
📌 Notice
본 블로깅은 아래의
24단계 실습으로 정복하는 쿠버네티스책을 기준하여 정리하였습니다.
출처 - https://wikibook.co.kr/kubepractice
CloudNetaStudy그룹에서 스터디한 내용입니다.
책의 저자이신이정훈-Jerry님과 함께 스터디 하고 있습니다. 🙏
Gasida님과Jerry님께 다시한번 🙇 감사드립니다.
📌 Summary
- 헬름 차트를 이용하여 인프라 관리에 필요한 리소스를 설치할 수 있습니다.
- Prometheus와 Grafana를 조합하여 시스템의 지표를 수집하고, 디스플레이 할 수 있습니다.
📌 Architecture
❗ 이번주 실습에서 성능을 요구하는 파드를 사용합니다.
1. kops 인스턴스 t3.small & 노드 c5.2xlarge (vCPU 8, Memory 16GiB) 배포
2. EC2 instance profiles 설정 및 AWS LoadBalancer 배포 & ExternalDNS 설치 및 배포
📌 Study Notes
👉 Step 01. Metrics-server
kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소입니다. - 링크 Docs CMD
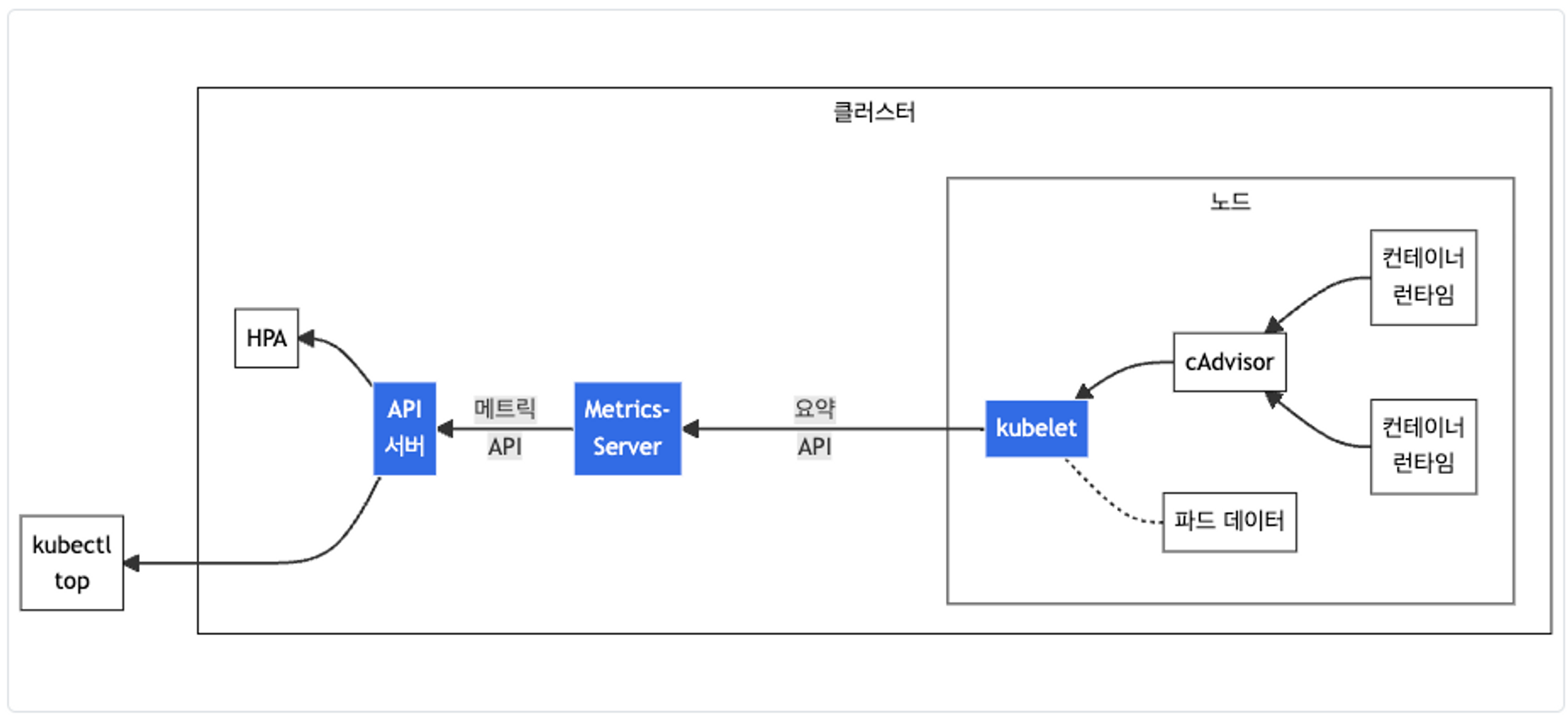 출처 - https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
출처 - https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
cAdvisor를 통하여 노드의 메트릭를 확인합니다.
