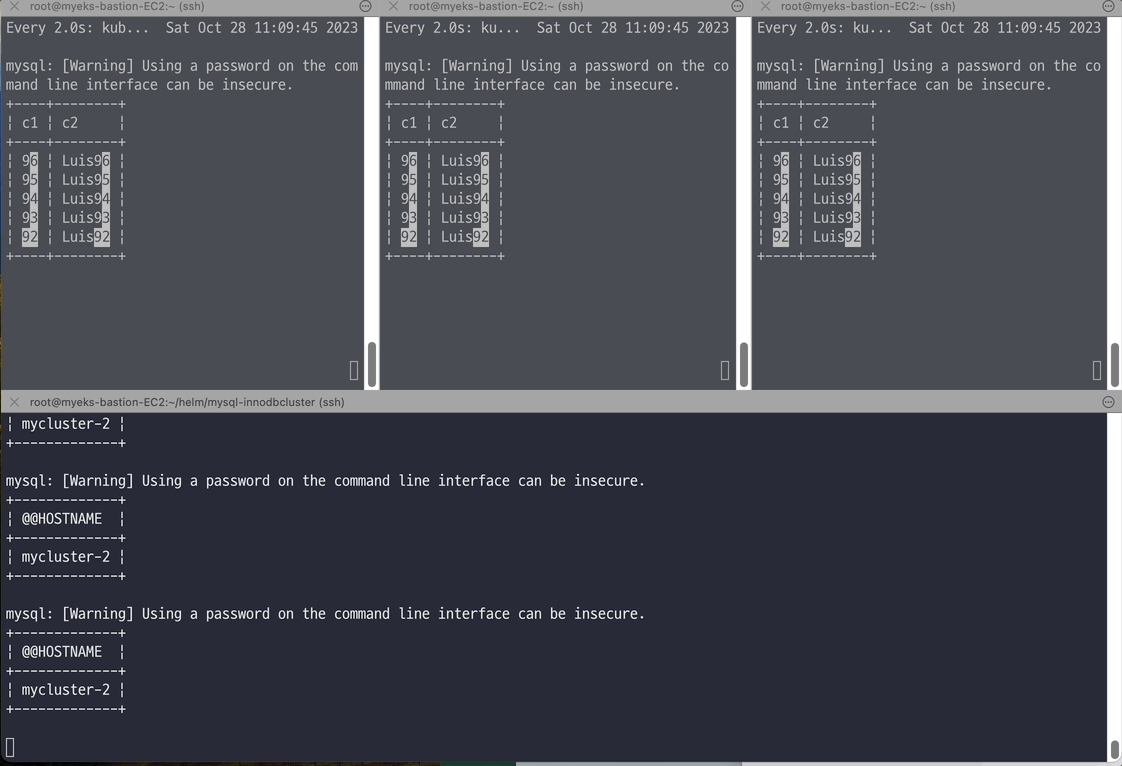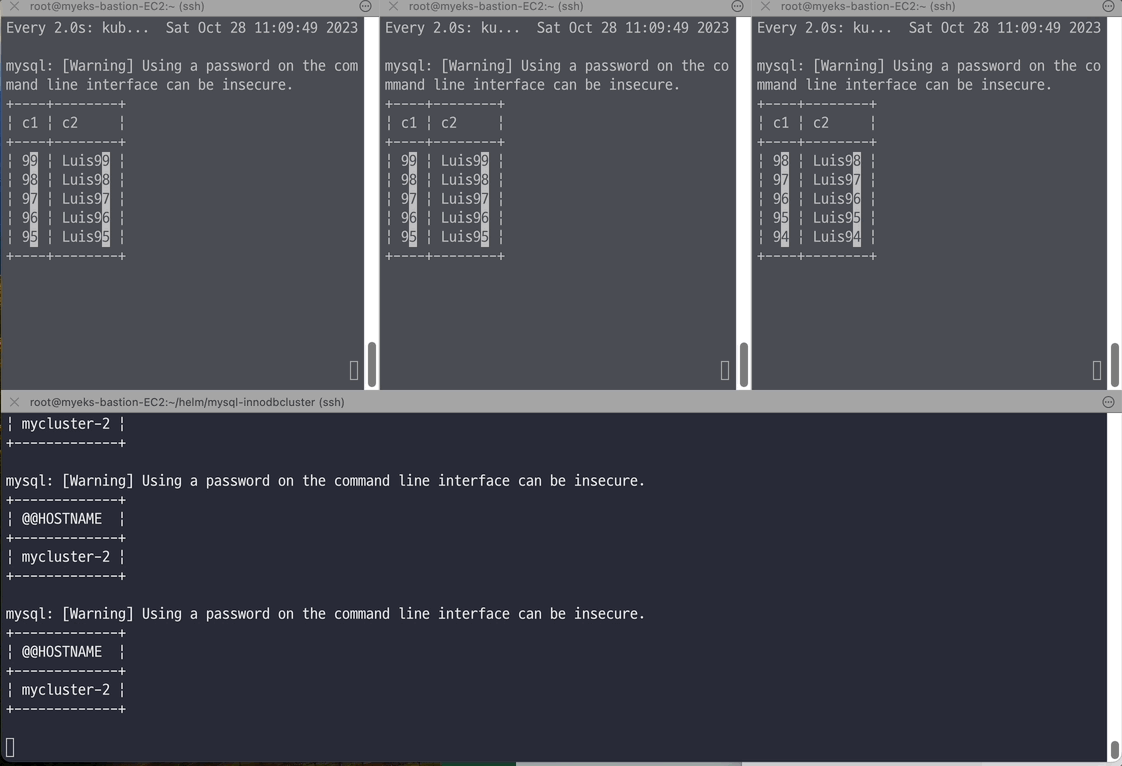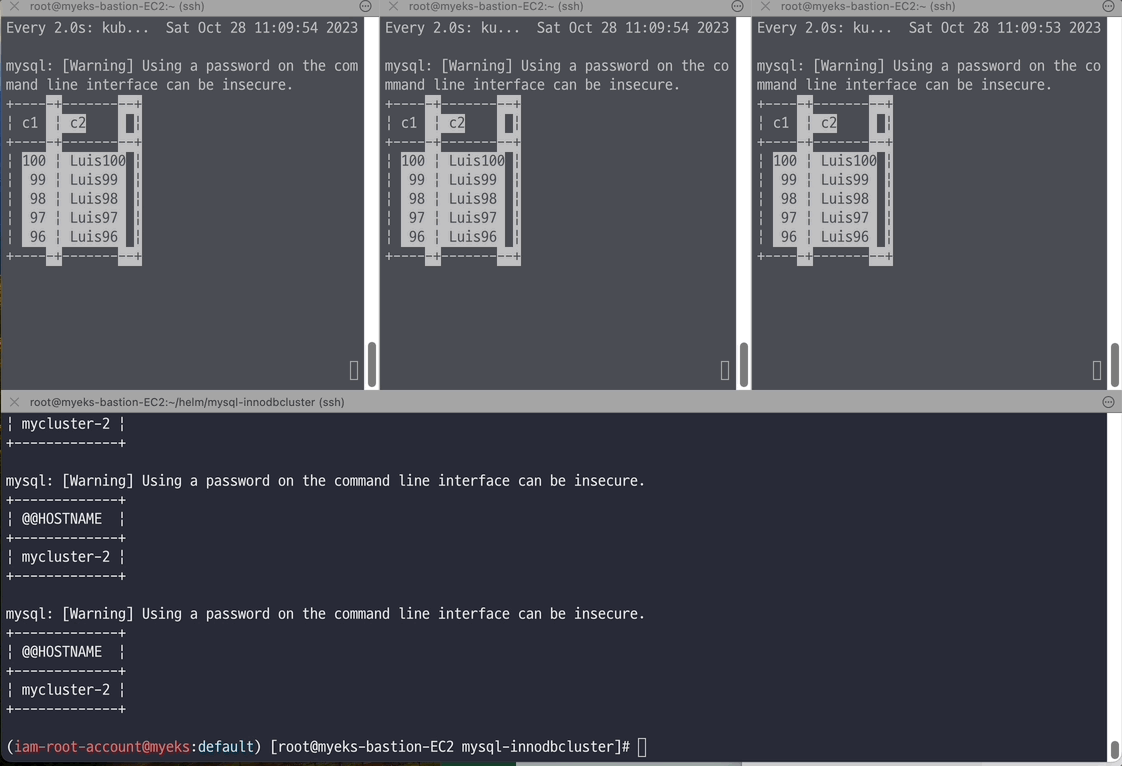
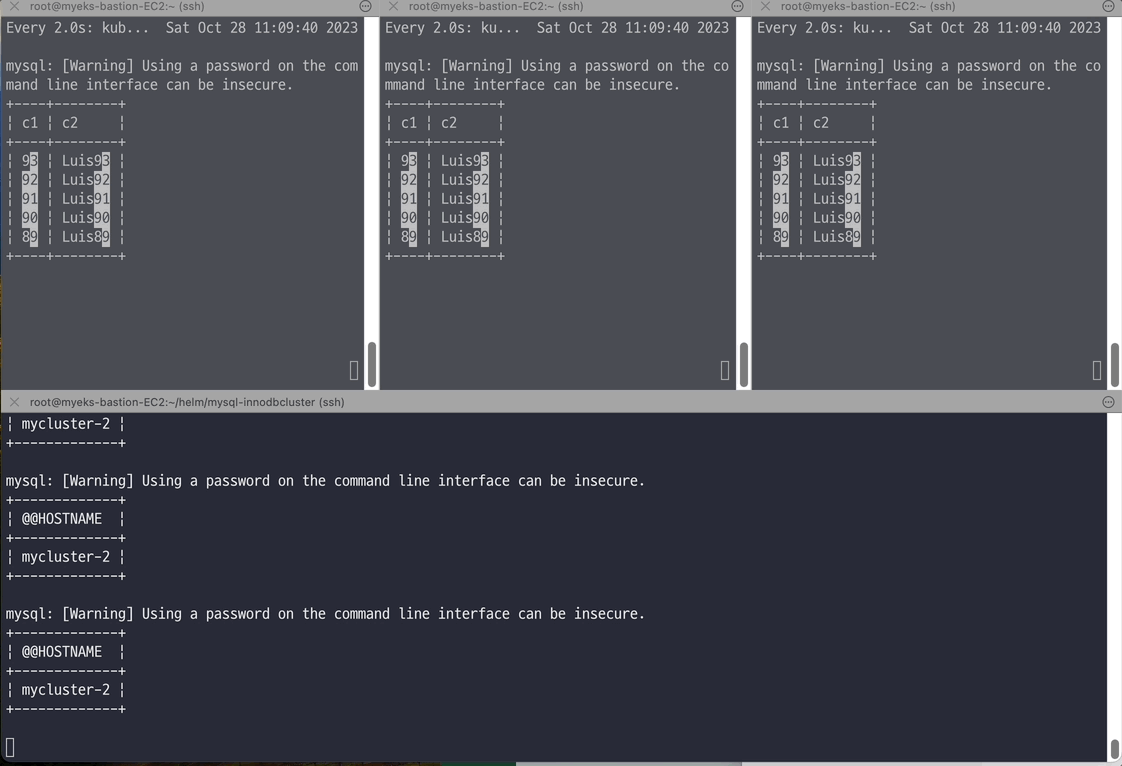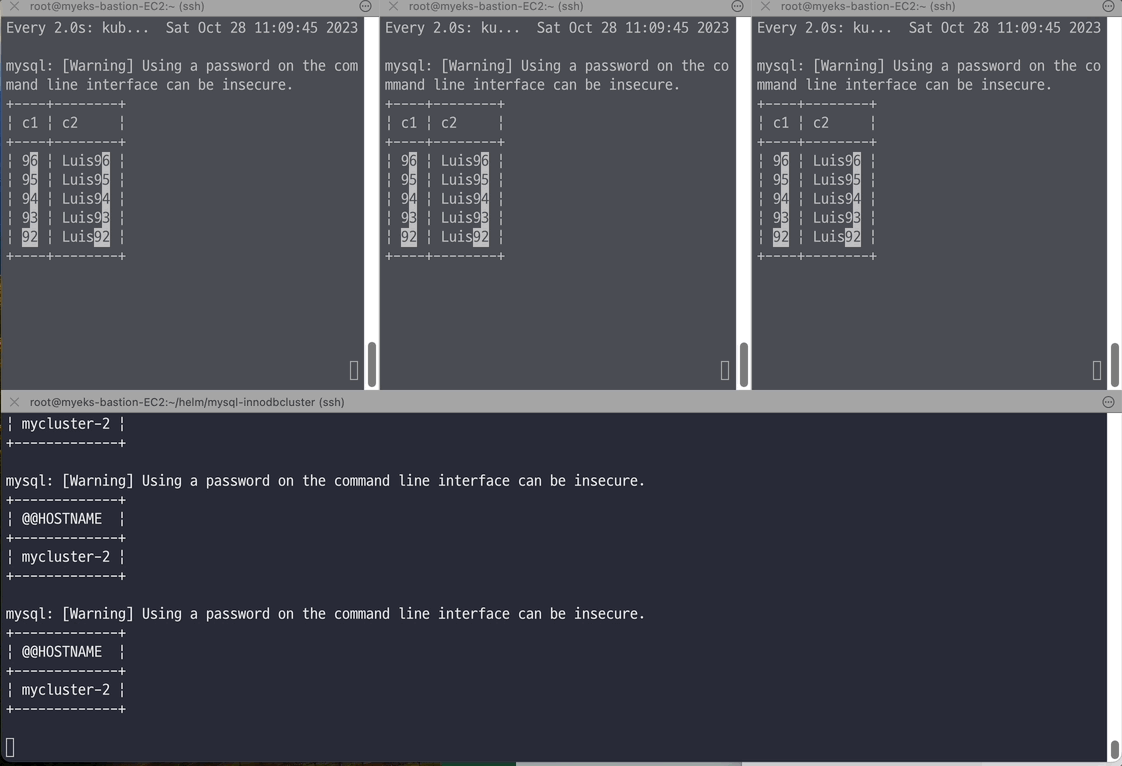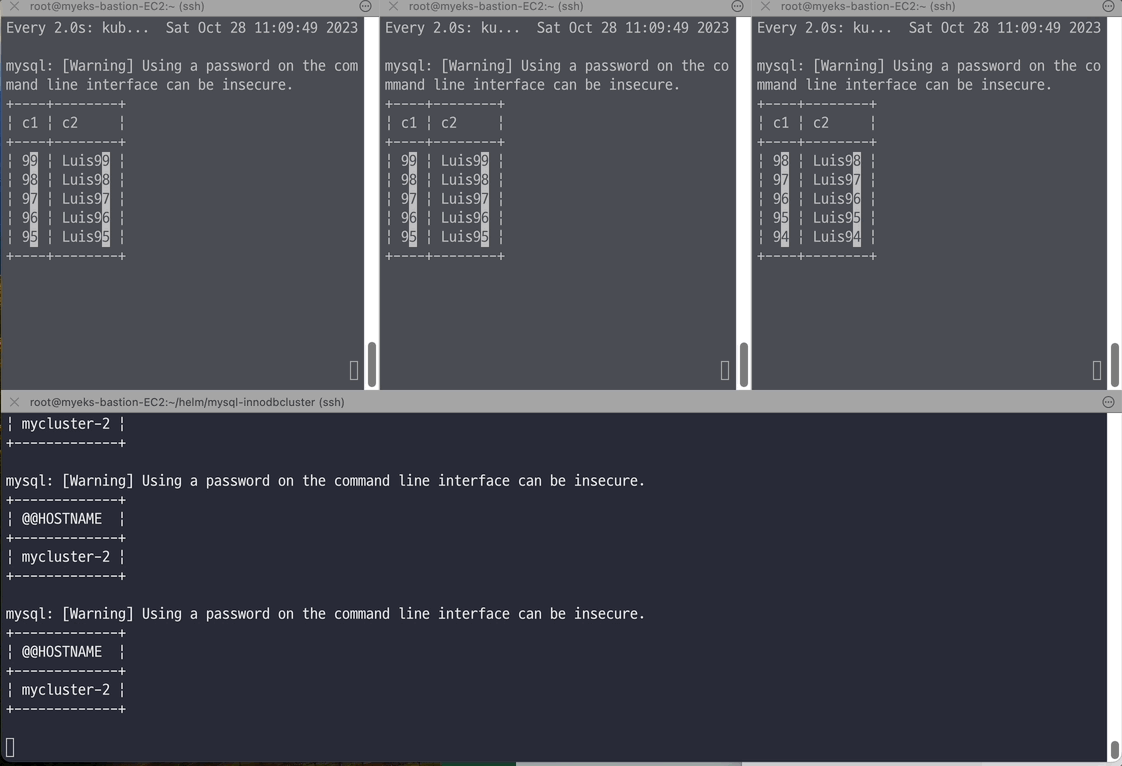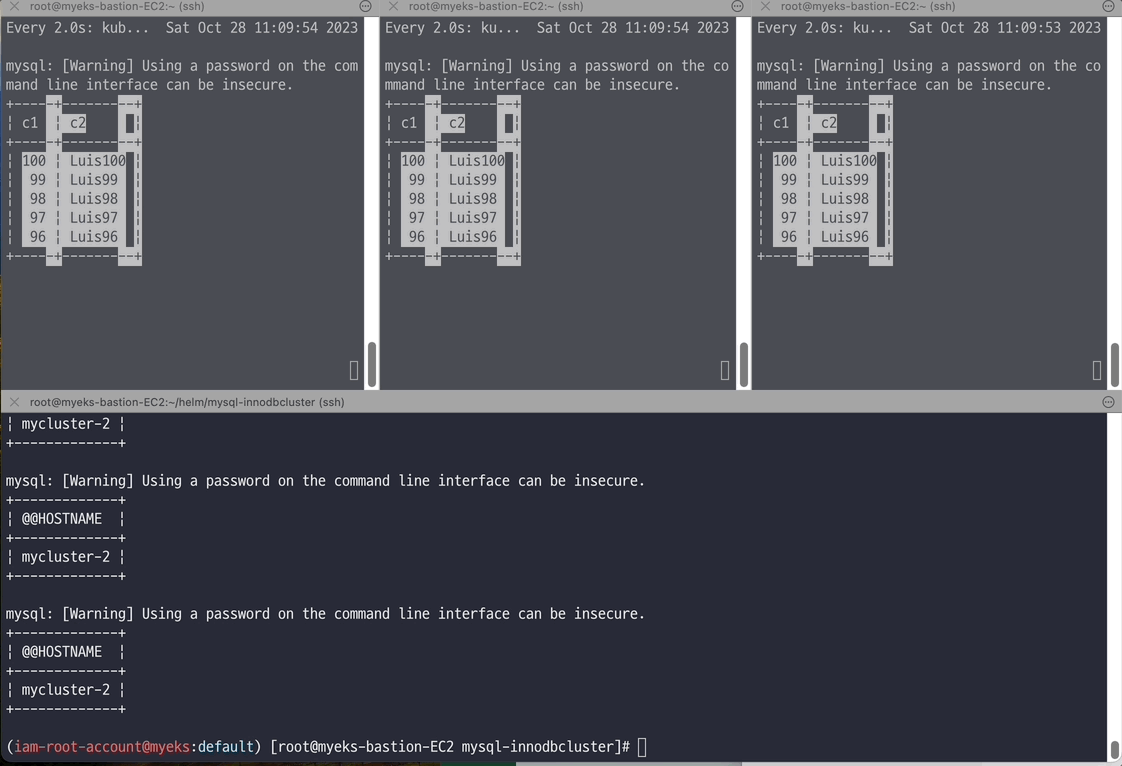
# 반복 추가 및 조회 for ((i=3; i<=100; i++)); do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME;USE test;INSERT INTO t1 VALUES ($i, 'Luis$i');";echo; done kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "USE test;SELECT * FROM t1;" # 모니터링 : 신규 터미널 3개 watch -d "kubectl exec -it myclient1 -- mysql -h mycluster-0.mycluster-instances.mysql-cluster.svc -uroot -psakila -e 'USE test;SELECT * FROM t1 ORDER BY c1 DESC LIMIT 5;'" watch -d "kubectl exec -it myclient2 -- mysql -h mycluster-1.mycluster-instances.mysql-cluster.svc -uroot -psakila -e 'USE test;SELECT * FROM t1 ORDER BY c1 DESC LIMIT 5;'" watch -d "kubectl exec -it myclient3 -- mysql -h mycluster-2.mycluster-instances.mysql-cluster.svc -uroot -psakila -e 'USE test;SELECT * FROM t1 ORDER BY c1 DESC LIMIT 5;'" # 원하는 갯수 만큼 추가, CTRL+C 로 취소 for ((i=101; i<=1000; i++)); do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT @@HOSTNAME;USE test;INSERT INTO t1 VALUES ($i, 'Luis$i');";echo; done
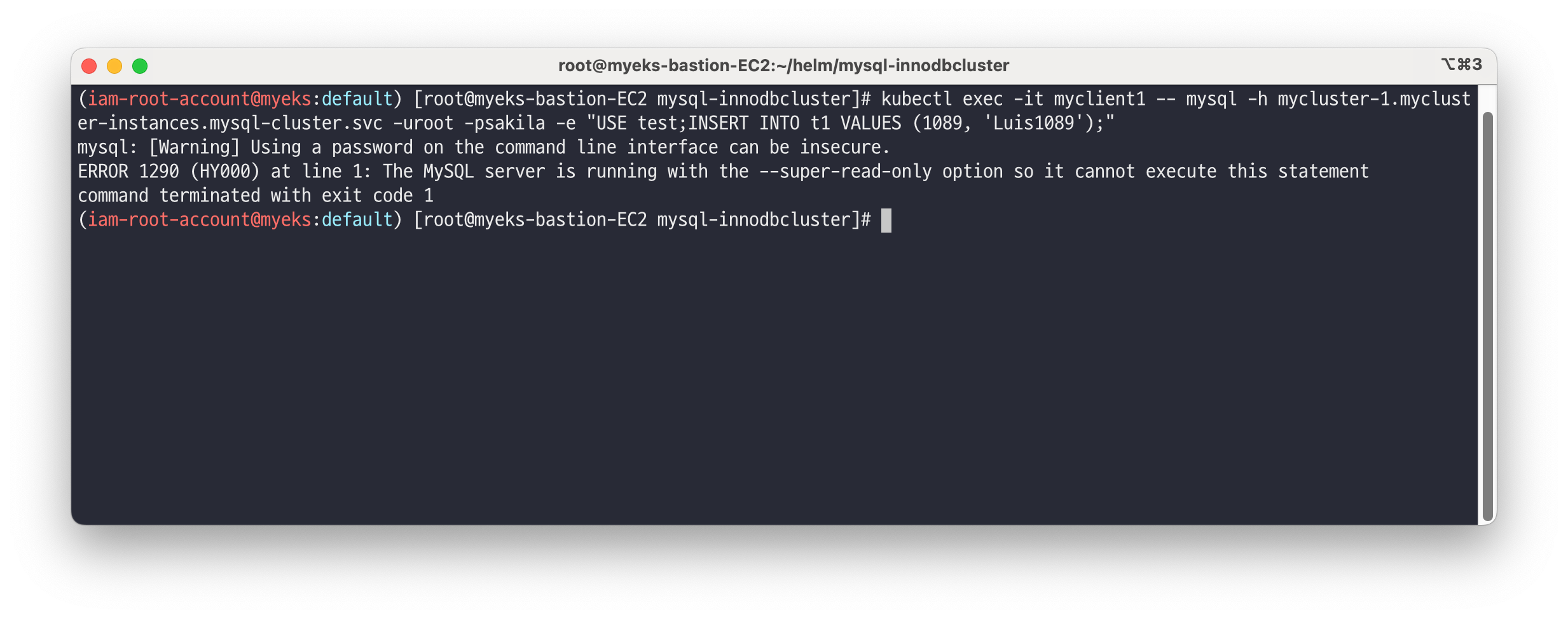
# (참고) 세컨더리 MySQL 서버 파드에 INSERT 가 되지 않는다 : --super-read-only option kubectl exec -it myclient1 -- mysql -h mycluster-0.mycluster-instances.mysql-cluster.svc -uroot -psakila -e "USE test;INSERT INTO t1 VALUES (1089, 'Luis1089');" 혹은 kubectl exec -it myclient1 -- mysql -h mycluster-1.mycluster-instances.mysql-cluster.svc -uroot -psakila -e "USE test;INSERT INTO t1 VALUES (1089, 'Luis1089');" 혹은 kubectl exec -it myclient1 -- mysql -h mycluster-2.mycluster-instances.mysql-cluster.svc -uroot -psakila -e "USE test;INSERT INTO t1 VALUES (1089, 'Luis1089');" ERROR 1290 (HY000) at line 1: The MySQL server is running with the --super-read-only option so it cannot execute this statement command terminated with exit code 1
👉 Step 04. 워드프레스 설치
워드프레스 설치
with Helm - Chart → 워드프레스 접속 및 (관리자 페이지 로그인 후) 글 작성# MySQL 에 wordpress 데이터베이스 생성 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "create database