
*2021. 7. 4. 11:38 에 작성한 글
파이썬이 뭔지는 알았으니
데이터 사이언스랑 연결고리를 찾아가보자
데이터 사이언스란?
데이터 사이언스
: 다양한 데이터로부터 지식과 인사이트를 추출하는 분야, 데이터와 연관된 모든 것, 데이터를 다루는 일
데이터 사이언스의 목표
: 가치를 더할 수 있는 문제 + 데이터로 해결
데이터 사이언티스트가 하는 일
: 가치를 더할 수 있는 일을 찾고 데이터를 이용해서 문제를 해결하는 것
어떤 분야에 어떤 문제가 있는지 잘 파악하고,
문제를 창의적으로 해결하기 위해 인사이트를 길러야 하고,
의미있는 데이터를 위한 엔지니어와 비즈니스의 핵심을 위한마케팅팀, 경영팀과 커뮤니케이션 중요
R
: 통계를 위해 만들어진 언어, 데이터 분석의 도구가 잘 갖춰짐, 통계와 시각화만을 위한 툴
Python
: 다양한 용도로 만들어진 언어, 데이터 분석의 도구가 평범, 다른 분야로 넘어갈 수 있음
데이터 사이언스 프로세스
문제 정의하기 - 데이터 모으기 - 데이터 다듬기 - 데이터 분석하기 - 데이터 시각화 및 커뮤니케이션
1. 문제 정의하기
: 해결하고자 하는 문제를 정의한다.
-
목표 설정
-
기간 설정
-
평가 방법 설정
-
필요한 데이터 설정
(해결하고자 하는 게 무엇인지, 언제까지 어떤 결과물을 얻을 것인지, 어떤 방식으로 데이터를 활용할 것인지)
2. 데이터 모으기
: 필요한 데이터를 모을 수 있는 방법을 찾는다.
-
웹 크롤링
-
자료 모으기
-
파일 읽고 쓰기
(누군가 이미 모아 놓은 데이터, 공공 기관 등에서 배포한 자료, 웹사이트에서 직접 데이터 수집 등)
- 데이터 다듬기
: 데이터의 퀄리티를 높여서 의미 있는 분석이 가능하게끔 한다.
-
데이터 관찰하기
-
데이터 오류 제거
-
데이터 정리하기
"쓰레기를 넣으면 쓰레기가 나온다(garbage in, garbage out)"
- 데이터 분석하기
: 준비된 데이터로부터 의미를 찾는다.
-
데이터 파악하기
-
데이터 변형하기
-
통계 분석
-
인사이트 발견
-
의미 도출
(수치 또는 그래프를 보면서 탐색 가능, 처음 설계했던 방식대로 데이터를 활용해서 결과를 도출해야 한다)
- 데이터 시각화 및 커뮤니케이션
: 분석 결과를 다른 사람들에게 전달
-
다양한 시각화
-
커뮤니케이션
-
리포트
(어떻게 문제를 해결하려 했는지, 어떻게 데이터를 모았는지, 어떤 방식으로 어떤 인사이트를 얻었는지 등을 전달.
적절한 시각화를 통해 소통을 원활히~)
Jupyter Notebook
파이썬으로 프로그래밍 하는 세 가지 방법
- 텍스트 에디터 + 커맨드 라인
: Sublime Text, Atom 등
-
장점 - 굉장히 가볍기 때문에 컴퓨터 사양이 좋지 않아도 사용 가능
-
단점 - 제공되는 툴이 적기 때문에 실수 가능, 권장되는 스타일 적음, 오류수정 어려움
- IDE(Integrated Development Evironment)
: Pycharm, Cloud IDE 등
-
장점 - 통합 개발 환경이기 때문에 제공되는 툴이 많음, 자동 완성, 코드스타일 교정
-
단점 - 소프트웨어 자체가 무거움
3.Jupyter Notebook 🌟
: Python, R, Julia 등 데이터 분석에 특화
-
웹브라우저에서 인터랙티브하게 작업을 하기 위한 툴, 코딩을 하면서 그래프도 보고 설명글 동시 작성 가능
-
장점 - 코드에 대한 결과물을 바로 볼 수 있음, 코드를 여러 단계로 나눠서 볼 수 있음, 마크다운 설명 깔끔 정리
-
단점 - IDE에서 제공하는 대부분의 툴이 없고 버전관리나 협업이 어려움
단축키(커맨드 모드에서)
A - 위에 셀 추가, B-아래에 셀 추가, DD-삭제
*실행 독립적, 순차적 X 그래도 실행되는 순서대로 작성
Markdown 정리
제목 :
#, ##, ###, #### 단계가 높아질수록 글자 크기 작아짐
번호가 있는 목록 :
1. 2. 3.
번호가 없는 목록 :
숫자 대신 *으로 리스트
줄바꿈 :
space 키 두번
문단 바꿈 :
enter 키 두 번
문자 강조 :
이탈릭체는 *나 _로.
