[6주차] EDA

selenium
selenium webdriver 사용하기
from selenium import webdriver
# 크롬 드라이버 위치
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 불러오고 싶은 url
driver.get('http://www.naver.com')화면 최대 크기
driver.maximize_window()화면 최소 크기
driver.minimize_window()화면 크기 설정
driver.set_window_size(600, 600)새로 고침
driver.refresh()뒤로 가기
driver.back()앞으로 가기
driver.forward()클릭
from selenium.webdriver.common.by import By
frist_element = driver.find_element(By.CSS_SELECTOR, '#content > div.cover-masonry > div > ul > li:nth-child(1) > a > span.title')
frist_element.click()새로운 탭 생성
driver.execute_script('window.open("http://www.naver.com")')탭 이동
driver.switch_to.window(driver.window_handles[0])탭 닫기
driver.close()화면 스크롤
스크롤 가능한 높이(길이)
# 자바스크립트 코드 실행
driver.execute_script('return document.body.scrollHeight')화면 스크롤 하단 이동
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')현재 보이는 화면 스크린샷 저장
driver.save_screenshot('./last_screen.png')화면 스크롤 상단 이동
driver.execute_script('window.scrollTo(0, 0)')특정 태그 지점까지 화면 스크롤
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.CSS_SELECTOR,'#content > div.cover-masonry > div > ul > li:nth-child(1) > a > span.title')
action = ActionChains(driver)
action.move_to_element(some_tag).perform()검색어 입력
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome('./chromedriver.exe')
driver.get('https://www.naver.com')CSS_SELECTOR
keyword = driver.find_element(By.CSS_SELECTOR, '#query')
keyword.clear()
keyword.send_keys('파이썬')
search_btn = driver.find_element(By.CSS_SELECTOR, '#sform > fieldset > button')
search_btn.click()from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome('./chromedriver.exe')
driver.get('https://pinkwink.kr')
search_tag = driver.find_element(By.CSS_SELECTOR, '#header > div.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > input[type=text]').send_keys('딥러닝')
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > button').click()xpath
- '//' : 최상위