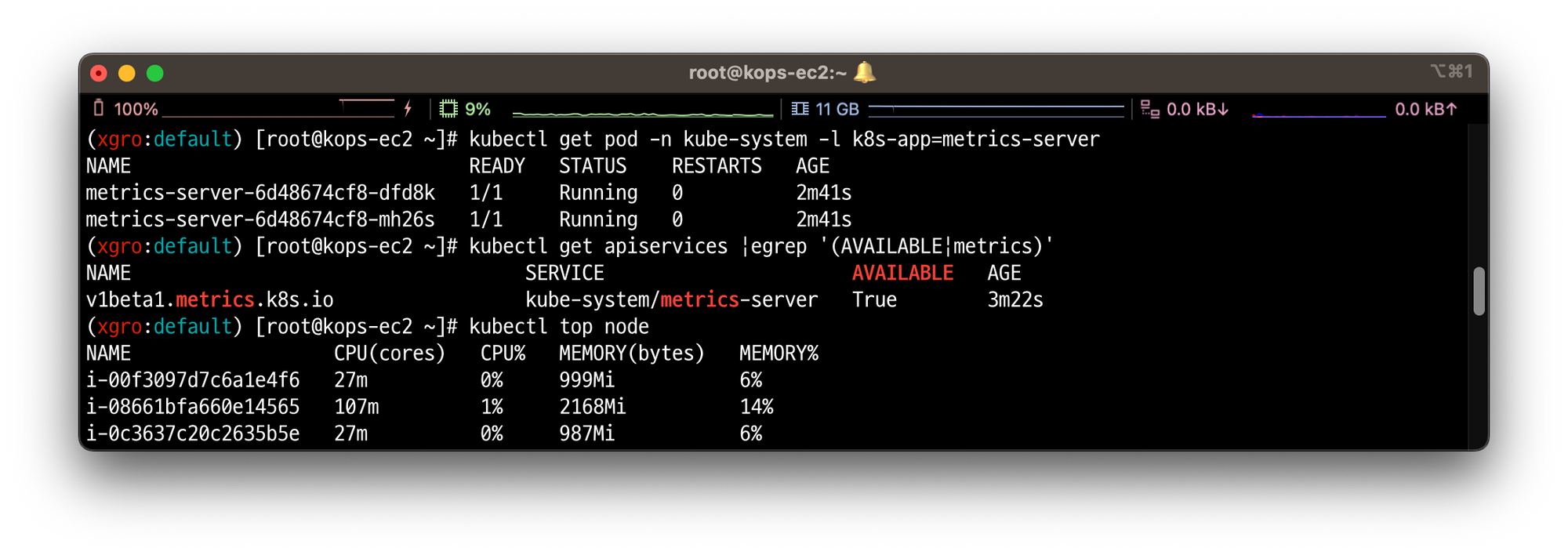
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴 kubectl get pod -n kube-system -l k8s-app=metrics-server kubectl get apiservices |egrep '(AVAILABLE|metrics)' # 노드 메트릭 확인 kubectl top node
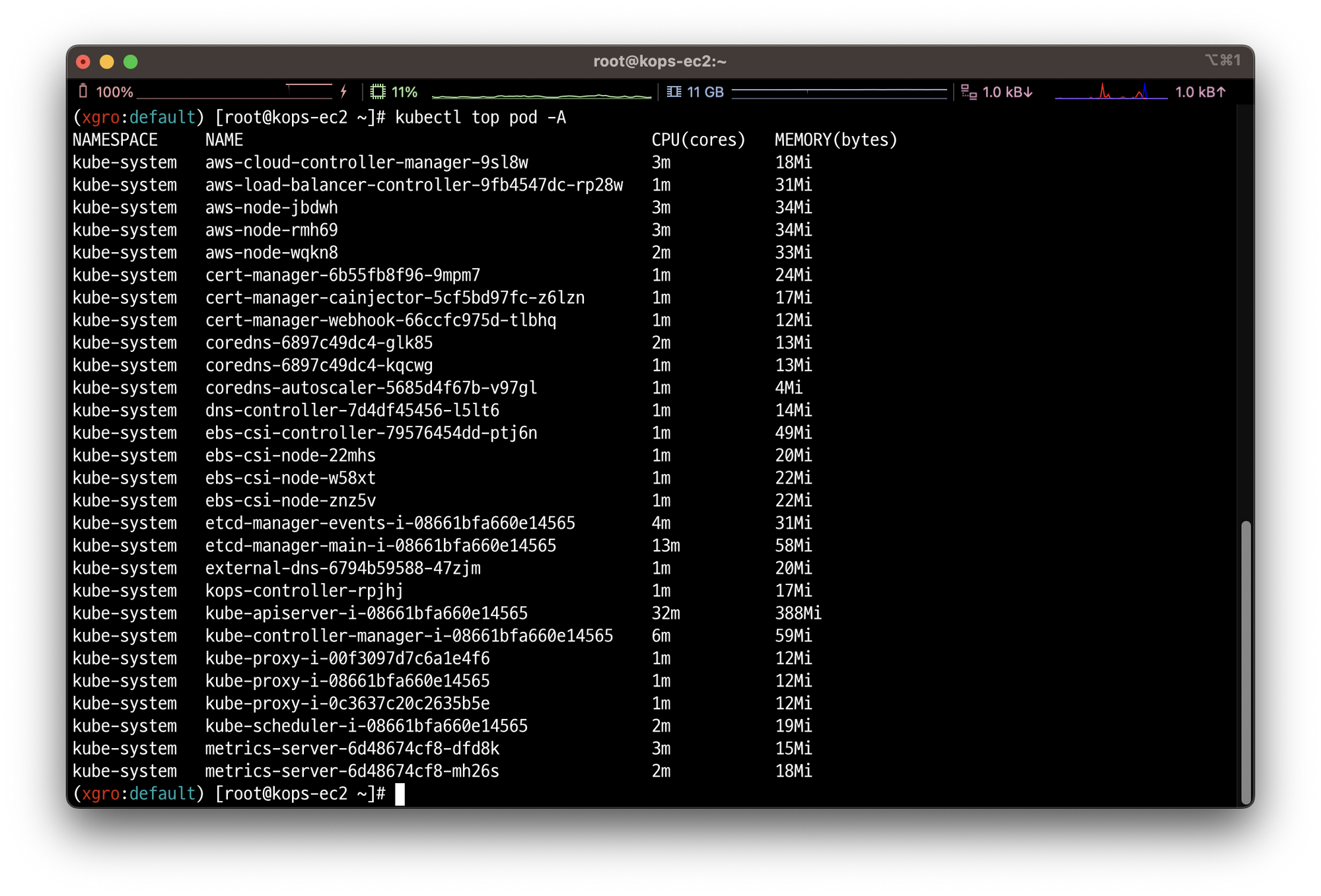
생성된 파드의 메트릭을 확인합니다.