wordpress;" kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "show databases;" # 파라미터 파일 생성 cat <<EOT > wp-values.yaml wordpressUsername: admin wordpressPassword: "password" wordpressBlogName: "DOIK Study" replicaCount: 3 service: type: NodePort ingress: enabled: true ingressClassName: alb hostname: wp.$MyDomain path: /* annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]' alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN alb.ingress.kubernetes.io/success-codes: 200-399 alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb alb.ingress.kubernetes.io/group.name: study alb.ingress.kubernetes.io/ssl-redirect: '443' persistence: enabled: true storageClass: "efs-sc" accessModes: - ReadWriteMany mariadb: enabled: false externalDatabase: host: mycluster.mysql-cluster.svc port: 3306 user: root password: sakila database: wordpress EOT # wordpress 설치 : MySQL 접속 주소(mycluster.mysql-cluster.svc), MySQL 데이터베이스 이름 지정(wordpress) , 장애 테스트를 위해서 3대의 파드 배포 helm repo add bitnami https://charts.bitnami.com/bitnami helm install my-wordpress bitnami/wordpress --version 18.0.7 -f wp-values.yaml helm get values my-wordpress # 설치 확인 watch -d kubectl get pod,svc,pvc kubectl get deploy,ingress,pvc my-wordpress kubectl get pod -l app.kubernetes.io/instance=my-wordpress kubectl get sc,pv
# NFS 마운트 확인 ssh ec2-user@$N1 sudo df -hT --type nfs4 ssh ec2-user@$N2 sudo df -hT --type nfs4 ssh ec2-user@$N3 sudo df -hT --type nfs4 # Wordpress 웹 접속 주소 확인 : 블로그, 관리자 echo -e "Wordpress Web URL = https://wp.$MyDomain" echo -e "Wordpress Admin URL = https://wp.$MyDomain/admin" # 관리자 페이지 : admin, password # 모니터링 while true; do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT post_title FROM wordpress.wp_posts;"; date;sleep 1; done # (참고) EFS 확인 mount -t efs -o tls $EFS_ID:/ /mnt/myefs df -hT --type nfs4 tree /mnt/myefs/ -L 4 # (참고) 관리자 로그인 후 새 글 작성(이미지 첨부) 후 아래 확인 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT * FROM wordpress.wp_term_taxonomy;" kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT post_content FROM wordpress.wp_posts;"
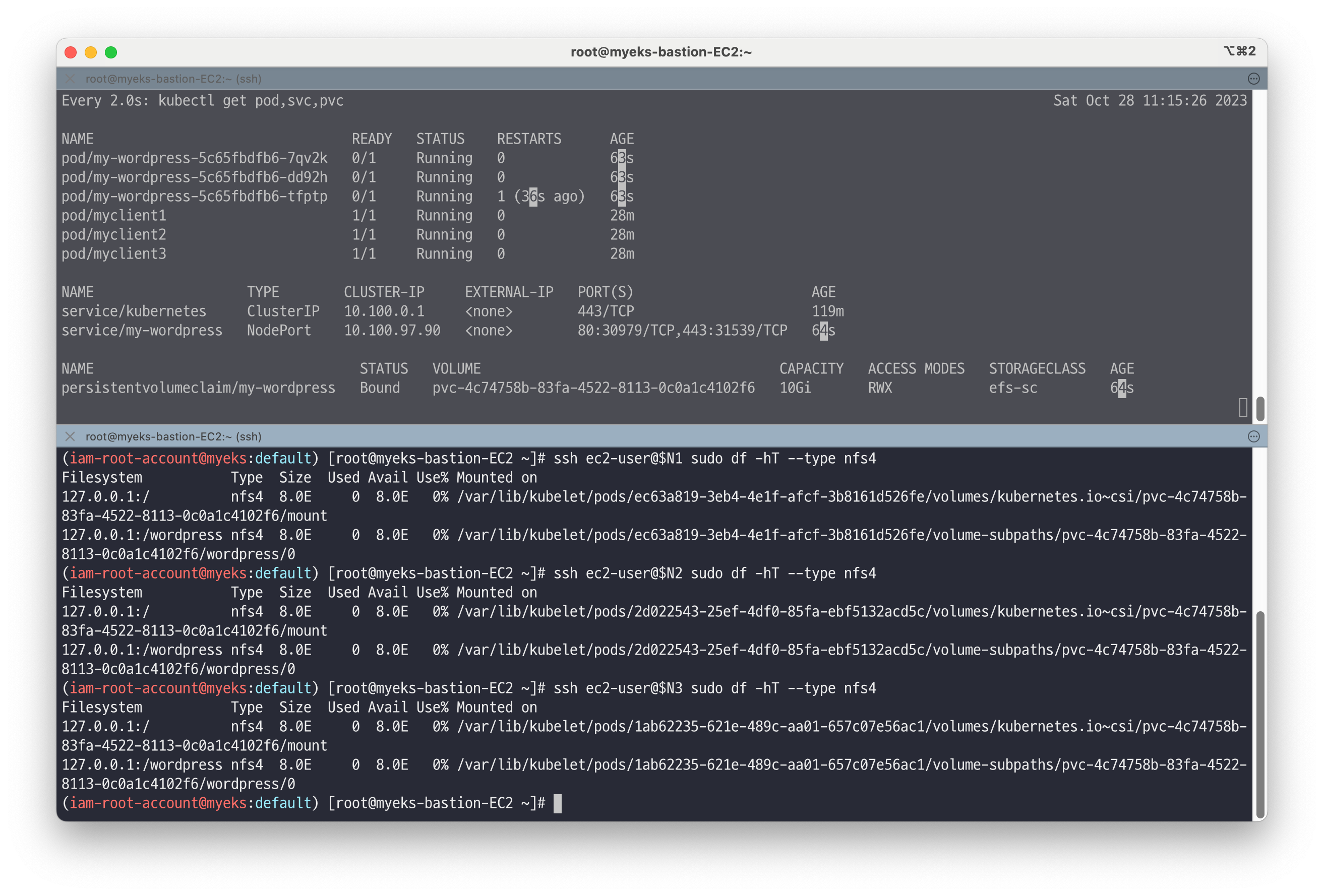
워드프레스가 정상적으로 배포된 것을 확인할 수 있습니다.
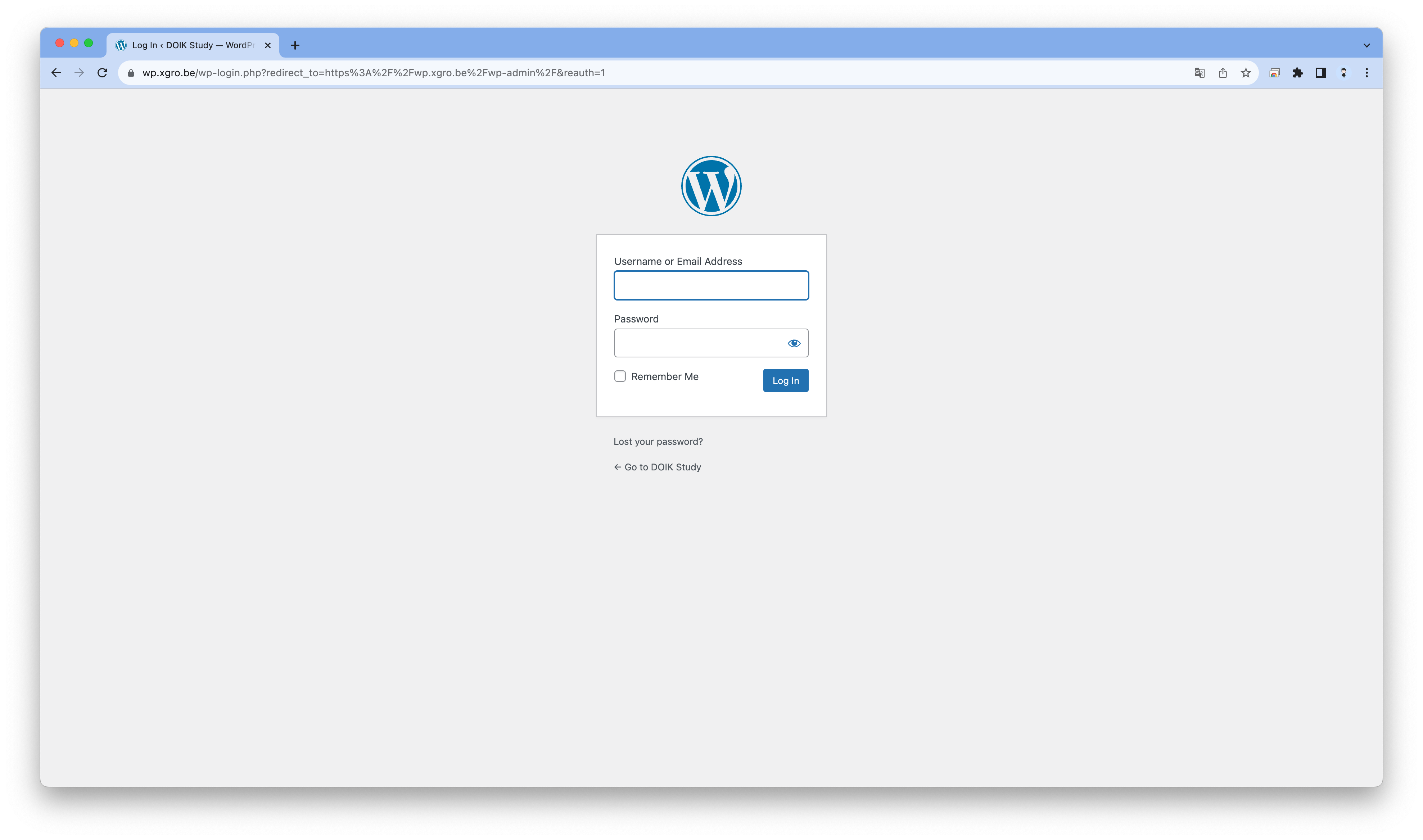
게시글을 작성하면, Mysql에 데이터가 저장되는것은 확인할 수 있습니다.
