[5주차] EDA

Pandas 기초
데이터 읽기
import pandas as pd
CCTV_Seoul = pd.read_csv('Seoul_CCTV.csv', encoding ='utf-8')head()
데이터를 위에서 부터 불러온다(기본 값 : 5)
CCTV_Seoul.head()
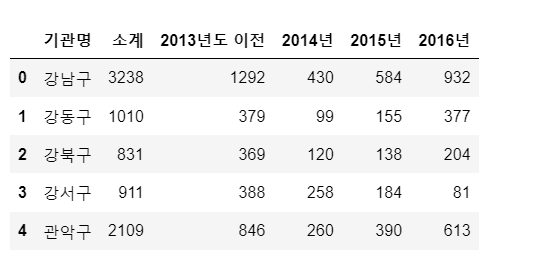
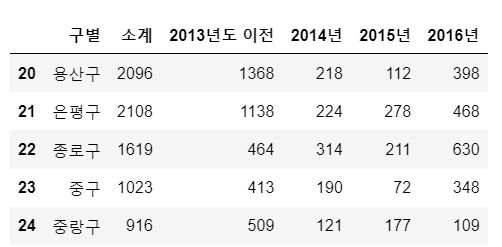
tail()
데이터를 아래서 부터 불러온다(기본 값 : 5)
CCTV_Seoul.tail()
column의 이름 조회
CCTV_Seoul.columns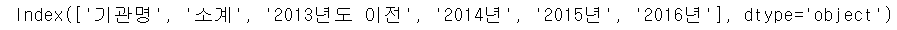
CCTV_Seoul.columns[0]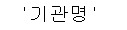
column명 바꾸기
CCTV_Seoul.rename(columns = {CCTV_Seoul.columns[0] : '구별'}, inplace=True)
CCTV_Seoul.head()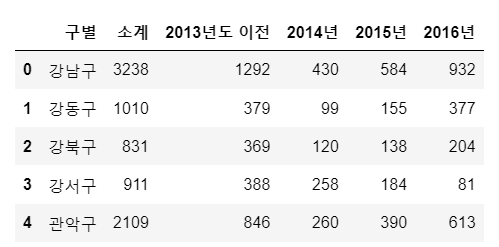
pop_Seoul.rename(columns = {
pop_Seoul.columns[0] : '구별',
pop_Seoul.columns[1] : '인구수',
pop_Seoul.columns[2] : '한국인',
pop_Seoul.columns[3] : '외국인',
pop_Seoul.columns[4] : '고령자'
}, inplace=True)
pop_Seoul.head()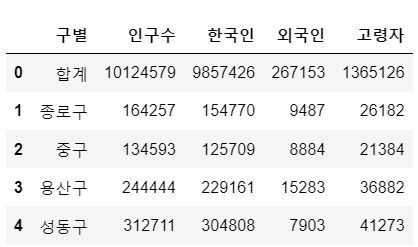
excel 불러오기
- 엑셀 설정
- 자료를 읽기 시작할 행(header)를 지정
- 읽어올 엑셀의 컬럼을 지정(usecols)
pop_Seoul = pd.read_excel('Seoul_Population.xls', header=2, usecols="B, D, G, J, N")
pop_Seoul.head()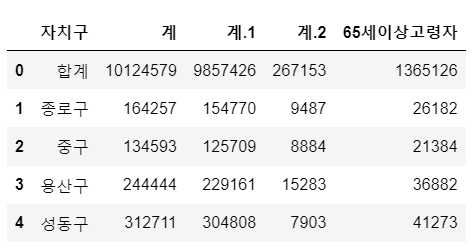
Series
- index와 value로 이루어져 있다.
- 한 가지 데이터 타입만 가질 수 있다.
- Pandas의 데이터형을 구성하는 기본
pd.Series([1,2,3,4])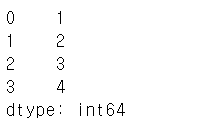
pd.Series([1,2,3,4], dtype=np.float64)
pd.Series([1,2,3,4], dtype=str)
연산(int나 float)
data = pd.Series([1,2,3,4])
data % 2
날짜(시간)
dates = pd.date_range('20130101', periods=6)
dates
DataFrame
- Pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다.
- index와 columns를 지정하면 된다.
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=['A','B','C','D'])
df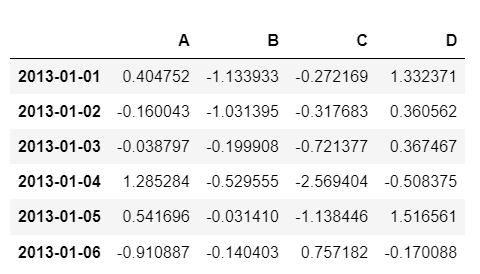
columns 확인
df.columns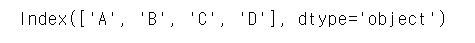
values 확인
df.values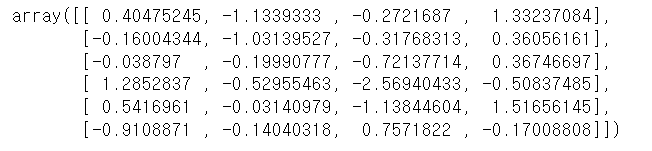
info
- DataFrame의 기본 정보 확인
- 여기서는 각 컬림의 크기와 데이터형태를 확인하는 경우가 많다.
