
1. 선형 회귀(Linear Regression)
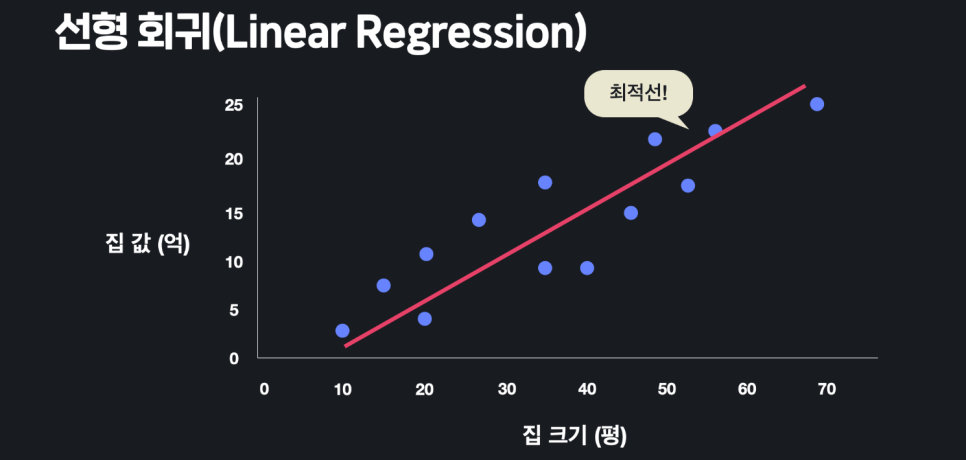
-
데이터를 가장 잘 대변해 주는 선을 찾아내는 것
-
지도 학습 알고리즘
-
목표 변수(y) : 맞추려고 하는 값 (target variable / output variable)
-
입력 변수(x) : 맞추는데 사용하는 값(input variable / feature)
-
학습 데이터(m) : 프로그램을 학습시키기 위한 데이터
-
가설 함수(hypothesis function) : 최적선(line of best fit)을 찾아내기 위해 시도하는 다양한 함수
-
가설 함수 평가법
-
평균 제곱 오차(MSE) : 데이터와 가설 함수가 평균적으로 얼마나 떨어져 있는지 나타내기 위한 방식
-
평균 제곱 오차가 크면 : 가설 함수가 데이터에 안 맞는다.
-
평균 제곱 오차가 작으면 : 가설 함수가 데이터에 잘 맞는다.
-
-
손실 함수(loss function)
-
가설 함수의 성능을 평가하는 함수
-
손실 함수가 작으면 : 가설 함수가 데이터 잘 맞는다.
-
손실 함수가 크면 : 가설 함수가 데이터에 안 맞는다.
-
-
선형 회귀 : 데이터에 가장 잘 맞는 가설 함수를 찾아야함
- 세타 값을 조율해서 최적선을 찾음
-
손실 함수 : 세타 값들을 바꿔 손실 함수의 아웃풋을 최소화
-
경사 하강법(Gradient Descent)
- 손실 함수의 극소점으로 가는 방법




