
기존 추천 시스템은 대표적으로 콘텐츠 기반(Content-Based) 방식과 협업 필터링(Collaborative Filtering)방식으로 나뉜다.
오늘은 첫 시간인 만큼 추천 시스템에 대한 개괄적인 내용과 기존 두 방식의 장점을 결합하여 제안된 하이브리드 추천 시스템(Hybrid Recommender System)에 대해서 알아보자!
✋ 추천 시스템이란?
들어가기에 앞서서, 추천 시스템이란 무엇일까? 추천 시스템은 정보 필터링 중 하나의 방식으로, 사용자의 정보 데이터를 분석, 개인의 취향에 맞는 아이템을 추천하는 알고리즘으로 정의할 수 있다.
쉽게 말해서, 특정 사용자가 관심을 가질만한 정보(동영상, 이미지, 음악, 도서, 뉴스 등)를 추천하는 시스템 이다. 고객에게 다양한 아이템을 추천함으로써 고객의 정보 데이터가 누적되고, 이를 통해서 고객의 취향과 니즈를 파악할 수 있다. 고객 입장에서는 개인이 좋아할만한 다양한 콘텐츠와 상품을 접할 수 있기 때문에 만족도가 증가하고, 이를 통해 유치된 고객으로부터 기업은 매출 증가를 기대할 수 있다.
실제로 넷플릭스는 매출의 약 75%정도가 추천 시스템에 의해서 발생한다고 하며, 유튜브 또한 추천 시스템의 도입 이후 사용자들의 비디오 시청 시간이 20배 이상 증가했다고 한다. 넷플릭스, 왓챠, 유튜브, 페이스북, 인스타그램 등의 기업에서 모두 추천 시스템이 활용되고 있다.
추천 시스템에 사용되는 데이터의 종류
추천 시스템에 사용되는 데이터의 종류로는 2가지가 있다.
- Explicit 데이터 : 사용자가 선호도를 직접적으로 표현한 데이터
e.g. 평점, 별점, 좋아요/싫어요, 구독, 리뷰 등 - Implict 데이터 : 사용자의 선호도가 간접적으로 표현된 데이터
e.g. 검색 기록, 방문 페이지, 사용자 로그, 구매 내역 등
실무에서는 사실 Explicit, 명백한 데이터를 얻기는 쉽지 않다. 상품을 구매하거나 서비스를 이용해도 모든 사용자가 리뷰나 평점, 별점을 남기지는 않는다. 따라서 Explicit 데이터는 사용자의 취향이 정확하게 반영된다는 장점이 있는 반면, 데이터 자체를 얻기 힘들다는 단점이 존재한다.
Implicit 데이터는 서비스를 이용하는 사용자가 자신도 모르게 남기는 발자취같은 데이터다. 사용자가 웹 서핑을 하거나 서비스를 이용하며 로그데이터나 검색/클릭 기록은 무조건 남게 된다. 비교적 실무에서 얻기는 쉽지만, 사용자의 취향이나 선호도를 직접적으로 알 수는 없다.
유사도
추천 시스템을 이해하는데 중요한 수학적 개념인 유사도에 대해서 알아보자. 추천 시스템에서 유사도는 다음과 같은 방식으로 적용된다.
- 영상, 이미지, 텍스트 등의 다양한 형태의 아이템 정보 데이터를 벡터화한 이후, 아이템 벡터간의 유사도를 측정
- 측정된 유사도를 바탕으로 고객이 선호하는 아이템과 비교하여 유사도가 높은 아이템을 추천
유사도 방식의 종류
- 여기서는 대표적인 4가지 방식만을 간략하게 소개한다. 이 외에도 여러 효과적인 유사도 방식이 존재한다.
| 번호 | 기반 | 명칭 | 설명 |
|---|---|---|---|
| 1 | 집합 | 자카드 유사도 | 아이템 집합 간의 교집합 크기를 이용하여 유사도 측정 |
| 2 | 각도 | 코사인 유사도 | 아이템의 벡터 사이의 각도를 이용하여 유사도 측정 |
| 3 | 거리 | 유클리디안 거리 | 아이템의 벡터 사이의 거리를 이용하여 유사도 측정 |
| 4 | 상관관계 | 피어슨 상관계수 | 아이템의 벡터간 선형 상관 관계를 이용하여 측정 |
추천 시스템의 종류
 |
|---|
| 추천 시스템의 종류 |
🍓 콘텐츠 기반 필터링(Content-Based Filtering)
콘텐츠 기반 필터링은 말 그대로 콘텐츠의 유사도를 기반으로 사용자에게 추천하는 방법이다. 즉, 항목 자체를 분석한다. 사용자가 이용하거나 선택한 아이템과 유사한 아이템을 추천하는 방식이다.