df.info()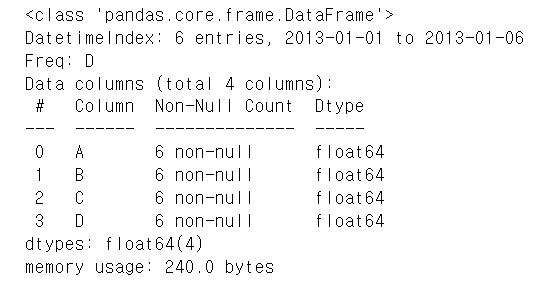
describe
- DataFrame의 통계 기술 정보를 확인
df.describe()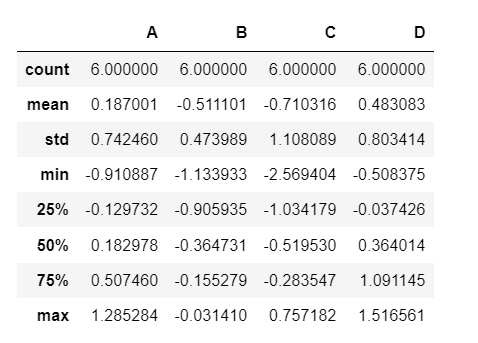
sort_values
데이터 정렬(특정 컬럼(열))
df.sort_values(by='B', ascending=False)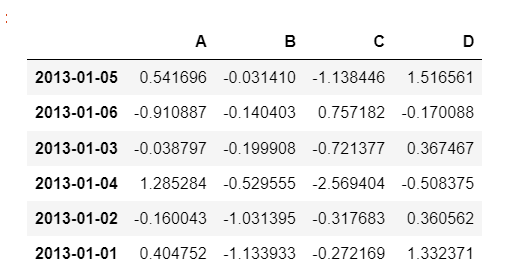
특정 컬럼 확인
df['A']
슬라이싱
- [n:m] : n부터 m-1까지
- 그러나 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함함
df[0:3]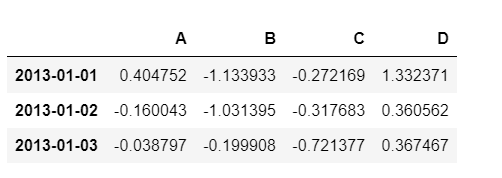
df['20130101':'20130103']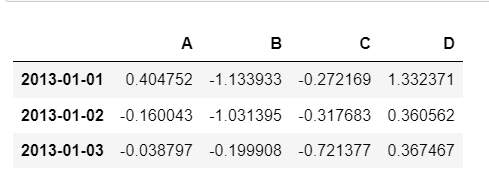
loc : location
- 이름으로도 사용 가능
df.loc[:, ["A", "B"]]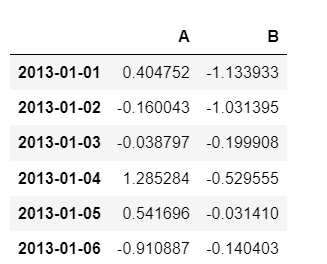
df.loc['20130101':'20130102', ["A", "B"]]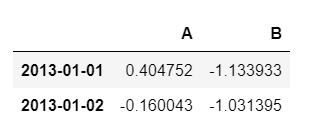
iloc
- 번호로 접근
df.iloc[3]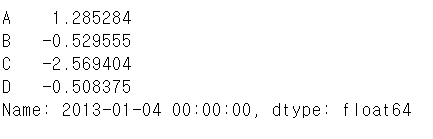
df.iloc[3:5, 0:2]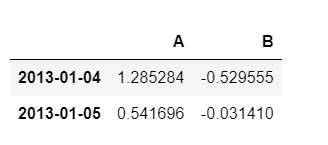
del
- 컬럼 지우기
del df['E']
df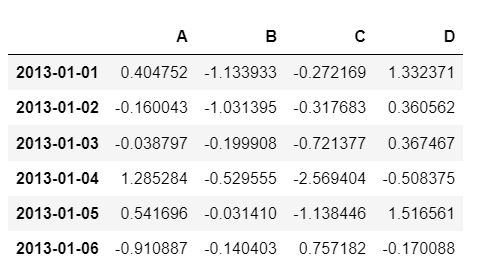
apply
- 함수를 적용
df.apply(np.cumsum)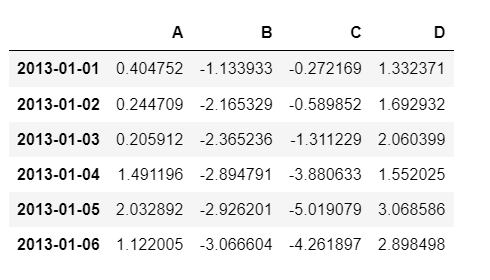

끄적끄적..