-
prediction 함수
-
주어진 가설 함수로 얻은 결과를 리턴하는 함수
-
x의 각 요소의 예측값에 대한 numpy 배열을 리턴
-
-
prediction_difference 함수
- 모든 데이터의 예측 값과 실제 목표 변수의 차이를 리턴
-
gradient_descent 함수
- 실제 경사 하강법을 구하는 함수
-
학습률 α : 경사를 내려갈 때마다 얼마나 많이 그 방향으로 갈 건지를 결정하는 변수
-
일반적으로 1.0 ~ 0.0 사이의 숫자로 정하고(1,0.1, 0.01, 0.001 또는 0.5, 0.05, 0.005 이런 식으로)
-
여러 개를 실험해보면서 경사 하강을 제일 적게 하면서 손실이 잘 줄어드는 학습률을 선택
-
-
모델 평가하기
-
가설 함수는 세상에 일어나는 상황을 수학적으로 표현한다는 의미에서 '모델'
-
모델이 결과를 얼마나 정확히 예측하는지를 평가해야 함
-
평균 제곱근 오차(RMSE)
-
2. 다중 선형 회귀(Multiple Linear Regression)
-
다중 선형 회귀
-
여러 개의 입력 변수를 사용해서 목표 변수를 예측하는 알고리즘
-
시각적으로 표현하기 어려움
-
입력 변수 = 속성 = feature
-
i번째 데이터의 j번째 속성
-
목적: 세타 값들을 조금씩 조율하면서, 학습 데이터에 가장 잘 맞는 세타 값들을 찾아내는 것
-
그래야 좋은 가설 함수가 나오고, 최대한 정확하게 예측을 할 수 있으니까
-
-
경사 하강법
-
손실을 가장 빨리 줄이는 방향으로 세타 값들을 바꿔주는 방법
-
손실을 최소화하는 하나의 방법
-
이 과정을 한 번 거칠 때마다 손실을 최대한 빨리 감소시키는 방향으로 세타 값들이 업데이트
-
충분히 반복하면 결국 손실을 최소에 가깝게 줄일 수 있음
-
우리는 학습 데이터에 잘 맞는 세타 값들을 찾게 되고 데이터에 잘 맞는 가설 함수를 찾았다고 할 수 있음
-
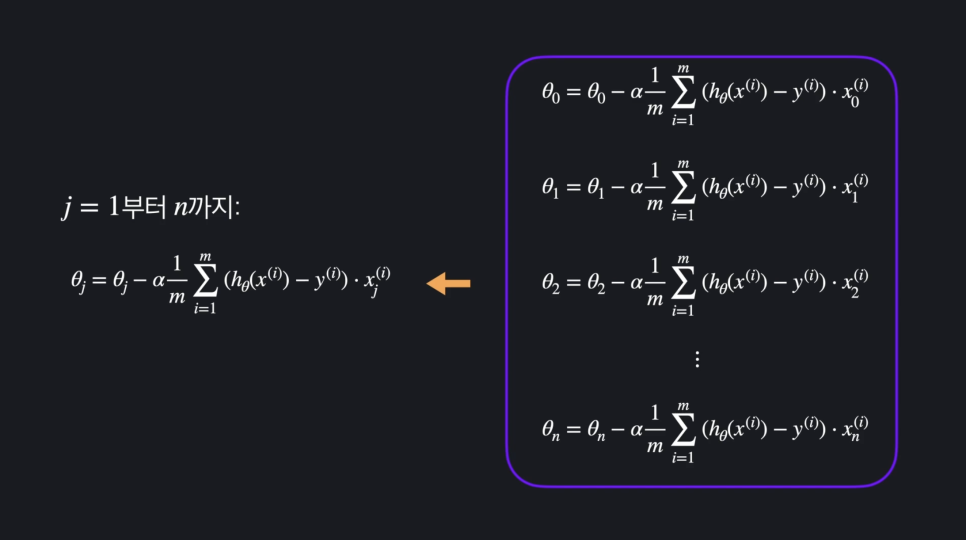
-
정규 방정식
-
normal_equation 함수
- 파라미터로 설계 행렬 X, 모든 목표 변수 벡터 y를 받아서 정규 방정식을 계산해 최적의 theta 값들을 numpy 배열로 리턴

-
-
경사 하강법 vs 정규 방정식
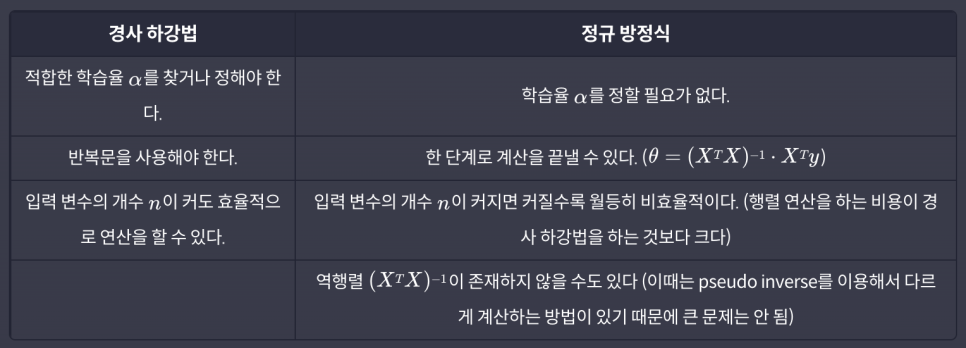
-
입력 변수(속성)의 수가 엄청 많을 때는(1000개를 넘느냐를 기준으로 사용할 때가 많습니다) 경사 하강법
-
비교적 입력 변수의 수가 적을 때는 정규 방정식
-
-
Convex 함수
-
convex 함수에서는 항상 경사 하강법이나 정규 방정식을 이용해서 최소점을 구할 수 있는 반면, non-convex 함수에서는 구한 극소점이 최소점이라고 확신할 수 없음
-
다행히 선형 회귀 손실 함수로 사용하는 MSE는 항상 convex 함수
-
-
참고 : http://localhost:8888/notebooks/codeit_multiplelinearregression.ipynb
3. 다항 회귀(Polynomial Regression)
-
다항 회귀
-
고차식을 찾아서 예측하는 알고리즘
-
데이터에 잘 맞는 일차 함수나 직선을 구하는 게 아니라 다항식이나 곡선을 구해서 학습
-
속성들을 서로 곱해 차항을 높여주는 방법으로 선형 회귀 문제를 다항 회귀 문제로 만들면 속성들 사이에 있을 수 있는 복잡한 관계들을 프로그램에 학습시킬 수 있음
-
단일 속성 다항 회귀 : 입력 변수 1개
-
다중 다항 회귀 : 입력 변수 여러개
-
-
참고 : http://localhost:8888/notebooks/codeit_polynomialregression.ipynb
4. 로지스틱 회귀(Logistic Regression)
-
로지스틱 회귀
-
분류
-
데이터에 가장 잘 맞는 시그모이드 함수를 찾기
-
선형 회귀로도 분류는 가능하지만 예외적인 데이터에 민감
-
선형 회귀는 결과의 범위가 없어 얼마든지 크거나 작아질 수 있음
-
무조건 0과 1 사이의 값이 나오는 시그모이드 함수가 분류에 더 적합
-
- 선형 회귀 가설 함수

