이전 글에서는 딥러닝의 기본 단위인 퍼셉트론(Perceptron), 그리고 단일 뉴런의 학습 과정을 살펴봤다.
이번 글에서는 이 퍼셉트론을 여러 층 쌓은 다층 퍼셉트론(MLP, Multi-Layer Perceptron)의 개념과 역전파(Backpropagation) 학습법까지 알아보려한다.
1. Multi-Layer Perceptron (MLP)
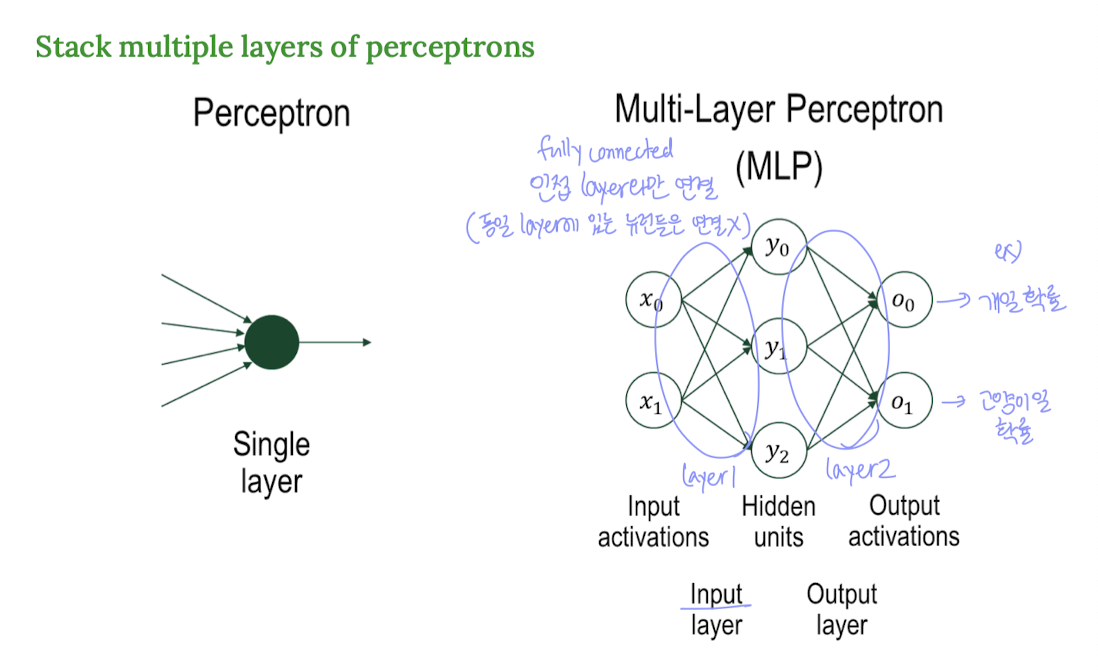
Multi-Layer Perceptron(MLP)는 말 그대로, 퍼셉트론을 여러 층으로 쌓은 구조이다.
- 입력층(Input layer)
- 은닉층(Hidden layer)
- 출력층(Output layer)
여기서 “다층”이란 은닉층이 하나 이상 존재하는 경우를 말한다.
👉 층(layer)과 층(layer) 사이를 Fully Connected(완전 연결)로 연결한다.
(단, 같은 층 안의 뉴런들끼리는 연결하지 않는다.)