👉 Step 05. 장애 테스트
⛔ EC2 전원 OFF 테스트 시, 해당 EC2 에 컨트롤러 관련 파드가 배치되어 있는 경우 관련 동작에 클러스터 수준의 영향도가 있다🔥 [장애1] Pod 장애
MySQL 서버 파드(인스턴스) 1대 강제 삭제 및 동작 확인
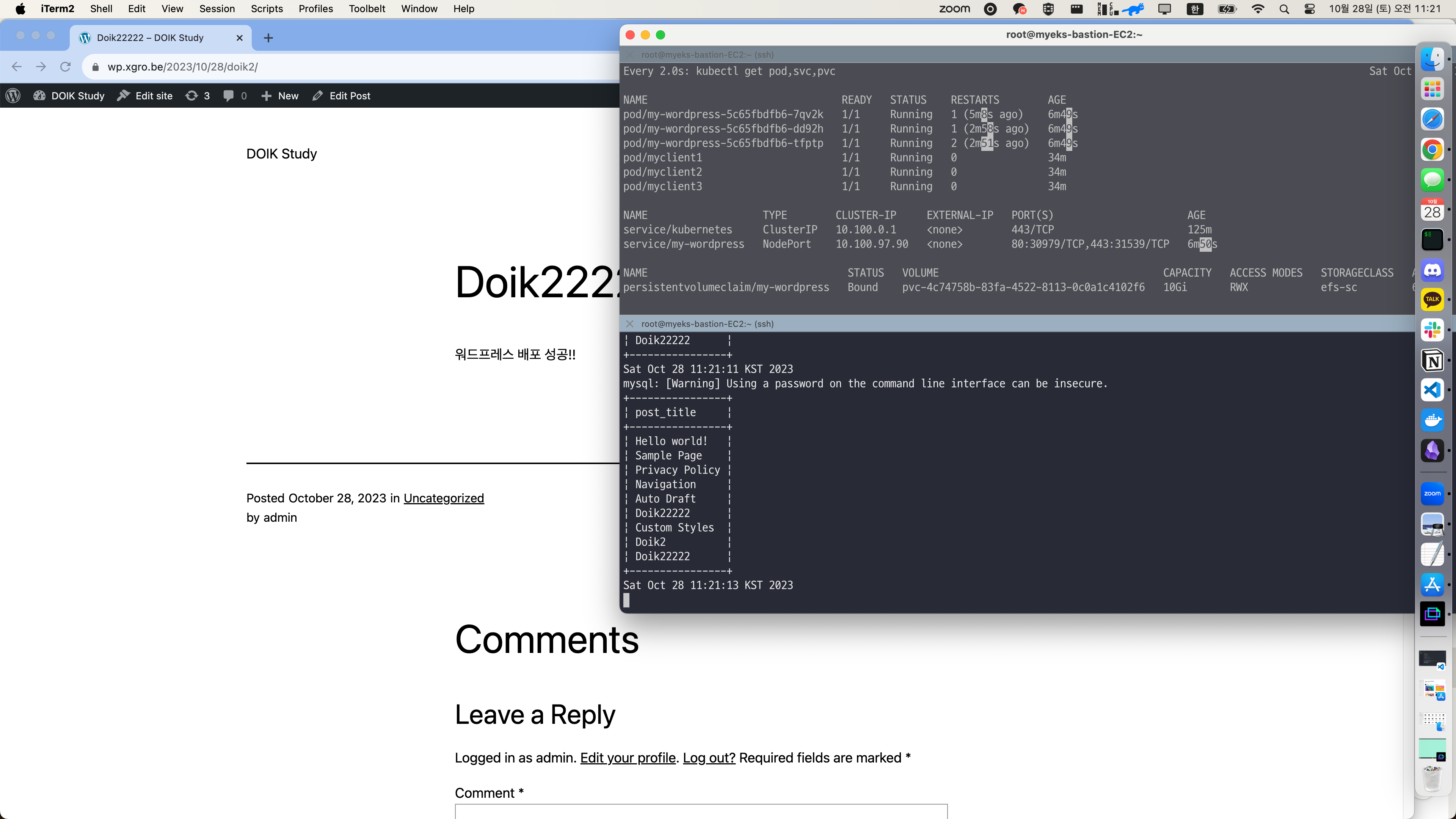
워드프레스 정상 접속 및 포스팅 작성 가능, 데이터베이스에 반복해서 INSERT 시도하며 포드의 장애 상황을 재현합니다.
# PRIMARY 파드 정보 확인 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e 'SELECT VIEW_ID FROM performance_schema.replication_group_member_stats LIMIT 1;SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;' kubectl get pod -n mysql-cluster -owide # 파드들에서 mysql 라우터 서비스로 접속 확인 : TCP 6447 접속 시 round-robin-with-fallback 정책에 의해서 2대에 라운드 로빈(부하분산) 접속됨 >> 3초 간격으로 확인! kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "SELECT @@HOSTNAME,@@SERVER_ID;" 3초 간격 kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e "SELECT @@HOSTNAME,@@SERVER_ID;" # 모니터링 : 터미널 3개 watch -d 'kubectl get pod -o wide -n mysql-cluster;echo;kubectl get pod -o wide' while true; do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e 'SELECT VIEW_ID FROM performance_schema.replication_group_member_stats LIMIT 1;SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;'; date;sleep 1; done while true; do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e 'SELECT @@HOSTNAME;'; date;sleep 2; done # 신규터미널4 : test 데이터베이스에 원하는 갯수 만큼 데이터 INSERT, CTRL+C 로 취소 for ((i=1001; i<=5000; i++)); do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT NOW();INSERT INTO test.t1 VALUES ($i, 'Luis$i');";echo; done # 신규터미널5 : 프라이머리 파드 삭제 kubectl delete pod -n mysql-cluster <현재 프라이머리 MySQL 서버파드 이름> && kubectl get pod -n mysql-cluster -w kubectl delete pod -n mysql-cluster mycluster-0 && kubectl get pod -n mysql-cluster -w 혹은 kubectl delete pod -n mysql-cluster mycluster-1 && kubectl get pod -n mysql-cluster -w 혹은 kubectl delete pod -n mysql-cluster mycluster-2 && kubectl get pod -n mysql-cluster -w
# 워드프레스에 글 작성 및 접속 확인 : 1초 미만으로 자동 절체! >> 원상복구 FailBack 확인(파드 재생성 후 그룹 멤버 Join 확인) # 만약 <세컨더리 MySQL 서버파드> 를 삭제했을 경우에는 자동 Join 되지 않음 >> 아래 수동 Join 실행하자
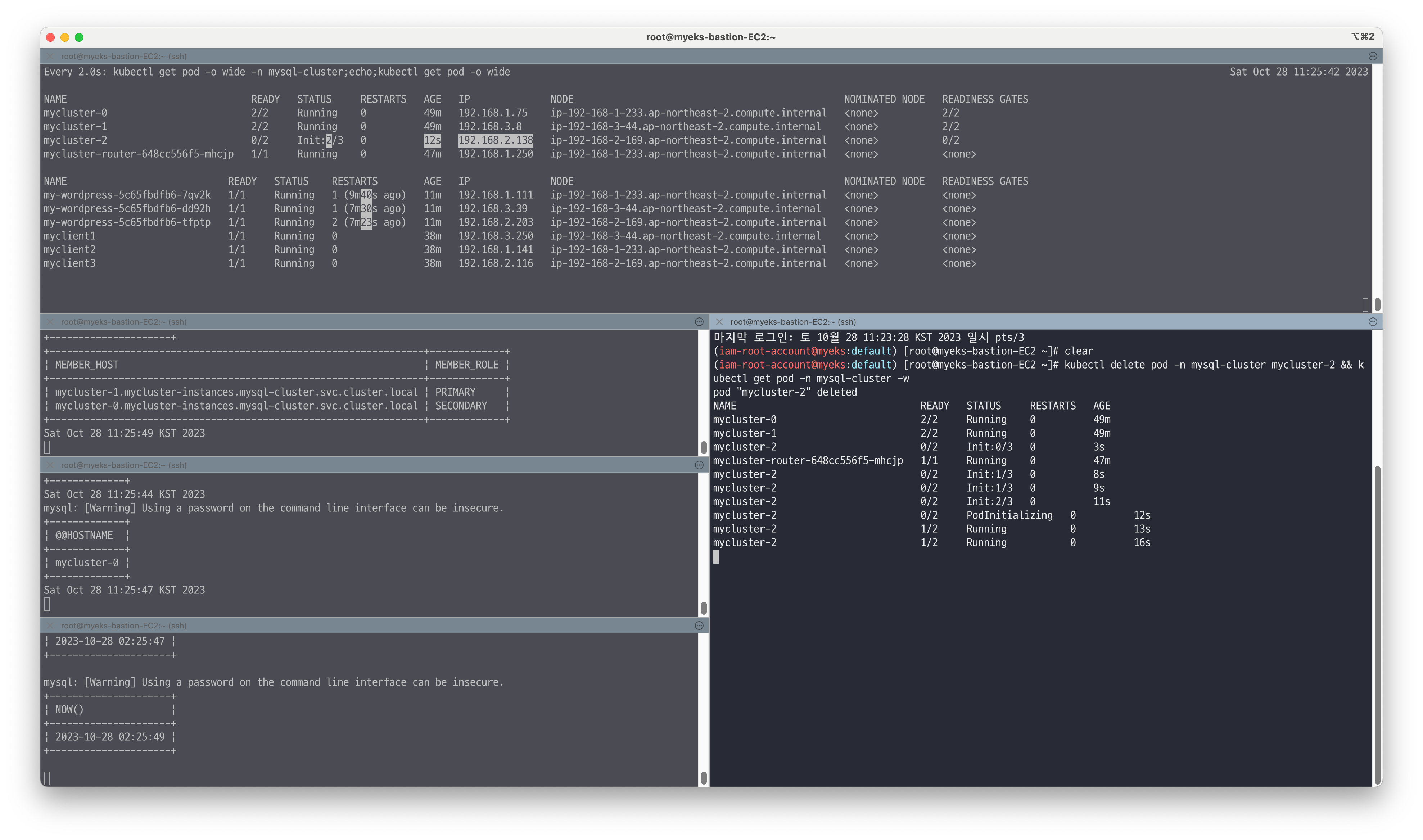
세컨더리 파드를 삭제하여, 두개의 파드로 동작하고 있지만 여전히 워드프레스는 잘 작동하는것을 확인할 수 있습니다.