-
로지스틱 회귀 가설 함수
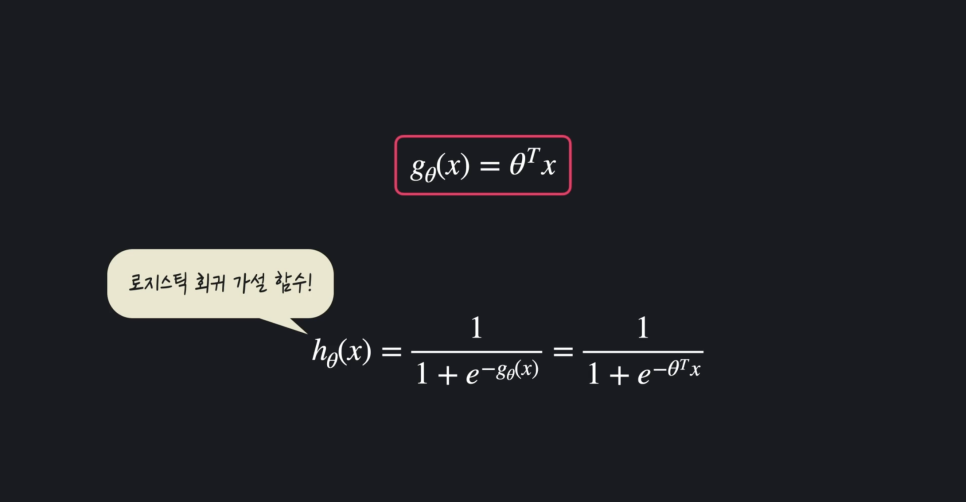
-
일차 함수 : 인풋에 따라 아웃풋이 무한히 커지거나 작아질 수 있다.
-
따라서 무조건 0과 1사이의 값이 나오는 시그모이드 함수 사용
-
-
로지스틱 회귀의 목적 : 단순한 시각화
-
결정 경계선(Decision Boundary) : 분류를 구별하는 경계선
-
로그 손실(log-loss/cross entropy)
-
예측값이 실제 결과랑 얼마나 괴리가 있는지 알려주는 함수
-
손실의 정도를 로그 함수로 결정
-
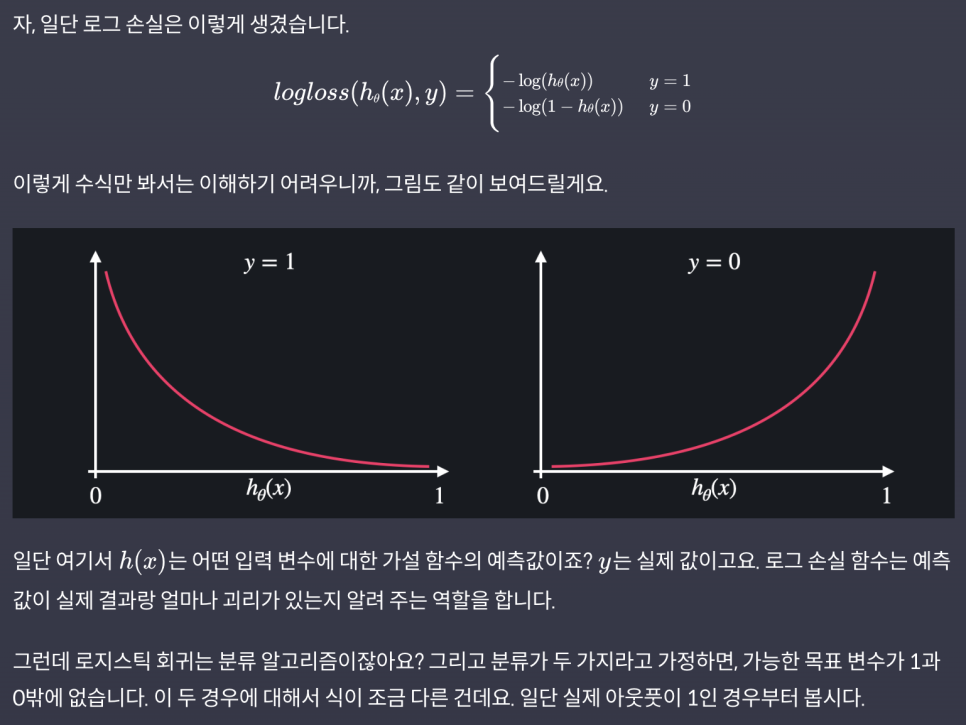

-
로지스틱 회귀 손실 함수
- 모든 데이터의 로그 손실을 계산한 후, 평균을 낸다.
- 로지스틱 회귀와 정규 방정식

책으로 한 번 공부하고 코드잇 들으면 이해가 빠르다.
'머신 러닝' 기본 지도 학습 알고리즘들|작성자 Index