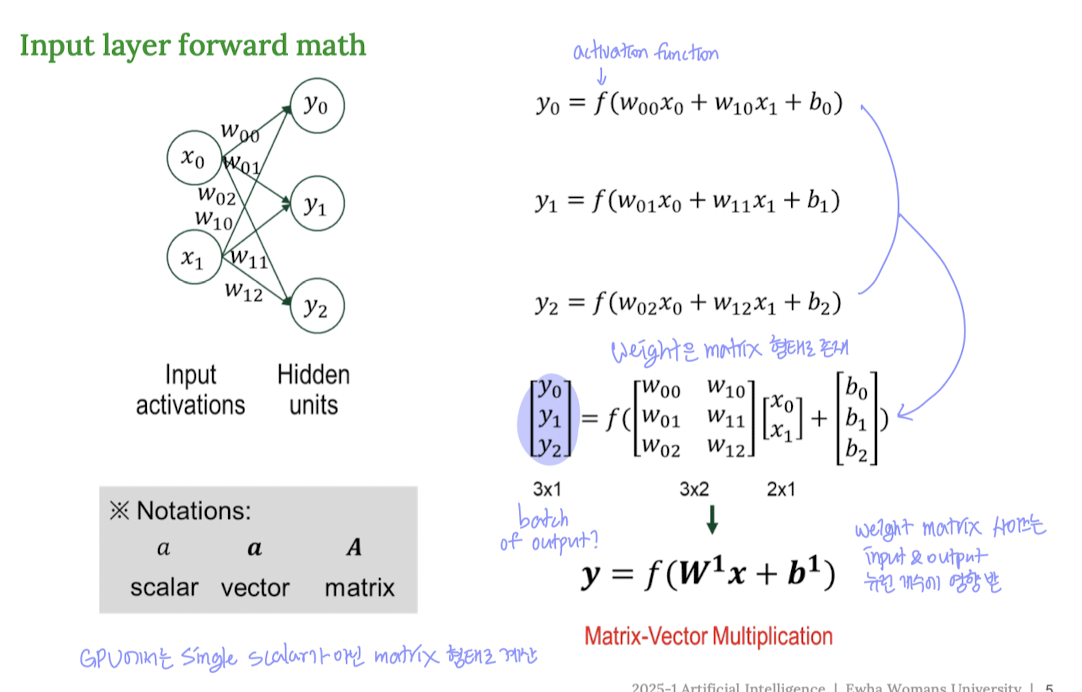
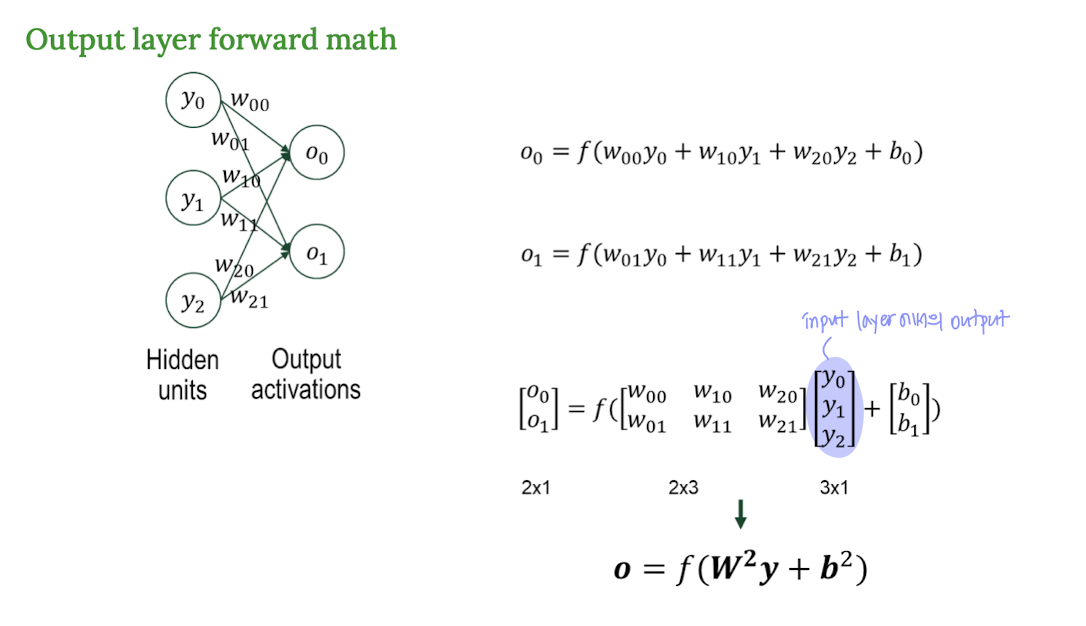
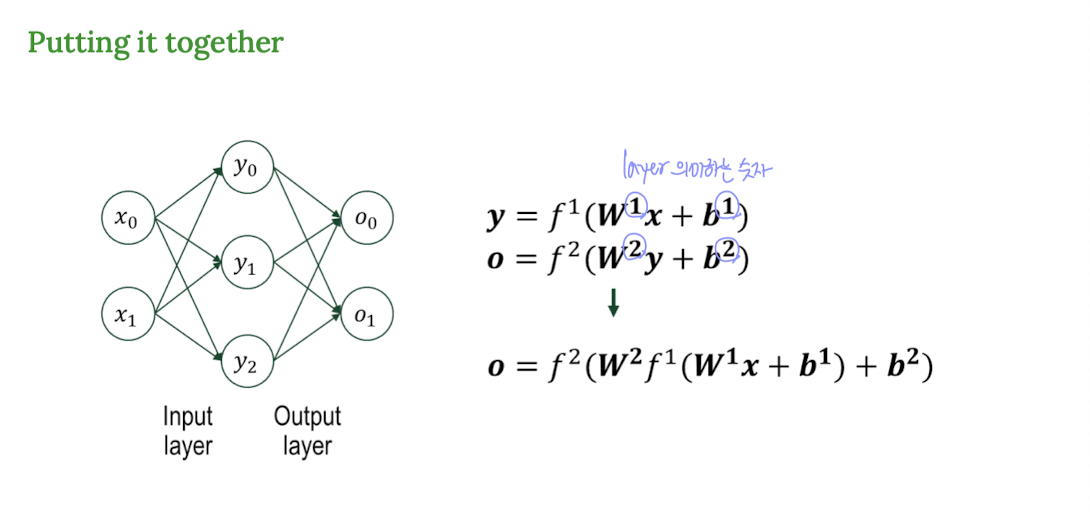
MLP의 수식 표현: 행렬(Matrix) 연산으로 간결하게!