# 파드 메트릭 확인 kubectl top pod -A kubectl top pod -n kube-system --sort-by='cpu' kubectl top pod -n kube-system --sort-by='memory'
👉 Step 02. Prometheus 설치
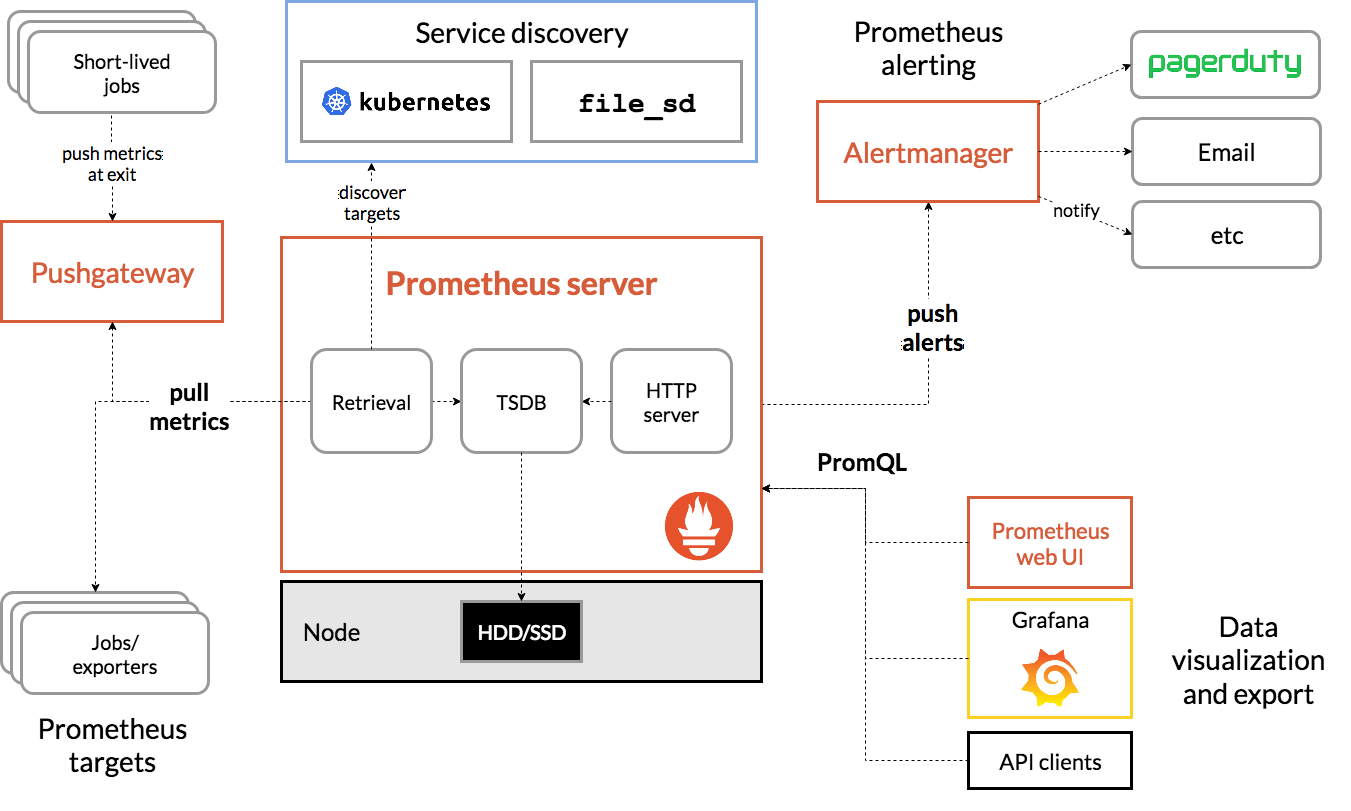
Prometheus란?
프로메테우스는
Soundcloud에서 개발한 오픈소스이며, 대상 시스템의 지표를 수집하여 저장하고 검색할 수 있는 프로그램 입니다.
프로메테우스는 다음과 같은 기능을 제공합니다.
-
a multi-dimensional data model with time series data(=TSDB, 시계열 데이터베이스) identified by metric name and key/value pairs
-
PromQL, a flexible query language to leverage this dimensionality
-
no reliance on distributed storage; single server nodes are autonomous
-
time series collection happens via a pull model over HTTP ⇒ Push 와 Pull 수집 방식 장단점 - 링크
-
pushing time series is supported via an intermediary gateway
-
targets are discovered via service discovery or static configuration
-
multiple modes of graphing and dashboarding support
✅ 프로메테우스 스택 설치
모니터링에 필요한 여러 요소를 단일 차트(스택) 형식으로 제공합니다.
시각화에 필요한 그라파나, 이벤트 메시지 정책(경고 임계 값, 경고 수준) 등 - helm
- kube-prometheus-stack collects Kubernetes manifests,
Grafana dashboards, andPrometheus rulescombined with documentation and scripts to provide easy to operate end-to-end Kubernetes cluster monitoring with Prometheus using thePrometheus Operator.