- '*' : 자손 태그
- '/' : 자식 태그
- 'div[1] : div중 1번째 태그
driver.find_element(By.XPATH, '//*[@id="query"]').send_keys('xpath')
driver.find_element(By.XPATH, '//*[@id="sform"]/fieldset/button').click()selenium + beautifulsoup
현재 화면의 html 코드 가져오기
from bs4 import BeautifulSoup
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
soup.select('.post-item')미니 프로젝트(유가 데이터 분석 - 셀프 주유소가 저렴한가?)
- https://www.opinet.co.kr/searRgSelect.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
셀레니움으로 접근
페이지 접근
url = 'https://www.opinet.co.kr/searRgSelect.do'
driver = webdriver.Chrome('./chromedriver.exe')
driver.get(url)
# import time
# 팝업창으로 전환
# driver.switch_to_window(driver.window_handles[-1])
# 팝업창 닫기
# driver.close()
# time.sleep(3)
# 메인 화면으로 전환
# driver.switch_to_window(driver.window_handles[-1])
#접근 URL 다시 요청
# driver.get(url)데이터 저장
# 지역 : 시/도
sido_list_raw = driver.find_element_by_id("SIDO_NM0")
sido_list_raw.text
# 여러개의 옵션 가져오기
sido_list = sido_list_raw.find_elements_by_tag_name('option')