층이 많아지면 입력과 가중치를 일일이 다 곱하고 더하는 게 복잡해진다.
그래서 행렬(Matrix)과 벡터(Vector) 연산으로 깔끔하게 표현한다.
행렬 곱 연산 기본 흐름:
[출력 벡터] = act([가중치 행렬] x [입력 벡터] + [편향 벡터])
👉 이렇게 계산하면 GPU 병렬 연산에도 최적화되어 빠르게 학습할 수 있다.
2. The Need for Multiple Layers
XOR 문제: 단일 퍼셉트론으로는 풀 수 없다
📌 XOR 연산 :
- 입력 두 개가 다르면 출력 1
- 입력이 같으면 출력 0
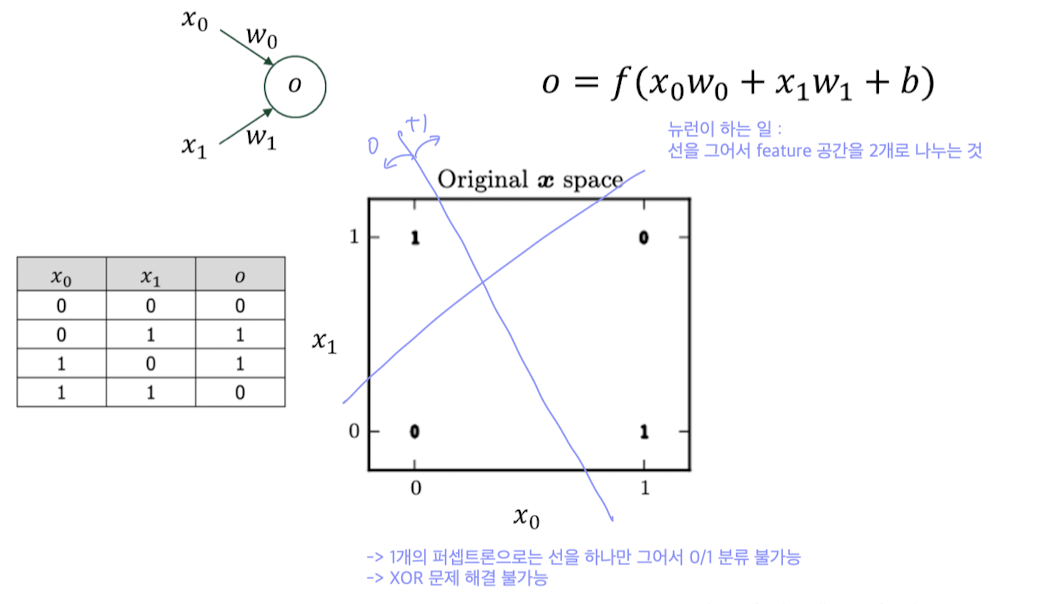
보다시피 그 어떤 선을 그어도 0과 1을 분류하도록 그을 수 없다..!
👉 단일 퍼셉트론은 선을 하나만 그어서 데이터를 구분해야 하는데,
XOR은 선 하나로 구분이 불가능하다. (선형 분리 불가)
두 개 이상의 층이 있으면 XOR도 해결 가능!
1) 2-Layer perceptron 구조
입력층과 출력층 사이에 ‘숨겨진(hidden) 유닛’을 추가함으로써 두 개의 layer를 만든다.