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 -f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
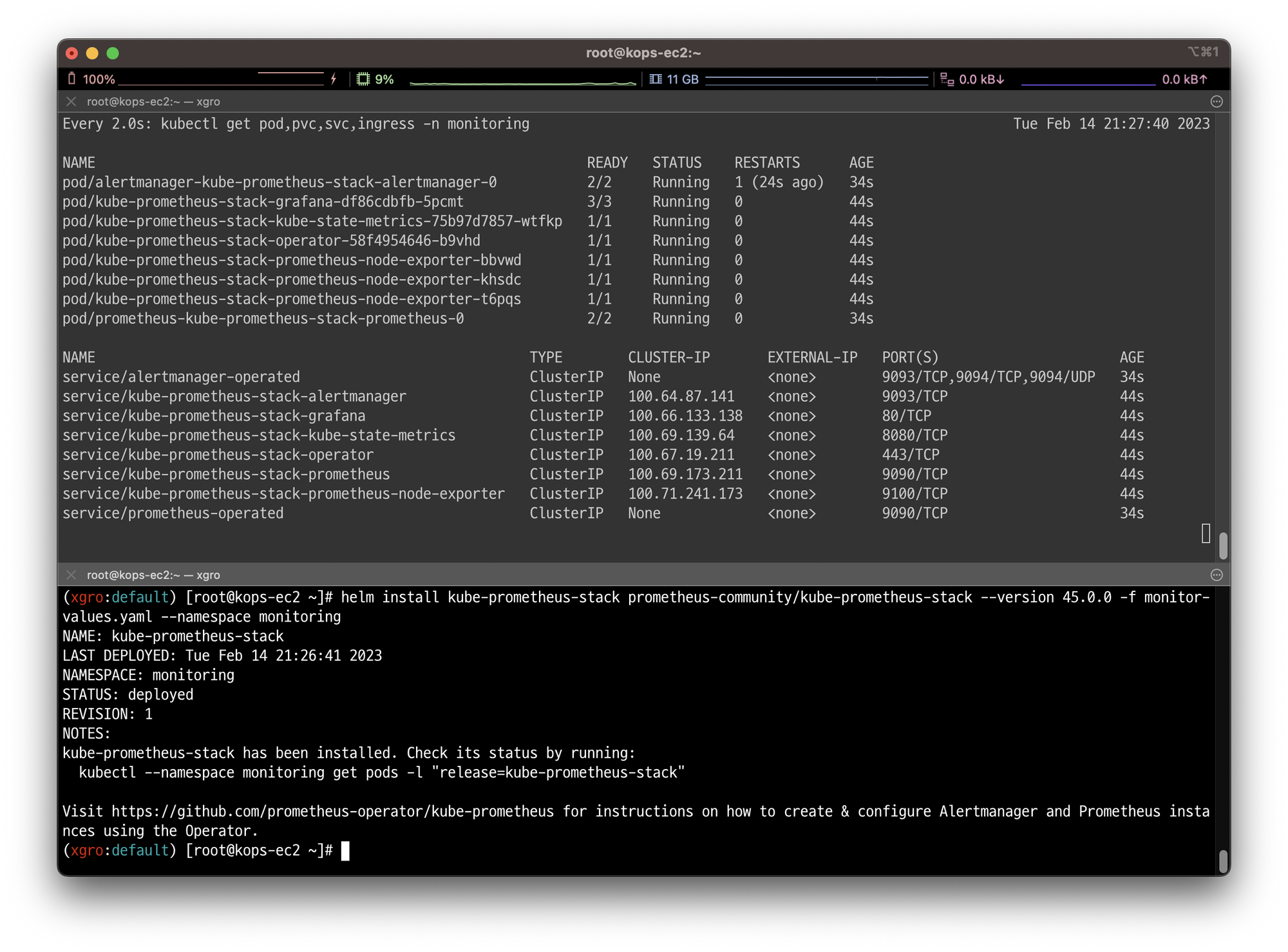
kubectl get pod,pvc,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl krew install df-pv && kubectl df-pvHelm을 이용하여 프로메테우스 스택을 설치하였습니다.
✅ 프로메테우스 기본 사용
-
모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출합니다.
-
이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장합니다.
프로메테우스 웹페이지에서 다양한 정보를 수집 할 수 있습니다.
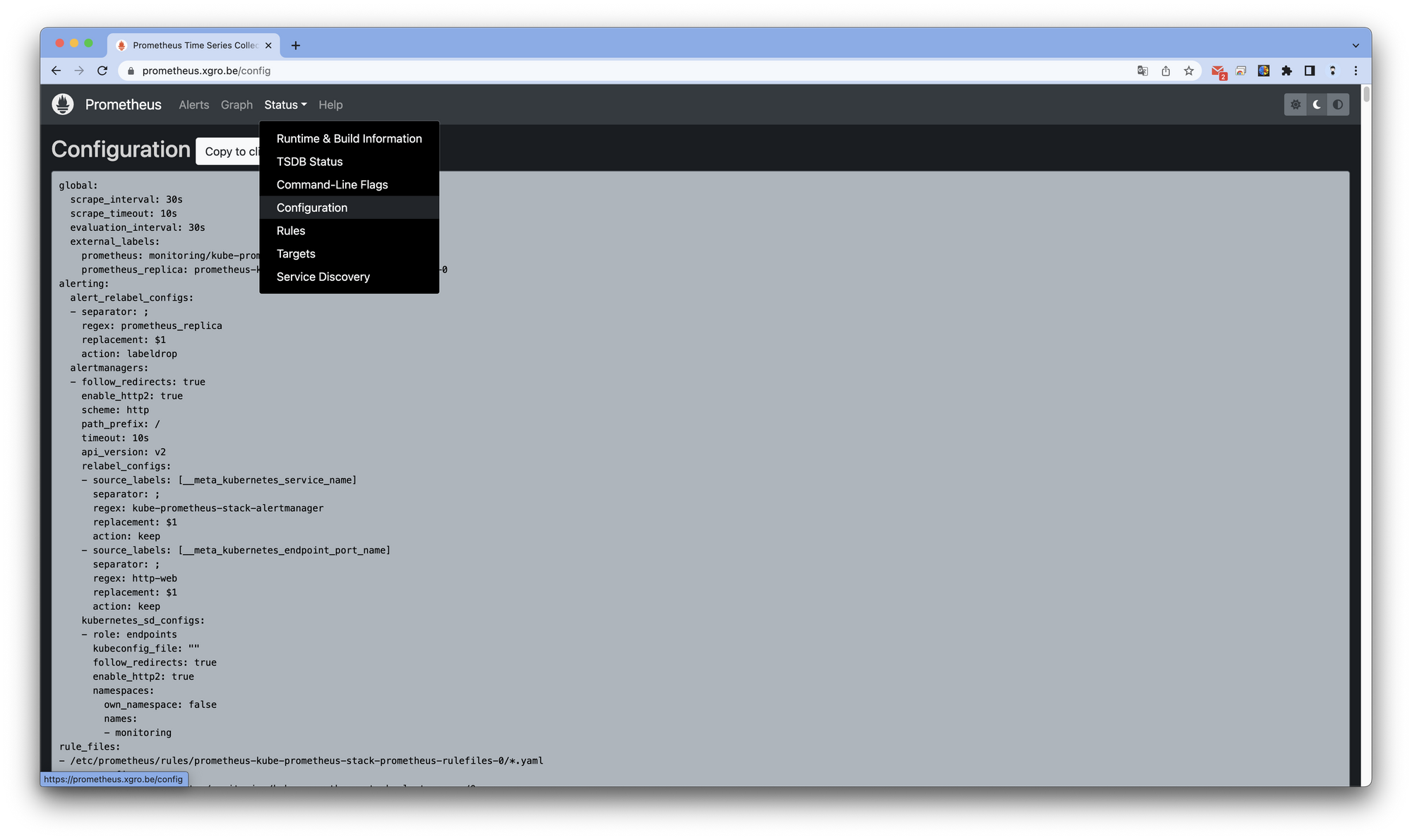
Status의 Configuration 탭에서 프로메테우스 설정과 관련된 내용을 확인할 수 있습니다.