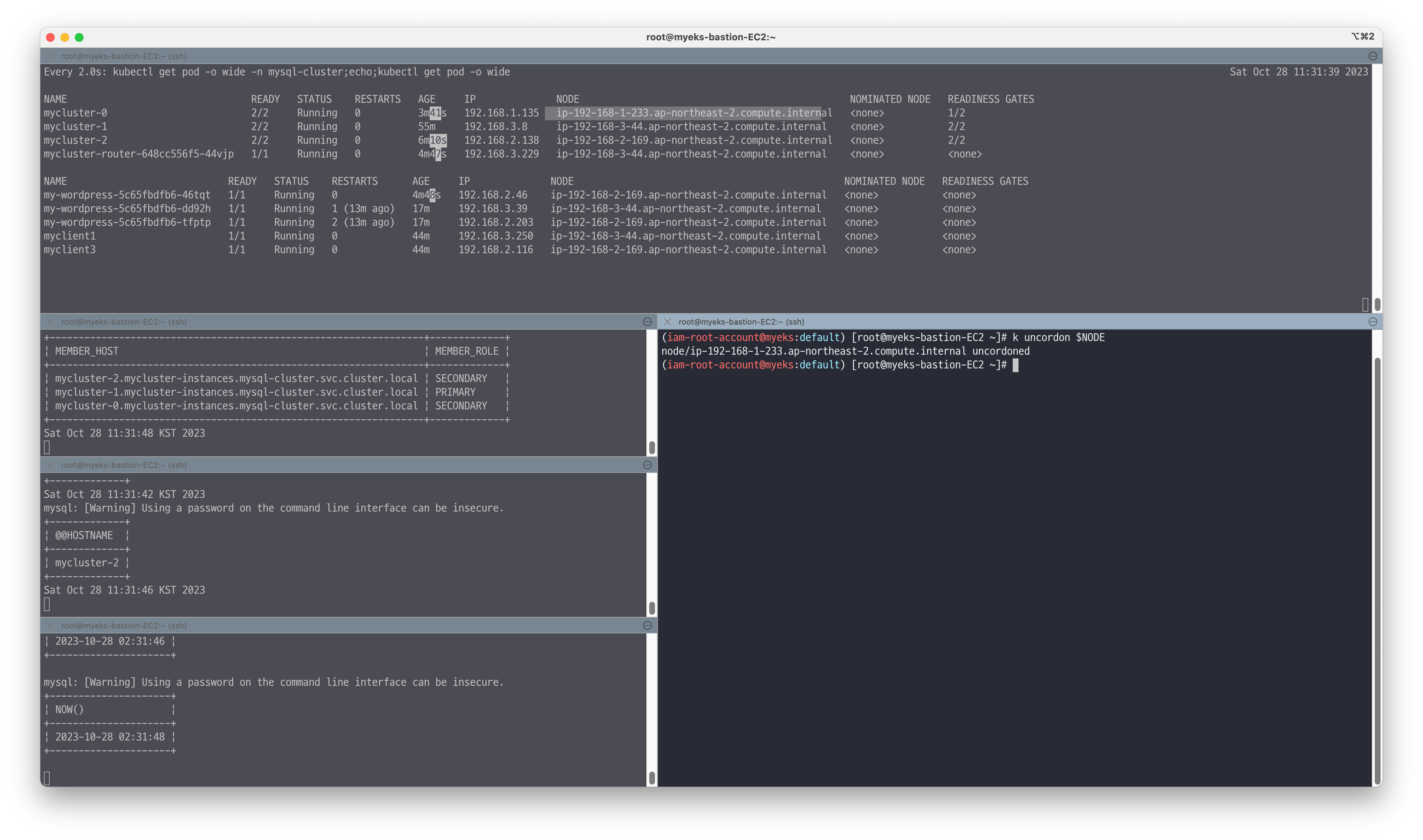
🔥 [장애2] Node 장애
MySQL 서버 파드(인스턴스) 가 배포된 노드 1대 drain 설정 및 동작 확인
워드프레스 정상 접속 및 포스팅 작성 가능, 데이터베이스에 반복해서 INSERT 시도하여 노드 장애시 발생하는 현상을 확인합니다.
# 모니터링 : 터미널 3개 >> 장애1 모니터링과 상동 watch -d 'kubectl get pod -o wide -n mysql-cluster;echo;kubectl get pod -o wide' while true; do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e 'SELECT VIEW_ID FROM performance_schema.replication_group_member_stats LIMIT 1;SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;'; date;sleep 1; done while true; do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila --port=6447 -e 'SELECT @@HOSTNAME;'; date;sleep 2; done # 신규터미널4 : test 데이터베이스에 원하는 갯수 만큼 데이터 INSERT, CTRL+C 로 취소 for ((i=5001; i<=10000; i++)); do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e "SELECT NOW();INSERT INTO test.t1 VALUES ($i, 'Luis$i');";echo; done # 신규터미널5 : EC2 노드 1대 drain(중지) 설정 : 세컨더리 노드 먼저 테스트 =>> 이후 프라이머리 노드 테스트 해보자! 결과 비교! kubectl get pdb -n mysql-cluster # 왜 오퍼레이터는 PDB 를 자동으로 설정했을까요? *# kubectl drain <<노드>> --ignore-daemonsets --delete-emptydir-data* kubectl get node NODE=*<각자 자신의 EC2 노드 이름 지정>* NODE=*ip-192-168-2-58.ap-northeast-2.compute.internal* kubectl drain $NODE --ignore-daemonsets --delete-emptydir-data --force && kubectl get pod -n mysql-cluster -w
# 워드프레스에 글 작성 및 접속 확인 & INSERT 및 확인
# 노드 상태 확인 kubectl get node NAME STATUS ROLES AGE VERSION k8s-m Ready control-plane,master 65m v1.23.6 k8s-w1 Ready <none> 64m v1.23.6 k8s-w2 Ready,SchedulingDisabled <none> 64m v1.23.6 k8s-w3 Ready <none> 64m v1.23.6 # 파드 상태 확인 kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=database -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mycluster-0 2/2 Running 2 (15m ago) 