[5주차] EDA

CCTV 데이터 훑어보기
CCTV_Seoul.head()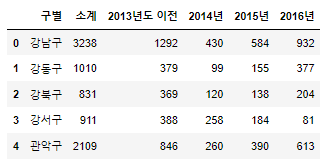
CCTV_Seoul.tail()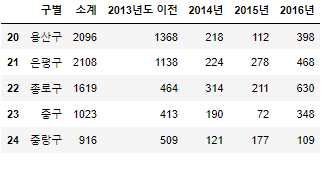
오름차순 정렬
CCTV_Seoul.sort_values(by='소계', ascending=True).head()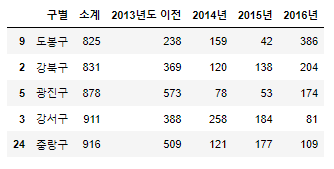
내림차순 정렬
CCTV_Seoul.sort_values(by='소계', ascending=False).head()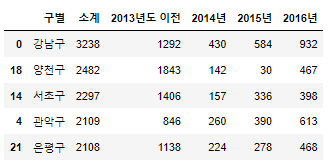
기존 컬럼이 없으면 추가, 있으면 수정
CCTV_Seoul['최근 증가율'] = (
(CCTV_Seoul['2016년'] + CCTV_Seoul['2015년'] + CCTV_Seoul['2014년']) / CCTV_Seoul['2013년도 이전'] * 100
)
CCTV_Seoul.sort_values(by='최근 증가율', ascending=False).head()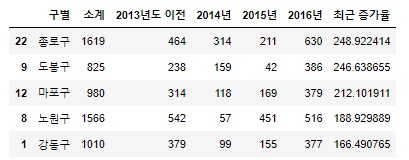
인구현황 데이터
pop_Seoul.head()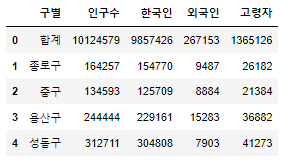
pop_Seoul.tail()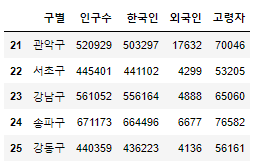
불필요한 행 제거
pop_Seoul.drop([0], axis=0, inplace=True)pop_Seoul.head()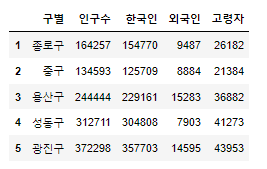
unique()
유일한 값을 가져온다. (중복 X)
pop_Seoul['구별'].unique()
외국인, 고령자 비율 구하기
pop_Seoul['외국인비율'] = pop_Seoul['외국인'] / pop_Seoul['인구수'] * 100
pop_Seoul['고령자비율'] = pop_Seoul['고령자'] / pop_Seoul['인구수'] * 100pop_Seoul.head()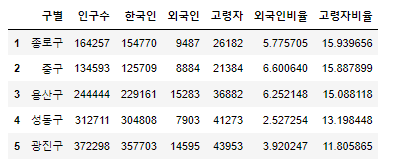
데이터 합치기
pandas에서 데이터 프레임 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join()
merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬림이나 인덱스를 키값이라고 한다.
- 기준이 되는 키 값은 두 데이터 프레임에 모두 포함 되어 있어야한다.
pd.merge(left,right,on="key")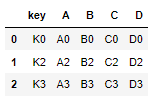
pd.merge(left,right,how="left",on="key")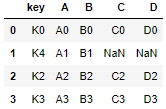
pd.merge(left,right,how="right",on="key")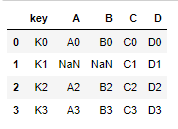
pd.merge(left,right,how="outer",on="key")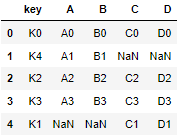
data_result = pd.merge(CCTV_Seoul,pop_Seoul,on="구별")
data_result.head()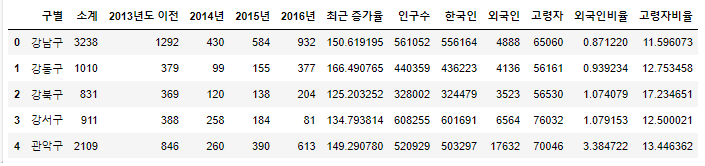
불필요한 컬럼 제거
del data_result['2013년도 이전']
del data_result['2014년']
data_result.head()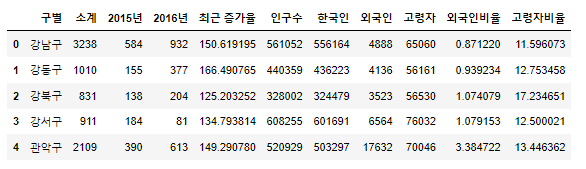
data_result.drop(["2015년", "2016년"], axis=1, inplace=True)
data_result.head(1)
index 변경
- set_index()
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index("구별", inplace=True)
data_result.head()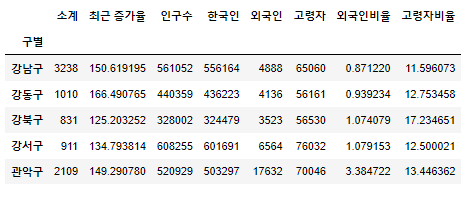
상관계수
- corr() : correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
data_result.corr()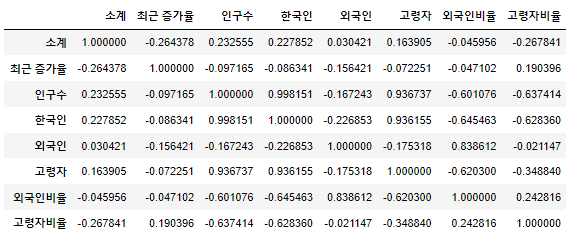
CCTV 비율 컬럼 추가
data_result['CCTV비율'] = data_result['소계'] / data_result['인구수']
data_result['CCTV비율'] = data_result['CCTV비율'] * 100
data_result.head()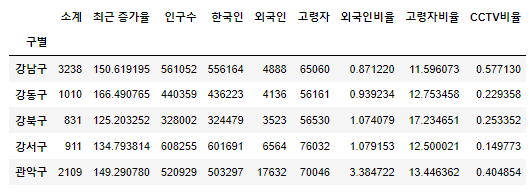

끄적끄적..