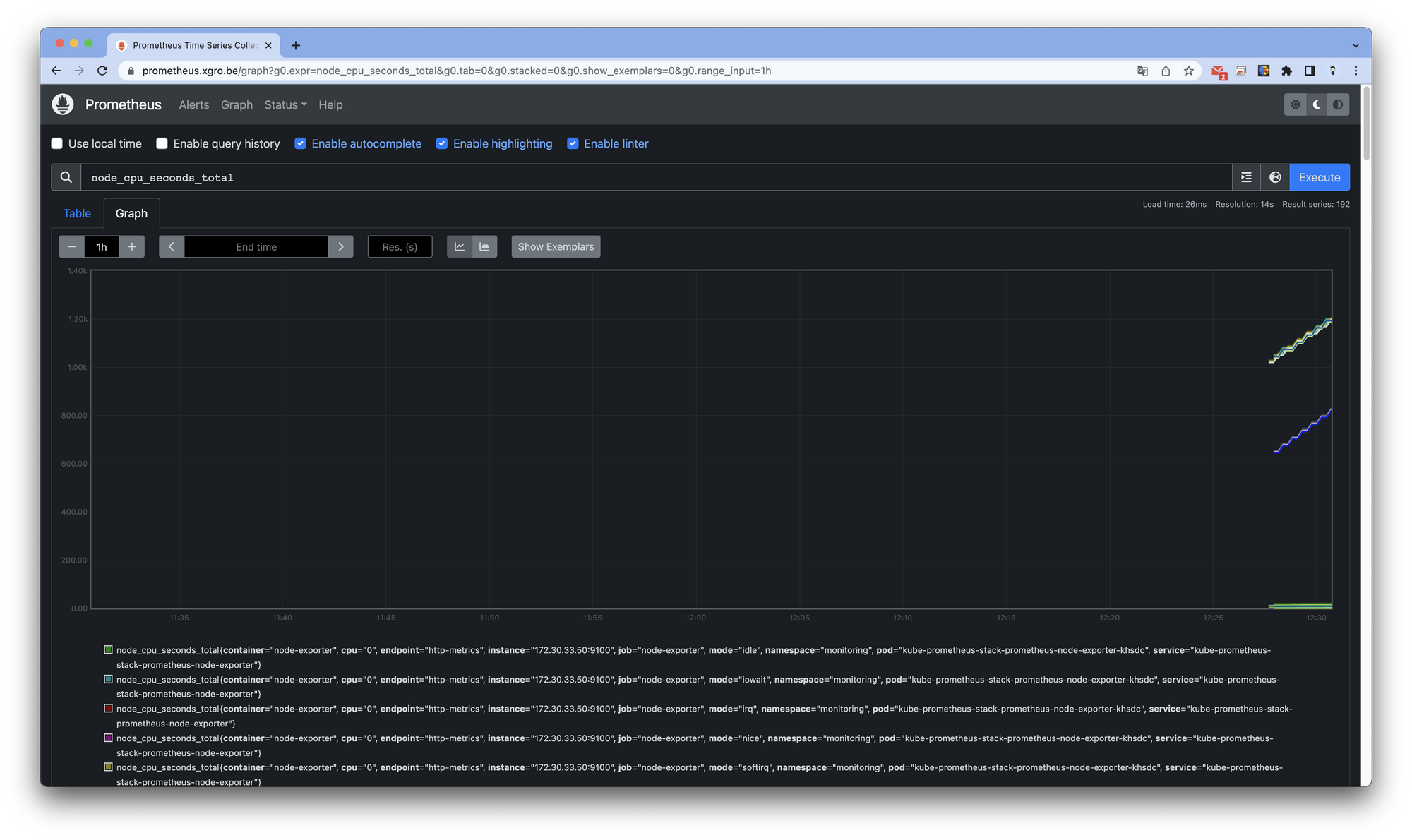
Gragh 탭에서 수집된 지표를 확인하고, 그래프로 나타낼 수 있습니다.
👉 Step 03. 그라파나
그라파나란?
TSDB 데이터를 시각화하고, 다양한 데이터 형식을 지원합니다. - 링크
- Grafana open source software enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored. Grafana OSS provides you with tools to turn your time-series database (TSDB) data into insightful graphs and visualizations.
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않습니다.
- 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용합니다.
- 접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
Configuration → Data sources : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가하였습니다. ← 서비스 주소 확인

✅ 대시보드 적용
그라파나의 강력한 기능 중 하나로, 공식 대시보드 저장소에서 대시보드를 추가하여 사용할 수 있습니다.
- kube-syate-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-syate-metrics-v2] Dashboard → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Node Exporter Full] Dashboard → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → Import → 13770 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
👉 Step 04. Nginx 서비스 적용해보기
NGINX 웹서버 애플리케이션 모니터링 설정 및 접속합니다.
