1. 모델 평가 (Model Evaluation)
회귀 문제 (Regression)
정답과 예측값의 차이를 기반으로 평가한다.
- MSE (Mean Squared Error): 평균 제곱 오차. 큰 오차에 큰 패널티.
- RMSE (Root MSE): MSE에 루트를 씌운 값. 원래 단위와 같아서 해석이 쉬움.
- MAE (Mean Absolute Error): 평균 절대 오차. 모든 오차를 동일하게 반영.
‼️ 위 세 가지는 y의 scale에 민감하게 반응
민감하게 반응하지 않는 방법들:
- MAPE (Mean Absolute Percentage Error): 상대 오차. 정답이 작을수록 오차 커짐.
- MSLE (Mean Squared Log Error): log를 씌워 오차 계산. 과대 예측에 관대하고, 과소 예측에 민감.
- RMSLE (Root Mwan Squared Log Error): log를 씌워 오차 계산. 과대 예측에 관대하고, 과소 예측에 민감.
- R²(결정계수): 0~1 사이 값으로 모델의 설명력을 나타냄. 1에 가까울수록 좋은 모델.
📌 MAPE는 값이 0에 가까울수록 불안정하다 (분모가 작아서).
📌 RMSLE는 log로 오차를 줄이기 때문에 과소 예측에 더 민감하게 반응한다.
분류 문제 (Classification)
예측한 클래스와 실제 클래스가 얼마나 일치하는지 평가한다.
- Accuracy: 전체 데이터 중 맞춘 비율.
‼️ 정확도만으로 충분하지 않을 수 있다
- 클래스가 불균형한 경우 (예: 고장/질병 데이터)
- 오분류 비용이 다른 경우 (예: 암 진단)
Confusion Matrix (혼동 행렬)
이진 분류 문제에서 성능을 설명할 때 가장 많이 사용하는 구조다.
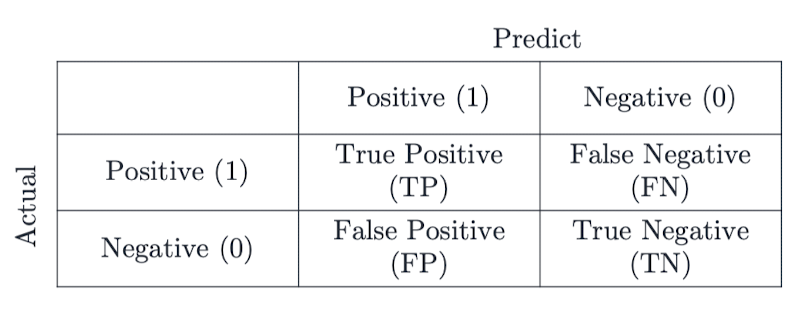
- TP: True Positive (정답도 1, 예측도 1)
- FN: False Negative (정답은 1인데 예측은 0)
- FP: False Positive (정답은 0인데 예측은 1)
- TN: True Negative (정답도 0, 예측도 0)
📌
- Accuracy : (TP + TN) / (TP + TN + FP + FN)
- Recall (Sensitivity): 실제 양성 중 예측도 양성인 비율 : TP / (TP + FN)
- Specificity: 실제 음성 중 예측도 음성인 비율 : TN / (FP + TN)
- False Alarm Prob: 실제는 음성인데 양성으로 잘못 예측한 비율 : FP / (FP + TN)
- Precision: 예측한 양성 중 실제 양성인 비율 : TP / (TP + FP)
- F1: Precision과 Recall의 조화 평균.
Threshold 선택
로지스틱 회귀처럼 확률을 출력하는 모델은 임계값(threshold)에 따라 결과가 달라진다.
- threshold를 낮추면 → Recall ↑ Precision ↓
- threshold를 높이면 → Recall ↓ Precision ↑
상황에 따라 threshold를 조정해야 한다.
예를 들어:
- 희귀 질병 예측처럼 false negative가 위험한 경우 → threshold를 낮춰서 예민하게 탐지
- 스팸 필터처럼 false positive가 불편한 경우 → threshold를 높여서 신중하게 판단
📌 threshold를 결정하는 방법?