58m 172.16.158.10 k8s-w1 <none> 1/2 mycluster-1 2/2 Running 0 21m 172.16.24.6 k8s-w3 <none> 2/2 mycluster-2 0/2 Pending 0 6m15s <none> <none> <none> 0/2 # EC2 노드 1대 uncordon(정상복귀) 설정 *# kubectl uncordon <<노드>>* kubectl uncordon $NODE
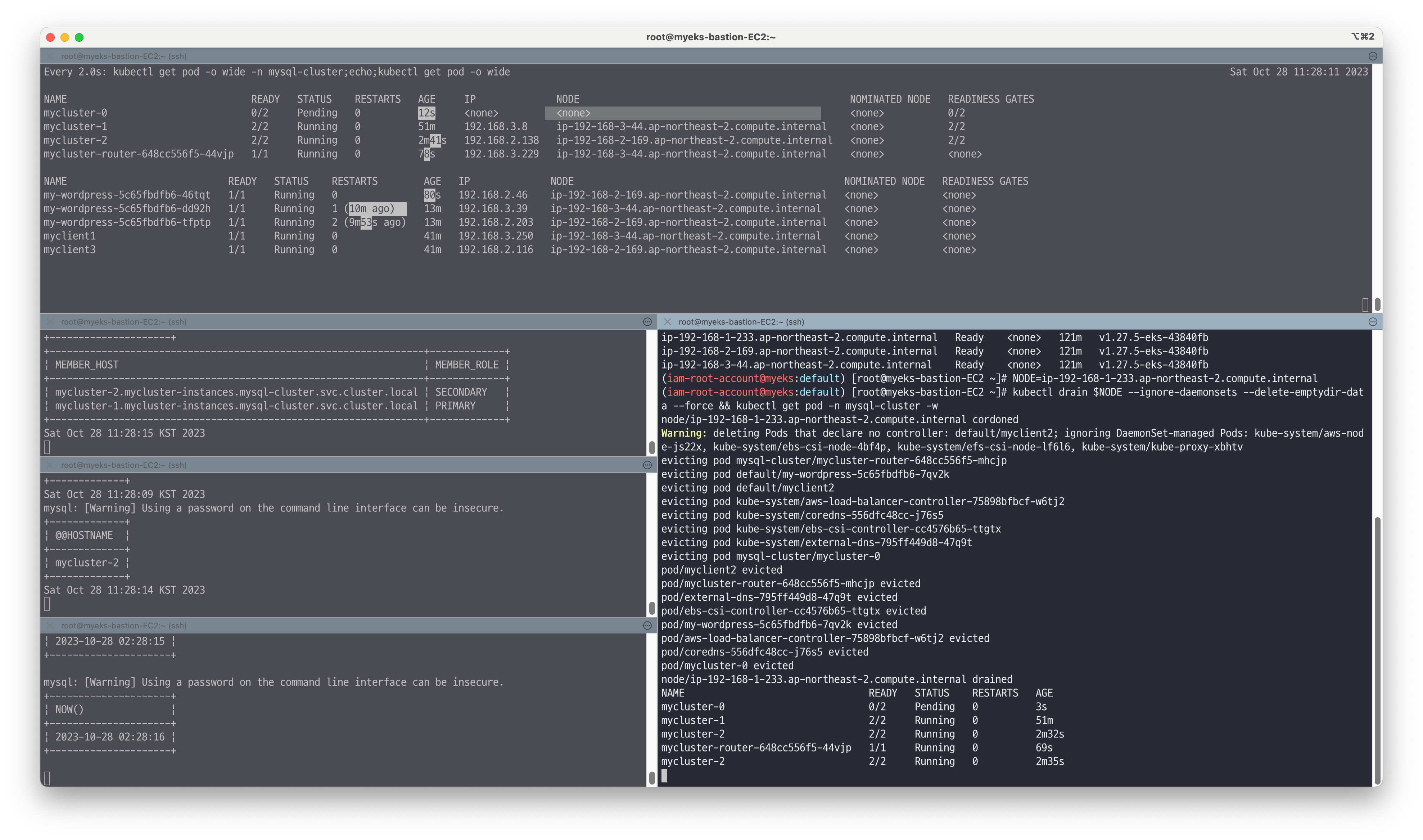
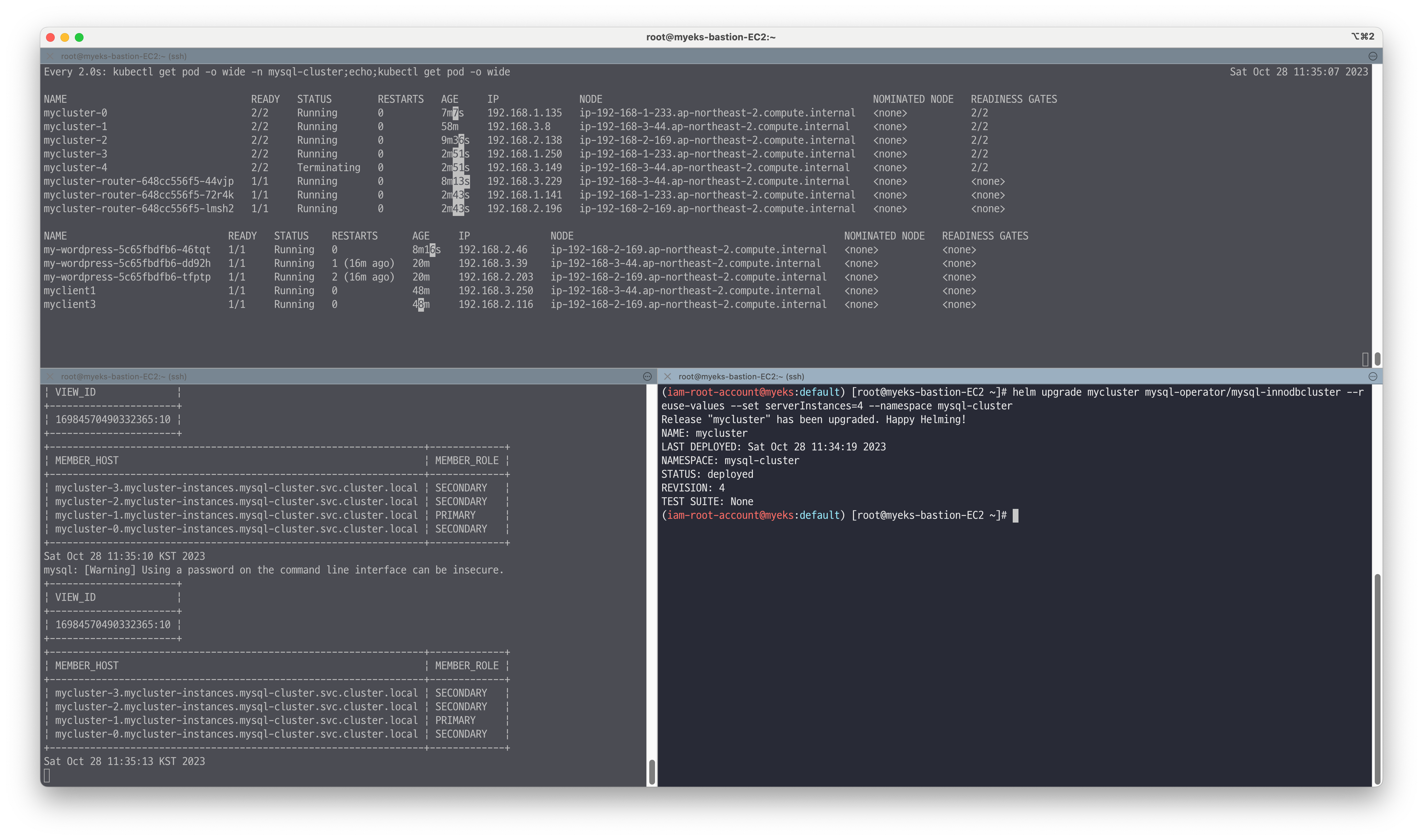
👉 Step 06. Scale 테스트
Scale 증가 / 감소
MySQL 서버 파드(인스턴스) / 라우터 파드 증가 및 감소시키는 실습을 진행합니다.# 현재 MySQL InnoDB Cluster 정보 확인 : 서버파드(인스턴스)는 3대, 라우터파드(인스턴스)는 1대 kubectl get innodbclusters -n mysql-cluster NAME STATUS ONLINE INSTANCES ROUTERS AGE mycluster ONLINE 3 3 1 17m # 모니터링 while true; do kubectl exec -it myclient1 -- mysql -h mycluster.mysql-cluster -uroot -psakila -e 'SELECT VIEW_ID FROM performance_schema.replication_group_member_stats LIMIT 1;SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;'; date;sleep 1; done # MySQL 서버 파드(인스턴스) 2대 추가 : 기본값(serverInstances: 3, routerInstances: 1) >> 복제 그룹 멤버 정상 상태(그후 쿼리 분산)까지 다소 시간이 걸릴 수 있다(데이터 복제 등) helm upgrade mycluster mysql-operator/mysql-innodbcluster --reuse-values --set serverInstances=5 --namespace mysql-cluster # MySQL 라우터 파드 3대로 증가 helm upgrade mycluster mysql-operator/mysql-innodbcluster --reuse-values --set routerInstances=3 --namespace mysql-cluster # 확인 kubectl get innodbclusters -n mysql-cluster kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=database kubectl get pod -n mysql-cluster -l app.kubernetes.io/component=router
# MySQL 서버 파드(인스턴스) 1대 삭제 : 스테이트풀셋이므로 마지막에 생성된 서버 파드(인스턴스)가 삭제됨 : PV/PVC 는 어떻게 될까요? helm upgrade mycluster mysql-operator/mysql-innodbcluster --reuse-values --set serverInstances=4 --namespace mysql-cluster #kubectl delete pvc -n mysql-clutser datadir-mycluster-4 # (옵션) PV는 어떻게 될까요?