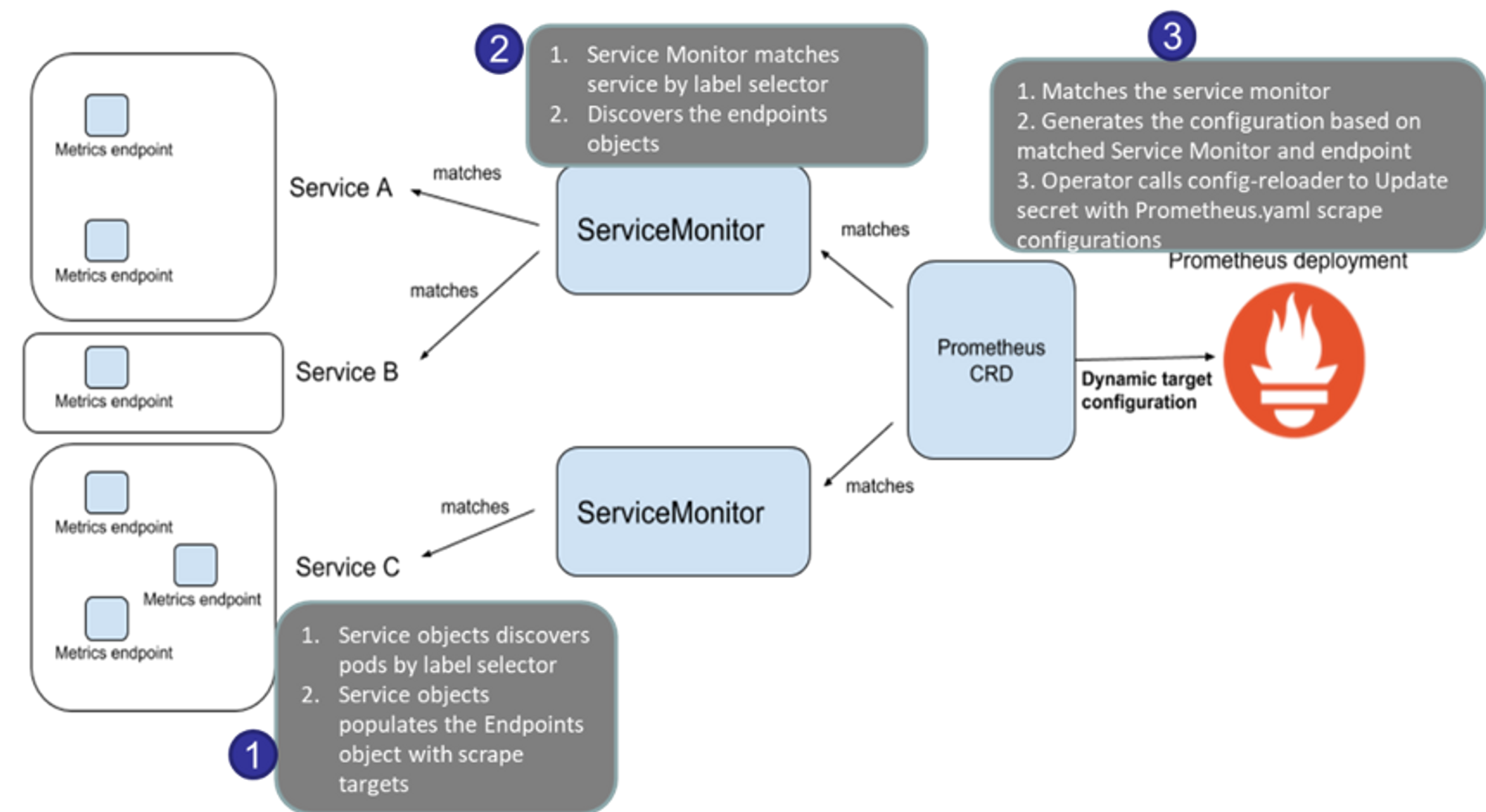
- nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능합니다.
- 프로메테우스 설정에서 nginx 모니터링 관련 내용을 서비스 모니터 CRD로 추가 할 수 있습니다.
- 기존 애플리케이션 파드에 프로메테우스 모니터링을 추가하려면 사이드카 방식을 사용하여
exporter 컨테이너를 추가하여 기능을 구현합니다. - nginx 웹 서버 helm 설치 - Helm
# helm Repo 추가
helm repo add bitnami https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install nginx bitnami/nginx --version 13.2.23 -f nginx-values.yaml