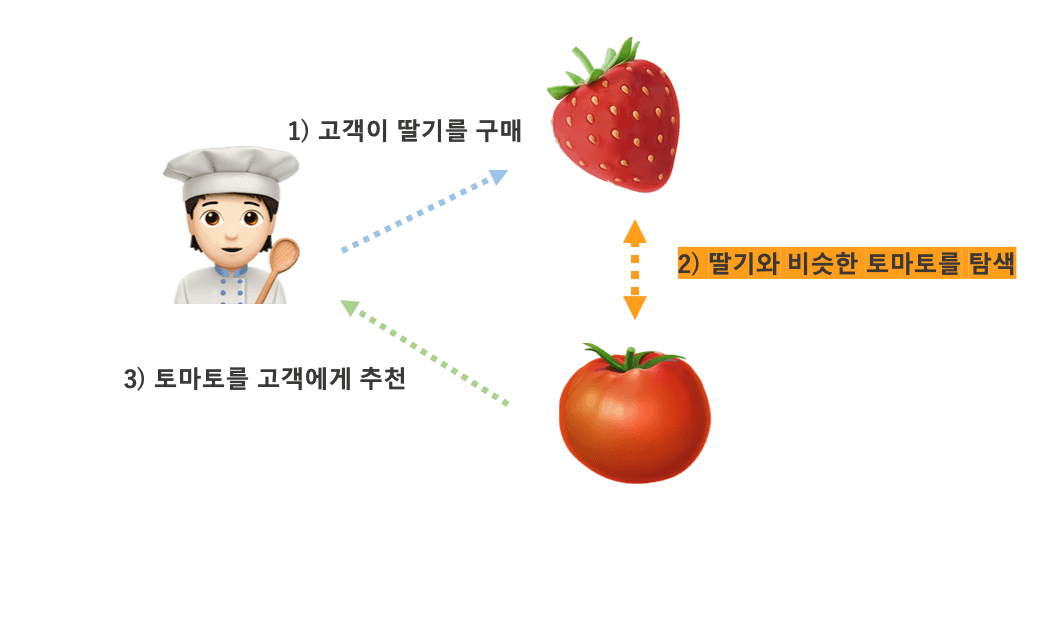 |
|---|
| e.g. 콘텐츠 기반 필터링(출처) |
🤼 협업 필터링(Collaborative Filtering)
협업 필터링은 다수의 사용자로부터 얻은 선호도 정보에 기반하여 사용자에게 추천하는 방법이다. 협업 필터링 방식은 보통 2가지로 나뉜다.
-
사용자 기반
취향이 비슷한 사용자들을 그룹화하여 아이템을 추천하는 방식 -
아이템 기반(Amazon 방식)