볼드체는 **나 __ 두 개로.
취소선은 ~~로.
링크 :
[들어갈 글자](넣을 링크)
이미지 : ! [이름]\ (이미지주소)
구분선 추가 : --
Numpy
numpy(numerical python)
: 숫자와 관련한 파이썬 도구
numpy 배열(numpy array)
: 여러 값들을 효율적으로 다룰 수 있는 도구, 계산 작업을 편하게.
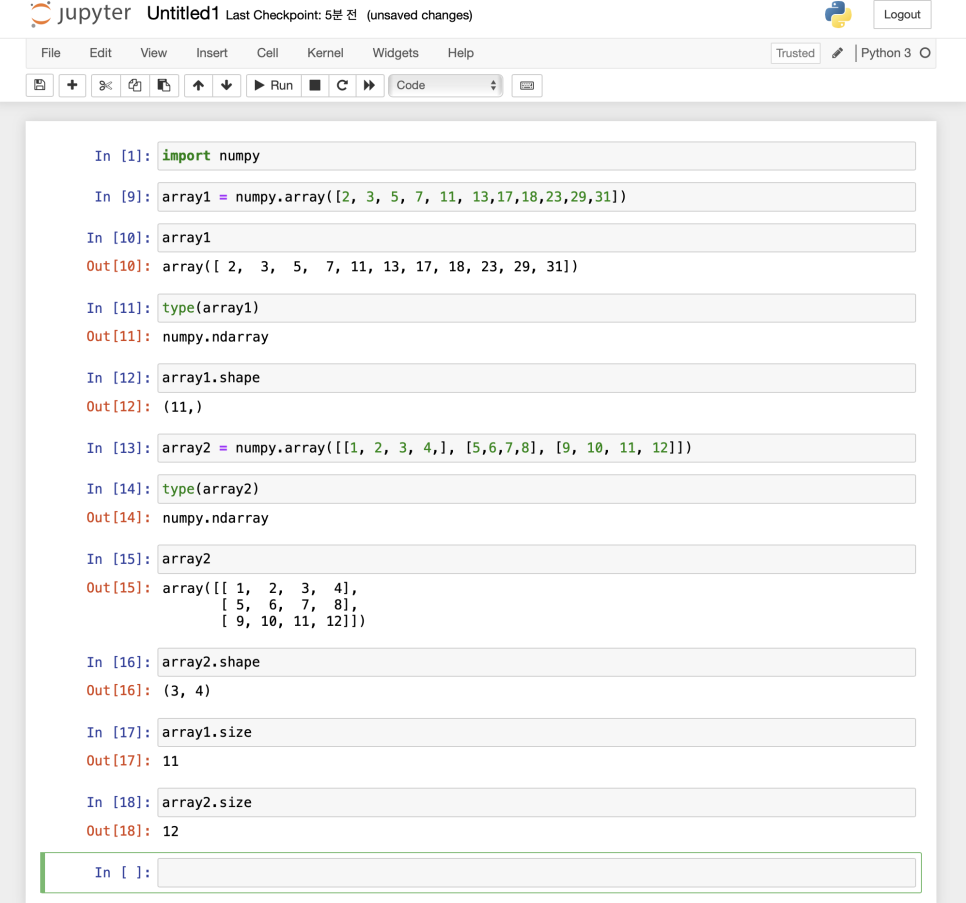
numpy array를 만드는 다양한 방법
1) 파이썬 리스트를 통해 생성
: numpy 모듈의 array 메소드에 따라 파라미터로 파이썬 리스트를 넘겨주면 numpy array가 리턴
array1 = numpy.array([2, 3, 5, 7, 11, 13, 17, 19 23, 29 31])
print(array1)
[2 3 5 7 11 13 17 19 23 29 31]
2) 균일한 값으로 생성
: numpy 모듈의 full 메소드를 사용하면, 모든 값이 같은 numpy array를 생성
array1 = numpy.full(6, 7)
print(array1)[7 7 7 7 7 7]
3) 모든 값이 0인 numpy array 생성
: 모든 값이 0인 numpy array를 생성하기 위해서는 full 메소드를 사용
array1 = numpy.full(6, 0)
array2 = numpy.zeros(6, dtype=int)
print(array1)
print()
print(array2)[0 0 0 0 0 0]
[0 0 0 0 0 0]
4) 모든 값이 1인 numpy array 생성
: zeors 메소드 대신 ones 사용
array1 = numpy.full(6, 1)
array2 = numpy.ones(6, dtype=int)
print(array1)
print()
print(array2)[1 1 1 1 1 1]
[1 1 1 1 1 1]
5) 랜덤한 값들로 생성
: numpy의 random 모듈의 random 함수 사용
array1 = numpy.random.random(6)
array2 = numpy.random.random(6)
print(array1)
print()
print(array2)[0.42214929 0.45275673 0.57978413 0.61417065 0.39448558 0.03347601]
[0.42521953 0.65091589 0.94045742 0.18138103 0.27150749 0.8450694 ]
6) 연속된 값들이 담긴 numpy array 생성
: numpy 모듈의 arange 함수 사용
#파라미터 1개
#arange(m) 0부터 m-1까지
array1 = numpy.arange(6)
print(array1)[0 1 2 3 4 5]
#파라미터 2개
#arage(n, m) n부터 m-1까지
array1 = numpy.arange(2, 7)
print(array1)[2 3 4 5 6]
#파라미터 3개
#arange(n, m, s)를 하면 n부터 m-1까지의 값들 중 간격이 s인 값들
array1 = numpy.arange(3, 17, 3)
print(array1)[ 3 6 9 12 15]
numpy 기본 통계
-
최댓값 max
-
최솟값 min
-
평균값 mean
import numpy as np
array1 = np.array([14, 6, 13, 21, 23, 31, 9, 5])
print(array1.mean()) # 평균값15.25
중앙값 median
*numpy array 메소드가 아니라 numpy의 메소드이다.