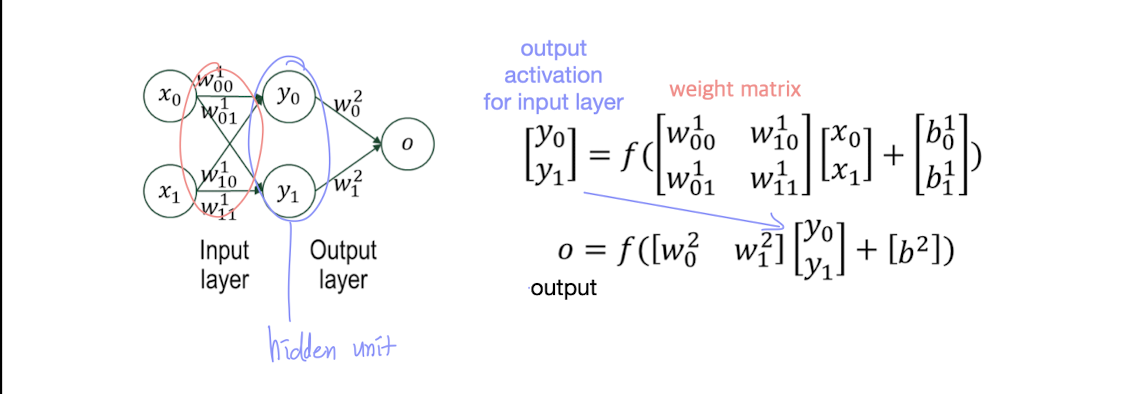
- Input Layer: 입력값 ,
- Hidden Layer(은닉층): 중간 계산을 수행하는 ,
- Output Layer: 최종 출력
XOR 문제를 어떻게 해결하는지, 자세히 살펴보자.
2) 4가지 입력에 대해 계산하기
학습을 통해 다음과 같은 가중치가 주어졌다고 가정한다.
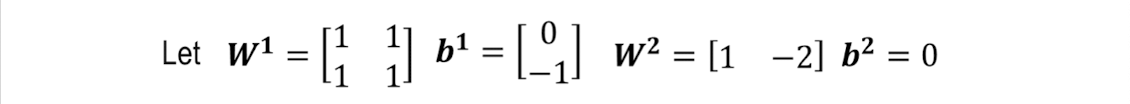
활성화 함수는 ReLU:
XOR 문제의 4가지 입력 조합에 대해 계산한 최종 출력은 다음과 같다

👉 각 입력에 대해 중간 결과와 최종 출력을 구하면 정확히 XOR 연산 결과를 내고 있다!
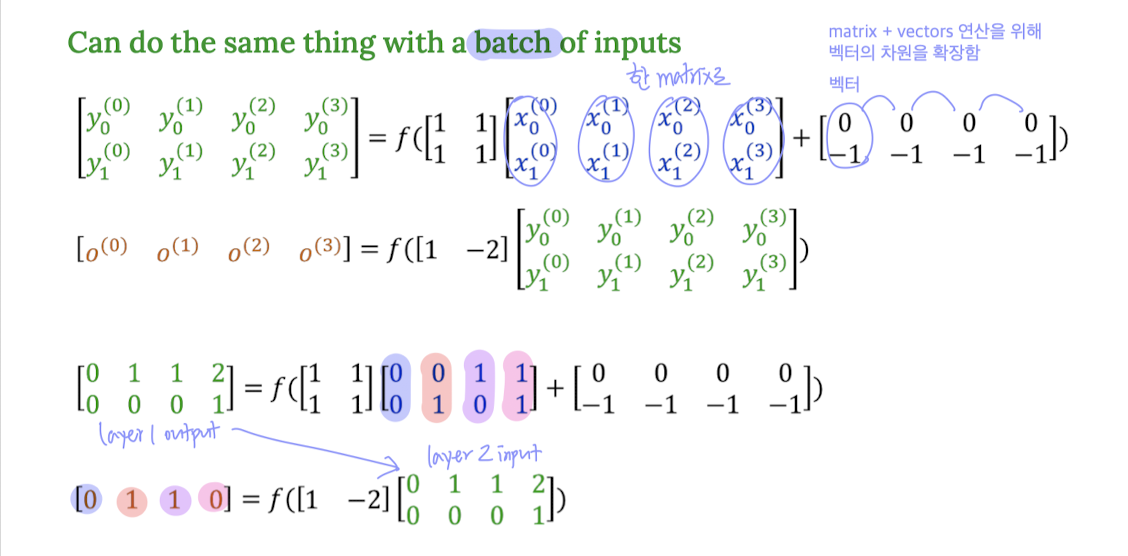
3) Batch 연산으로 정리
한 번에 여러 입력을 묶어서 계산하는 Batch 형태로도 표현할 수 있다.
(벡터 4개를 하나의 행렬로 묶음)
이때 bias를 맞춰주기 위해 bias 벡터의 차원을 확장해 같이 더해준다.
4) 직관적 이해: Feature Space 변화
최종 출력을 좌표상에 나타내면 다음과 같다.