- ROC Curve
- Expected Profit (EP)
하나씩 살펴보자
ROC Curve와 AUC
💡 ROC Curve란?
Recall (Sensitivity) vs FPR (False Positive Rate)을 시각화한 곡선이다.
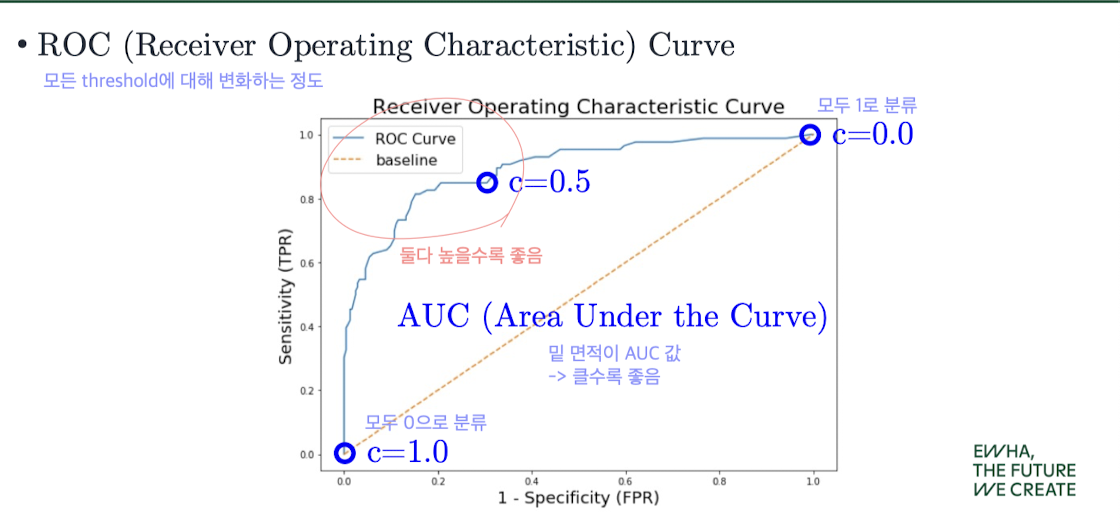
- 왼쪽 위 (0,1) 꼭짓점에 가까울수록 좋음
- ROC 곡선 아래 면적 = AUC (클수록 좋은 모델)
- 완벽한 모델의 AUC는 1, 완전 랜덤이면 0.5
📌 ROC curve로 threshold 결정하기
- SE : Sensitivity, SP : Specificity
- Euclidean : (0,1) 꼭짓점에서 가장 짧은 거리를 갖는 부분에 대한 threshold
- Youden's index : SE와 SP를 합친걸 최대화하는
Expected Profit (기대 이익)
모델 성능을 이익 기준으로 평가할 수도 있다.
예를 들어,
- 실제 양성을 맞추면 +1
- 실제 음성을 맞추면 +1
- 음성을 양성으로 틀리면 -1
- 양성을 음성으로 틀리면 -10
처럼 각 케이스에 가중치를 다르게 준다.