# MySQL 라우터 파드 1대로 축소 helm upgrade mycluster mysql-operator/mysql-innodbcluster --reuse-values --set routerInstances=1 --namespace mysql-cluster # 확인 kubectl get innodbclusters -n mysql-cluster

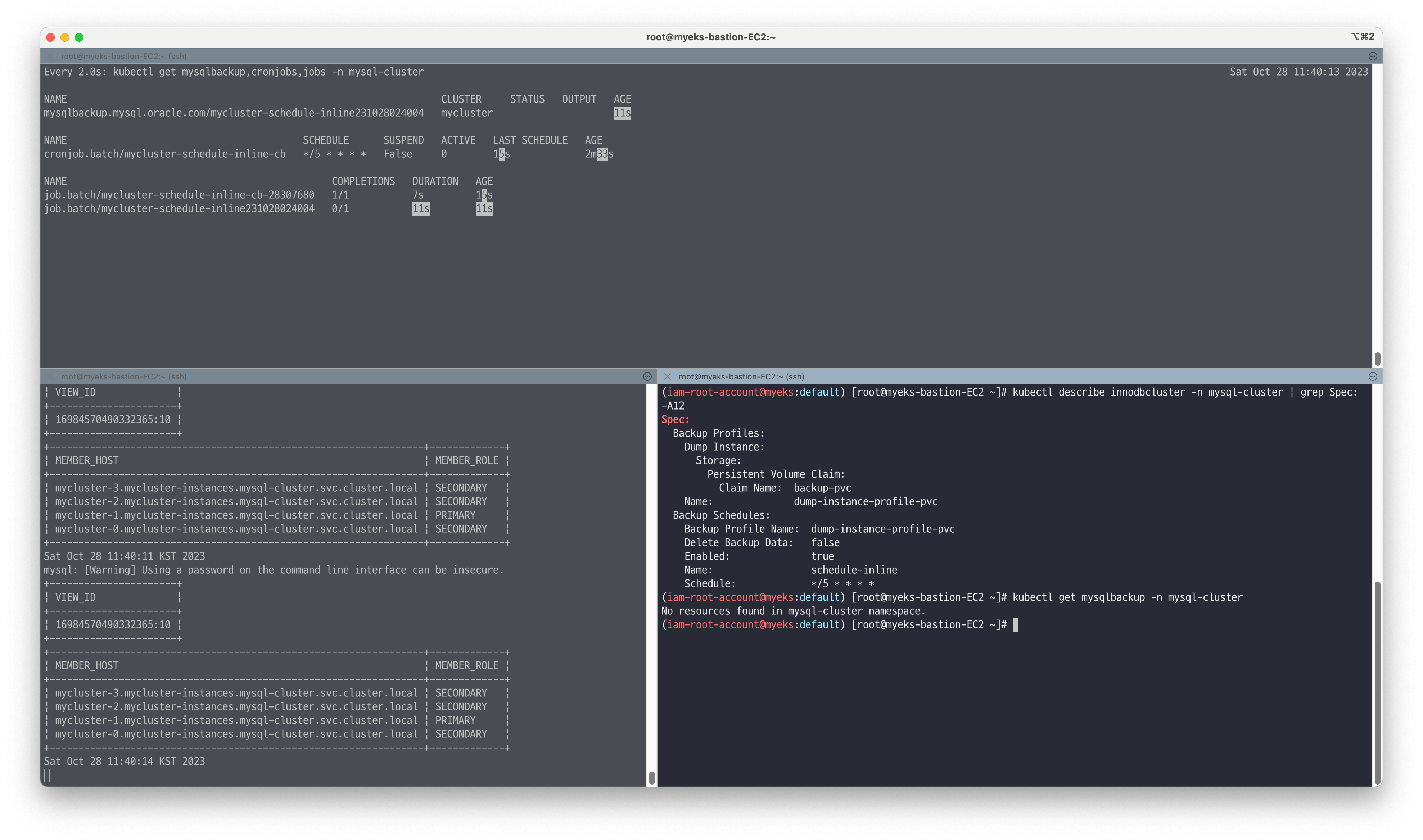
👉 Step 07. MySQL 백업 & 복구
Database를 운영 하며 가장 중요한 요소 중 하나인 백업 실습에 대해서 진행합니다.
PV/PVC를 통해 볼륨을 관리하며 backupProfiles 설정을 InnoDB Cluster의 values로 추가 하여 백업 기능을 구현할 수 있습니다.
backupProfiles 설정을 통한 (스케줄) 백업
PVC PersistentVolumeClaim 와 OCI ociObjectStorage 로 백업 가능 - 링크
# backup 관련 설정 정보 확인 : 5분 마다 백업 실행(스케줄) kubectl describe innodbcluster -n mysql-cluster | grep Spec: -A12 Spec: Backup Profiles: Dump Instance: Storage: Persistent Volume Claim: Claim Name: backup-pvc Name: dump-instance-profile-pvc Backup Schedules: Backup Profile Name: dump-instance-profile-pvc Delete Backup Data: false Enabled: true Name: schedule-inline Schedule: */5 * * * * # 모니터링 : 설정 후 최소 5분 이후에 결과 확인 watch -d kubectl get mysqlbackup,cronjobs,jobs -n mysql-cluster
# 백업 작업 정보 확인 kubectl get mysqlbackup -n mysql-cluster NAME CLUSTER STATUS OUTPUT AGE mycluster-schedule-inline220513170040 mycluster Completed mycluster-schedule-inline220513170040 14m mycluster-schedule-inline220513170502 mycluster Completed mycluster-schedule-inline220513170502 10m ... # 크론잡 cronjobs 확인 : backup 설정 시 자동으로 크론잡 설정됨 kubectl get cronjobs -n mysql-cluster NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE mycluster-schedule-inline-cb */5 * * * * False 0 119s 20m # 잡 확인 : 실제로 수행 기록 확인 kubectl get jobs -n mysql-cluster NAME COMPLETIONS DURATION AGE mycluster-schedule-inline220513170040 1/1 4m40s 17m mycluster-schedule-inline220513170502 1/1 17s 13m ... # 백업으로 사용되는 PVC 확인 : 백업 수행 전까지는 Pending 상태였다가 한번이라도 실행 시 Bound 로 변경됨 kubectl get pvc -n mysql-cluster backup-pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE backup-pvc Bound pvc-b0b4f5b5-284a-48ac-b94b-c2dd1fa2cb7c 10Gi RWO local-path 15m
# 백업으로 사용되는 PVC 가 실제 저장되는 노드 확인 kubectl describe pvc -n mysql-cluster backup-pvc | grep selected-node volume.kubernetes.io/selected-node: k8s-w3 # 백업으로 사용되는 PV 가 실제 저장되는 노드의 Path 확인 kubectl describe pv pvc-<YYY> | grep Path: Path: /opt/local-path-provisioner/pvc-b0b4f5b5-284a-48ac-b94b-c2dd1fa2cb7c_mysql-cluster_backup-pvc # 마스터노드에서 PV Path 디렉터리 내부 정보 확인 : 하위 디렉터리 1개씩이 매 5분 백업 시마다 생성 BNODE=<PV 저장노드> BNODE=k8s-w3 BPATH=<PV 의 Path> BPATH=/opt/local-path-provisioner/pvc-b0b4f5b5-284a-48ac-b94b-c2dd1fa2cb7c_mysql-cluster_backup-pvc sshpass -p "Pa55W0rd" ssh -o StrictHostKeyChecking=no root@$BNODE ls $BPATH mycluster-schedule-inline220513170040 mycluster-schedule-inline220513170502 mycluster-schedule-inline220513171002 ... sshpass -p "Pa55W0rd" ssh -o StrictHostKeyChecking=no root@$BNODE tree $BPATH ...(생략)... └── mycluster-schedule-inline220513172502 ├── @.done.json ├── @.json ├── @.post.sql ├── @.sql ├── @.users.sql ├── mysql_innodb_cluster_metadata.json ├── mysql_innodb_cluster_metadata.sql ├── mysql_innodb_cluster_metadata@async_cluster_members.json ├── mysql_innodb_cluster_metadata@async_cluster_members.sql ├── mysql_innodb_cluster_metadata@async_cluster_members@@0.tsv.zst ├── mysql_innodb_cluster_metadata@async_cluster_members@@0.tsv.zst.idx ├── mysql_innodb_cluster_metadata@async_cluster_views.json ├── mysql_innodb_cluster_metadata@async_cluster_views.sql ├── mysql_innodb_cluster_metadata@async_cluster_views@@0.tsv.zst ├── mysql_innodb_cluster_metadata@async_cluster_views@@0.tsv.zst.idx ├── mysql_innodb_cluster_metadata@clusters.json ├── mysql_innodb_cluster_metadata@clusters.sql ├── mysql_innodb_cluster_metadata@clusters@@0.tsv.zst ├── mysql_innodb_cluster_metadata@clusters@@0.tsv.zst.idx ...(생략)...

{kind=link}
{kind=link}
{kind=link}
📌 Conclusion
쿠버네티스 환경에서 Mysql를 배포하기 위해 Operator, innoDBCluster helm 차트를 사용하여 구축하는 실습을 진행하였습니다. 실제 서비스가 운영되는 상황에서 RDS를 주로 사용했었던 경험을 토대로 하나씩 구축하며 세부적인 기능을 매칭하는것이 정말 도움이 되었습니다.
특히 Operator 구조를 통해 어플리케이션을 추상화하여 관리할 수 있는 컨셉을 새로이 알게 되었습니다.
추가적으로 다음 포스팅에는 Vitess의 구조와 사용방법에 대해서 정리해보겠습니다.
📌 Reference

안녕하세요 글 잘읽었습니다 백업하는것은 잘봤는데 반대로 복구하는 과정은 없는것으로 보입니다. 혹시 복구하는것도 볼수있을까요?