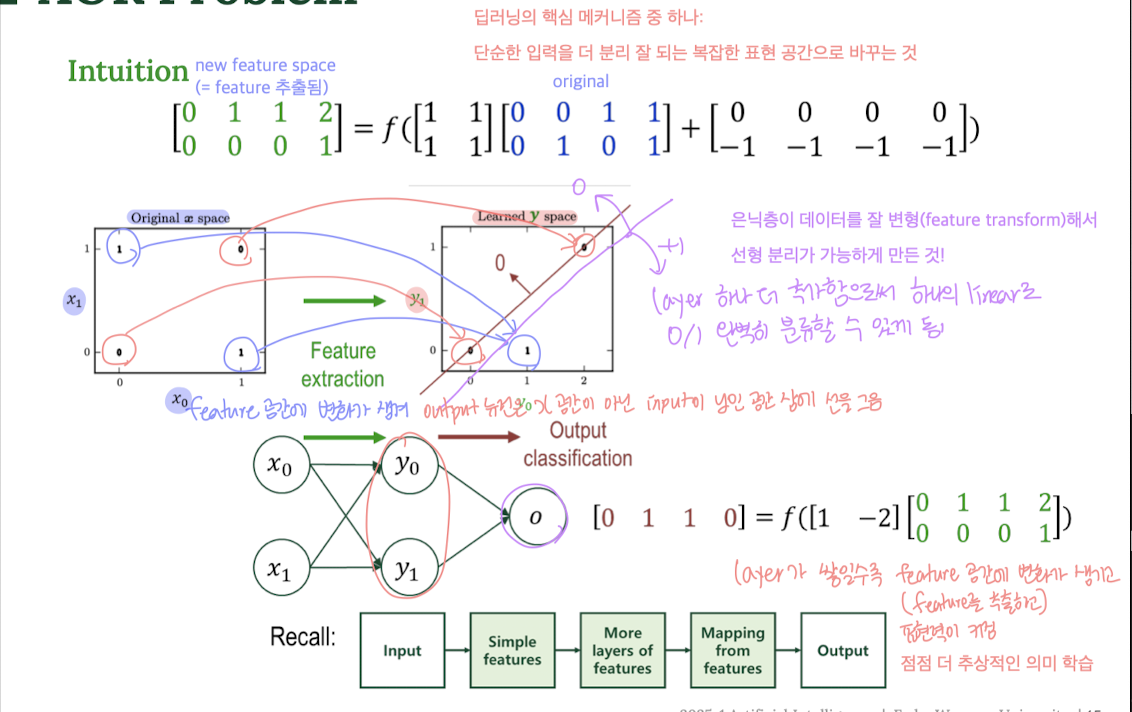
변환 후 :
- 은닉층을 거치며 feature가 변형되면서
- 새로운 공간에서는 XOR 문제를 선형으로 구분할 수 있다.
💡 즉, “단순한 입력 데이터를 더 복잡하고 잘 분리되는 새로운 표현 공간으로 변환”하는 것!
(= 딥러닝의 핵심 메커니즘 중 하나)
3. MLP에서의 경사하강법(Gradient Descent)
앞에서는 weight와 bias 값을 “주어진 것”으로 두고 계산했었다.
하지만 실제 딥러닝에서는 이 값들을 우리가 직접 학습해야 한다.
MLP를 학습한다는 건 뭘까?
단일 퍼셉트론에서의 학습 목적과 동일하다
예측값과 실제 정답(label)의 차이, 즉 cost를 최소화하는 것
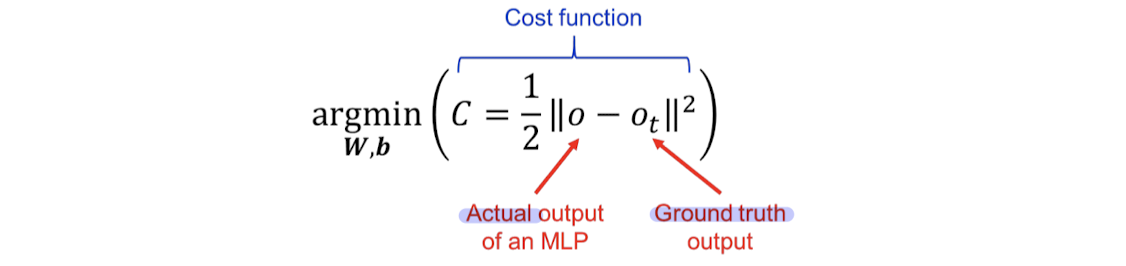
📌 Gradient Descent 복습
: weight를 조금씩 수정하면서 cost를 최소화하는 weight을 찾아야하는데,
이때 사용하는 weight 수정 알고리즘이 경사하강법(Gradient Descent)이다.
경사하강법(Gradient Descent) - 단일 퍼셉트론
📌 수식:
이때 Cost를 weight에 대해 미분하면:
- : 활성화 함수의 미분값
- : 입력값
cf) 유도 과정 :

💡 weight 업데이트는
“오차(error) × 활성화 함수 미분값 × 입력”으로 이루어진다!