📌 Profit Matrix :
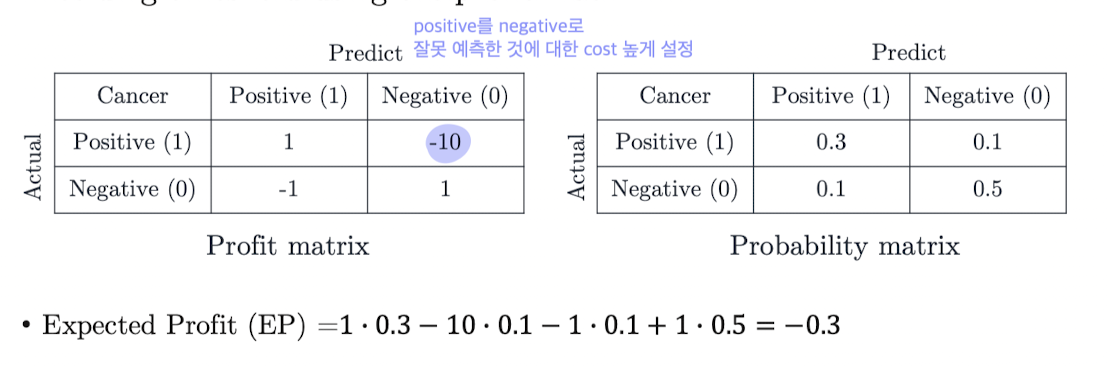
그렇게 해서
예상되는 전체 이익(Expected Profit)을 계산하고,
- Expected Profit = 각 경우의 확률 × profit
👉 가장 이득이 높은 모델이나 threshold를 선택한다!
2. 모델 검증 (Validation)
모델을 학습하는 과정에서 과적합(overfitting)을 방지하기 위해
validation set를 활용해 모델을 평가해야 한다.
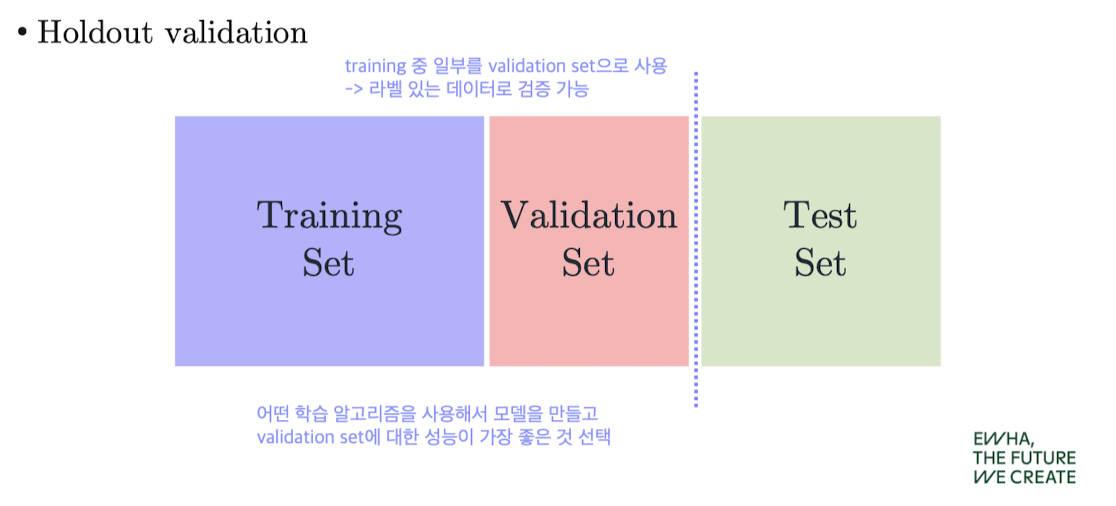
Holdout Validation
- 데이터를 train/validation/test로 나누어 사용
- 가장 간단하지만 데이터가 적을 경우 불리
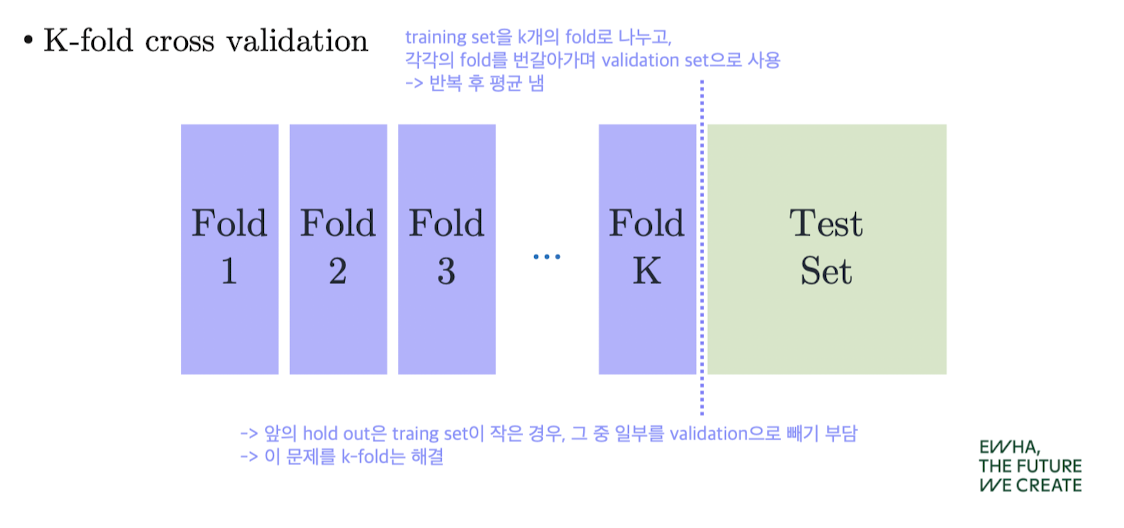