sido_list[1].text
sido_names = []
for option in sido_list:
sido_names.append(option.get_attribute("value"))
sido_names = sido_names[1:]
sido_names
# 구
gu_list_raw = driver.find_element_by_id('SIGUNGU_NM0') # 부모 태그
gu_list = gu_list_raw.find_elements_by_tag_name('option') # 자식 태그
gu_names = [option.get_attribute('value') for option in gu_list]
gu_names = gu_names[1:]
gu_names
import time
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
elment = driver.find_element_by_id('SIGUNGU_NM0')
elment.send_keys(gu)
time.sleep(3)
elment_get_excel = driver.find_element_by_css_selector('#glopopd_excel').click()
time.sleep(2)
driver.close()데이터 정리
import pandas as pd
from glob import glob
glob('./지역_*.xls')
# 파일명 저장
stations_files = glob('./지역_*.xls')
tmp_raw = []
for file in stations_files:
tmp = pd.read_excel(file, header=2)
tmp_raw.append(tmp)
station_raw = pd.concat(tmp_raw)
station_raw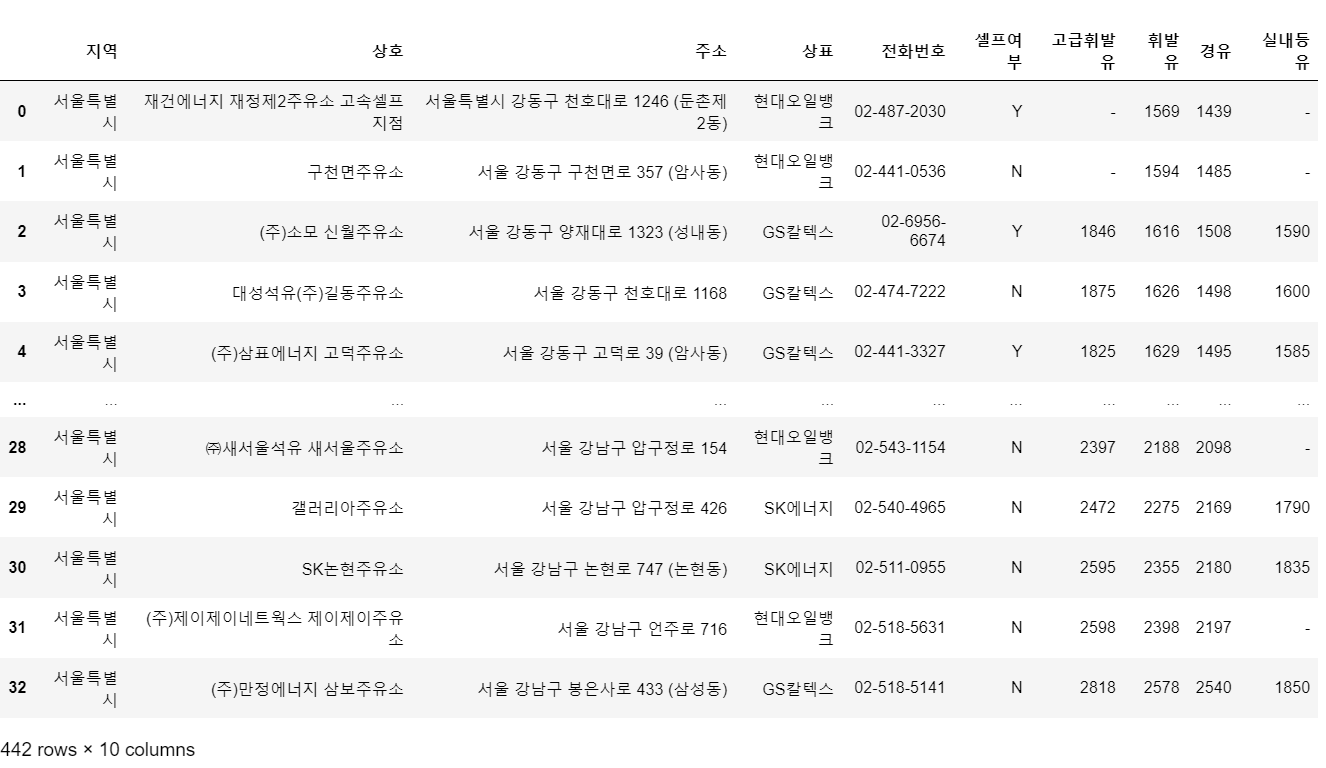
