1 Numpy
- Numerical Python의 약자로 대규모 다차원 배열고 ㅏ행렬 연산에 필요한 함수 제공. => Pandas, Scikit-learn, Tensorflow 등의 토대가 된다.
- 이미지 등도 2차원 배열로 구성. 픽셀 하나하나에 0~255까지의 숫자로 구성. 데이터를 배열로 구성하고 저장하고 가공하는 것이 데이터 처리의 기본 절차.
- 장점
- 코어 부분이 C로 구현되어 동일한 연산이어도 Python에 비해 빠름
- 효율적 메모리 사용 가능하도록 구현
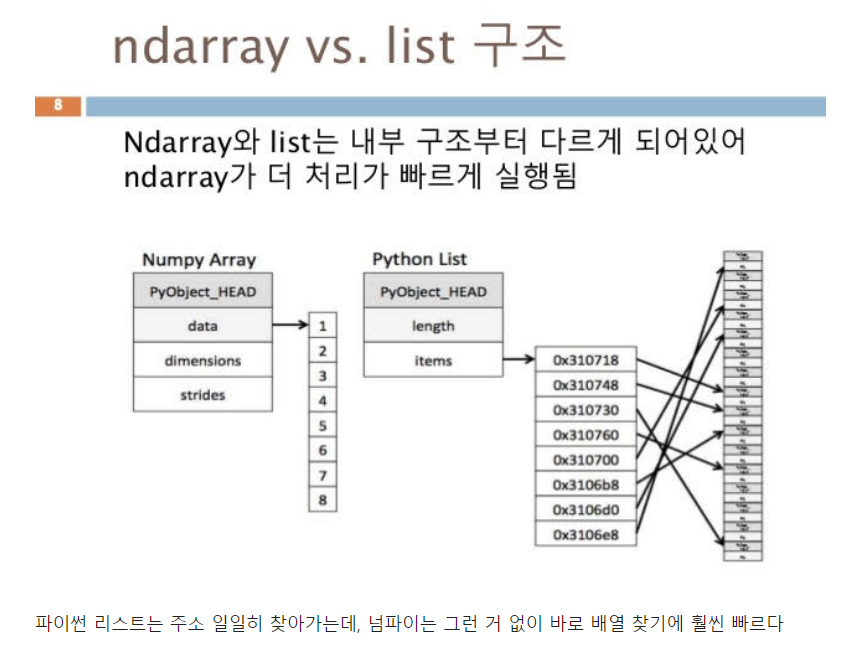
2 기본 기능들
np.array([1, 3, 5, 7], float): numpy array를 생성하고, 뒤에는 내부 element 데이터 타입 지정.
참고로 여기 "5"처럼 string으로 들어가있어도, 자동으로 지정한 타입으로 변경.- numpy 데이터 타입
np.float16: 일반적인 float는 float64로 8비트, 소수점 16~18자리까지. float16은 2비트로, 소수점 3~4자리 정밀도. 대규모 데이터에서 디테일 중요하지 않고 연산 더 빠르게 하기 위해.np.float32
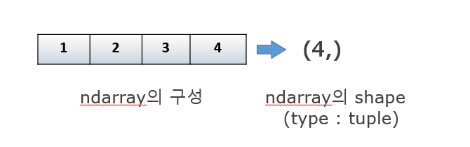
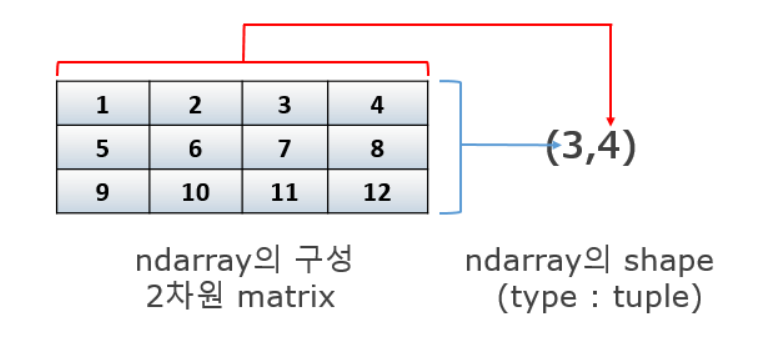
np.array.dtype: numpy array의 배열 전체의 데이터 타입을 나타내는 속성. =로 배열 전체 데이터 바꿀 수 있다.np.array.shape: 튜플 형태로 데이터 배열의 모양을 나타낸다.
- 1차원 array: vector
- 2차원 array: matrix(행렬)
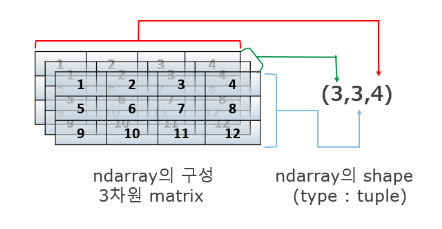
- 3차원 이상의 array: nth-order tensor.
- (3, 3, 4)로 shape가 나왔을 때, 항상 마지막 2글자가 2차원 행렬이다. 즉, 3행X4열 행렬이 3개 있는 것.
np.array.ndim: number of dimension. 3차원이면 3, 2차원이면 2.np.array.reshape(8, ): reshape는 배열을 원하는 모양으로 바꾸는 것.- 이렇게 (8, )이면 1차원 배열.
- (8, 1)이면 8행 1열의 2차원 배열
- (8, -1)이면 -1은 나머지에 맞춰서 자동으로 지정. 즉, 데이터가 8개 있으면 1열로 자동으로 바뀐다.
- (4, -1, 2) 등 3차원 이상도 가능.
np.array.flatten(): 다차원 array를 1차원으로 변환.np.arange(5, 50, 2): list의 range와 같다. 5~49까지 2 간격으로 추출.np.zeros(shape=(5, 2), dtype=np.int8): 0으로 가득찬 ndarray 생성. 데이터 타입은 지정 안하면, float.np.ones(shape=(5, 2), dtype=np.int8): 1로 가득찬 ndarray 생성.np.empty(shape=(5, 2)): 지정된 shape와 dtype의 ndarray 생성. 배열 요소를 특정 값으로 초기화하지 않아 임의의 데이터가 채워지고, 이 데이터는 실행할 때마다 달라질 수 있는 메모리 상의 임의의 값.np.zeros_like(배열),np.ones_like(배열),np.empty_like(배열): 기존 ndarray와 같은 shape 크기의 0, 1, empty array 반환.
empty의 경우 shape과 dtype이 같은 ndarray를 제공. 배열 내부를 특정 값으로 초괴화하지 않아, 새 배열엔 임의의 데이터 포함하고, 이 데이터는 메모리에 이미 존재하는 값들.
3 NumPy indexing, slicing
- list와 달리 [0, 0] 같은 표기법 제공. 2차원 배열에서 제공하는 표기법.
- slicing도 마찬가지라 [:, 1:] 과 같이 가능. 2차원 배열에서 [1:3]처럼 하면 1~3행만 추출. [:, ::2]처럼 간격도 가능.

일본에서 일하는 게임 기획자. 시시해서 죽어버리지 않게, 재밌고 의미 있는 컨텐츠에 관심 있습니다. 그 도구로 데이터, AI도 찝적댑니다.