과거에 구매했던 아이템을 기반으로 그 아이템들과 연관성이 높은 다른 아이템들을 추천해주는 방식
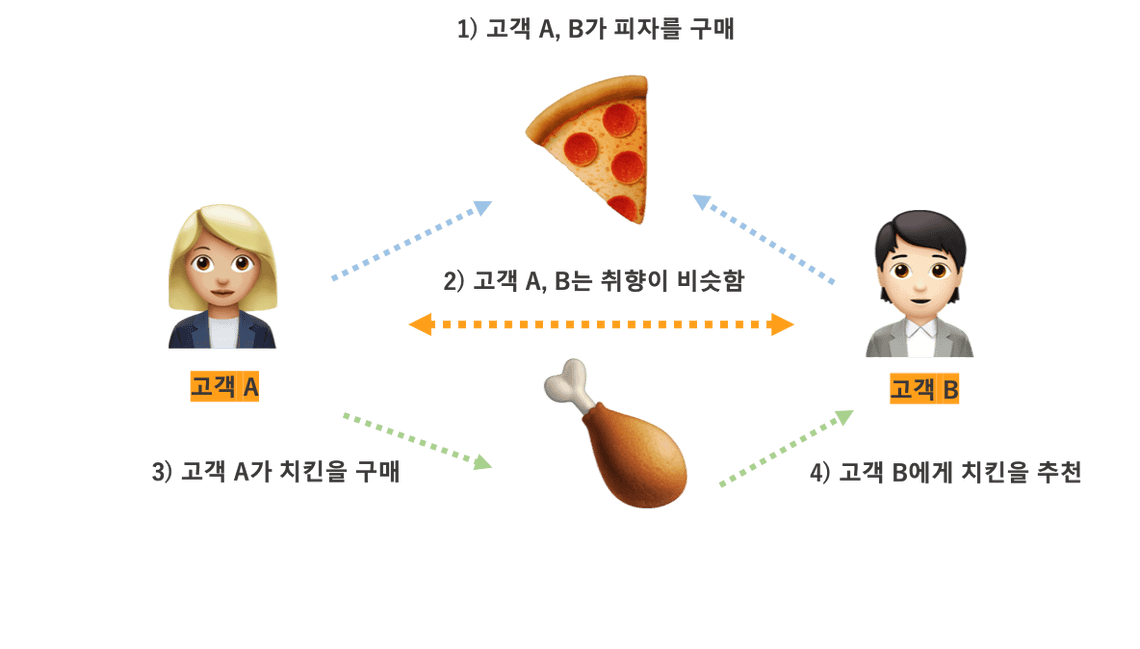 |
|---|
| e.g. 협업 필터링(사용자 기반 방식)(출처) |
요약 정리(같은 예시)
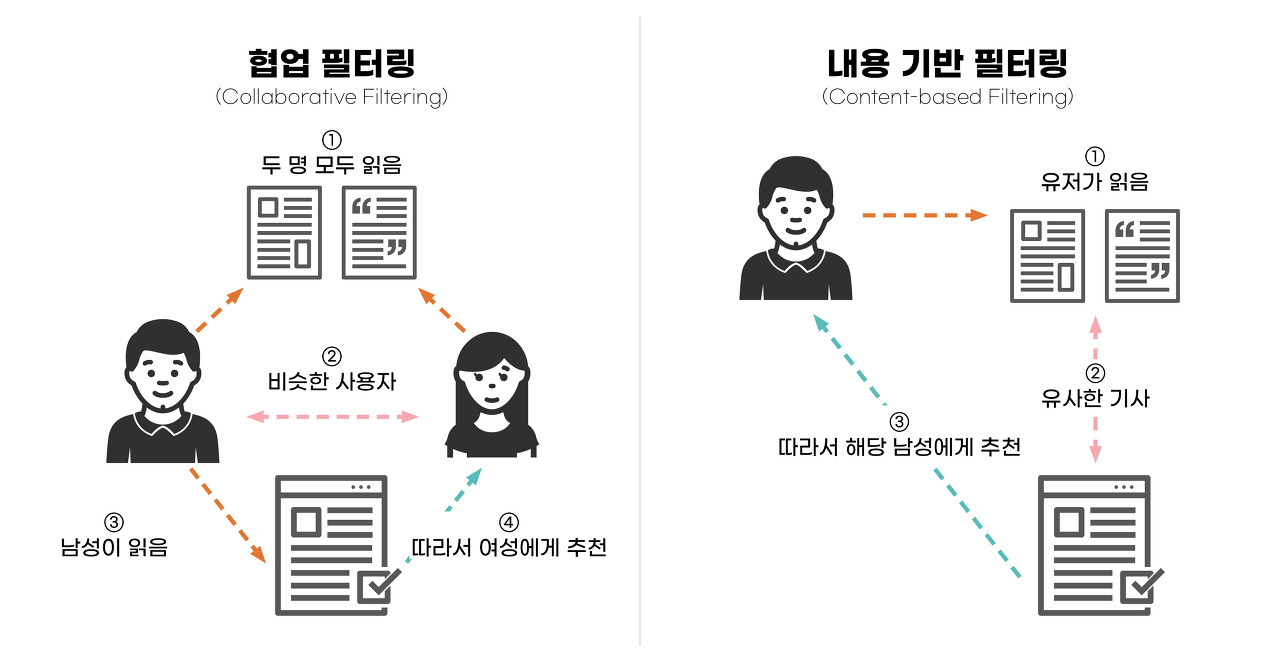 |
|---|
| e.g. 콘텐츠 기반 필터링과 협업 필터링(출처) |
하이브리드 추천 시스템(Hybrid Recommender System)
밑에서 설명!