# CLB에 ExternanDNS 로 도메인 연결
kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME"
curl -s http://nginx.$KOPS_CLUSTER_NAME
kubectl logs deploy/nginx -f
# 반복 접속
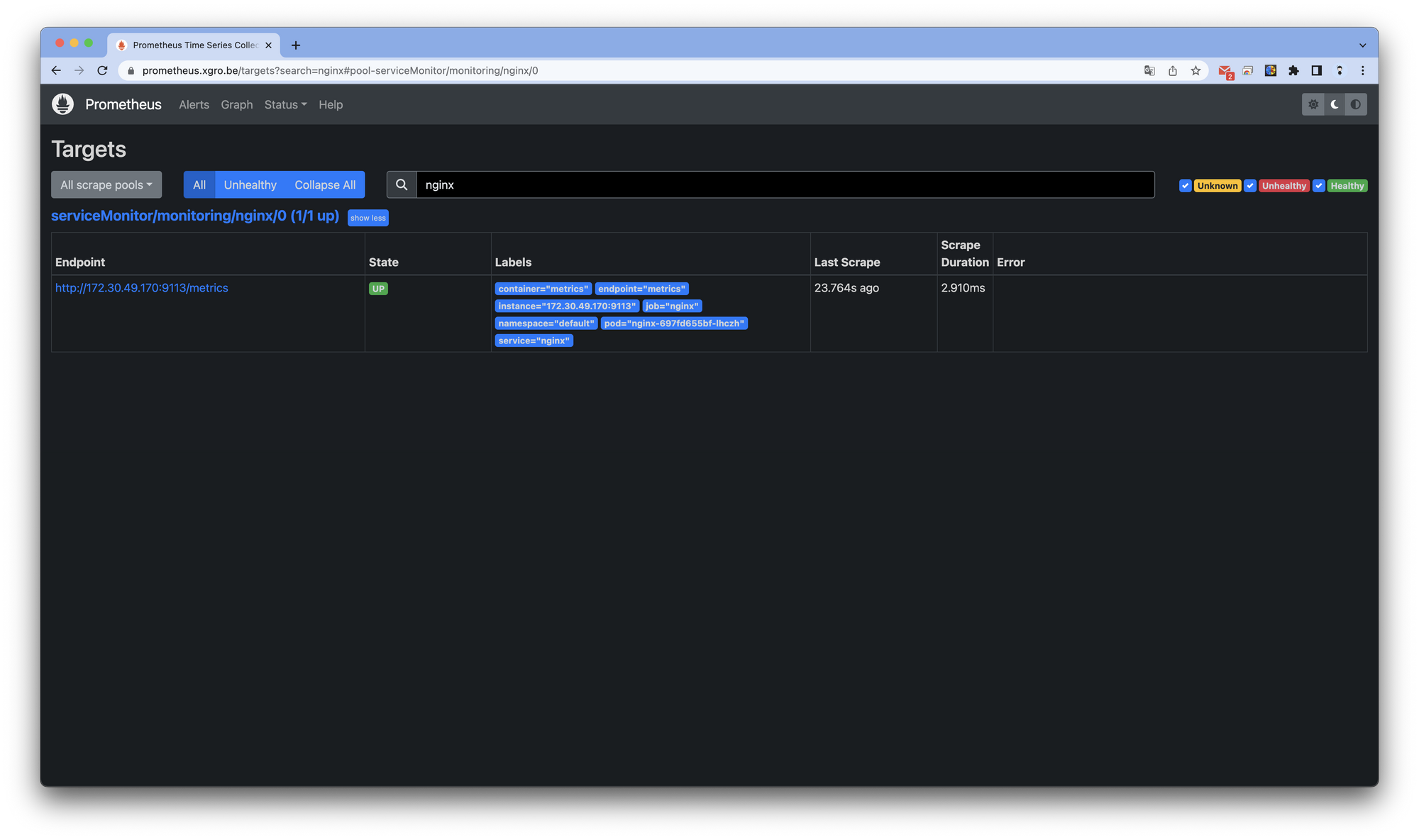
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done프로메테우스 타겟을 확인하면 서비스가 추가된 것을 확인할 수 있습니다.
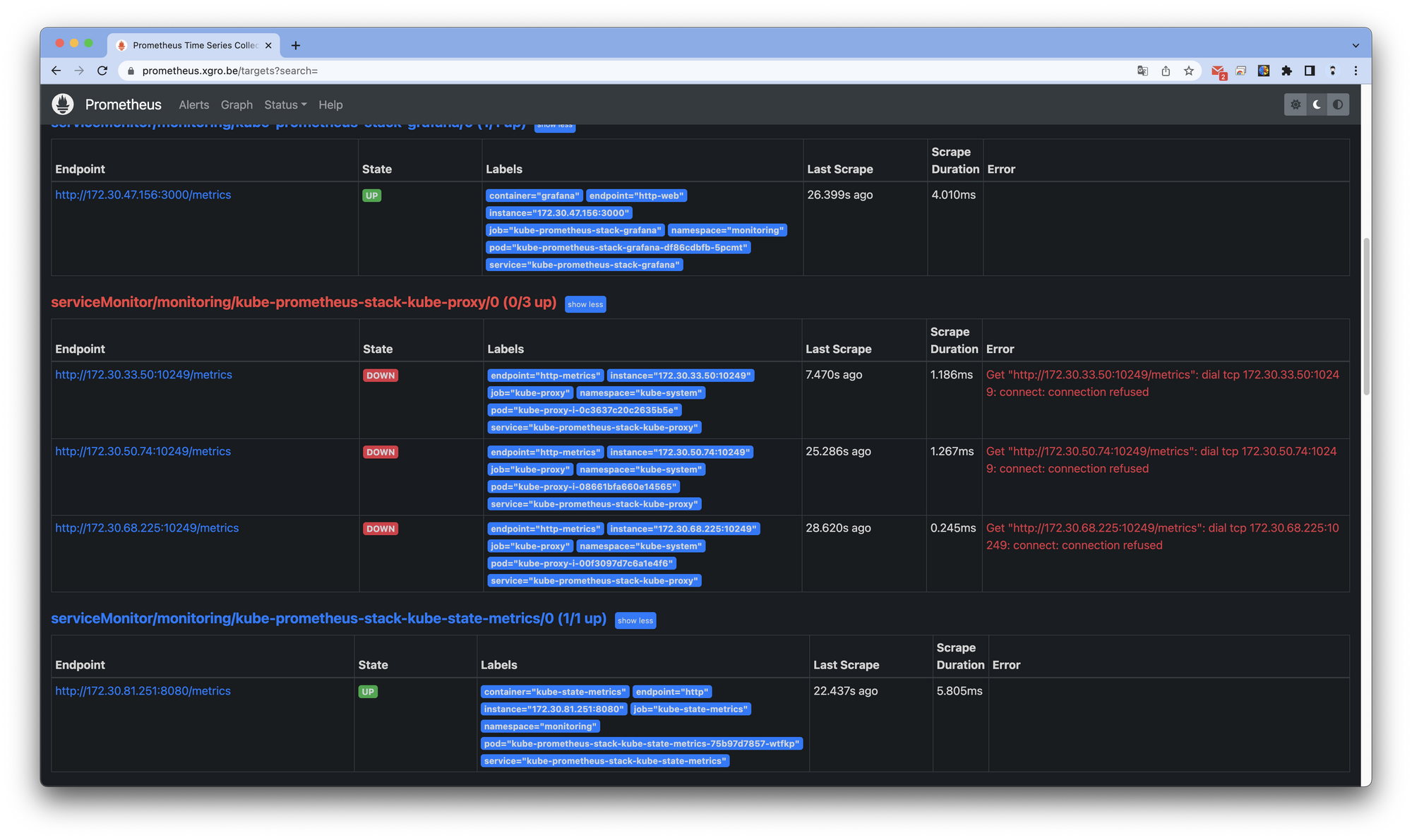
⛔ Trouble Shooting
절차대로 진행하였을 경우, 프로메테우스 Target 창을 확인하면 kube-proxy의 지표를 정상적으로 취득하지 못하는 것을 확인할 수 있습니다.