import numpy as np
array1 = np.array([8, 12, 9, 15, 16])
array2 = np.array([14, 6, 13, 21, 23, 31, 9, 5])
print(np.median(array1)) # 중앙값
print(np.median(array2)) # 중앙값
12.0
13.5
표준 편차 std
분산 var
import numpy as np
array1 = np.array([14, 6, 13, 21, 23, 31, 9, 5])
print(array1.std()) # 표준 편차
print(array1.var()) # 분산8.496322733983215
72.1875
numpy array vs. python list
-
numpy for 수치 계산이 많고 복잡할 때, 행렬같은 다차원 배열의 경우
-
python for 값을 추가하고 제거하는 일
Pandas
pandas
: numpy 기능(데이터 정리, 데이터 분석)에 외부 데이터 읽고 쓰기, 시각화 기능 등 추가. 특히 표형식!
DataFrame
: 표형식의 데이터를 담는 자료형, 2차원 형태의 데이터를 다루기 위한 자료형
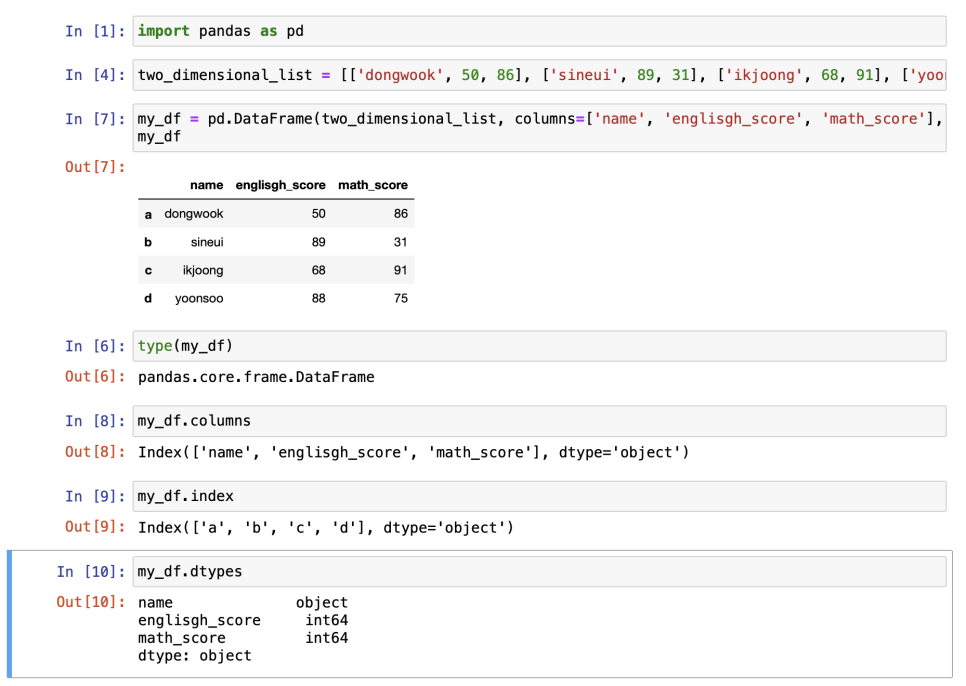
pandas의 dtype들
| dtype | 설명 |
|---|---|
| int64 | 정수 |
| float64 | 소수 |
| object | 텍스트 |
| bool | 불린(참과 거짓) |
| datetime64 | 날짜와 시간 |
| category | 카테고리 |
CSV(Comma-seperated values)
pandas로 데이터 읽어들이기

'데이터 사이언스 입문' 1.데이터 사이언스 시작하기|작성자 Index