🤷 콘텐츠 기반 필터링과 협업 필터링의 한계
-
콘텐츠 기반 필터링
콘텐츠 기반 필터링은 아이템 그 자체를 분석하여 유사도를 비교하기 때문에, 사용자가 선택한 아이템과 비슷한 분류를 계속해서 추천할 수 밖에 없다. 즉, 아이템이 가지고 있는 잠재적이고 간접적인 특징을 활용하기 어렵다. 쉽게 말해서, 콘텐츠 기반 필터링은 다양한 형식의 항목 추천이 어렵다는 명확한 단점이 존재한다. -
협업 필터링
협업 필터링 방식에는 크게 3가지의 단점이 존재한다.
i. 콜드 스타트(Cold Start)
콜드 스타트란 "새로 시작할 때의 곤란함"이라는 의미로, 데이터가 존재하지 않는 상태에서 추천을 할 수 없는 상황을 일컫는다. 협업 필터링을 위해서는 기존 데이터가 반드시 필요하므로 신규 사용자에게는 어떠한 아이템도 추천할 수 없다.
ii. 계산 효율성 저하
협업 필터링은 계산량이 비교적 많은 알고리즘이기 때문에 사용자 수가 많거나 행렬 분해(Matrix factorization) 시, 계산에 장기간의 시간이 소요된다. 사용자들의 수가 많아 데이터가 누적되면 정확도에 반비례하여 계산 시간이 오래 걸려 효율성이 떨어진다.
iii. 롱 테일(Long Tail)
롱 테일 현상은 '비대칭적 쏠림 현상'을 의미한다. 사용자들은 인기있는 소수의 콘텐츠에만 관심을 쏟게 되고 곧, 전체 추천 콘텐츠를 장악하게 된다. 인기가 저조한 콘텐츠는 정보의 부족으로 추천되지 못하게 된다.
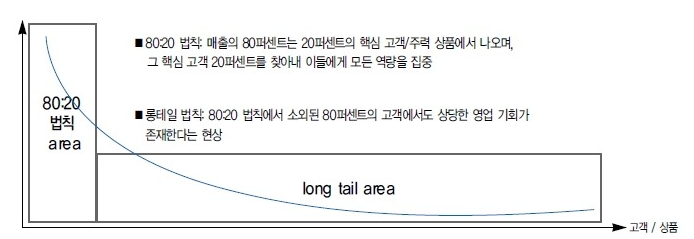 |
|---|
| cf.롱 테일(Long Tail)현상 설명 자료(출처) |
🔗 하이브리드 추천 시스템
콘텐츠 기반 필터링과 협업 필터링의 단점을 보완하기 위해 하이브리드 추천 시스템방식이 제안됐다. 하이브리드 추천 시스템은 2가지 이상 다양한 종류의 추천 시스템 알고리즘을 조합하는 방법이다. 즉, 하이브리드 추천 시스템은 다양한 알고리즘들의 단점은 보완하고 장점을 결합하여 더 좋은 알고리즘으로 거듭난다.
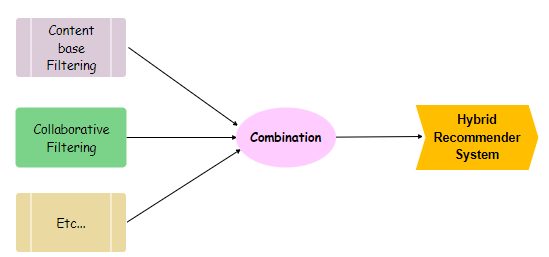 |
|---|
| e.g. 하이브리드 추천 시스템 |
Ref
jaaa_mj님의 "추천시스템(Recommender System)"
[pap] 주정민님의 "추천시스템, 그것이 알고싶다"
suminwooo님의 "추천 시스템(9) - 하이브리드 추천시스템"

요즘 사이드 프로젝트로 추천시스템에 대해 공부하고 있는데 좋은글 감사합니다!
참고해서 훌륭한 추천시스템 모델 학습 시켜보도록 하겠습니다!