stations = pd.DataFrame({
'상호' : station_raw['상호'],
'주소' : station_raw['주소'],
'가격' : station_raw['휘발유'],
'셀프여부' : station_raw['셀프여부'],
'상표' : station_raw['상표']
})
stations.tail()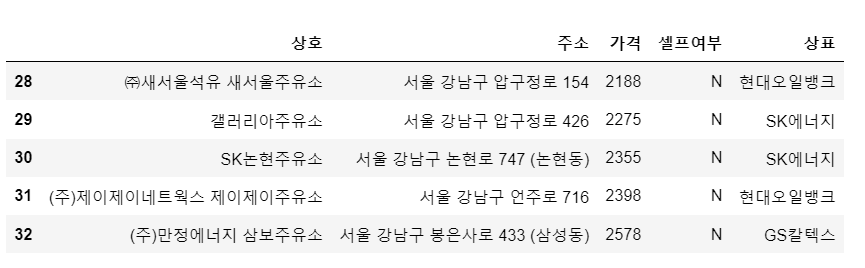
stations['구'] = [address.split()[1] for address in stations['주소']]
# 가격 정보 없는 주유소 제거
stations = stations[stations['가격'] != '-']
# 가격 데이터형 변환 object => float
stations['가격'] = stations['가격'].astype('float')
stations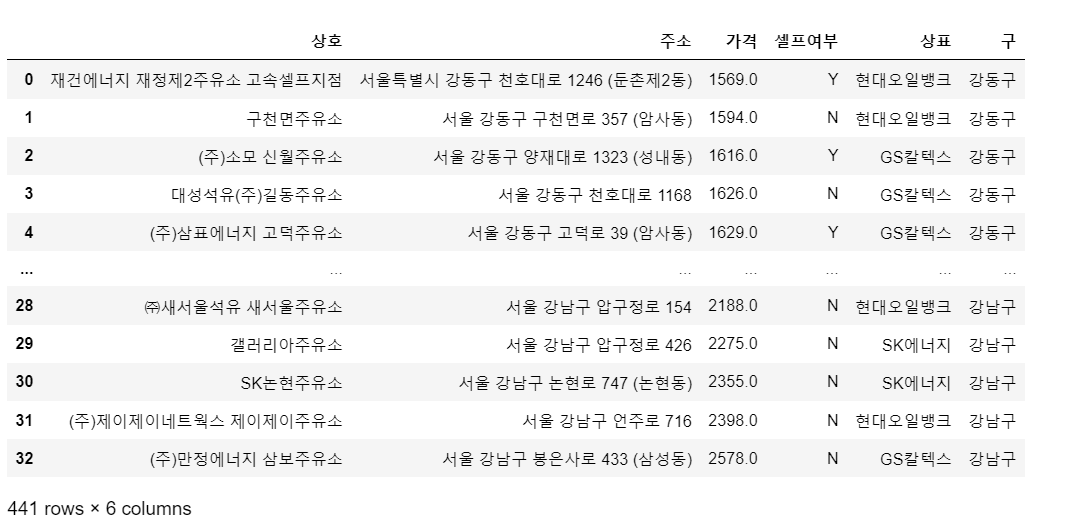
# 인덱스 재정렬
stations.reset_index(inplace=True)
del stations['index']
stations.tail()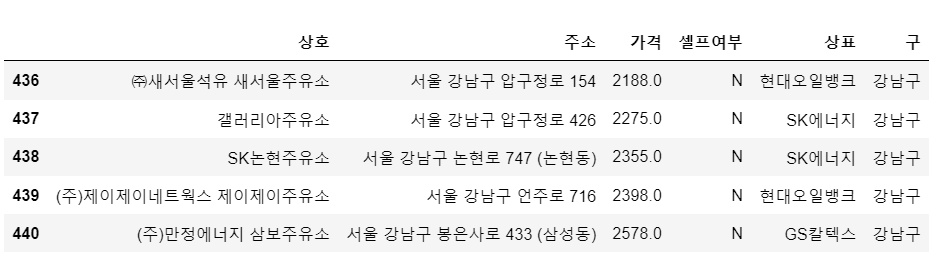
시각화
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import rc, font_manager
get_ipython().run_line_magic('matplotlib', 'inline')
plt.rcParams['font.family'] = 'Malgun Gothic'
stations.boxplot(column='가격', by='셀프여부', figsize=(12, 8))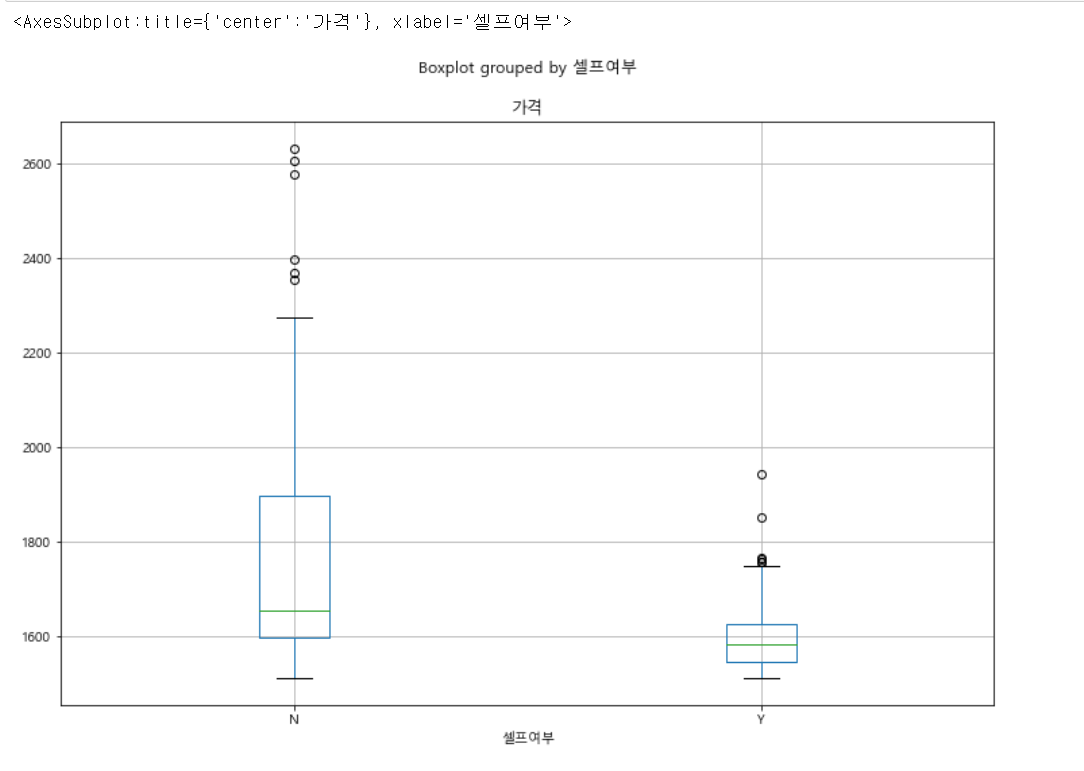
# seaborn boxplot
plt.figure(figsize=(12, 8))
sns.boxplot(x='셀프여부', y='가격', data=stations, palette='Set3')