SSH 명령으로 확인하면, kube-proxy의 10249 포트가 127.0.0.1로 리스닝하고 있는 것을 확인할 수 있습니다.
# kube-proxy의 10249 포트의 정보를 확인
ssh -i ~/.ssh/id_rsa ubuntu@api.$KPOS_CLUSTER_NAME sudo ss -tnlp | grep kube-proxy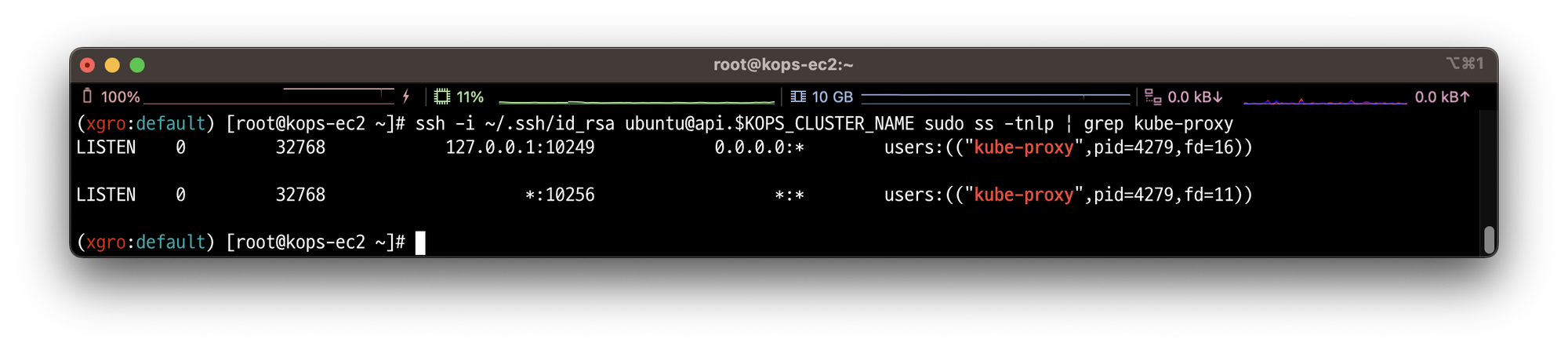
클러스터의 내용을 수정하여 이를 해결 할 수 있습니다
kops edir cluster
---
spec:
kubeProxy:
metricsBindAddress: 0.0.0.0
---
# 업데이트 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster --yes
내용을 적용하여 클러스터를 업데이트하면 아래와 같이 kube-proxy의 지표도 정상적으로 수집 할 수 있습니다.
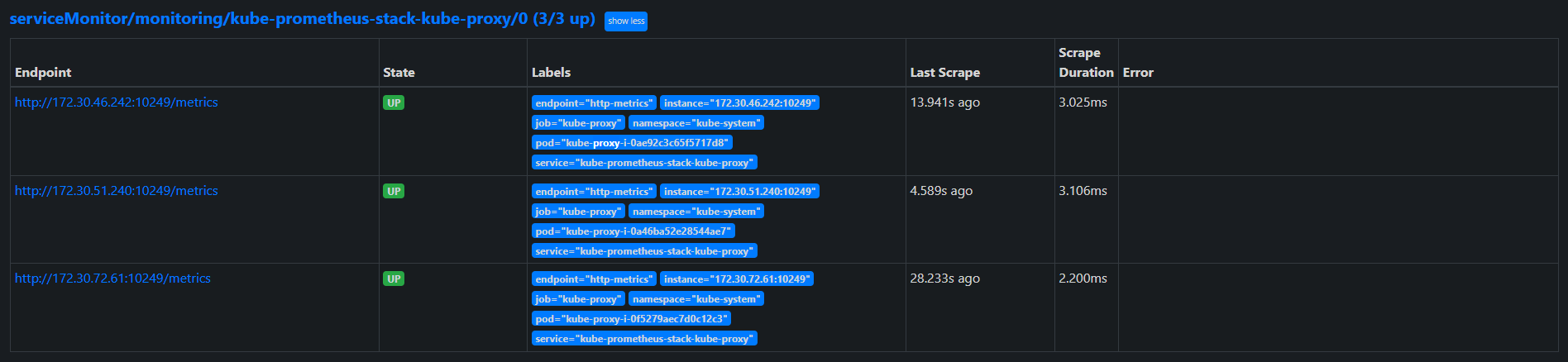
📌 Conclusion
5주차는 프로메테우스와 그라파나 조합을 사용하여 서비스의 지표를 수집하고, 사용자의 요구사항에 맞춰 대시보드를 구성하였습니다.
다른 사용자들이 만들어 공유한 그라파나 대시보드를 잘 활용하면, 그라파나를 보다 쉽게 사용할 수 있습니다.
쿠버네티스 환경에서 helm을 이용하는 강력한 장점을 다시한번 경험하였습니다. (배포 편의성)
다음주는 수집된 지표를 이용하여 알람을 발생 시킬 수 있는 AlertManager에 대해 스터디 하고자 합니다.
해당 기능들을 잘 조합하여 운영중인 서비스에 적용할 수 있는 방안도 고려해보겠습니다.
📌 Reference
- Trouble Shooting - https://github.com/kubernetes/kops/issues/6472