경사하강법(Gradient Descent) - 다층 퍼셉트론
MLP 전체에서 Gradient를 계산하려면?
뉴런 하나만이 아니라,
다층 퍼셉트론(MLP)은 여러 레이어, 여러 뉴런이 연결되어 있다.
그래서 체인 룰을 이용하고, 가중치와 오차(error)를 각 층별로 거꾸로 계산해야 한다.
1️⃣ 출력층(2층) 가중치 업데이트
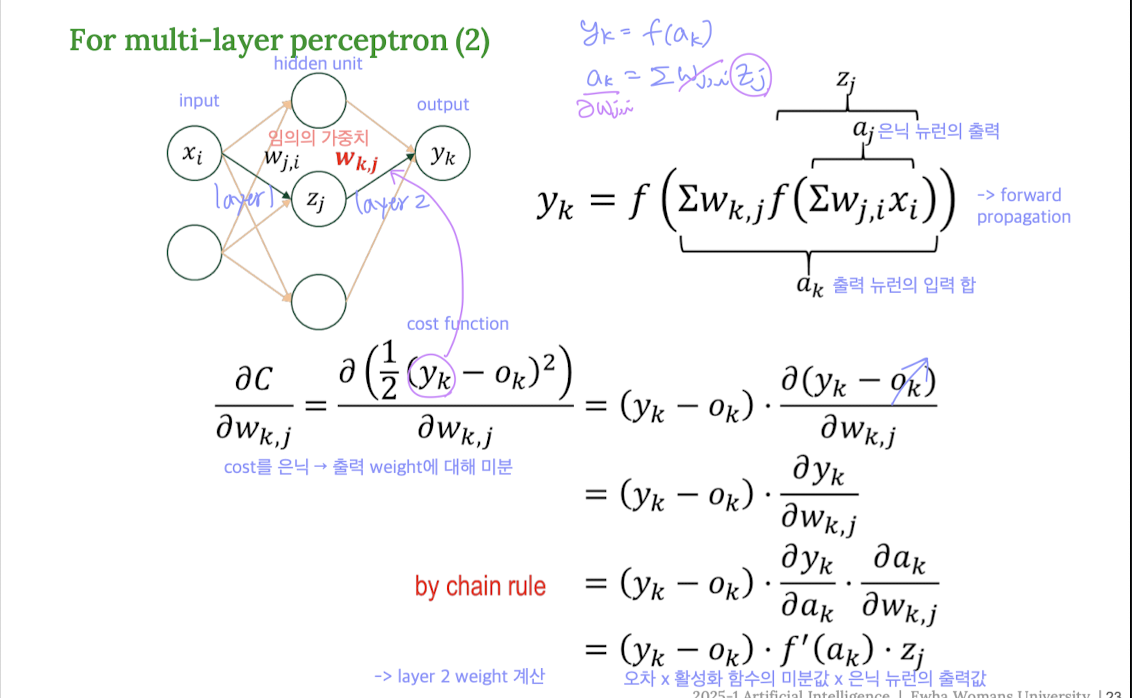
출력층의 뉴런에 대해 기울기를 계산하면:
📌 최종 수식 :
👉 출력층 weight의 gradient는
오차(error) × 활성화 함수의 미분값 × 은닉 뉴런의 출력값으로 계산된다.
2️⃣ 은닉층(1층) 가중치 업데이트
은닉층은 정답값이 없기 때문에, 출력층의 error를 전파(backpropagate)해서 계산해야 한다.