plt.grid(True)
plt.show()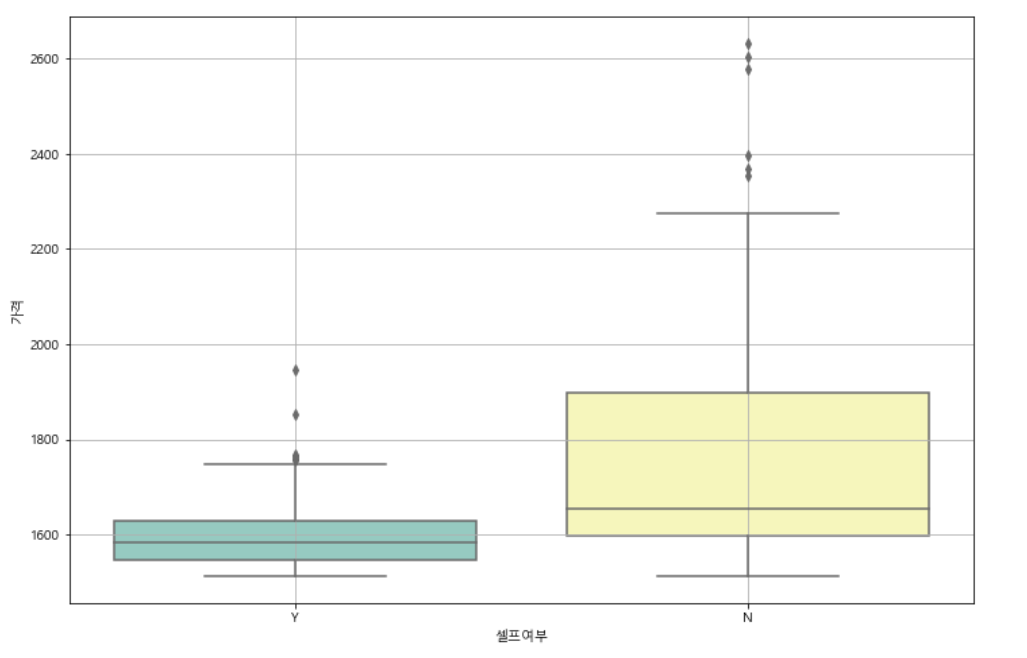
# seaborn boxplot > 상표별 셀프기준 가격 여부
plt.figure(figsize=(12, 8))
sns.boxplot(x='상표', y='가격',hue ='셀프여부', data=stations, palette='Set1')
plt.grid(True)
plt.show()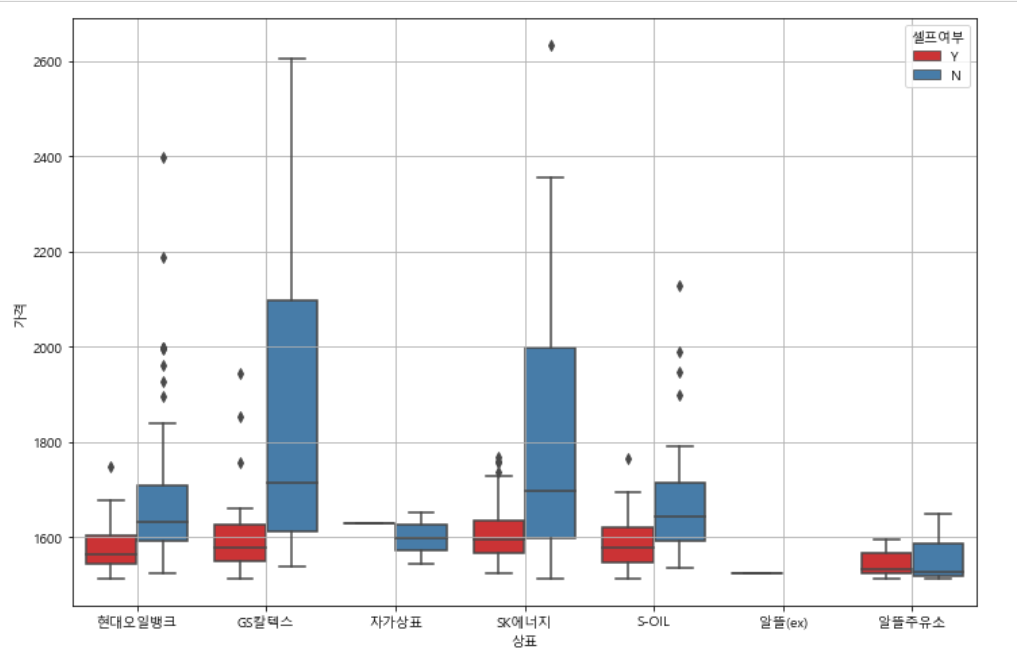
# 지도 시각화
import json
import folium
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
# 가장 비싼 주유소 10개
stations.sort_values(by='가격', ascending=False).head(10)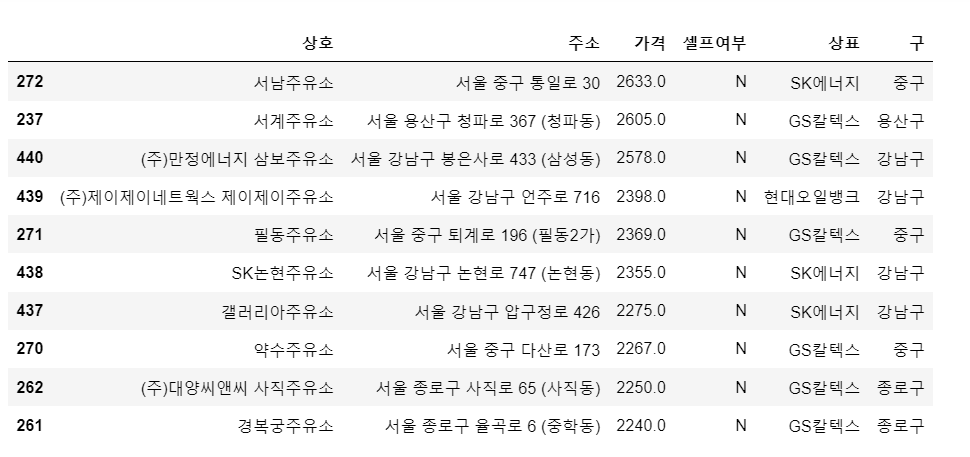
# 가장 싼 주유소 10개
stations.sort_values(by='가격').head(10)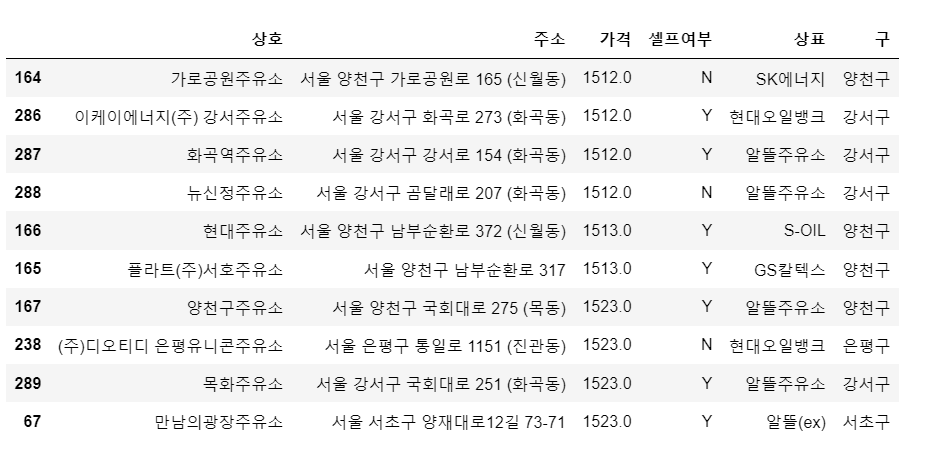
import numpy as np
gu_data = pd.pivot_table(data=stations, index='구', values='가격', aggfunc=np.mean)
gu_data.head()
geo_path = '../범죄/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5)
my_map.choropleth(
geo_data=geo_str,
data = gu_data,
columns=[gu_data.index, '가격'],
key_on='feature.id',
fill_color='PuRd'
)
my_map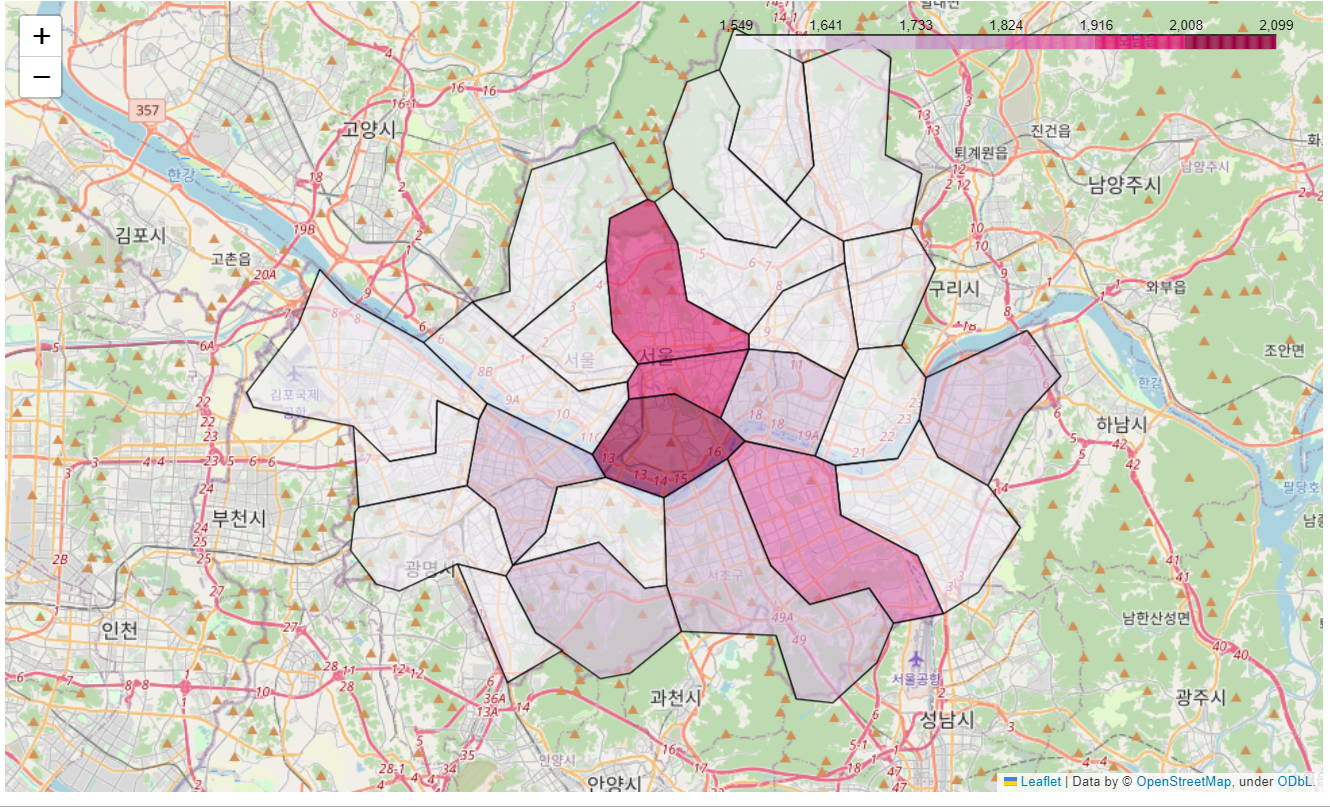

끄적끄적..