K-Fold Cross Validation
- train set을 K개의 Fold로 나누고
- 각각의 Fold를 번갈아 가며 validation set으로 사용
- 모든 데이터가 한 번씩 validation set이 되어 안정적
- 반복 후 평균 성능으로 모델 선택
LOOCV (Leave One Out Cross Validation)
- cross의 특수한 형태 (모든 데이터 하나하나가 Fold)
- 데이터가 n개면, 매번 1개를 validation으로 사용 (총 n번 학습)
- ‼️ bias는 낮지만 계산량이 큼
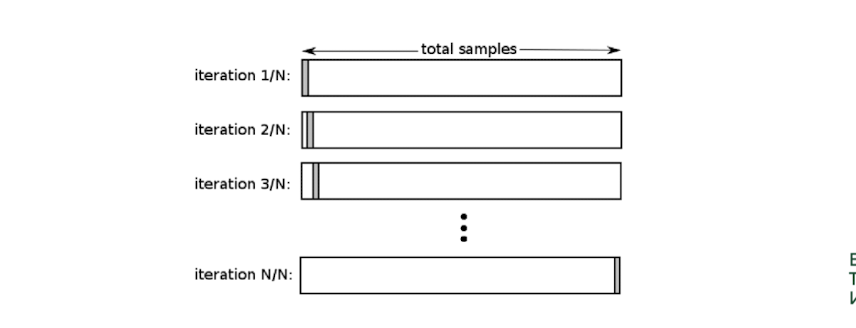
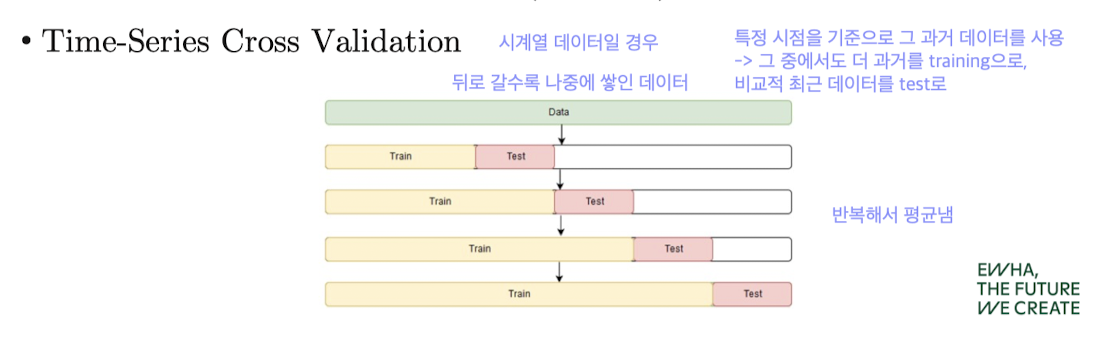
Time-Series Cross Validation
- 시계열 데이터에 특화
- 과거 데이터를 훈련, 비교적 미래 데이터를 검증으로