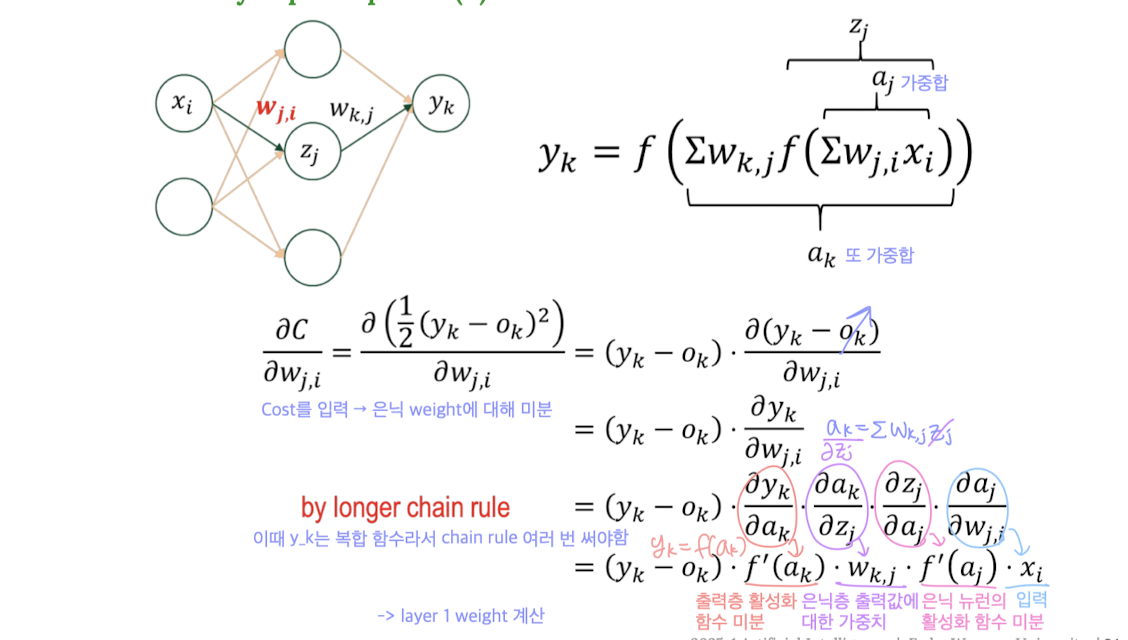
📌 최종 수식 :
👉 은닉층의 weight()에 대한 gradient는
오차 × 출력층 활성화 함수 미분 × 은닉→출력 weight × 은닉 뉴런 활성화 함수 미분 × 입력의 곱으로 계산된다.
앞서 본 것처럼,
우리는 경사하강법(Gradient Descent)을 통해 가중치를 업데이트할 때,
각 weight마다 기울기(gradient)를 계산해야 한다.
하지만 다층 퍼셉트론(MLP)처럼 레이어가 깊은 경우,
모든 weight에 대한 gradient를 일일이 계산하는 건 매우 복잡하다.
👉 그래서 출력층에서 계산된 오차(error)를 시작으로, 은닉층 방향으로 차례차례 오차를 전파하며 gradient를 계산하는 효율적인 방법이 필요하다.
👉 이 과정을 통해 은닉층 뉴런들도 어떻게 weight를 수정해야 할지 알 수 있게 된다.
👉 이게 바로 Backpropagation(오차 역전파)이다.
4. 역전파(Backpropagation)
💡 역전파란?
출력층 → 은닉층 → 입력층 방향으로 “오차”를 전파하면서
각 가중치에 대해 “얼마나 수정해야 하는지(기울기)”를 계산하는 것
출력층에서 시작해서,
- 각 가중치가 손실(loss)에 얼마나 영향을 미쳤는지 (weight gradient)를 계산하고
- 이 기울기(gradient)를 사용해 가중치를 업데이트(update)한다.
하나의 은닉층 뉴런이 1개의 출력층 뉴런에 연결되어 있을 때
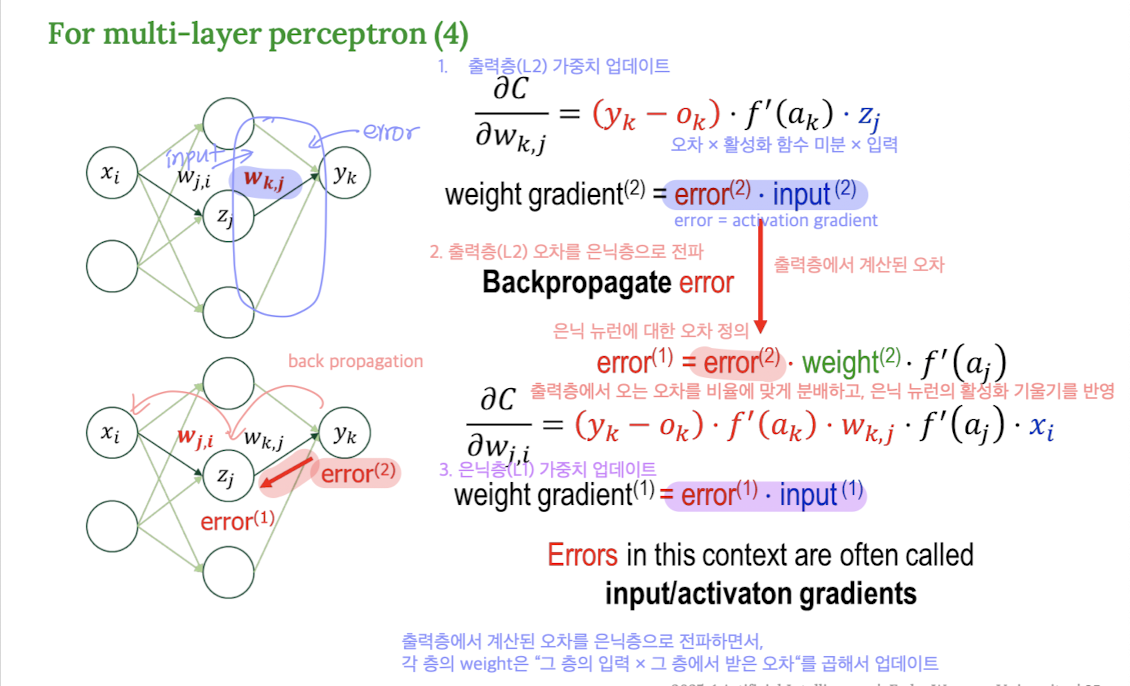
1️⃣ 출력층의 오차(error)를 은닉층으로 전파
출력층 뉴런 의 출력과 정답 레이블 사이 오차를 계산하고,
이 오차를 은닉층 뉴런 로 되돌려(backpropagate) 보내야 한다.
📌 수식:
- : 출력 뉴런의 오차 (예측 - 정답)
- : 출력 뉴런의 활성화 함수 미분
- : 은닉층 뉴런 에서 출력 뉴런 로 향하는 weight
👉 출력 뉴런의 오차를, 연결된 weight와 activation의 기울기를 고려하여 은닉층으로 전파한다.
2️⃣ 은닉층 weight 업데이트
이제 은닉층 weight를 업데이트해야 한다.
📌 수식:
- : 은닉층 뉴런 로 들어온 입력값
👉 출력층에서 계산된 오차를 은닉층으로 전파하면서,
각 층의 weight은 “그 층의 입력 × 그 층에서 받은 오차“를 곱해서 업데이트한다.
하나의 은닉층 뉴런이 여러 개의 출력층 뉴런에 연결되어 있을 때
1️⃣ 여러 출력 뉴런에서 오는 오차를 합산
하나의 은닉 뉴런 가 여러 출력 뉴런들과 연결되어 있을 경우,
각 출력 뉴런에서 오는 오차를 weight에 비례하여 받아 합산해야 한다.

📌 수식 :
- 출력 뉴런 각각의 오차를 구하고,
- 해당 weight 로 scaling해서,
- 모두 더해준다.
👉 여러 출력 뉴런에서 오는 오차들을 weight 비율에 따라 받아서 은닉층에서 하나로 모은다!
2️⃣ 은닉층 weight 업데이트
앞서 계산한 를 가지고, 은닉층 가중치도 업데이트한다.

📌 수식 :
- 여전히 “에러 × 입력” 형태!
- 단, 여기서 사용하는 에러는 이제 여러 출력 뉴런으로부터 backpropagate된 합산된 에러다.
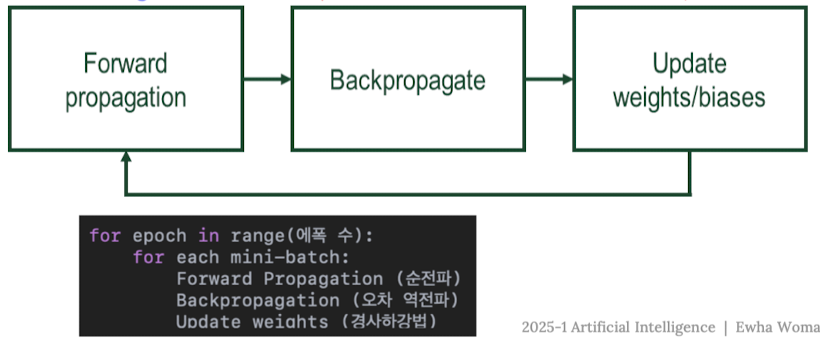
5. 딥러닝 학습의 전체 흐름
딥러닝 모델은 단순히 입력 → 출력만 계산하는 게 아니라,
“가중치(weight)“를 스스로 학습하는 과정이 반드시 필요하다.
그 학습의 전체 흐름은 이렇게 세 단계로 정리할 수 있다.
Forward → Backpropagation → Update
1. Forward Propagation(순전파):
- 입력을 넣고 출력을 계산다.
- 예측값과 정답 사이의 오차(loss)를 계산한다.
2. Backpropagation(역전파): 출력층에서 시작해
- 오차가 각 weight에 얼마나 영향을 미쳤는지(기울기, gradient)를 구한다.
3. Update weights and biases
- 기울기를 사용해 가중치를 업데이트한다.
cf)
- 이 과정을 모든 mini-batch에 대해 반복한다. = 1 Epoch
- 이것을 또 여러 Epoch 동안 반복한다.
결론
정리
다음 글에서는?
- 활성화 함수 종류 (ReLU, sigmoid, tanh 등)
